





International Conference on Machine Learning은 기계학습과 인공지능 커뮤니티에서 가장 권위 있는 학회 중 하나로, 올해는 7월 21일부터 27일까지 비엔나에서 2024년 회의를 개최했습니다.

이 학회는 7일간의 집중적인 학습 경험으로, 구두 발표와 다른 연구자들과 직접 아이디어를 교환할 수 있는 기회가 있었습니다. 강화학습, 생명과학을 위한 AI, 표현 학습, 멀티모달 모델, 그리고 물론 AI 모델 개발의 핵심 요소들에서 많은 흥미로운 연구가 진행되고 있습니다. 특히 주목할 만한 것은 Physics of Large Language Models에 관한 튜토리얼로, LLM의 내부 작동 방식을 광범위하게 탐구하고 LLM이 정보를 암기하는지 아니면 추론을 적용하는지에 대한 설득력 있는 답변을 제시했습니다.
tagJina-CLIP-v1에 대한 우리의 연구
우리는 Multi-modal Foundation Models meet Embodied AI 워크샵의 일환으로 새로운 멀티모달 모델 jina-clip-v1에 관한 연구를 포스터 발표했습니다.
다양한 분야에서 일하는 국제 동료들과 만나 우리의 연구에 대해 논의하는 것은 매우 영감을 주었습니다. 우리의 발표는 많은 긍정적인 피드백을 받았으며, 특히 Jina CLIP이 멀티모달과 유니모달 대조 학습 패러다임을 통합하는 방식에 많은 사람들이 관심을 보였습니다. 토론은 CLIP 아키텍처의 한계부터 추가 모달리티로의 확장, 나아가 펩타이드와 단백질 매칭에의 응용까지 다양했습니다.
Michael Günther가 Jina CLIP을 발표하는 모습
tag우리가 선정한 주목할 만한 연구들
다른 연구자들의 프로젝트와 발표에 대해 많은 논의를 할 수 있는 기회가 있었으며, 다음은 우리가 가장 인상 깊었던 몇 가지입니다:
tagPlan Like a Graph (PLaG)
많은 사람들이 "Few-Shot Prompting"이나 "Chain of Thought prompting"을 알고 있습니다. Fangru Lin이 ICML에서 발표한 새롭고 더 나은 방법이 있습니다: Plan Like a Graph (PLaG)입니다.
그녀의 아이디어는 간단합니다: LLM에 주어진 작업을 LLM이 병렬로 또는 순차적으로 해결할 수 있는 하위 작업들로 분해합니다. 이러한 하위 작업들이 실행 그래프를 형성하며, 전체 그래프를 실행하면 상위 수준의 작업이 해결됩니다.
위 비디오에서 Fangru Lin은 이해하기 쉬운 예시를 통해 이 방법을 설명합니다. 이 방법으로 결과가 개선되지만, LLM은 여전히 작업 복잡도가 증가할 때 급격한 성능 저하를 겪는다는 점을 주목해야 합니다. 그렇다 하더라도, 이는 올바른 방향으로의 훌륭한 진전이며 즉각적인 실용적 이점을 제공합니다.
우리에게 있어 그녀의 연구가 Jina AI에서의 우리의 프롬프트 응용과 어떻게 유사한지 보는 것은 흥미롭습니다. 우리는 이미 그래프와 같은 프롬프트 구조를 구현했지만, 그녀가 했던 것처럼 실행 그래프를 동적으로 생성하는 것은 우리가 탐구할 새로운 방향입니다.
tagXRM을 통한 환경 발견
이 논문은 레이블과 상관관계가 있지만 정확한 분류/관련성을 유도하지 않는 특징에 모델이 의존하게 만들 수 있는 훈련 환경을 발견하는 간단한 알고리즘을 제시합니다. 유명한 예시로 물새 데이터셋이 있는데(arXiv:1911.08731 참조), 이는 물새나 육지새로 분류되어야 하는 서로 다른 배경의 새 사진들을 포함합니다. 훈련 중에 분류기는 새의 특징 자체에 의존하는 대신 이미지의 배경에 물이 있는지 여부를 감지합니다. 이러한 모델은 배경에 물이 없는 경우 물새를 잘못 분류하게 됩니다.
이러한 행동을 완화하기 위해서는 모델이 오해의 소지가 있는 배경 특징에 의존하는 샘플들을 감지할 필요가 있습니다. 이 논문은 이를 위한 XRM 알고리즘을 제시합니다.
