


In the modern digital age, the line between visuals and the stories they convey is becoming increasingly blurred. SceneXplain has consistently been at the forefront of this transformation, setting new standards in visual comprehension. Starting with innovations in image-to-text and image-to-audio generations, we've now extended our expertise into the intricate realm of video-to-text! This natural progression marks our latest endeavor, the Inception algorithm.

The power of video, with its dynamic interplay of images and sequences, captures narratives that are often richer and deeper than static images. Yet, unlocking these narratives remains a challenge. Here's where SceneXplain steps in. By leveraging advanced multimodal AI techniques, our platform doesn't merely provide superficial descriptions; it delves deeper to unearth and articulate the stories that unfold within videos. Beyond mere captions, SceneXplain strives for contextual understanding, ensuring each narrative is captured with the depth it deserves.
Developers and enterprises alike will find value in our system. Not only does SceneXplain bring sophisticated video storytelling tools to the table, but its seamless interface and adaptable API ensure that integrating these tools into your platforms or systems is as smooth as possible.
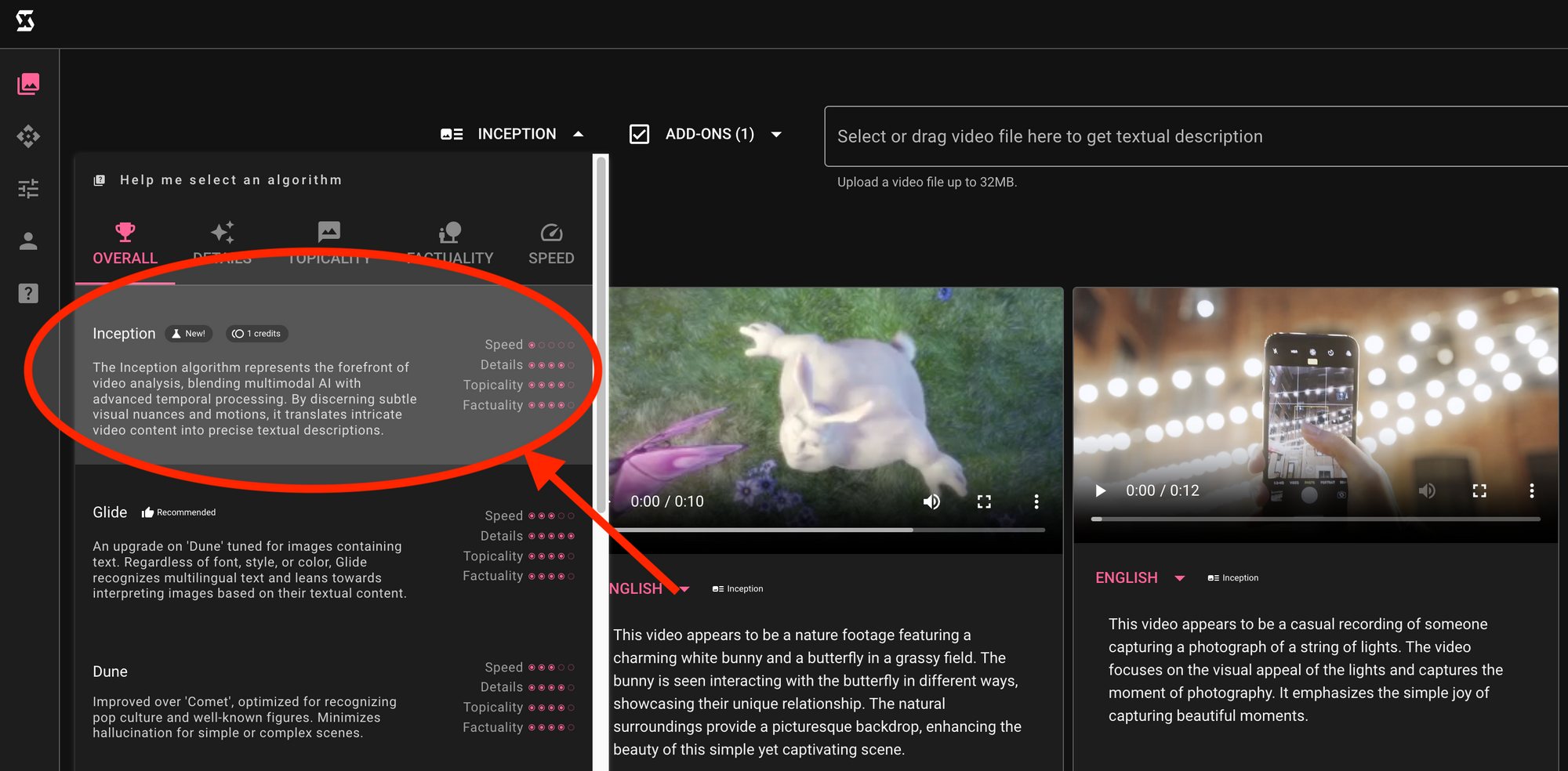
Join us as we dive deeper into the inception of the "Inception" algorithm and explore how it’s setting new paradigms in the world of video comprehension.
