



Many search systems are rolling out hybrid search functionality that combines conventional keywords, traditional text information retrieval techniques, and some kind of “vector” or “neural” search based on recent advances in artificial intelligence. But is “hybrid search” really more than a buzzword? Text-based search is a very old technology, so old that users have now trained themselves to accept its idiosyncrasies and limitations. Do new AI technologies have a lot to add?
The unsurprising answer is: It depends.
Modern data stores are multimedia and multi-modal, with texts, images, video and audio stored together in the same databases and on the same computers. This means that to retrieve a picture of, for example, a screwdriver on the website of a hardware store, you can’t just query for the word “screwdriver” and expect that to match some index entry. You must first store and index a text or some kind of label with each picture. Unless you explicitly associate all the pictures of screwdrivers in your database with the label “screwdriver” or some text that says, one way or another, that it’s a picture of a screwdriver, there is no way of using traditional search techniques to find them.
Adding the best and newest AI technologies to search for texts and labels won’t help if you don’t have useful labels and texts. It doesn’t matter if it’s an improvement on traditional technologies if it has nothing to work with.
Let’s say we have a large hardware vendor with online shopping that sells potentially hundreds of thousands of different items. They don't have the staff to craft detailed product labels and descriptions or check their accuracy. They may not have pictures for every item and don’t have the time to take good ones. Even the very best text-only search is a flawed solution for them.
New AI techniques can address these limitations. Deep learning and neural search have made it possible to create powerful general purpose neural network models and to apply them to different kinds of media — texts, images, audio, and video — in a common way, so that, even without text labels, a search for “screwdrivers” finds pictures of screwdrivers!
But these newer technologies often give results that are hard to explain. Customers might reasonably expect that a query like “Phillips screwdriver” would match a product actually called “Slotted and Phillips Screwdrivers, 4" Long”. Users of traditional search technologies can expect that, but the new AI technologies by their very nature can’t guarantee it.
No single search model is genuinely adequate for this use-case.
We’re going to show you how construct a hybrid search system that takes advantage of traditional text matching technologies while retaining and even improving on the value of AI-based search methods. The techniques presented here focus on combining scores to improve results. There will be a follow-up post specifically implementing hybrid search using Jina AI inside of Elasticsearch.
tagSearch Models
We’re going to use three specific search models to build a hybrid search engine: BM25, SBERT and CLIP.
BM25 is the classic text-based information retrieval algorithm. It is widely used, having first been developed in the 1990s. For more information about BM25, see Robertson & Zaragoza (2009), Spärck Jones et al. (2000a and 2000b), or consult the presentation on BM25 in Wikipedia. We used the rank_bm25 package for Python, which fully implements the BM25 ranking algorithm.
SBERT is a neural network framework that is widely used in textual information retrieval. We used the msmarco-distilbert-base-v3 model, because it was trained for the MS-MARCO passage ranking task, which is more-or-less the same task as the ranking we’re doing here.
CLIP is a neural network trained with both images and descriptive texts. Although CLIP has a number of other usages, we will be using it in this article to match images to text queries, and return ranked results. For this work, we used the clip-vit-base-patch32 model from OpenAI, which is the most widely used CLIP model.
