


Every time I introduce Jina AI and explain what we do, I switch up my narrative depending on who I'm talking to:
The first narrative is data-driven and academic-oriented, aimed at AI researchers. The second is more application-driven and intuitive for practitioners and industry partners. Whatever the narrative, four terms are new to most people:
- Cross-modal
- Multimodal
- Neural search
- Generative AI (sometimes as Creative AI)
Some people have heard of unstructured data, but what's multimodal data? Some have heard of semantic search, but what on Earth is neural search?
Most confusingly of all, why lump these four terms together, and why is Jina AI working on one MLOps platform to cover them all?
This article answers those questions. But I'm impatient. Let's fast-forward to the conclusion: The AI industry has shifted away from single-modal AI and has entered the era of multimodal AI, as illustrated below:

At Jina AI, our spectrum encompasses cross-modal, multimodal, neural search, and generative AI, covering a significant portion of future AI applications. Our MLOps platform gives businesses and developers the edge while they're right at the starting line of this paradigm shift, and build the applications of the future today.
In the next sections, we'll review the development of single-modal AI and see how this paradigm shift is happening right beneath our noses.
tagSingle-Modal AI
In computer science, "modality" roughly means "data type". When we talk about single-modal AI, we're talking about applying AI to one specific type of data. Most early machine learning works fall into this category. Even today, when you open any machine learning literature, single-modal AI is still the majority of the content.
tagNatural Language Processing
We'll start our look back with natural language processing (NLP). Back in 2010, I published a paper about an improved Gibbs sampling algorithm for the Latent Dirichlet Allocation (LDA) model:

Some old machine learning researchers may still remember LDA: a parametric Bayesian model for modeling text corpora. It "clusters" words into topics and represents each document as a combination of topics. For this reason, some people called it a "topic model".
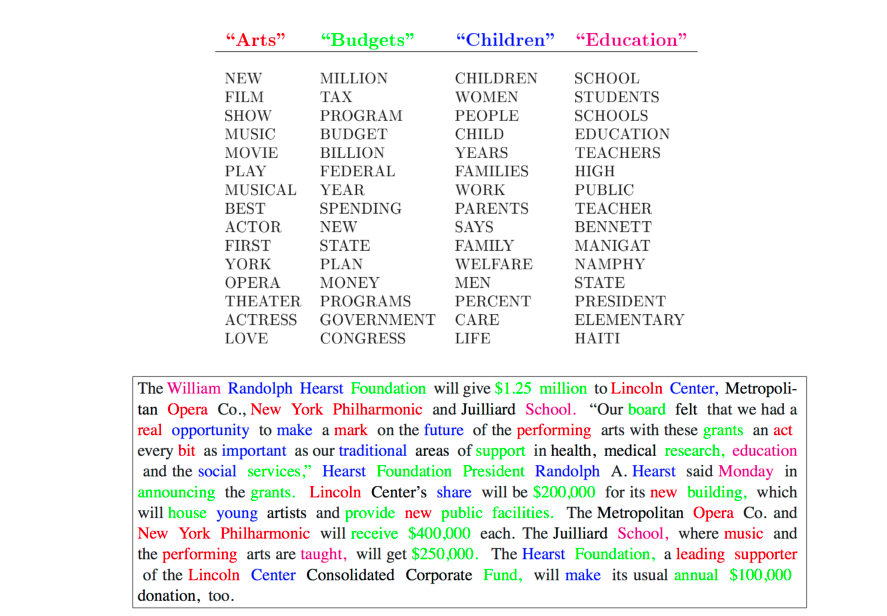
From 2008 to 2012, the topic model was one of the most effective and popular models in the NLP community – it was the BERT/Transformer of its day. Every year at top-tier ML/NLP conferences, many papers would extend or improve the original model. But looking back on it today, it was a pretty "shallow learning" model with a very ad-hoc language modeling approach. It assumed words were generated from a mixture of multinomial distributions. This makes sense for certain specific tasks but isn't general enough for other tasks, domains, or modalities.
Back in 2010-2020, ad-hoc approaches like this were the norm in NLP. Researchers and engineers developed specialist algorithms, each of which was good at solving one task, and one task only:

tagComputer Vision
Compared to NLP, I came to the field of computer vision (CV) pretty late. While at Zalando in 2017, I published a paper on the Fashion-MNIST dataset. This dataset is a drop-in replacement of Yann LeCun's original MNIST dataset from 1990 (a set of simple handwritten digits for benchmarking computer vision algorithms.) The original MNIST dataset was too trivial for many algorithms – shallow learning algorithms such as logistic regression, decision trees, and support vector machines could easily hit 90% accuracy, leaving little room for deep learning algorithms to shine.


Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017
Fashion-MNIST provided a more challenging dataset, allowing researchers to explore, test, and benchmark their algorithms. Today, over 5,000 academic papers have cited Fashion-MNIST in their research on classification, regression, denoising, generation, etc.
Just as the topic model was only good for NLP, Fashion-MNIST was only good for computer vision. There was almost no information in the dataset that you could leverage for studying other modalities. If you look at common tasks in the CV community between 2010-2020, practically all were single-modality. Like NLP, they all covered one task, and one task only:

tagSpeech & Audio
Speech and audio machine learning followed the same pattern: Algorithms were designed for ad-hoc tasks around the audio modality. They each performed (all together now!) one task, and one task only:

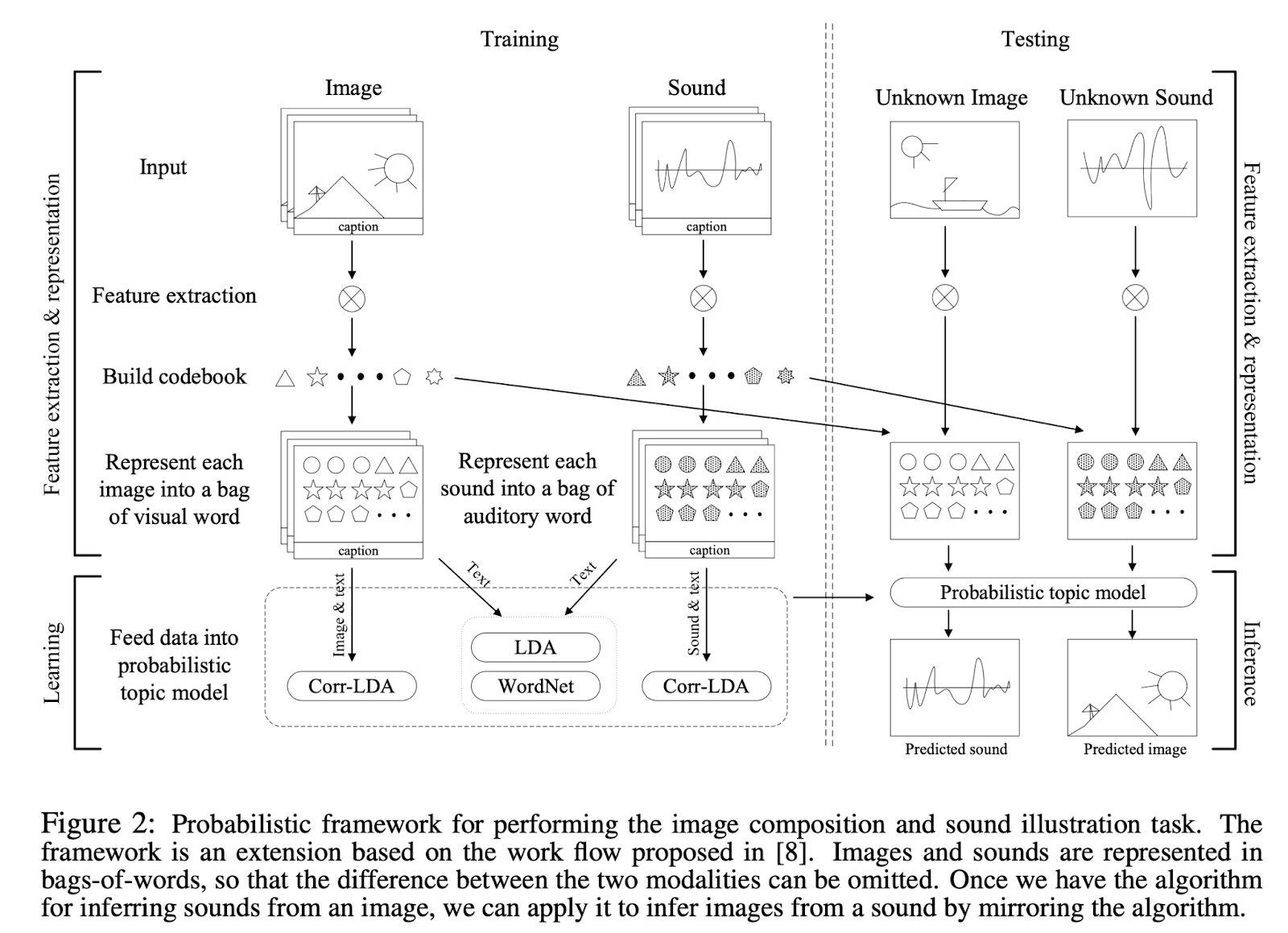
One of my earliest attempts at multimodal AI was a paper I published in 2010, where I built a Bayesian model that jointly modeled visual, textual, and acoustic modalities. Once trained, it accomplished two cross-modal retrieval tasks: finding the best-matching images from a sound snippet and vice-versa. I gave these two tasks a very sci-fi name: "artificial synesthesia".