tagThe Imperative of Video-to-Text Comprehension in a Visual-First Digital Age
In our digital epoch, the proliferation of visual content has outpaced almost every other medium. Videos, in particular, have mushroomed into the bedrock of content consumption. From short-form social media clips to extensive webinars, the digital ecosystem is awash with moving pixels. And while the explosion of video content signals a seismic shift in how information is shared and consumed, it also presents an intricate challenge: the sheer volume of content and the immediacy of its consumption.
tagThe Search Dilemma: From Pixels to Text
Think about it. Every video that gets uploaded is, in essence, a repository of information. But how do search engines understand them? Unlike text, videos don’t lend themselves easily to the parsing and indexing mechanisms that power the modern web. This is where video-to-text transcends from a luxury to a necessity. Translating videos into text allows search engines to index, categorize, and rank them, making content not just accessible but discoverable.
tagThe Skim Economy: Catering to the Impatient User
Today’s user is not the reader of yesteryears; they're skimmers and scanners. Not everyone has the time (or inclination) to sit through a 30-minute video. A textual summary, however, can be skimmed in mere minutes. Video comprehension caters to this very demographic, ensuring content remains consumable for the fast-paced digital nomad.
 Maryanne Wolf
Maryanne Wolf
tagAccessibility: Bridging the Gap
A core tenet of the modern web is inclusivity. While videos are an excellent medium for many, they inadvertently sideline those with visual or auditory impairments. Converting videos to text ensures that content is universally accessible, not just to a select few. Interested readers are strongly recommended to follow our efforts in using SceneXplain to improve digital accessibility in the EU.

tagThe Content Overload: Making Sense of the Digital Deluge
Every minute, 500 hours of video are uploaded to platforms like YouTube. In this sea of content, how does one discern value? Automatic video comprehension can help platforms curate and recommend, ensuring users find not just any content, but relevant content.
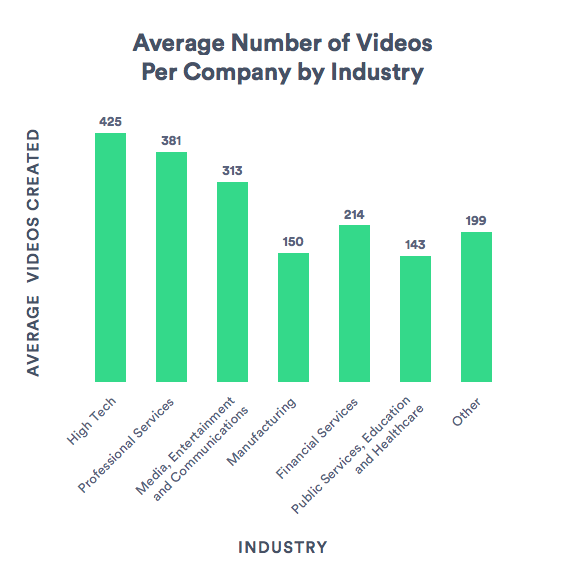
The pressing need for video comprehension or video-to-text techniques is not just about keeping pace with technological advancements; it's about shaping the future of content consumption. In an increasingly visual-first digital realm, understanding and articulating the stories within videos isn't just desirable — it's imperative.
tagDelving into the Mathematics of Video Comprehension
The modern quest to elucidate video content's narrative essence can be likened to the pursuit of converting a rich tapestry of visual sequences into coherent textual symphonies. To embark on this journey, we must first define our problem in a precise mathematical manner.
Given a video , comprising a series of frames , our aim is to transform it into a series of textual descriptions or a summary , such that where .
At the heart of this transformation lies the relationship between each frame and its corresponding summary statement . Using Bayesian probabilistic notation, we can express this relationship as the conditional probability . However, given the sequential nature of videos, it's often the case that a summary statement is conditioned on a sequence of frames rather than an individual frame.
Thus, we extend our probability notation to consider a window of frames, leading to:
Where represents the length of the frame window that influences the summary statement .