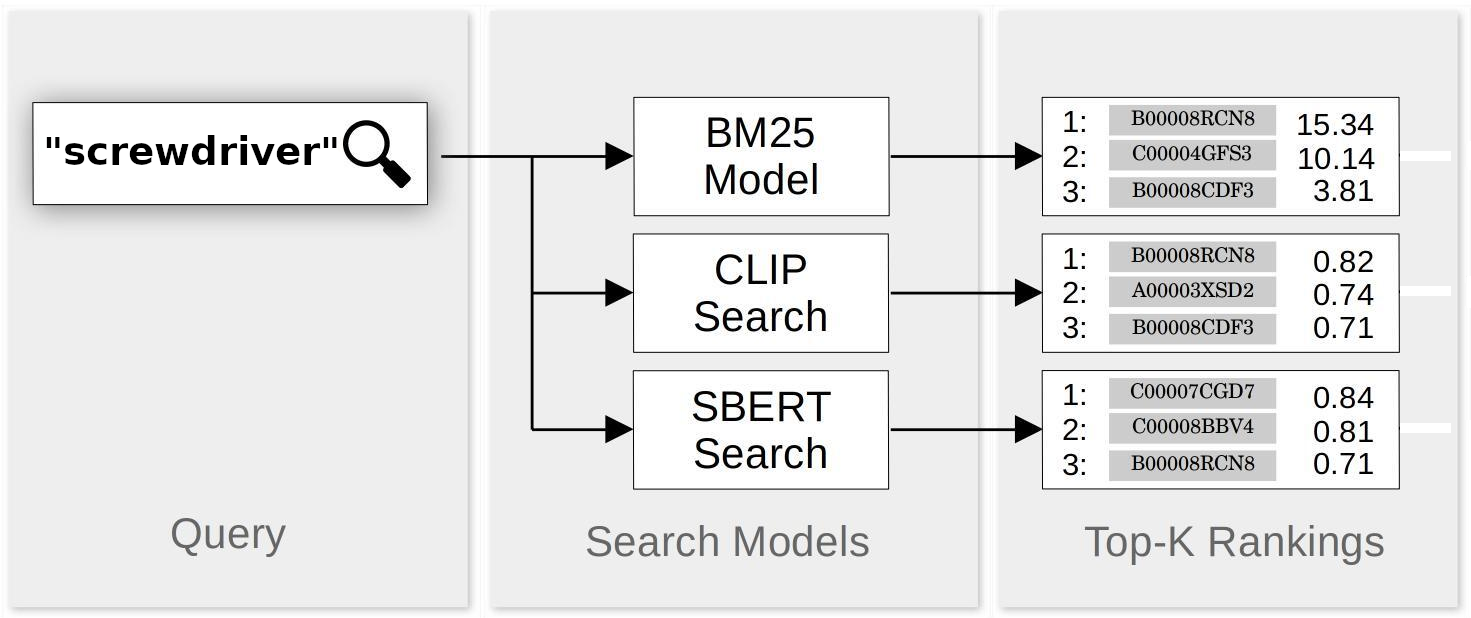
All three work by scoring and ranking matches in response to text queries, then returning some number of top results, with the number decided by the user. This makes it easier to integrate them. Both SBERT and CLIP produce scores between -1.0 (worst match for query) and 1.0 (best match). The lowest possible BM25 score is 0.0, but there are no upper bounds.
To make them fully comparable, we took a few measures:
- We reject all matches from CLIP or SBERT with scores less than zero. These are always bad matches anyway.
- We normalize BM25 scores to the range 0.0 to 1.0 by applying a simple formula: Divide the BM25 score by itself plus 10.
- When a match appears in the top results of one or two but not all three search methods, we assign it an interpolated score for the search methods that miss it. If we request the top N matches, we assign the missing match a small, non-zero value that we determined empirically for each model.
For example, let’s say we search for “screwdriver” and get the twenty best matches from each of BM25, SBERT and CLIP. BM25 and SBERT search both identify a product “6-Piece Magnetic Tip Screwdriver Set, 3 Phillips and 3 Flat” in the top twenty matches, but CLIP does not have this product in its top twenty matches at all because the picture is of the box it ships in. We then find the lowest score CLIP assigned to any of its top 20 matches, and we use that as the score that CLIP gave to “6-Piece Magnetic Tip Screwdriver Set, 3 Phillips and 3 Flat”.

tagHybrid Search
We constructed a hybrid search scheme that combines the results of searches using BM25, SBERT and CLIP. For each query, we performed search using each of the three systems, and retrieved the twenty best matches from each system and adjusted their scores as described in the previous section. The score for each match is a weighted sum the scores given to it by each of the three search systems — SBERT, CLIP, and the normalized BM25.