Toward Artificial Synesthesia: Linking Images and Sounds via Words, 2010
tagTowards Multimodal AI
From the examples above, we can see that all single-modal AI algorithms have two things in common:
- Tasks are specific to just one modality (e.g. textual, visual, acoustic, etc).
- Knowledge is learned from and applied to only one modality (i.e. a visual algorithm can only learn from and be applied to images).
So far I have talked about text, image, audio. There are other modalities such as 3D, video, time series which should be considered as well. If we visualize all tasks from different modalities: We get a cube, where modalities are arranged orthogonally:

On the other hand, multimodal AI is like molding this cube into a sphere, erasing boundaries between different modalities, where:
- Tasks are shared and transferred between multiple modalities (so one algorithm can work with images and text and audio).
- Knowledge is learned from and applied to multiple modalities (so an algorithm can learn from textual data and apply that to visual data).

The rise of multimodal AI can be attributed to advances in two machine learning techniques: Representation learning and transfer learning.
- Representation learning lets models create common representations for all modalities.
- Transfer learning lets models first learn fundamental knowledge, and then fine-tune on specific domains.
Without these techniques, multimodal AI on generic data types would be unfeasible or merely a toy, just like my sound-image paper from back in 2010.
In 2021 we saw CLIP, a model that captures the alignment between image and text; in 2022, we saw DALL·E 2 and Stable Diffusion generate high-quality images from text prompts.
The paradigm shift has already started: In the future we'll see more and more AI applications move beyond one data modality and leverage relationships between different modalities. Ad-hoc approaches are dying out as boundaries between data modalities become fuzzy and meaningless:

tag
The Duality of Search & Creation
Search and creation are two essential tasks in multimodal AI. Here, search means neural search, namely searching using deep neural networks. For most people, these two tasks are entirely isolated, and they have been independently studied for many years. Let me point out this: search and creation are strongly connected and share a duality. To understand this, let's look at the following examples.
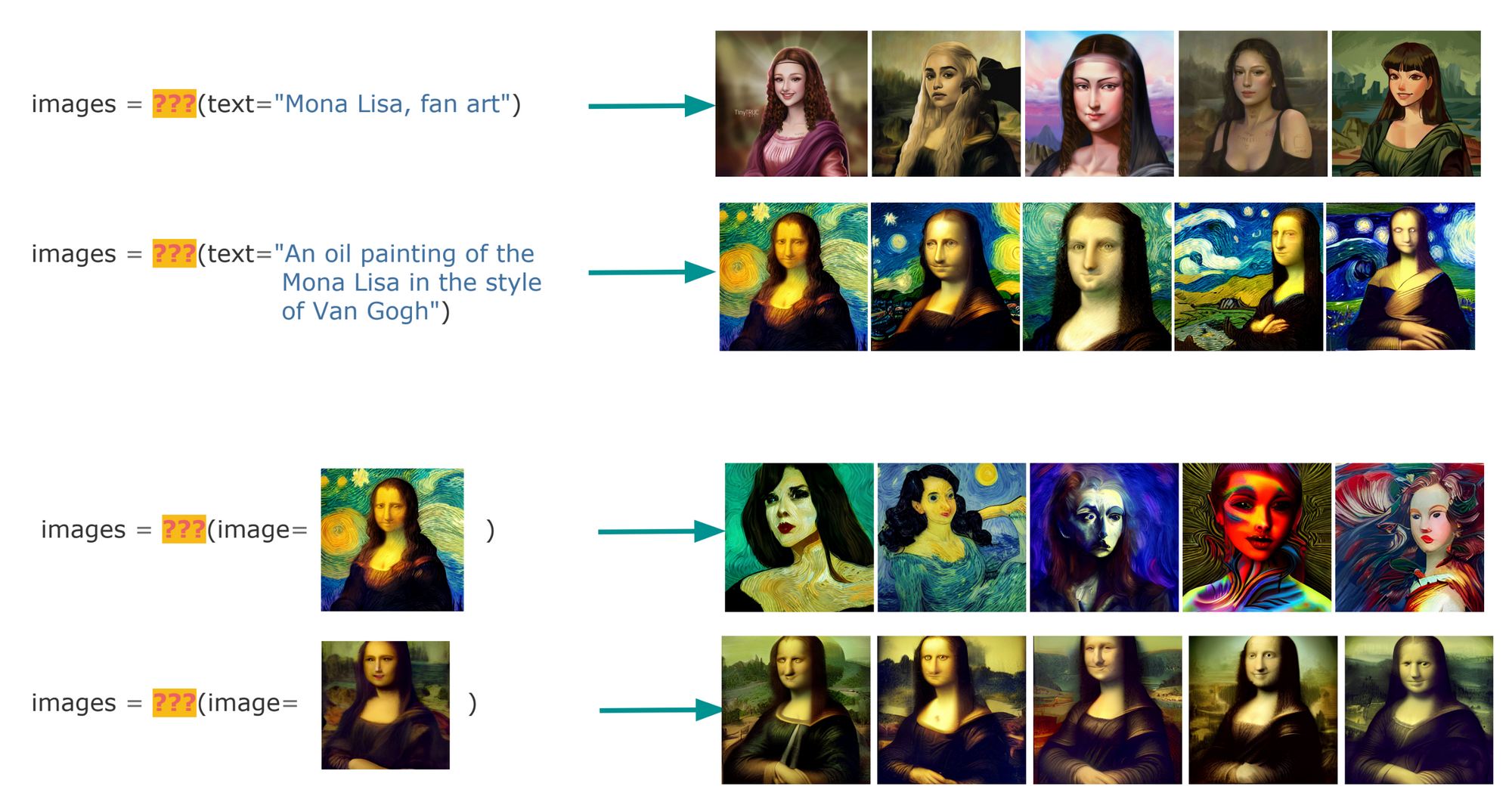
With multimodal AI, it's simple to use a text or image query to search a dataset of images:
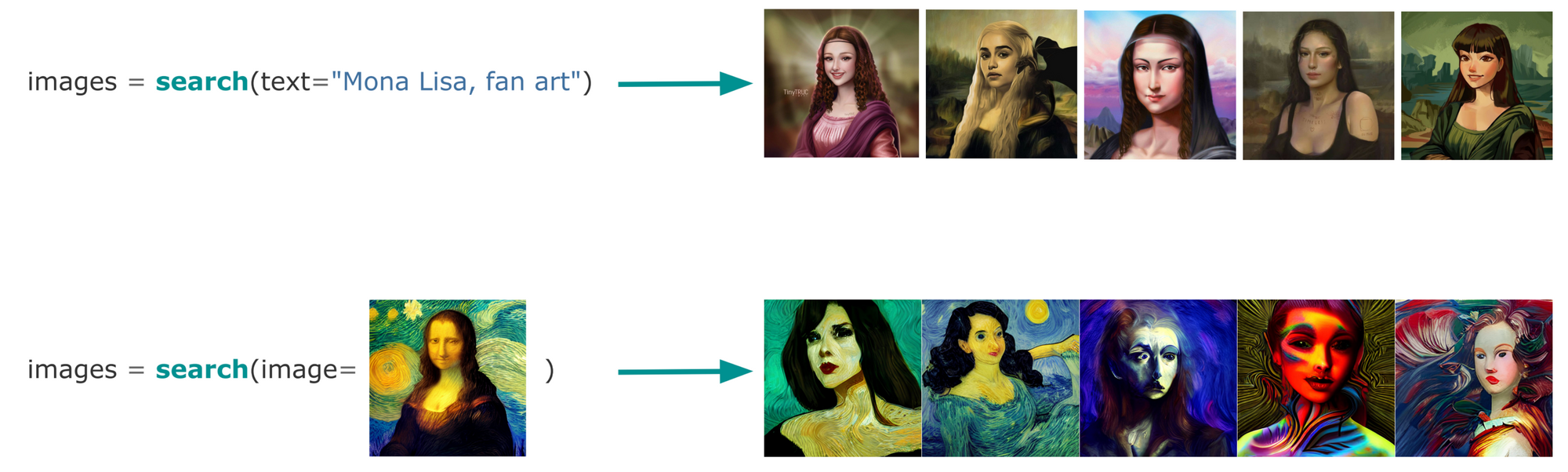
Creation is similar. You create a new image from a text prompt or by enriching/inpainting from an existing image:
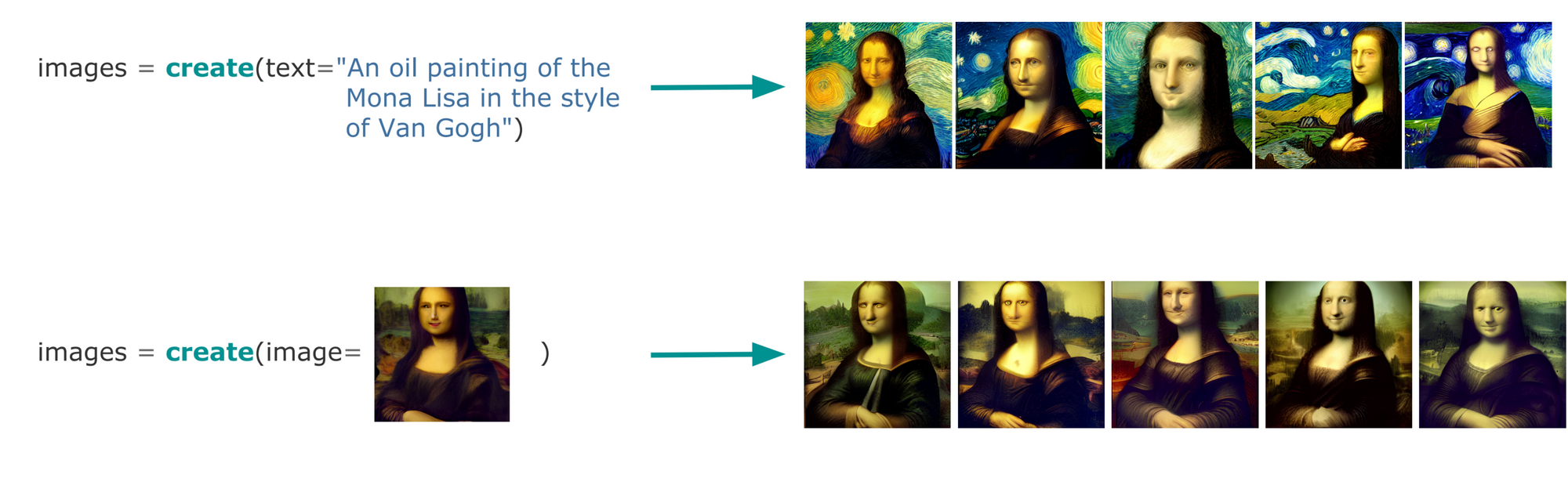
When grouping these two tasks together and masking out their function names, you can see the two tasks are indistinguishable: Both receive