Our objective function then aims to maximize the likelihood of our entire summary given the video :
This formulation elegantly captures the essence of video comprehension — weaving a textual narrative from a series of interlinked visual frames, while also accounting for the inherent continuity and interdependence of video content.
In this probablistic framework, our task not only becomes clearer but also lays the foundation for the development of algorithms, like Inception, that can effectively tackle the intricate nuances of the video-to-text conversion process.
tagTackling the Challenges: Keyframes, Context, and Coherence
In our earlier discussion on the mathematical framework of video comprehension, we highlighted the importance of a narrative continuum and the sequential dependence of frames. This context is vital in comprehending how we approach keyframe insights and descriptions.
tagThe Keyframe Conundrum: Coherence Over Quantity
A consistent series of keyframe insights ensures that the video's narrative essence remains undistorted. However, inconsistency in keyframes' details introduces fragmentation, leading to a disjunctive understanding where the context is lost. Instead of a clear narrative thread, you're left with disconnected vignettes, robbing the video of its richness and continuity.
The most direct approach would be to ascertain the "optimal" number of keyframes, capturing the essence without diluting the narrative. But what's optimal for a fast-paced action clip might differ from an introspective documentary. Additionally, the descriptions for each keyframe should be succinct yet sufficiently detailed to relay the frame's narrative weight.
