


The tech world has recently been abuzz with the astounding rise of Auto-GPT, an experimental open-source application built on the cutting-edge GPT-4 language model. In a mere seven days, this project has skyrocketed to fame, amassing an incredible 44,000 GitHub stars and captivating the open-source community. Auto-GPT envisions a future where autonomous AI-driven tasks are the norm, achieved by chaining together Large Language Model (LLM) thoughts.
 Torantulino
TorantulinoHowever, every overnight success comes with its fair share of growing pains. As we celebrate Auto-GPT's rapid ascent, it's crucial to take a step back and scrutinize its potential shortcomings. In this article, we will delve deep into the limitations and challenges that this AI wonderkid faces in its pursuit of production readiness. So, fasten your seatbelts and join us on this riveting journey as we navigate the twists and turns on Auto-GPT's path to stardom.
tagHow does Auto-GPT work?
Auto-GPT has been making waves in the AI world, and for a good reason. It's like giving GPT-based models a memory and a body, allowing them to tackle tasks independently and even learn from their experiences. To help you understand how Auto-GPT works, let's break it down using simple metaphors.
Imagine Auto-GPT as a resourceful robot. You assign it a mission, and it comes up with a plan to accomplish it. If the mission requires browsing the internet or using new data, Auto-GPT adapts its strategy until the task is complete. It's like having a personal assistant that can handle various tasks, such as analyzing markets, customer service, marketing, finance, and more.
Four main components make this robot tick:
- Architecture: Auto-GPT is built using the powerful GPT-4 and GPT-3.5 language models, which serve as the robot's brain, helping it think and reason.
- Autonomous Iterations: This is like the robot's ability to learn from its mistakes. Auto-GPT can review its work, build on its previous efforts, and use its history to produce more accurate results.
- Memory Management: Integration with vector databases, a memory storage solution, enables Auto-GPT to preserve context and make better decisions. This is like equipping the robot with a long-term memory to remember past experiences.
- Multi-functionality: Auto-GPT's capabilities, such as file manipulation, web browsing, and data retrieval, make it versatile and set it apart from previous AI advancements. It's like giving the robot multiple skills to handle a broader range of tasks.
So, Auto-GPT is an AI-powered robot that promises a remarkable range of tasks, learning from its experiences, and continuously improving its performance. However, it's important to recognize that these enticing prospects may not yet translate into true capabilities that Auto-GPT can deliver. As we explore its limitations and challenges, we'll focus on the following key areas:
- Sky-High Costs: A Barrier to Task Completion
- Merging Worlds: The Development and Production Conundrum
- The Looping Quagmire: Why Auto-GPT Gets Stuck
- The Vector DB: An Overkill Solution
- The Birth of Agent Mechanisms: A Work in Progress
By delving into these critical aspects, we'll provide a balanced perspective on Auto-GPT's potential for production readiness.
tagSky-High Costs: A Barrier to Task Completion
While Auto-GPT promises remarkable capabilities, one significant obstacle to its adoption in production environments is its prohibitive cost. As tasks are accomplished through a chain of thoughts, each step requires a call to the expensive GPT-4 model, which often maxes out tokens in order to provide better reasoning and prompting.
VUEGPT THOUGHTS: Let's start by checking if there are any updates to VueJS. If there are, we can update to the latest version and proceed. Otherwise, we can move on to creating the TODO list website application.
REASONING: Starting with the most updated and stable version of the framework will ensure our project has the latest features, bug fixes and is properly supported. Creating the TODO list website application is our primary goal, so we can move on to that if there are no updates.
PLAN:
- Check for VueJS updates
- Update to latest version if there are updates
- If no updates, move on to creating the TODO list website application
CRITICISM: None
NEXT ACTION: COMMAND = google ARGUMENTS = {'input': 'VueJS latest version update'}
Enter 'y' to authorise command, 'y -N' to run N continuous commands, 'n' to exit program, or enter feedback for VueGPT...GPT-4 tokens are far from cheap. According to OpenAI, the GPT-4 model with an 8K context window charges 0.06 per 1,000 tokens for results. Let's break down the cost of each step in the chain of thoughts, assuming that each action maxes out the context window of 8,000 tokens, with 80% being prompts and 20% being results.