이 알고리즘은 훈련 데이터셋의 두 개의 서로 다른 부분에서 두 모델을 훈련시킵니다. 훈련 중에 일부 샘플의 레이블이 뒤바뀝니다. 구체적으로, 다른 모델(해당 샘플로 훈련되지 않은)이 샘플을 다르게 분류할 경우 이런 일이 발생합니다. 이런 방식으로 모델들은 허위 상관관계에 의존하도록 유도됩니다. 이후에는 모델 중 하나가 예측한 레이블이 실제 정답과 다른 훈련 데이터에서 샘플을 추출할 수 있습니다. 나중에 이 정보를 사용하여 더 강건한 분류 모델을 훈련시킬 수 있는데, 예를 들어 Group DRO 알고리즘을 사용할 수 있습니다.
tagLLM 평가 비용을 140분의 1로 줄이세요!
네, 제대로 들으셨습니다. 이 한 가지 트릭으로 LLM 평가 비용을 아주 작은 부분으로 줄일 수 있습니다.
핵심 아이디어는 간단합니다: 동일한 모델 능력을 테스트하는 모든 평가 샘플을 제거하는 것입니다. 그 뒤에 있는 수학은 덜 직관적이지만 포스터 세션에서 발표한 Felipe Maia Polo가 잘 설명했습니다. 140분의 1로의 감소는 인기 있는 MMLU 데이터셋(Massive Multitask Language Understanding)에 적용됩니다. 여러분 자신의 평가 데이터셋의 경우, 샘플들의 평가 결과가 서로 얼마나 상관관계가 있는지에 따라 달라집니다. 많은 샘플을 건너뛸 수도 있고 몇 개만 건너뛸 수도 있습니다.
한번 시도해 보세요. 우리 Jina AI에서 평가 샘플을 얼마나 줄일 수 있었는지 계속 알려드리겠습니다.
tag다중 마진 매칭 갭을 통한 다중 표현의 대조
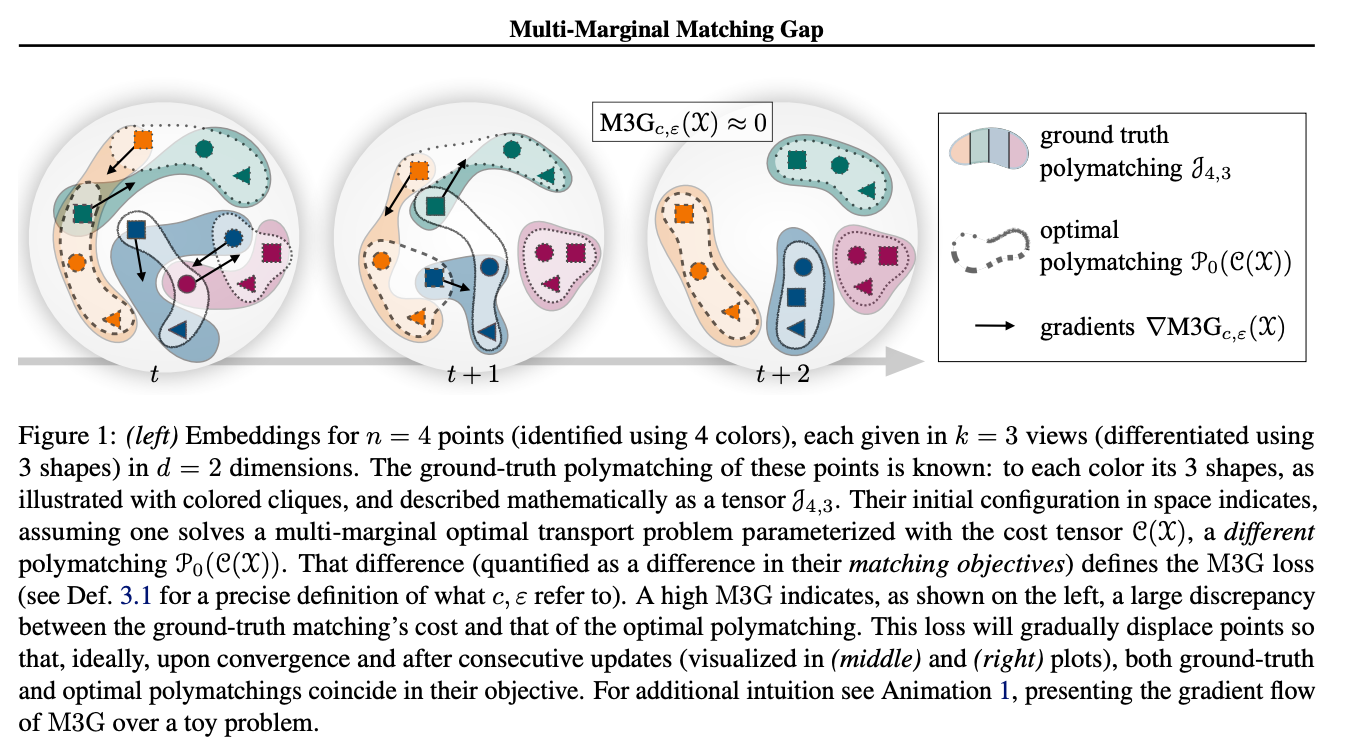