tagTowards an Adaptive Framework: Balancing Details and Density
Defining the "right" balance of keyframes and the granularity of their descriptions is a nuanced challenge, with variances across video genres and styles. Taking a probabilistic stance, as per our Bayesian framework, the challenge boils down to maximizing the likelihood of our summarized content given the original video, while maintaining a controlled description density.
SceneXplain's base video summarization algorithm pragmatically navigates this challenge. Built on the principle that "overloading with details can be more detrimental than being minimally informative," we've capped the keyframes to a maximum of 6 per minute and limited caption lengths to 20 words. This ensures clarity without overburdening the viewer, offering a distilled yet coherent narrative.
tagThe Road Ahead: Dynamic Adaptations
Recognizing the dynamic nature of videos and their myriad styles, SceneXplain is also committed to evolving its constraints. Future iterations are primed to make these metrics tunable, adapting to the unique requirements of different content, thus maintaining the Bayesian foundation of context and sequence.
tagDemonstrating SceneXplain: A Deep Dive into Inception's Excellence
As we transition from the theoretical framework and the challenges we navigated to bring SceneXplain to life, it's time to dive into its practical performance. Words, equations, and design philosophies can only convey so much — it's in the real-world application that an algorithm truly proves its mettle. And our Inception algorithm stands tall when subjected to the rigorous tests of Topicality, Details, and Factuality.
