


Back in the day, pre-Google, the Internet was mostly text. Whether it was news updates, sports scores, blog posts or emails, ASCII and Unicode were the way to go.
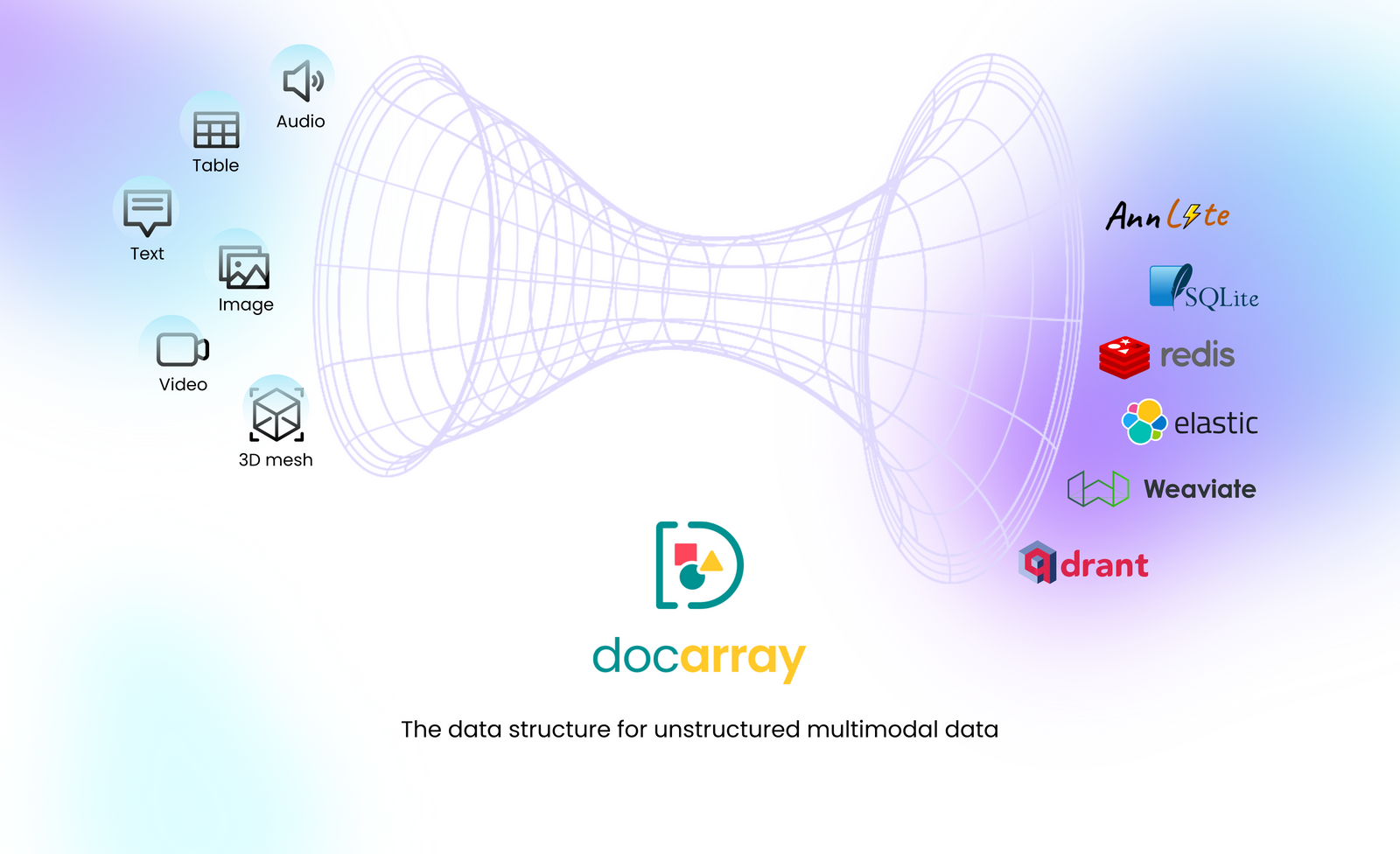
But nowadays, data is becoming increasingly complex and multimodal, mostly coming in unstructured forms such as images, videos, text, 3D mesh, etc. Gone are the days of being limited to 26 characters and 10 numbers (or more for other character sets). Now there’s much more stuff to deal with.
Just think about your favorite YouTube videos, Spotify songs, or game NPCs.
Typical databases can’t handle these kinds of multimodal data. They can only store and process structured data (like simple text strings or numbers). This really limits our ability to extract valuable business insights and value from a huge chunk of the 21st century's data.