Below is a schematization of how the hybrid search scheme works:
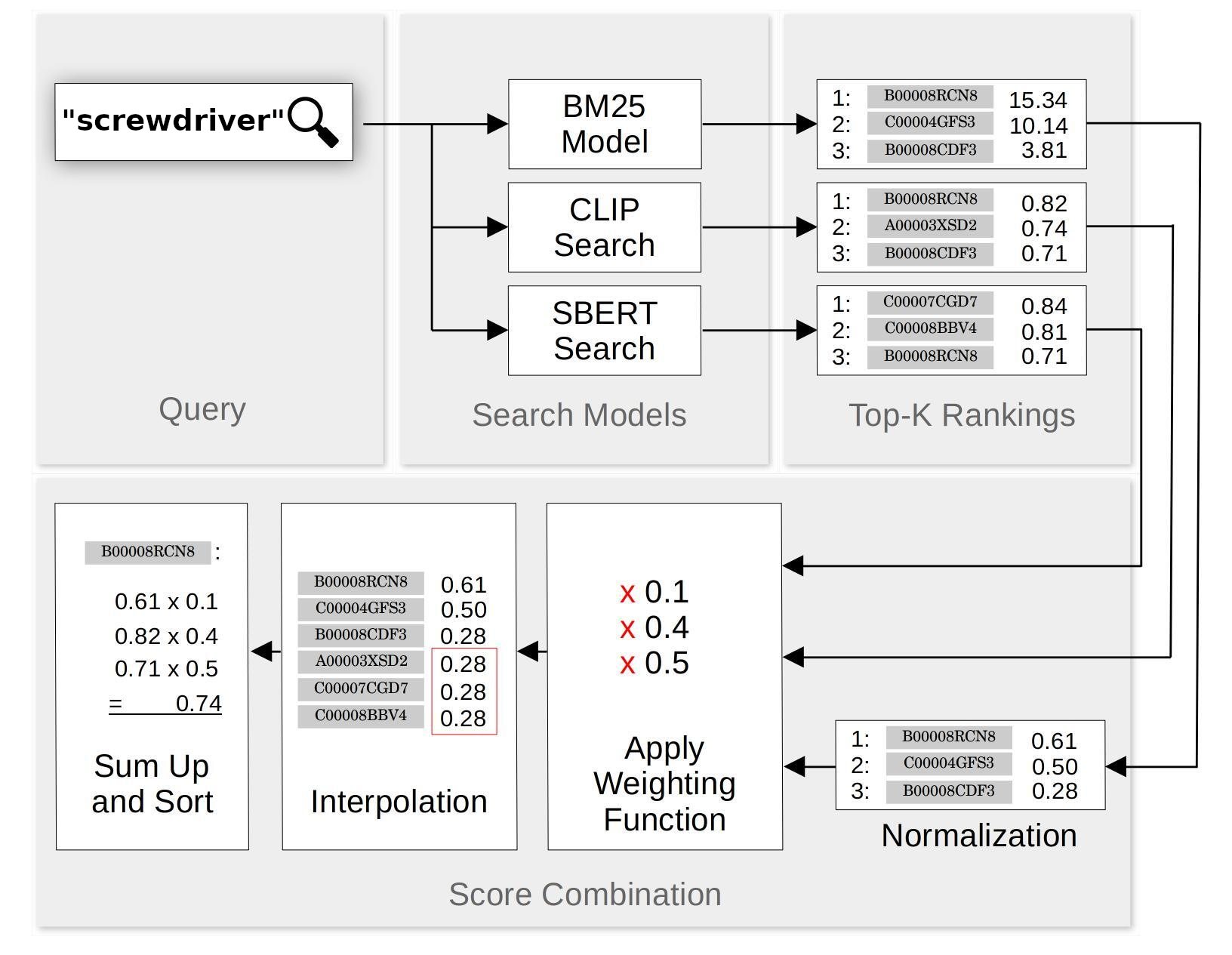
Empirical testing found that the following weights worked fairly well:
| Model | Weight |
|---|---|
| BM25 | 0.1 |
| SBERT | 0.5 |
| CLIP | 0.4 |
Intuitively, we can interpret this as placing a bit more than half the weight on text retrieval (SBERT and BM25) and bit less than half on text-to-image retrieval (CLIP), with BM25’s 0.1 weight ensuring a bias in favor of traditional term matches, all else being equal, or acting as a fallback when neural models fail to produce any good results.
tagComparing Search Schemes
tagTest Data
Ideally, we would have the product database and query log of a real online vendor. However, companies (especially fictional ones) generally don't make their users’ queries available to researchers for commercial and legal reasons. So we are forced to use a substitute.
We used the closest readily available alternative: the XMarket dataset. This data is drawn from Amazon.com marketplaces in eighteen countries, and consists of product images found on Amazon websites, as well as product names, descriptions, categories and various metadata.
For this article, we used a subset of the XMarket data: Only entries in the category Electronics, and only from the US Amazon site. This comes to 15,934 products distributed over 837 categories.
Furthermore, of the information fields available for each item, we used only the following:
- ASIN — A unique product ID assigned by Amazon.
- Title — The name of the product as used by Amazon.
- Description — Free text description of the product, presumably from the manufacturer or vendor.