이 연구는 대조 학습의 일반적인 과제를 다룹니다: InfoNCE loss와 같은 대부분의 대조 손실 함수들은 데이터 포인트 쌍으로 작동하고 긍정적 쌍 간의 거리를 측정합니다. k > 2 크기의 긍정적 튜플로 확장하기 위해, 대조 학습은 보통 문제를 여러 쌍으로 줄이고 모든 긍정적 쌍에 대한 쌍별 손실을 누적하려고 합니다. 저자들은 여기서 다중 마진 최적 수송 문제를 해결하는 Sinkhorn 알고리즘의 수정된 버전인 M3G(Multi-Marginal Matching Gap) 손실을 제안합니다. 이 손실 함수는 데이터셋이 k > 2 크기의 긍정적 튜플로 구성된 시나리오, 예를 들어 동일한 객체의 2개 이상의 이미지, 3개 이상의 양식을 가진 멀티모달 문제, 또는 동일한 이미지의 3개 이상의 증강을 사용하는 SimCLR 확장에서 사용될 수 있습니다. 실험 결과는 이 방법이 문제를 쌍으로 단순화하는 것보다 더 나은 성능을 보여줍니다.
tag정답 데이터가 필요 없습니다!
스탠포드 대학교의 Zachary Robertson는 레이블이 없는 데이터로 LLM을 평가하는 연구를 발표했습니다. 이것이 이론적인 연구이긴 하지만, 고급 AI 시스템의 확장 가능한 감독에 많은 잠재력을 가지고 있다는 점을 주목하세요. 이는 일반적인 LLM 사용자를 위한 것은 아니지만, LLM 평가 작업을 하는 경우 반드시 살펴봐야 할 것입니다. 우리는 이미 Jina AI에서 이런 방식으로 우리의 에이전트를 평가할 수 있다는 것을 알 수 있습니다. 첫 실험을 실행하면 결과를 공유하겠습니다.
tag모델 붕괴는 피할 수 없는가? 실제 및 합성 데이터를 축적하여 재귀의 저주 깨기
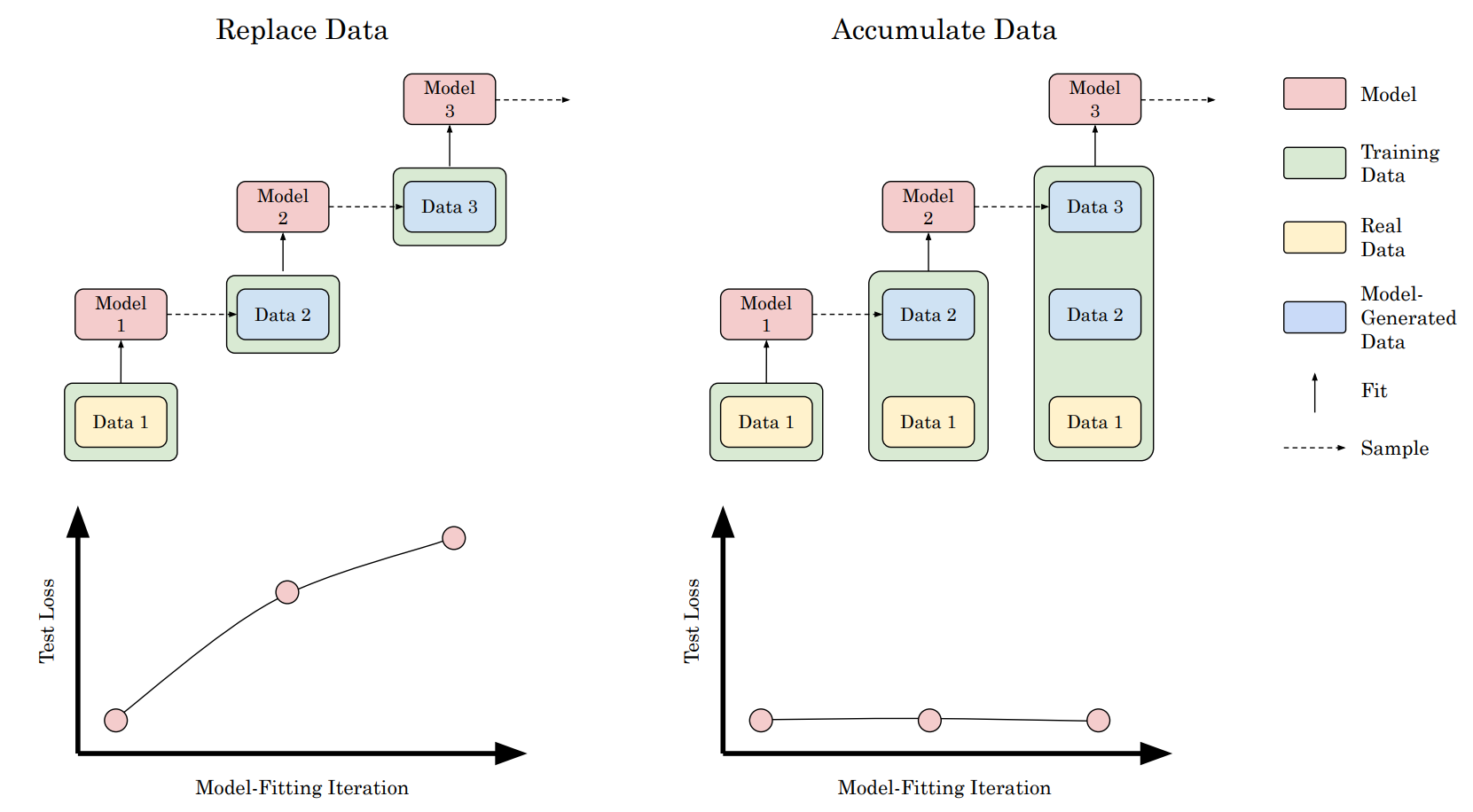