Lucky for us, recent advancements in machine learning techniques and approximate nearest neighbor search have made it possible to better utilize unstructured data:
- Deep learning models and representation learning to effectively represent complex data using vector embeddings.
- Vector databases leverage vector embeddings to store and analyze unstructured data.
tagWhat are vector databases?
A vector database is a type of database that can index and retrieve data using vectors, similar to how a traditional database uses keys or text to search for items using an index.
A vector database uses a vector index to enable fast retrieval and insertion by a vector, and also offers typical database features such as CRUD operations, filtering, and scalability.
This gives us the best of both worlds - we get the CRUDiness of traditional databases, coupled with the ability to store complex, unstructured data like images, videos, and 3D meshes.
So, vector databases are great, right? What’s even more awesome is having a library to use them all while being capable of handling unstructured data at the same time! One unstructured data library to rule them all!
We are, of course, talking about DocArray. Let’s see what this project is all about.


tagDocArray's universal Pythonic API to all vector databases
As the description suggests on the project home page, DocArray is a library for nested, unstructured and multimodal data.
This means that if you want to process unstructured data and represent it as vectors, DocArray is perfect for you.
DocArray is also a universal entrypoint for many vector databases.
For the remainder of this post, we’ll be using DocArray to index and search data in the Amazon Berkeley Objects Dataset. This dataset contains product items with accompanying images and metadata such as brand, country, and color, and represents the inventory of an e-commerce website.
Although a traditional database can perform filtering on metadata, it is unable to search image data or other unstructured data formats. That’s why we’re using a vector database!
We’ll start by loading a subset of the Amazon Berkeley Objects Dataset that comes in CSV format into DocArray and computing vector embeddings.

Then, we'll use DocArray with each database to perform search and insertion operations using vectors.
We’ll use the following databases via DocArray in Python:
- Milvus - cloud-native vector database with storage and computation separated by design
- Weaviate - vector search engine that stores both objects and vectors and can be accessed through REST or GraphQL
- Qdrant - vector database written in Rust and designed to be fast and reliable under high loads
- Redis - in-memory key-value database that supports different kinds of data structures with vector search capabilities
- ElasticSearch - distributed, RESTful search engine with Approximate Nearest Neighbor search capabilities
- OpenSearch - open-source search software based on Apache Lucene originally forked from ElasticSearch
- AnnLite - a Python library for fast Approximate Nearest Neighbor Search with filtering capabilities
For each database, we’ll:
- Setup the database and install requirements
- Index the data in the vector database
- Perform a vector search operation with filtering
- Display the search results
tagPreparing the data
First, we’ll install a few dependencies, namely DocArray, Jina (for cloud authentication), and the client for CLIP-as-service (for generating embeddings):
pip install docarray[common] jina clip-clientLet’s download a sample CSV dataset and load it into a DocumentArray with DocumentArray.from_csv():
wget https://github.com/jina-ai/product-recommendation-redis-docarray/raw/main/data/dataset.csvfrom docarray import DocumentArray, Document
with open('dataset.csv') as fp:
da = DocumentArray.from_csv(fp)We get an overview using the summary() method:
╭────────────────────── Documents Summary ──────────────────────╮
│ │
│ Type DocumentArrayInMemory │
│ Length 5809 │
│ Homogenous Documents True │
│ Common Attributes ('id', 'mime_type', 'uri', 'tags') │
│ Multimodal dataclass False │
│ │
╰───────────────────────────────────────────────────────────────╯
╭───────────────────── Attributes Summary ─────────────────────╮
│ │
│ Attribute Data type #Unique values Has empty value │
│ ────────────────────────────────────────────────────────── │
│ id ('str',) 5809 False │
│ mime_type ('str',) 1 False │
│ tags ('dict',) 5809 False │
│ uri ('str',) 4848 False │
│ │
╰──────────────────────────────────────────────────────────────╯We can also display the images of the first few items using the plot_image_sprites() method:
da[:12].plot_image_sprites()
Each product contains the metadata as a dict in the tags attribute:
da[0].tags{'height': '1926',
'color': 'Blue',
'country': 'CA',
'width': '1650',
'brand': 'Thirty Five Kent'}tagGenerating embeddings
Next, we’ll encode the Documents into vectors using Clip-as-service.