- Categories — A label within Amazon’s hierarchical product ontology.
- Image — The image or photo Amazon uses on this product’s page.
You can see an example record below:

You can examine the data yourself by logging in to Jina AI (using jina auth login at the command line to access your existing account, or to create one) and downloading it using the DocArray Python module:
 docarray
docarrayfrom docarray import DocumentArray
xmarket_dataset = DocumentArray.pull('xmarket_dataset')
xmarket_dataset.summary()╭────────────────── Documents Summary ───────────────────╮
│ │
│ Type DocumentArrayInMemory │
│ Length 16934 │
│ Homogenous Documents True │
│ Has nested Documents in ('chunks',) │
│ Common Attributes ('id', 'tags', 'chunks') │
│ Multimodal dataclass True │
│ │
╰────────────────────────────────────────────────────────╯
╭──────────────────────── Attributes Summary ────────────────────────╮
│ │
│ Attribute Data type #Unique values Has empty value │
│ ──────────────────────────────────────────────────────────────── │
│ chunks ('ChunkArray',) 16934 False │
│ id ('str',) 16934 False │
│ tags ('dict',) 16934 False │
│ │
╰────────────────────────────────────────────────────────────────────╯tagTask Description
Since we don’t have Amazon’s query logs either, we can’t test systems against a representative sample of queries. So we are forced to choose a similar but different task.
Amazon has assigned each product in the XMarket dataset is to a category in its product ontology, and those categories have text labels. For example, the “Sandisk MicroSD Card” in the previous section is assigned to the category “Micro SD Cards”.
The search task that we will use to compare search schemes is to use those category labels as text queries, and then check if the query result returns items belonging to that category. To turn this into a quantitative measure, we look at the mean reciprocal rank (MRR), which we measure as follows:
We queried search systems with each category label and retrieved the twenty highest-ranked results. We then found the rank of the highest ranked result that was actually in that category. We then assigned that query the score 1.0/rank.
For example, if the first result from the query “Micro SD Cards” was a product that Amazon categorizes as belonging to “Micro SD Cards”, then that query has a score of 1.0. If the first four results were not members of that category but the fifth was, then the score is 0.2. If none of the top twenty belonged to that category, then the score is 0.0.
For each search system, we average the score for all queries to calculate the mean reciprocal rank. Since this is dependent on how many results we took for each query, we label it as MRR@20 because we use the top twenty results for each query.
tagPreparing the search databases and indexes
We selected 1,000 items from the 15,934 to use for testing. These ranged over 296 categories. The remaining data we held out for use in the next section.
We then prepared a BM25 index by getting the title and description for each item in the test set and using the rank_bm25 package, and specifically the BM25Okapi algorithm, to create a text retrieval database. See the relevant README on GitHub for specifics.
For SBERT, we used Jina AI DocArray to create a vector retrieval database, using the title and description of each test set item as input texts.
import finetuner
from docarray import Document, DocumentArray
sbert_model = finetuner.build_model('sentence-transformers/msmarco-distilbert-base-v3')
finetuner.encode(sbert_model, product_categories)
finetuner.encode(sbert_model, product_texts)For CLIP, we followed the same procedure, but using product images from the same test set.
import finetuner
from docarray import Document, DocumentArray
clip_text_model = finetuner.build_model('openai/clip-vit-base-patch32', select_model='clip-text')
clip_vision_model = finetuner.build_model('openai/clip-vit-base-patch32', select_model='clip-vision')
finetuner.encode(clip_text_model, product_categories)
finetuner.encode(clip_vision_model, product_images)
tagBaseline Results
We evaluated the performance of the three search systems by measuring the mean reciprocal rank for each, querying for the top twenty results:
| Search model | Average MMR@20 | Implementation |
|---|---|---|
| BM25 | 30.3% | bm25 package |
| SBERT | 49.1% | docarray.find() NN search |
| CLIP | 29.2% | docarray.find() NN search |
These results shouldn't be very surprising. CLIP — which compares text queries directly with images, not text descriptions — performs worse than BM25. This isn't surprising, and that it's only a little bit worse is evidence of how good CLIP is. Still, we should expect that purely image-driven search is going to be inadequate.
SBERT, which uses neural methods to perform searches on texts, works better on the average than BM25 and in this dataset we can see that the textual information provides a better basis for these searches than image information.
tagHybrid Results


We did the same test, using the same test data, on hybrid search schemes. We tested all three pairs of search systems, and a hybrid that used all three together.