For 8,000 tokens:
- Prompts (80%): 6,400 tokens
- Results (20%): 1,600 tokens
Cost of prompts: 6,400 tokens x 0.192 Cost of results: 1,600 tokens x 0.096
Total cost per step: 0.096 = $0.288
It's not uncommon for Auto-GPT to take an average of 50 steps to complete a small task. So, the cost of completing a single task would be:
Task cost: 50 steps x 14.4
The cost of completing a single task quickly adds up to a considerable amount, making Auto-GPT's current implementation impractical for many users and organizations.
tagMerging Worlds: The Development and Production Conundrum
Upon first glance, one might consider 14.4 to find a recipe for Thanksgiving by following the same chain of thought again. It becomes clear that generating recipes for Christmas or Thanksgiving should differ by only one "parameter": the festival. The initial $14.4 is spent on developing a method for creating a recipe. Once established, spending the same amount again to adjust the parameter seems illogical. This uncovers a fundamental problem with Auto-GPT: it fails to separate development and production.
When using Auto-GPT, the development phase is deemed complete once a goal is achieved and a chain of thoughts is derived. However, there is no way to "serialize" the chain of actions into a reusable function for later use, i.e., bringing it into production. Consequently, users must start from scratch of development each time they want to solve a problem. This inefficiency wastes time and money and presents an unrealistic expectation compared to how we approach problem-solving in the real world.
Unfortunately, Auto-GPT's current implementation does not allow this separation of development and production. It cannot "serialize" the chain of actions into a reusable function, forcing users to pay the full $14.4 again for a seemingly minor change in requirements. This economic inefficiency raises questions about the practicality of Auto-GPT in real-world production environments. It underscores its limitations in providing a sustainable and cost-effective solution for large problem-solving.
tagThe Looping Quagmire: Why Auto-GPT Gets Stuck
You might think that if $14.4 can genuinely solve a problem, then it's still worth it. However, many users have reported that Auto-GPT frequently gets stuck in a loop, rendering it unable to solve real problems. Several tweets reveal instances where Auto-GPT remained stuck in a loop even after an entire night of processing chains of thought. These cases highlight the reality that, in many situations, Auto-GPT cannot provide the solution it promises.
So I used it multiple times yesterday and here’s what I found… it never completes a task. It just always finds reasons to dig deeper and do more research. It never gets to a point to where it actually completes a single goal requested. I let it go for hours. Lol 😂
— Timothy Alan (@_timothyalan_) April 13, 2023
tagWhy does Auto-GPT get stuck in these loops?
To understand this, one can think of Auto-GPT as relying on GPT to utilize a very simple programming language to solve tasks. The success of solving a task depends on two factors: the range of functions available in that programming language and the divide-and-conquer ability of GPT, i.e. how well GPT can decompose the task into the predefined programming language. Unfortunately, both of these factors are currently inadequate.
The limited functions provided by Auto-GPT can be observed in its source code. For example, it offers functions for searching the web, managing memory, interacting with files, executing code, and generating images. However, this restricted set of functions narrows the scope of tasks Auto-GPT can perform effectively. Additionally, the decomposition and reasoning abilities of GPT are still constrained. Although GPT-4 has significantly improved over GPT-3.5, its reasoning capability is far from perfect, further limiting Auto-GPT's problem-solving capacities.
TorantulinoThis situation is similar to trying to build a complex game like StarCraft using Python. While Python is a powerful language, decomposing StarCraft into Python functions is extremely challenging. Alternatively, it's like attempting to create an instant messaging app using BASIC, a language lacking the necessary network communication functions. In essence, the combination of a limited function set and GPT-4's constrained reasoning ability results in a looping quagmire that prevents Auto-GPT from delivering the expected outcomes in many cases.
tagHuman vs. GPT on divide-and-conquer
Divide-and-Conquer is the key to Auto-GPT. While GPT-3.5/4 has shown significant advancements over its predecessors, it still falls short of human-level reasoning capabilities when employing divide-and-conquer techniques. Challenges such as inadequate problem decomposition, difficulty in identifying appropriate base cases, and the lack of adaptability and learning all contribute to the limitations of GPT-3.5/4 in solving complex problems using divide-and-conquer methods.