First, we need to log in to Jina AI Cloud:
jina auth loginLet’s create an authentication token to use the service:
jina auth token create abo -e 30Then, we can actually use the service to generate embeddings:
from clip_client import Client
c = Client(
'grpcs://api.clip.jina.ai:2096', credential={'Authorization': 'your-auth-token'}
)
encoded_da = c.encode(da, show_progress=True)tagPreparing a search Document
If we’re going to search our database, we need something to search our database with. As with everything in DocArray, the fundamental unit is the Document. So let’s prepare a query Document to search with. We’ll just select the first product in our dataset:
doc = encoded_da[0]
doc.display()tagIndexing the data
Now that the data is ready, we can index it and start performing search queries. In the next sections, we will index with each supported database.
tagMilvus
Milvus is an open-source vector database built to power embedding similarity search and AI applications. It is a cloud-native database with storage and computation separated by design.
This means that scaling each layer individually is possible. Thus, Milvus offers a scalable and reliable architecture.
Start a Milvus service using the following YAML:
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.0
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2022-03-17T06-34-49Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.1.4
command: ["milvus", "run", "standalone"]
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
networks:
default:
name: milvusdocker-compose upThen, create a DocumentArray instance connected to Milvus. Make sure to install DocArray using the milvus tag:
pip install "docarray[milvus]"milvus_da = DocumentArray(storage='milvus', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
with milvus_da:
milvus_da.extend(encoded_da)Now, make a search query for items similar to doc with filter color='Blue':
filter = 'color == "Blue"'
results = milvus_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
Being part of LFAI & Data, Milvus represents a production-ready cloud-native vector database.
Read more about Milvus support in DocArray:
tagWeaviate
Weaviate is an open source vector search engine that stores both objects and vectors, allowing for combining vector search with structured filtering.
It offers features like fault-tolerance and scalability and is accessible either through REST or GraphQL.
Start a Weaviate server using the following YAML:
version: '3.4'
services:
weaviate:
command:
- --host
- 0.0.0.0
- --port
- '8080'
- --scheme
- http
image: semitechnologies/weaviate:1.16.1
ports:
- "8080:8080"
restart: on-failure:0
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'none'
ENABLE_MODULES: ''
CLUSTER_HOSTNAME: 'node1'docker-compose upThen, create a DocumentArray instance connected to Weaviate. Make sure to install DocArray using the weaviate tag:
pip install "docarray[weaviate]"weaviate_da = DocumentArray(storage='weaviate', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'product_type': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
weaviate_da.extend(encoded_da)Now, make a search query for items similar to doc with filter color='Blue' :
filter = {'path': 'color', 'operator': 'Equal', 'valueString': 'Blue'}
results = weaviate_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
Therefore, Weaviate offers vector search functionalities with filtering support and features like replication, hybrid search, dynamic batching, etc
Read more about Weaviate integration in DocArray:
tagQdrant
Qdrant is an open source vector database. Written in Rust and offering a fast and reliable search experience even under high load. Actually, it ranks in DocArray’s one million benchmarks as the fastest on-disk vector database (As of the versions used to conduct the experiment).
Qdrant comes with filtering support and a convenient API using HTTP or gRPC.
Start a Qdrant server using the following YAML:
version: '3.4'
services:
qdrant:
image: qdrant/qdrant:v0.10.1
ports:
- "6333:6333"
- "6334:6334"
ulimits: # Only required for tests, as there are a lot of collections created
nofile:
soft: 65535
hard: 65535docker-compose upThen, create a DocumentArray instance connected to Qdrant. Make sure to install DocArray using the qdrant tag:
qdrant_da = DocumentArray(storage='qdrant', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'product_type': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
qdrant_da.extend(encoded_da)Now, make a search query for items similar to doc with filter color='Blue':
filter = {'must': [{'key': 'color', 'match': {'value': 'Blue'}}]}
results = qdrant_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
Qdrant offers a fast and reliable search service. It supports filtering and vector search at scale.
Its gRPC support also makes it convenient for indexing in batches since indexing datasets with gRPC is much faster than using the HTTP protocol.
Read more about the Qdrant integration in DocArray:
tagRedis
Redis is an open source in-memory key-value database. Redis supports different kinds of data structures and provides access using a set of commands using TCP sockets.
In its RediSearch module 2.4, Redis added vector search capabilities. This means Redis can be viewed as an in-memory vector database.
Start a Redis server using the following YAML:
docker run -d -p 6379:6379 redis/redis-stack:latestThen, create a DocumentArray instance connected to Redis. Make sure to install DocArray using the `redis` tag:
pip install "docarray[redis]"redis_da = DocumentArray(storage='redis', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'product_type': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
redis_da.extend(encoded_da)Now, make a search query for items similar to doc with filter color='Blue':
filter = '@color:Blue'
results = redis_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
Redis, since it’s an in-memory store, offers faster search queries compared to on-disk databases. It ranks in DocArray’s one million benchmarks as the fastest database server.