최근 여러 기사들(이 Nature 기사와 같이)은 웹에서 크롤링한 학습 데이터에 합성 데이터가 점점 더 많이 포함되면서 새로 학습된 모델의 성능이 시간이 지남에 따라 악화될 수 있다고 예측했습니다.
우리의 동료 Scott Martens도 모델 붕괴에 대한 글을 발표하고 합성 데이터가 모델 학습에 유용할 수 있는 경우에 대해 논의했습니다.

학습 데이터가 이전 버전의 모델이나 동일한 데이터로 학습된 모델에 의해 생성되었기 때문에 모델 학습이 붕괴될 수 있습니다. 이 논문은 약간 다른 그림을 보여주는 실험을 수행했습니다: 이전 실험에서처럼 실제 데이터를 합성 데이터로 대체할 때만 붕괴가 발생합니다. 하지만 실제 데이터에 추가 합성 데이터를 보강할 때는 결과 모델의 성능에 측정된 변화가 없습니다. 이러한 결과는 모델 붕괴가 일어나지 않을 것임을 시사합니다. 그러나 추가 합성 데이터를 사용하는 것이 해당 합성 데이터 포인트를 생성하는 데 사용된 모델보다 일반적으로 우수한 모델을 학습하는 데 도움이 되지 않는다는 것을 다시 한 번 입증합니다.
tagAI를 위한 뇌수술이 이제 가능합니다
누군가의 직업을 예측하되 성별은 예측하고 싶지 않다고 가정해 봅시다. Google Research, ETH Zürich, International Institute of Information Technology Hyderabad (IIITH), Bar-Ilan University의 이 연구는 스티어링 벡터와 공분산 매칭을 사용하여 편향을 제어하는 방법을 보여줍니다.
tagMagicLens - 개방형 지시사항을 통한 자기지도 이미지 검색

이 논문은 쿼리 이미지 + 지시사항 + 대상 이미지 삼중항으로 학습된 자기지도 이미지 검색 모델인 MagicLens 모델을 소개합니다.