tagDetails: Not Just What Meets the Eye
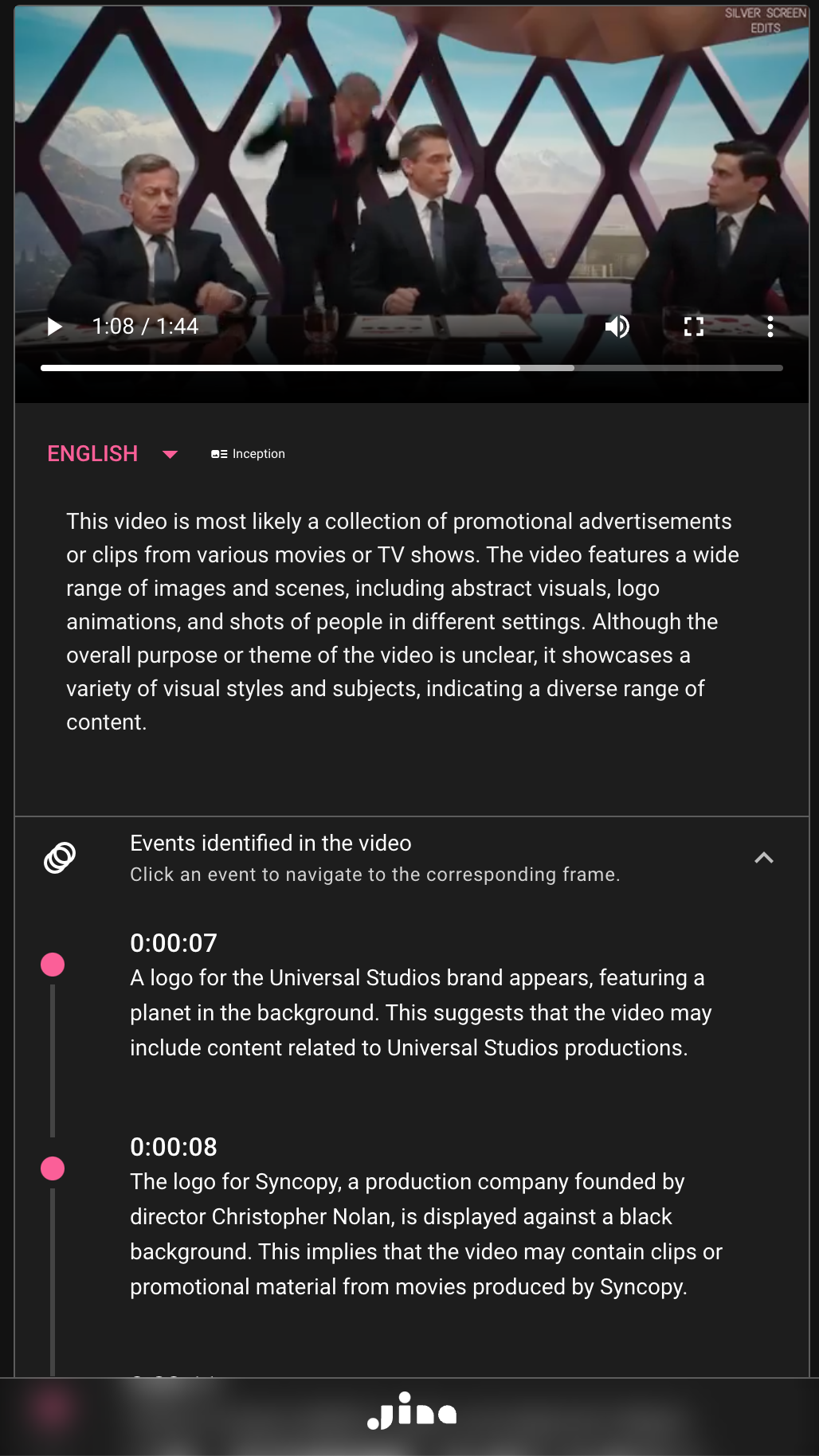
Every frame of a video carries an expansive depth of information — from the nuanced expressions of a character to the intricate patterns on a distant artifact. Inception's prowess lies in not merely recognizing these myriad details but artfully weaving them into coherent and engaging narratives. Our demo showcases scenes replete with complexity and depth, and Inception's ability to encapsulate each facet, validating its unparalleled performance in capturing intricate visual information.
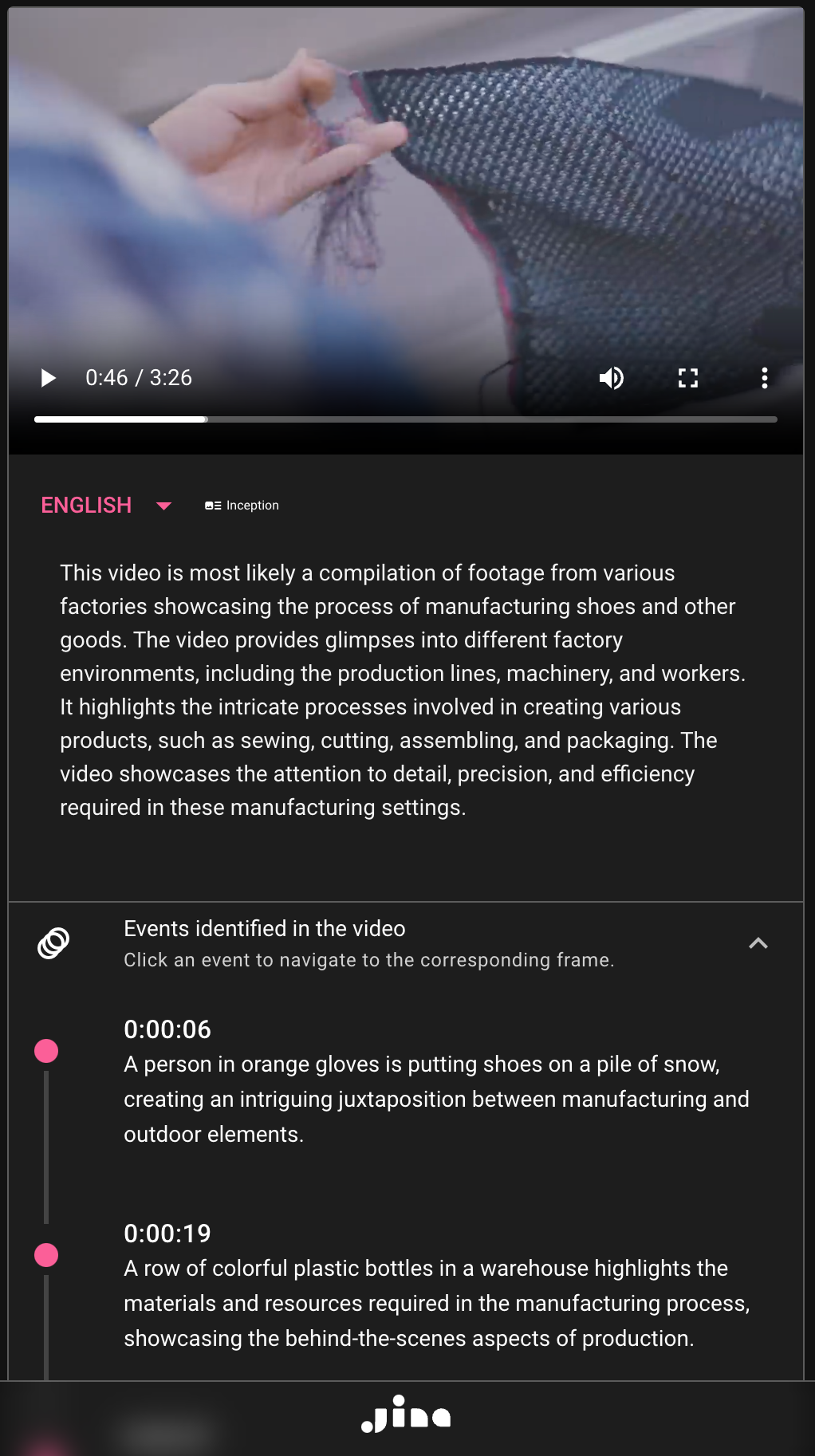
tagTopicality: Finger on the Pulse
In an age where information flows at breakneck speed and cultural contexts evolve almost daily, it's paramount for an algorithm to remain current and contextual. SceneXplain, powered by Inception, goes beyond just visually describing content. Whether it's referencing a recent global event, alluding to a trending meme, or identifying a breakout celebrity, our algorithm ensures that the generated captions resonate with what's topical, relevant, and engaging. Dive into our demos, and witness how Inception connects the visual narratives with the contemporary cultural zeitgeist.
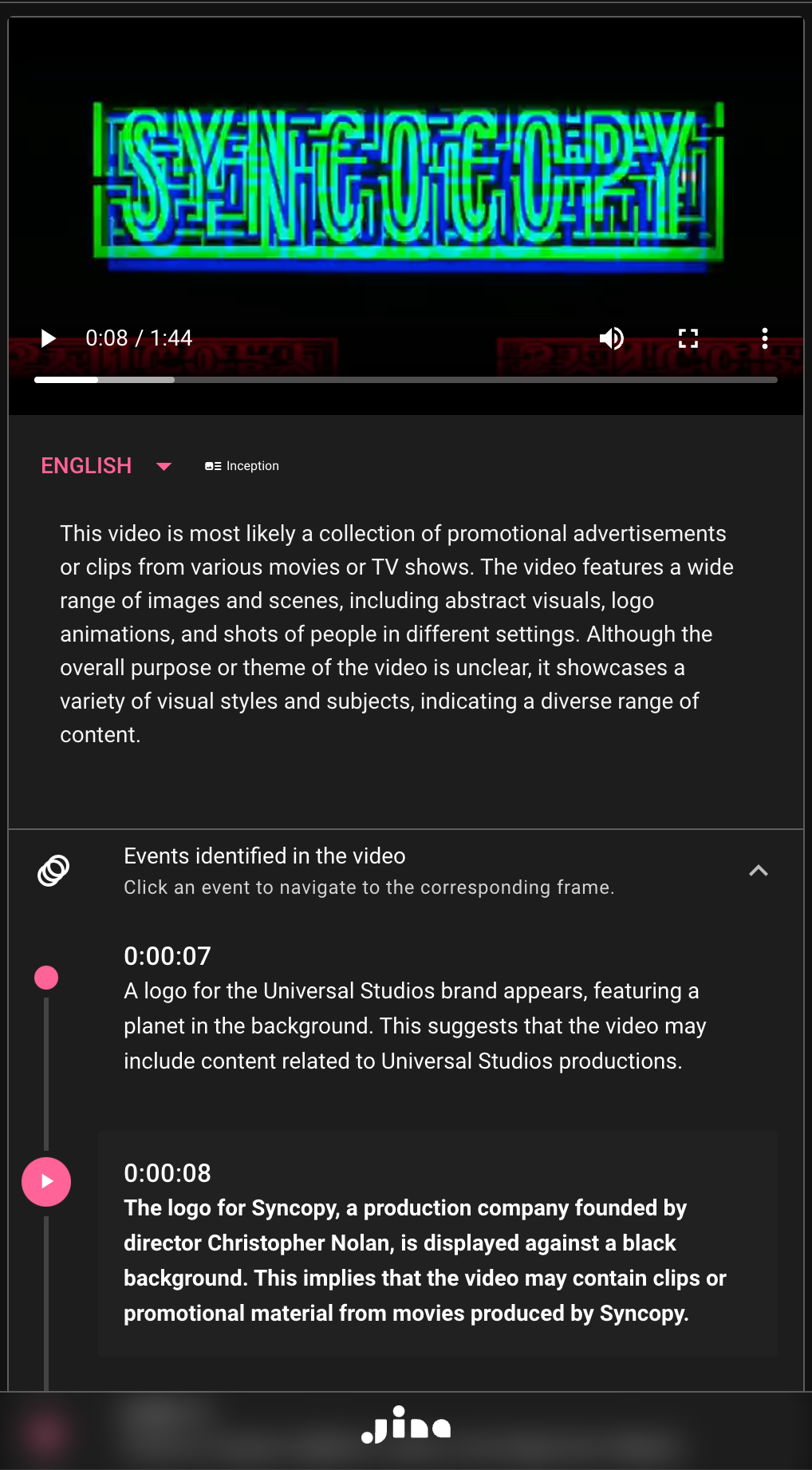
tagFactuality: The Bedrock of Trust