- Inadequate problem decomposition: The effectiveness of a divide-and-conquer approach largely depends on the ability to break down complex problems into smaller, manageable subproblems. GPT-3.5/4, despite its improvements, still struggles to consistently and effectively decompose problems in a manner that allows for efficient and accurate solutions. Human reasoning can often identify multiple ways to decompose a problem, while GPT-3.5/4 may not have the same level of adaptability or creativity.
- Difficulty in identifying appropriate base cases: Humans can intuitively choose appropriate ones that lead to efficient solutions. In contrast, GPT-3.5/4 may struggle to identify the most effective base cases for a given problem, which can significantly impact the overall efficiency and accuracy of the divide-and-conquer process.
- Insufficient understanding of problem context: While humans can leverage their domain knowledge and contextual understanding to tackle complex problems better, GPT-3.5/4 is limited by its pre-trained knowledge and may lack the necessary context to efficiently solve certain problems using divide-and-conquer techniques.
- Handling overlapping subproblems: Humans can often recognize when solving overlapping subproblems and strategically reuse previously computed solutions. GPT-3.5/4, on the other hand, may not always have the same level of awareness and may end up redundantly solving the same subproblems multiple times, leading to inefficient solutions.
tagThe Vector DB: An Overkill Solution
Auto-GPT relies on vector databases for faster k-nearest neighbor (kNN) searches. These databases retrieve earlier chains of thoughts, incorporating them into the current query context for GPT to provide a memory effect. However, given Auto-GPT's constraints and limitations, this approach has been criticized as excessive and unnecessarily resource-intensive.
TorantulinoThe main argument against using vector databases stems from the cost constraints associated with Auto-GPT's chain of thoughts. A 50-step chain of thoughts would cost 14.4 dollars, while a 1000-step chain would cost significantly more. As a result, the memory size or length of the chain of thought rarely exceeds four digits. In such cases, an exhaustive search (i.e., the dot product between a 256-dim vector and a 10,000 x 256 matrix) for the nearest neighbor proves to be sufficiently efficient, taking less than one second to complete. In contrast, each GPT-4 call takes approximately 10 seconds to process, making the system GPT-bound rather than database-bound.

Although vector databases may offer some advantages in specific scenarios, their implementation within the Auto-GPT system for accelerating kNN "long memory" searches appears to be an unnecessary extravagance and an overkill solution. The primary justification for using vector databases in this context seems to be the user-friendly sugar syntax available out-of-the-box.
tagThe Birth of Agent Mechanisms: A Work in Progress
Auto-GPT introduces a very intriguing concept by allowing the spawning of agents to delegate tasks. However, this mechanism is still in its early stages, and its potential remains largely untapped. There are several ways to enhance and expand upon the current agent system, opening up new possibilities for more efficient and dynamic interactions.
One potential improvement is the introduction of asynchronous agents. By incorporating async-await patterns, agents can operate concurrently without blocking one another, significantly improving the overall efficiency and responsiveness of the system. This concept draws inspiration from modern programming paradigms that have adopted asynchronous methods to manage multiple tasks simultaneously.