저자들은 웹에서 이미지 쌍을 수집하고 LLM을 사용하여 단순한 시각적 유사성을 넘어 다양한 의미론적 관계로 이미지를 연결하는 개방형 텍스트 지시사항을 합성하는 데이터 수집/큐레이션 파이프라인을 소개합니다. 이 파이프라인은 광범위한 분포에 걸쳐 3,670만 개의 고품질 삼중항을 생성하는 데 사용됩니다. 이후 이 데이터셋은 공유 매개변수를 가진 간단한 이중 인코더 아키텍처를 학습하는 데 사용됩니다. 백본 비전 및 언어 인코더는 CoCa 또는 CLIP base와 large 변형으로 초기화됩니다. 두 개의 멀티모달 입력을 단일 임베딩으로 압축하기 위해 단일 멀티헤드 어텐션 풀러가 도입됩니다. MagicLens를 학습시키기 위해 훈련 목표는 쿼리 이미지와 지시사항 쌍을 대상 이미지와 빈 문자열 지시사항과 간단한 InfoNCE 손실로 대조합니다. 저자들은 지시사항 기반 이미지 검색에 대한 평가 결과를 제시합니다.
tag프롬프트 스케칭 - 새로운 프롬프팅 방식
LLM을 프롬프팅하는 방식이 변화하고 있습니다. 프롬프트 스케칭을 통해 생성 모델에 고정된 제약 조건을 제공할 수 있습니다. 단순히 지시사항을 제공하고 모델이 원하는 대로 수행하기를 바라는 대신, 완전한 템플릿을 정의하여 모델이 원하는 것을 생성하도록 강제할 수 있습니다.
이를 구조화된 JSON 형식을 제공하도록 미세 조정된 LLM과 혼동하지 마세요. 미세 조정 접근 방식에서는 모델이 여전히 원하는 것을 자유롭게 생성할 수 있습니다. 프롬프트 스케칭은 그렇지 않습니다. 이는 프롬프트 엔지니어들에게 완전히 새로운 도구 상자를 제공하고 탐구해야 할 연구 영역을 제시합니다. 위 영상에서 Mark Müller는 이 새로운 패러다임에 대해 자세히 설명합니다.
그들의 오픈소스 프로젝트 LMQL도 확인해 보세요.
tagRepoformer - 저장소 수준 코드 완성을 위한 선택적 검색
많은 쿼리에서 RAG는 쿼리가 너무 쉽거나 검색 시스템이 관련 문서를 찾을 수 없어(아마도 존재하지 않기 때문에) 모델에 실제로 도움이 되지 않습니다. 이는 모델이 잘못된 또는 부재한 소스에 의존할 경우 생성 시간이 길어지고 성능이 저하되는 결과를 초래합니다.
이 논문은 LLM이 검색이 유용한지 자체 평가할 수 있도록 함으로써 이 문제를 해결합니다. 코드 템플릿의 빈 부분을 채우도록 학습된 코드 완성 모델에서 이 접근 방식을 보여줍니다. 주어진 템플릿에 대해 시스템은 먼저 검색 결과가 유용한지 결정하고, 유용하다면 검색기를 호출합니다. 마지막으로 코드 LLM은 검색 결과가 프롬프트에 추가되었는지 여부와 관계없이 누락된 컨텍스트를 생성합니다.
tag플라톤적 표현 가설

플라톤적 표현 가설은 신경망 모델이 세계에 대한 공통된 표현으로 수렴하는 경향이 있다고 주장합니다. 플라톤의 형상론에서 우리가 간접적으로만 관찰할 수 있는 왜곡된 형태로 나타나는 "이상"의 영역이 존재한다는 아이디어를 차용하여, 저자들은 우리의 AI 모델들이 학습 아키텍처, 학습 데이터, 심지어 입력 모달리티와 관계없이 하나의 현실 표현으로 수렴하는 것처럼 보인다고 주장합니다. 데이터 규모와 모델 크기가 클수록 이들의 표현은 더욱 유사해지는 것으로 보입니다.
저자들은 벡터 표현을 고려하고 커널 정렬 메트릭을 사용하여 표현 정렬을 측정합니다. 구체적으로 두 커널 K1과 K2에 의해 유도된 k-최근접 이웃 집합들의 평균 교집합을 k로 정규화한 상호 최근접 이웃 메트릭을 사용합니다. 이 연구는 모델과 데이터셋 크기가 커지고 성능이 향상될수록 커널들이 더 정렬된다는 실증적 증거를 제시합니다. 이러한 정렬은 텍스트 모델과 이미지 모델과 같이 서로 다른 모달리티의 모델들을 비교할 때도 관찰될 수 있습니다.
tag요약
스케일링 법칙과 함께 찾아왔던 초기의 열정이 다소 잦아들고 있지만, ICML 2024는 우리 분야에 새롭고 다양하며 창의적인 인재들이 많이 유입되었음을 보여주었고, 이를 통해 발전이 결코 끝나지 않았다고 확신할 수 있습니다.
우리는 ICML 2024에서 즐거운 시간을 보냈고 2025년에도 다시 돌아올 것입니다 🇨🇦.