While creativity and engagement are crucial, they should never come at the expense of truthfulness. A tool like SceneXplain holds immense responsibility in ensuring the information it disseminates is accurate. Inception has been crafted with an unwavering commitment to factuality. Every caption it produces is meticulously vetted for accuracy, minimizing hallucinations and misinformation. Our demonstrations will highlight scenes where it's tempting for algorithms to falter, to extrapolate beyond what's present — but Inception stands firm, delivering trustworthy descriptions consistently.
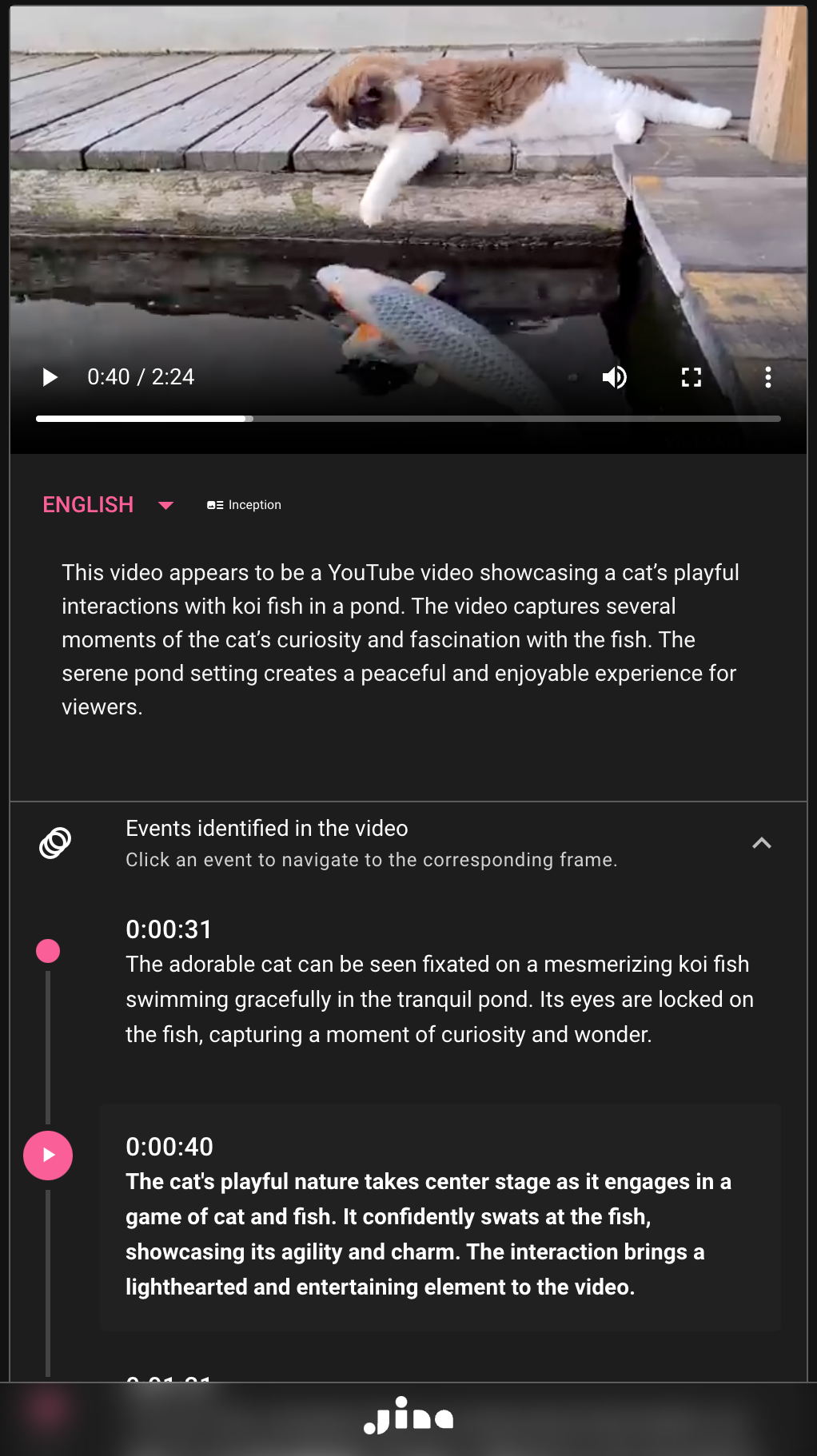
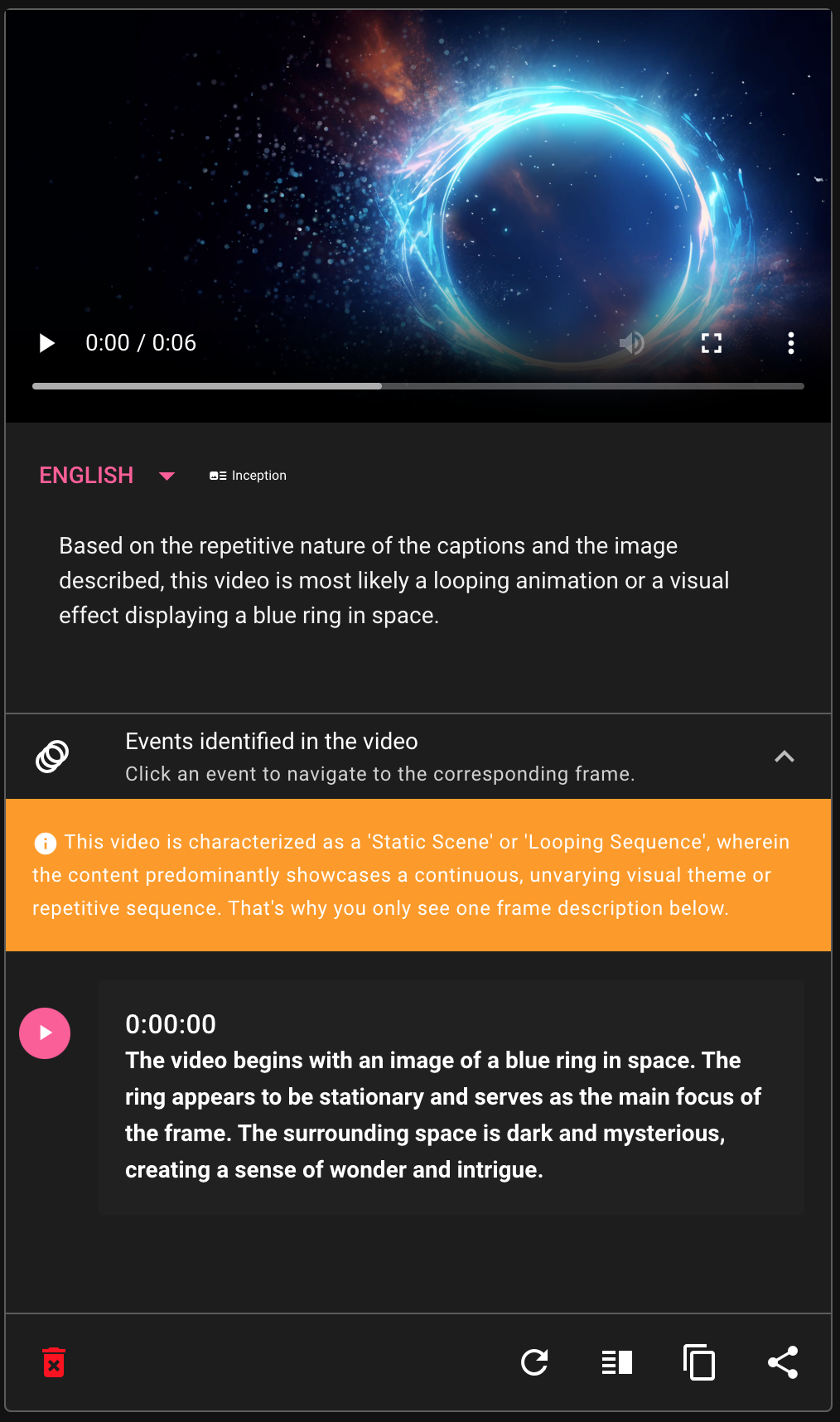
More examples can be found below:
- https://scenex.jina.ai/share?thread=mFme4ygBpTOkSzpGEDBT
- https://scenex.jina.ai/share?thread=RuXPznfRGNtqdKJuJVQl
- https://scenex.jina.ai/share?thread=EWJcZuS3FpcKJ9AyRq9i
tagKnown Limitations of the Inception Algorithm: Embracing Transparency and Ethical Responsibility
In the era of machine learning, it's tempting to herald algorithms as faultless, all-seeing entities. At SceneXplain, however, we firmly believe that recognizing and addressing an algorithm's limitations is just as important as celebrating its capabilities. As stewards of technology with potential societal impact, we bear the ethical responsibility of being transparent about the bounds of our creations. Here, we outline some of the known limitations of the Inception algorithm, allowing users to deploy it with a complete understanding of its scope.
tagChallenges with Keyframe Detection