Use it if you need fast vector search and operations to a vector database while being able to index data in-memory.
Read more about the Redis integration in DocArray:
tagElasticSearch
ElasticSearch is an open-source, distributed and RESTful search engine. It can be used to search, store and manage data.
This means that any ElasticSearch Server with version > 8.0 has vector search capabilities.
Start an ElasticSearch server using the following YAML:
version: "3.3"
services:
elastic:
image: docker.elastic.co/elasticsearch/elasticsearch:8.2.0
environment:
- xpack.security.enabled=false
- discovery.type=single-node
ports:
- "9200:9200"
networks:
- elastic
networks:
elastic:
name: elasticdocker-compose upThen, create a DocumentArray instance connected to ElasticSearch. Make sure to install DocArray using the elasticsearch tag:
pip install "docarray[elasticsearch]"elasticsearch_da = DocumentArray(storage='elasticsearch', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'product_type': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
elasticsearch_da.extend(encoded_da, request_timeout=60)Now, make a search query for items similar to doc with filter color='Blue':
filter = {'match': {'color': 'Blue'}}
results = elasticsearch_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
ElasticSearch is convenient for production use cases. It offers features like scalability, data distribution, filtering, hybrid search, etc. It comes with security, observability, and cloud-nativeness.
Read more about ElasticSearch integration in DocArray:
tagOpenSearch
OpenSearch is a scalable, flexible, and extensible open-source program for search, licensed under Apache 2.0.
OpenSearch is powered by Apache Lucene and was originally forked from ElasticSearch. This means OpenSearch includes most features of ElasticSearch.
Like ElasticSearch, OpenSearch includes Approximate Nearest Neighbor Search, allowing it to perform vector similarity search.
Start an OpenSearch server using the following YAML:
version: "3.3"
services:
opensearch:
image: opensearchproject/opensearch:2.4.0
environment:
- plugins.security.disabled=true
- discovery.type=single-node
ports:
- "9900:9200"
networks:
- os
networks:
os:
name: osdocker-compose upThen, create a DocumentArray instance connected to ElasticSearch. Make sure to install DocArray using the opensearch tag:
pip install "docarray[opensearch]"opensearch_da = DocumentArray(storage='opensearch', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'product_type': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
opensearch_da.extend(encoded_da)Now, make a search query for items similar to doc with filter color='Blue':
filter = {'match': {'color': 'Blue'}}
results = opensearch_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
Like ElasticSearch, OpenSearch is convenient for production use-cases. It also offers better integration with AWS Cloud. OpenSearch also has a more open license than ElasticSearch.
Read more about OpenSearch integration in DocArray:
tagAnnLite
AnnLite is a Python library for fast Approximate Nearest Neighbor search with filtering capabilities. Built by Jina AI, it offers an easy vector search experience as a library (no client-server architecture).
To use AnnLite, install DocArray using the annlite tag:
pip install "docarray[annlite]"annlite_da = DocumentArray(storage='annlite', config={
'n_dim': 768,
'columns': {
'color': 'str',
'country': 'str',
'product_type': 'str',
'width': 'int',
'height': 'int',
'brand': 'str',
}
})
# Index data
annlite_da.extend(encoded_da)Now, make a search query for items similar to doc with filter color='Blue':
filter = {'color': {'$eq': 'Blue'}}
results = annlite_da.find(doc,filter=filter, limit=5)
results[0].plot_image_sprites()
AnnLite is easy to install and use. With DocArray, it offers a great local vector search with filtering capabilities. Since it does not rely on a client-server architecture, there is no network overhead, yet it implements HNSW for fast vector search.
This explains why it ranks first on Jina AI’s one million scale benchmark.
Read more about AnnLite integration in DocArray:
tagConclusion
Vector databases let us efficiently leverage unstructured data and extract useful insights from it. They can perform vector searches, which are useful for similarity matching, recommendations, analysis, etc.
Choosing the right database can be challenging, depending on your resources, use cases, and requirements. For example, you would choose a different database for high speed versus low memory.
To help you decide, we’ve published benchmarks of vector databases using DocArray. That said, you may need to test out a few databases to find your match.
Normally that testing would mean learning each database before you could use it, taking lots of time and effort. But with DocArray’s unified API you can speak to all of these databases the same way. All it takes is changing one or two lines of code, and bam, you’re using a new database. You can check the docs for more information and install it with pip install docarray.