Hybrid search blows the individual search systems out of the water:
| Search model | Average MMR@20 | Max of the Baselines |
|---|---|---|
| BM25+CLIP | 41.1% | 30.3% |
| SBERT+CLIP | 51.7% | 49.1% |
| BM25+SBERT | 51.2% | 49.1% |
| BM25+SBERT+CLIP | 52.95% | 49.1% |
These results alone show the potential for improving search using hybrid methods. The biggest jump comes from combining the two individually worst-scoring models: BM25 and CLIP, which go from scoring roughly 30% separately to over 40% together. Text and image search are complementary, the one compensating for the shortcomings of the other.
SBERT, however, is only a bit improved by adding CLIP and BM25, jumping from a score of 49% to 53%. This still represents an 8% relative improvement compared to SBERT alone.
tagFine-tuning
Fine-tuning improves the performance of pre-trained neural networks by adding training data that is more representative of your specific use-case.
Jina AI Finetuner makes fine-tuning easier, faster and more performant by streamlining the workflow and handling all the operational complexity and physical infrastructure in the cloud.
jina-aiIt works by applying contrastive metric learning, which takes pairs of items that belong together, and then adjusts the model so that it makes better distinctions. There is no need to hand-annotate data or identify what products ought to match each query. As long as you have some kind of information about the semantic relatedness of pairs of data items that fit your use-case, you can use the Finetuner to improve performance.
Having already selected 1,000 items from the XMarket dataset as test data, we used the remaining almost 15,000 entries as training data to fine-tune SBERT and CLIP.
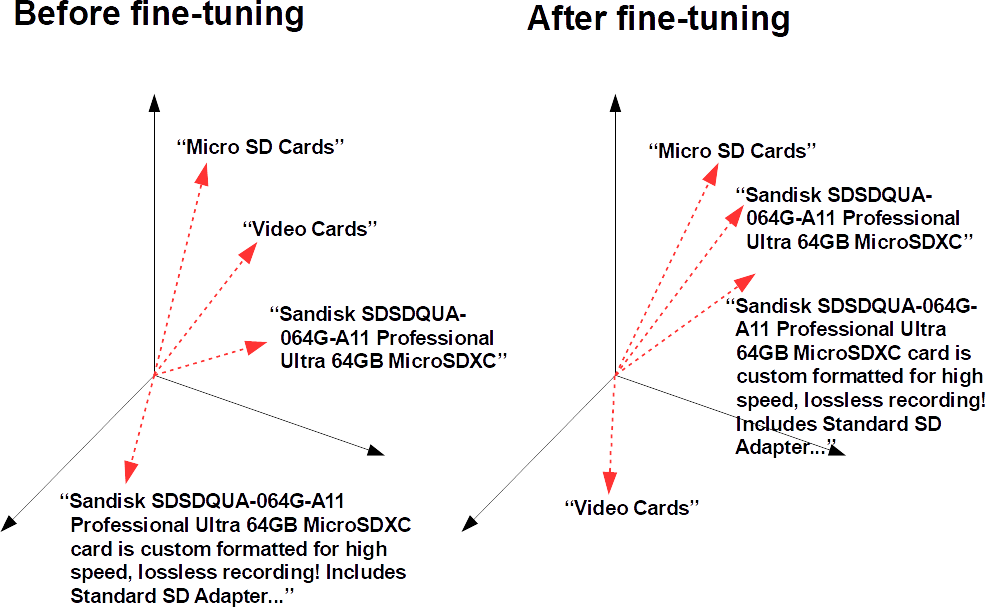
For SBERT, we extracted product titles, product descriptions, and category names from the training set. The logic of fine-tuning is that we want to train SBERT to recognize that product names and descriptions belonging to products in the same category should be relatively good matches for each other and for their category label. Using this information, we reorganized the training data as a DocumentArrayobject for fine-tuning SBERT, as described in the Jina AI Finetuner documentation.
import finetuner
# login to finetuner api
finetuner.login()
# create and submit SBERT finetuning job
sbert_run = finetuner.fit(
model='sentence-transformers/msmarco-distilbert-base-v3',
train_data=sbert_train_data,
epochs=3,
batch_size=64,
learning_rate=1e-6,
cpu=False,
)
# Wait for the run to finish!
finetuned_sbert_model = finetuner.get_model(sbert_run.artifact_id)We then extracted pairs of product images and their category names and did the same to construct a DocumentArrayobject for fine-tuning CLIP. The idea is to train it to place the category names and images closer together.