- Small Region Of Interest (ROI): In videos taken from a considerable distance without significant movement, the ROI is minimal. This can trip up similarity detection algorithms, causing them to perceive all frames as alike. A potential consequence? A 5-minute video might yield just 1 or 2 keyframes, translating to significant content loss.
- Proliferation of Scenes: Videos with rapid scene changes, like movie trailers, pose unique challenges. A sub-3-minute trailer could contain over a hundred disparate scenes, leading to a glut of keyframes. This not only increases the computational burden but also risks omitting crucial scenes when we apply a "max keyframe ratio per minute" filter.
- Artistic Interpretations: Videos with specific artistic styles, such as macro shots, time-lapses, or drone footage, defy conventional detection paradigms. Depending on zoom levels and playback speed, these could either produce an overabundance of keyframes or too few.
tagNuances in Keyframe Captioning
- Contextually Dependent Frames: Frames that are abstract or hinge on an external context can confound the algorithm. This leads to captions that range from slightly off-kilter to downright nonsensical. Computationally generated images, extreme zoom-ins, or artistic interpretations are classic culprits.
- Detecting Subtly Erroneous Captions: If a caption, while incorrect, aligns with the general context of the video, spotting such errors becomes challenging.
- Detail Disproportionality: A minor video element that's densely detailed might be accorded undue prominence over the main subject if it's relatively simpler. This can skew the narrative thread.
- Insufficient Details, Incorrect Associations: A recurring element across several keyframes, if not detailed enough, might be misinterpreted. For instance, the same individual appearing across multiple frames could be erroneously recognized as multiple people.
Our commitment to transparency and continual improvement means we're always working on these challenges. However, we believe that only by acknowledging these limitations can we truly leverage the Inception algorithm ethically and responsibly.
tagIn Conclusion: The Journey and the Invitation
The landscape of video comprehension has been evolving at a dizzying pace, and at SceneXplain, we're excited to be at the forefront of this revolution with our Inception algorithm. From understanding the nuances of complex narratives to grappling with the intricacies of contemporary culture, Inception promises a transformative experience in video-to-text translation.
However, as with all pioneering technologies, it's not without its challenges. We've approached these not as setbacks, but as opportunities for growth and refinement. Our transparency in sharing these challenges stems from a commitment to ethical and responsible AI development.
But, words can only convey so much. The true power and potential of Inception is best experienced firsthand. We invite you to try SceneXplain's Inception algorithm for yourself. Dive deep into its capabilities, test its boundaries, and witness how it can redefine your understanding of visual narratives.
The future of video comprehension beckons, and with SceneXplain's Inception, you're not just a spectator – you're a part of the narrative. Come, join the story.







