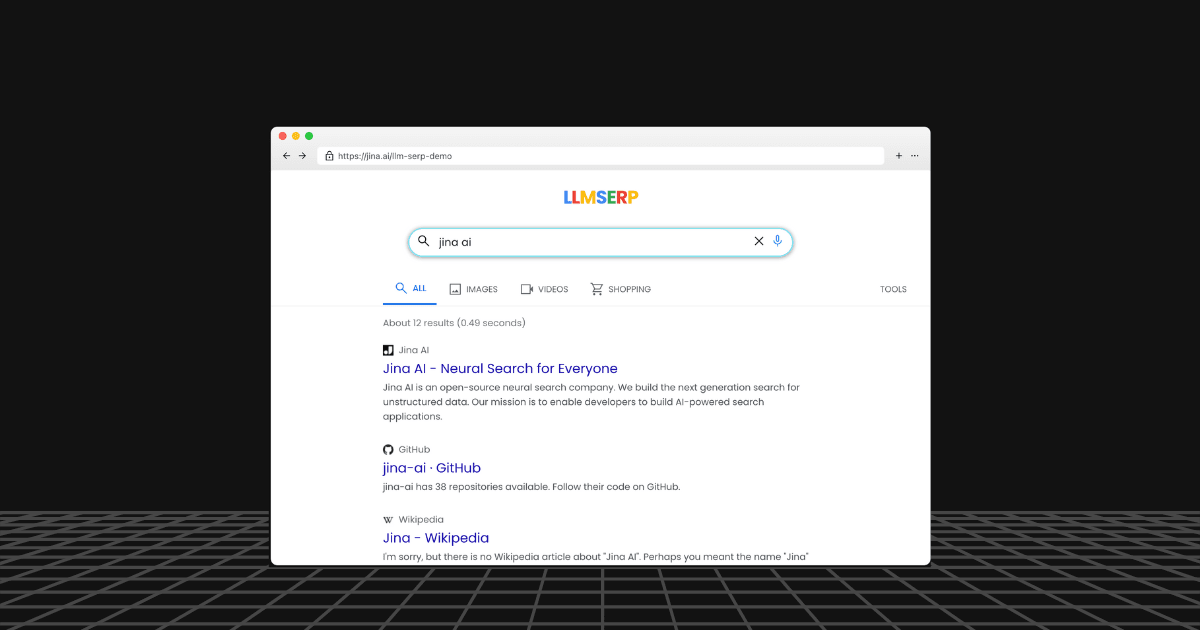


Try the interactive demo and see how your site appears in LLM SERP.
Since RAG, the trend has been using LLMs to improve search. From Perplexity to DeepSearch and DeepResearch, the idea of injecting search engine results into the generation process has become de-facto. Many users also claim they no longer use Google as often as before, finding its classic pagination design lame, overwhelming or tedious. Instead, they've grown accustomed to the high precision and recall of QA-style result from a chat-like search UI, suggesting this design philosophy may be the way forward.
But what if the LLM itself is the search engine?
What if you could explore the knowledge embedded within LLMs as though you were Googling? Pagination, links and everything - just like the old days you are familiar with - but are completely generated. If you're unsure what I mean, check the demo below first.
The links, titles, and snippets are completely generated by an LLM. You can visit https://jina.ai/llm-serp-demo and try some queries yourself!
Before raising concerns about hallucinations, let's first explain why this idea has some merit: LLMs are trained on vast repositories of web knowledge. Models like DeepSeek-R1, GPT-4, Claude-3.7, and Gemini-2.0 have been trained on trillions of tokens from across the public internet. A rough estimate is that <1% to ~5% of high-quality, publicly accessible web text has been used to train leading models.
If you think this number seems too small, consider this comparison: if we use Google's index as the benchmark (representing 100% of user-accessible data in the world), then Bing's index is approximately 30-50% of Google's. Baidu covers about 5-10%, and Yandex covers 3-5%. Brave Search indexes less than 1%. So if an LLM is trained on 1-5% of high-quality public data, it potentially equals the same amount of data a decent small search engine can provide.
Since these models have effectively "remembered" this web data, we simply need to prompt them in a way that "activates" their memory, allowing them to function as search engines and generate results similar to a search engine results page (SERP).
So yes, hallucination is a challenge, but as model capabilities improve with each iteration, we can reasonably expect this issue to alleviate. On X, people are often obsessed with generating SVGs from scratch whenever a new model is released, hoping each version produces better illustration than the last. This search engine idea follows similar hope of incremental improvement of LLM's understanding the digital world.

Knowledge cutoff dates present another limitation. Search engines should return near-real-time information, but since LLM weights are frozen after training, they cannot provide accurate information beyond their cutoff date. Generally, the closer a query is to this cutoff date, the more likely hallucinations become. Since older information has likely been cited and rephrased more frequently, potentially increasing its weights in training data. (This assumes information is uniformly weighted; breaking news may receive disproportionate attention regardless of recency.) However, this limitation actually defines precisely where this approach could be most useful—for information well within the model's knowledge timeframe.
tagWhere LLM-as-SERP Can Be Useful?

In DeepSearch/RAG or any search grounding systems, a core challenge is determining whether a question needs external information or can be answered from the model's knowledge. Current systems typically use prompt-based routing with instructions like:
- For greetings, casual conversation, or general knowledge questions, answer directly without references.
- For all other questions, provide a verified answer with external knowledge. Each reference must include exactQuote and url.This approach fails in both directions - sometimes triggering unnecessary searches, other times missing critical information needs. Especially with newer reasoning models, it's often not obvious until mid-generation whether external data is needed.
What if we simply ran search anyway? We could make one call to a real search API and another to an LLM-as-search system. This eliminates the upfront routing decision and moves it downstream where we have actual results to compare - recent data from real search, knowledge within the model's training cutoff, and potentially some incorrect information.
LLM-SERP gives search results that blend true knowledge with made-up information. However, since the real search engine provide grounded content, the next reasoning step can naturally prioritize the true knowledge.
The next reasoning step can then identify inconsistencies and weigh sources based on recency, reliability, and consensus across results, which we don't have to explicitly code in—this is already what LLMs excel at. One can also visit each URL in the search results (e.g., with Jina Reader) to further validate the sources. In practical implementations, this verification step is always necessary anyway; you should never rely solely on excerpts from search engines, regardless real or fake search engines they are.
tagConclusion
By using LLM-as-SERP, we transform the binary question of "is this within the model's knowledge or not?" into a more robust evidence-weighing process. This eliminates the need of prompt-based routing and may improve the search grounding in DeepSearch-like systems. The logical chain for this assumes:
- The training data for LLMs effectively serves as a small, high-quality search engine.
- As LLMs continue to evolve, the hallucination problem will diminish. Knowledge cutoff dates and hallucinations are relatively independent issues - meaning an ideal perfect LLMs should have zero hallucinations when answering questions about topics before its knowledge cutoff date. Hallucinations only occur when answering questions about events after the cutoff date.
- Information retrieved from Google exists in varying degrees of truth and falsehood, just as information from LLMs contains both accurate information and hallucinations.
- When implementing search grounding, we don't need to overly worry about distinguishing between true and false information, but rather focus on recall rates. The task of pushing precision and factuality can be left to the LLM itself.
We provide a playground as well as an API endpoint hosted by us that you can experiment with. Also feel free integrate into your own DeepSearch/DeepResearch implementations to see any improvement firsthand.

The API mimics a full SERP endpoint where you can define the number of results, pagination, country, language etc. You can find its implementation on GitHub. We're eager to hear your feedback on this interesting approach.