# create and submit CLIP finetuning job
clip_run = finetuner.fit(
model='openai/clip-vit-base-patch32',
loss='CLIPLoss',
train_data=clip_train_da,
epochs=3,
batch_size=128,
learning_rate=1e-6,
cpu=False
)
# Wait for the run to finish!
finetuned_clip_text_model = finetuner.get_model(clip_run.artifact_id, select_model='clip-text')
finetuned_clip_vision_model = finetuner.get_model(clip_run.artifact_id, select_model='clip-vision')BM25 is not based on neural networks, so naturally, it cannot be fine-tuned. After fine-tuning, it will have a sharp disadvantage compared to SBERT and CLIP because it has no information about categories at all.
After fine-tuning SBERT and CLIP, we reran the evaluation with only the 1,000 item test set, and achieved the following average scores:
| Search model | Average MMR@20 Baseline | Average MMR@20 after running Finetuner |
|---|---|---|
| SBERT | 49.08% | 56.19% |
| CLIP | 28.22% | 41.67% |
| BM25+CLIP | 41.08% | 50.06% |
| SBERT+CLIP | 51.66% | 58.42% |
| BM25+SBERT | 51.22% | 56.80% |
| BM25+SBERT+CLIP | 52.95% | 59.48% |
Although we see improvements in all scenarios, CLIP’s performance skyrockets with fine-tuning. And for hybrid search using all three techniques, there is over 12% relative improvement.
Why Does This Work?
Clearly, hybrid searching rocks. But looking at the evaluation numbers alone understates the improvement each component brings.
For example, for the query "CD-RW Discs", BM25 gives a very high score to a product labeled "Verbatim CD-RW 700MB 2X-12X Rewritable Media Disc - 25 Pack Spindle Style". This is exactly right.

SBERT, however, is misled by a long descriptive text that contains many terms it associates with the search terms:

CLIP, because it relies on visual similarity, is also poorly able to distinguish “CD-RW Discs” from other kinds of optical disks. They look exactly the same to humans too, if you take away the label text. It gives its highest ranking to this, a product that clearly doesn't match what the user is looking for:

CLIP excels when query terms are poor matches for descriptions, but good matches for its visual analysis of product pictures. For example, the query “Earbud Headphones” is a poor match for the textual label "Maxell 190329 Portable lightweight Behind The Head Extended Comfort Soft Touch Rubber Memory Neckband Stereo Line Neckband Head Buds - Silver". But it's a good match for the image below:
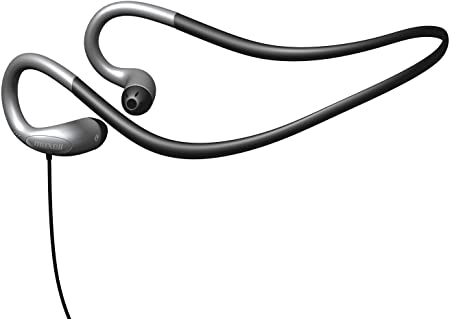
CLIP gives this product a high score because of its appearance, which it correctly identifies with “earbud”.
SBERT and BM25 both miss this match, giving their highest rankings to traditional “over-the-ear” headphones like this one:

SBERT excels where there is good textual information for matching, even if the match is not exact. For example, the query “Fiber Optic Cables” gives us this match from SBERT:

CLIP, in contrast, is useless with this query because it is unable to visually distinguish fiber optic cables from any other kind of cable, and highly ranks matches like this:

tagBring Hybrid Vigor to Your Search
Even with clean visual data and expansive descriptions, hybrid search with classical text retrieval technologies and AI-driven neural search is better than relying on just one technology.
Most use-cases are much less ideal. Descriptions are inaccurate, inadequate, or just plain missing. Photos are of poor quality or absent. And when users put in their queries texts with exact matches, they expect to see those matches in the results. Each of the three technologies is essential to meeting user expectations and providing good results.
With Jina AI’s framework, combining search results and fine-tuning for your use-case produces high quality retrieval software almost out of the box.
We are always moving forward at Jina AI, bringing state-of-the-art cloud-native neural AI to users through our intuitive Python framework and NoCode solutions. Feel free to contact us via our Community Slack with comments or to discuss your use-case.