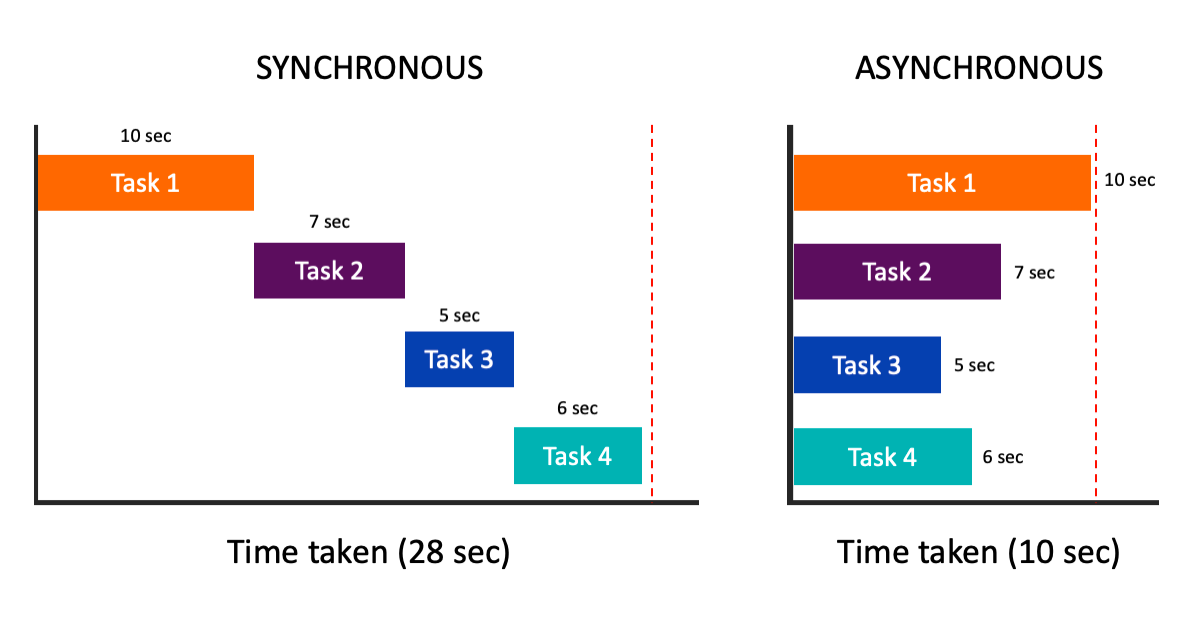
Another promising direction is enabling intercommunication between agents. By allowing agents to communicate and collaborate, they can work together to solve complex problems more effectively. This approach resembles the concept of IPC in programming, where multiple threads/processes can share information and resources to achieve a common goal.
tagGenerative agents are the future
As the GPT-powered agent continues to evolve, the future seems bright for this innovative approach. New research, such as the paper "Generative Agents: Interactive Simulacra of Human Behavior" by Park et al., highlights the potential of agent-based systems in simulating believable human behavior. Generative agents, as proposed in the paper, can interact in complex and engaging ways, forming opinions, initiating conversations, and even autonomously planning and attending events. This work further supports the argument that agent mechanisms have a promising future in AI development.
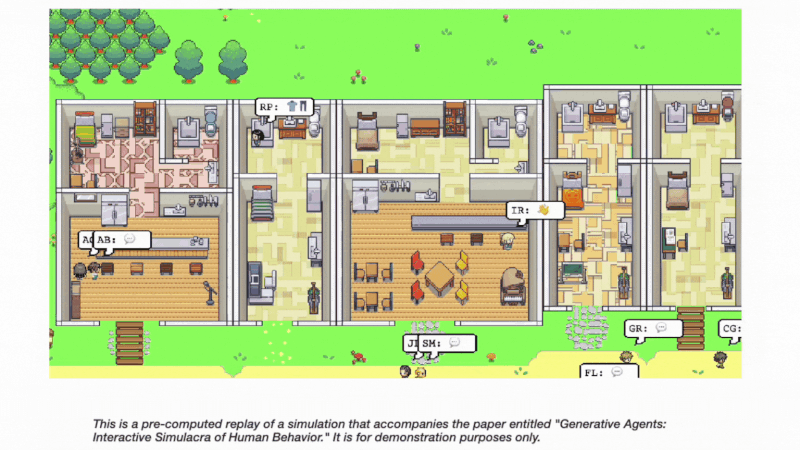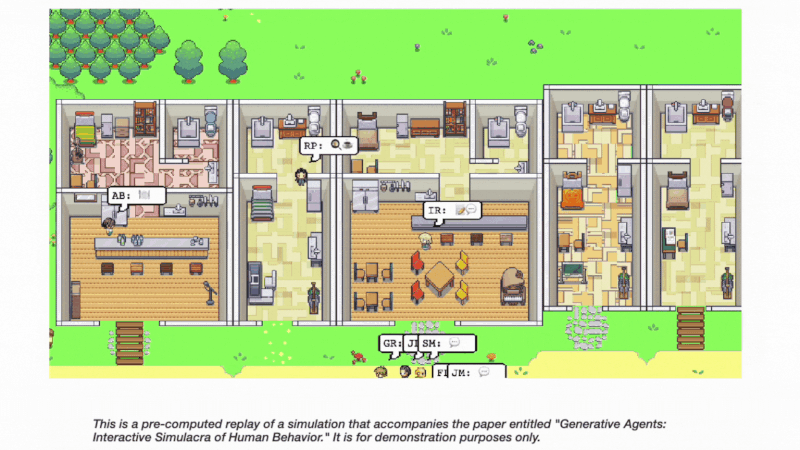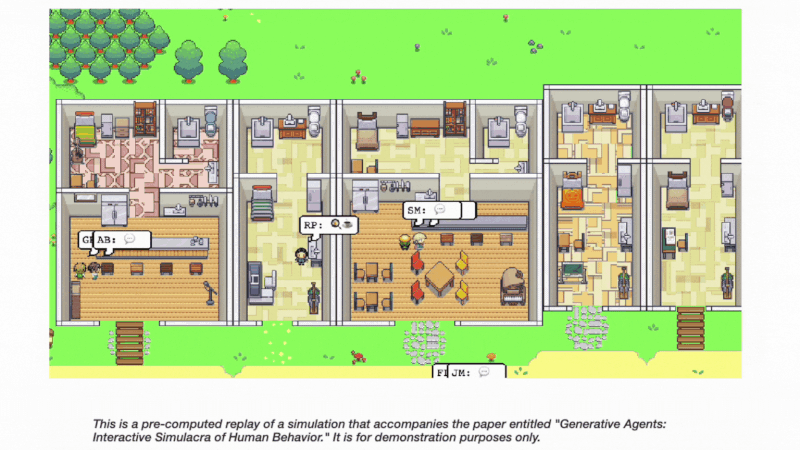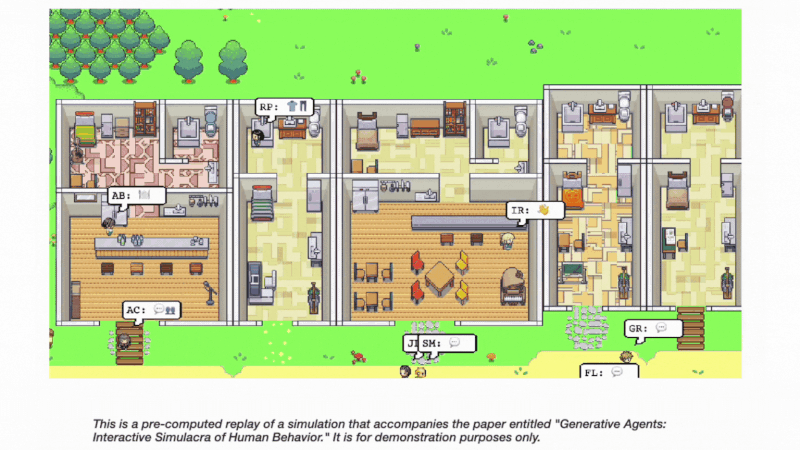
Auto-GPT can unlock new possibilities for more efficient and dynamic problem-solving capabilities by embracing the paradigm shift towards asynchronous programming and fostering inter-agent communication. Incorporating the architectural and interaction patterns introduced in the "Generative Agents" paper can lead to a fusion of large language models with computational, interactive agents. This combination has the potential to revolutionize how tasks are delegated and executed within AI frameworks and enable more believable simulations of human behavior. The development and exploration of agent systems can contribute significantly to advancing AI applications, providing more robust and dynamic solutions to complex problems.
tagConclusion
In conclusion, the buzz surrounding Auto-GPT raises important questions about the state of AI research and the role of public understanding in driving hype around emerging technologies. As we have demonstrated, Auto-GPT's limitations in reasoning capabilities, the overkill use of vector databases, and the early-stage development of agent mechanisms reveal that it is far from being a practical solution. Yet, it has managed to capture the general public's imagination, who may lack a deep understanding of its inner workings.
The hype around Auto-GPT serves as a sobering reminder of how shallow understanding can lead to inflated expectations, ultimately culminating in a distorted perception of AI's true capabilities. As a society, we must be vigilant in questioning the narratives that surround emerging technologies and strive to foster critical thinking and informed discussions.
That said, Auto-GPT does point to a promising direction for the future of AI: generative agent systems. As we move forward, let us learn from the lessons of the Auto-GPT hype and focus on nurturing a more nuanced and informed dialogue around AI research. By doing so, we can harness the transformative power of generative agent systems and continue to push the boundaries of AI capabilities, shaping a future where technology truly benefits humanity.