and output the same data type(s). The only difference is that search finds what you need, whereas creation makes what you need:
DNA is a good analogy: Once you have an organism's DNA, you can build a phylogenetic tree and search for the oldest and most primitive known ancestor. On the other hand, you could inject the DNA into an egg and create something new, just as David creates his own alien creature:
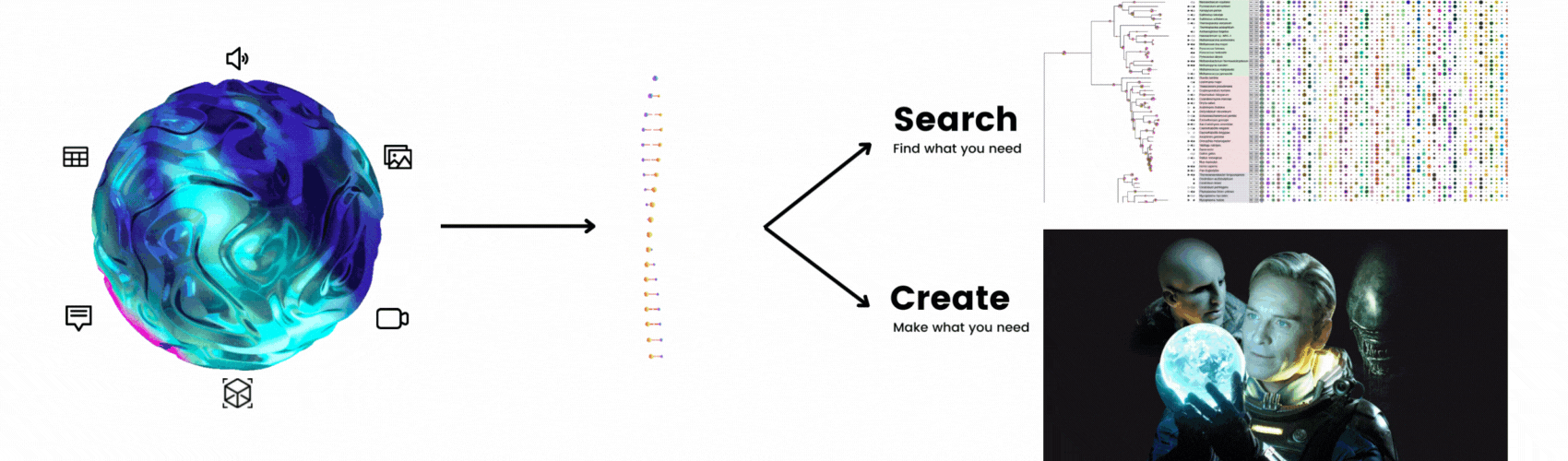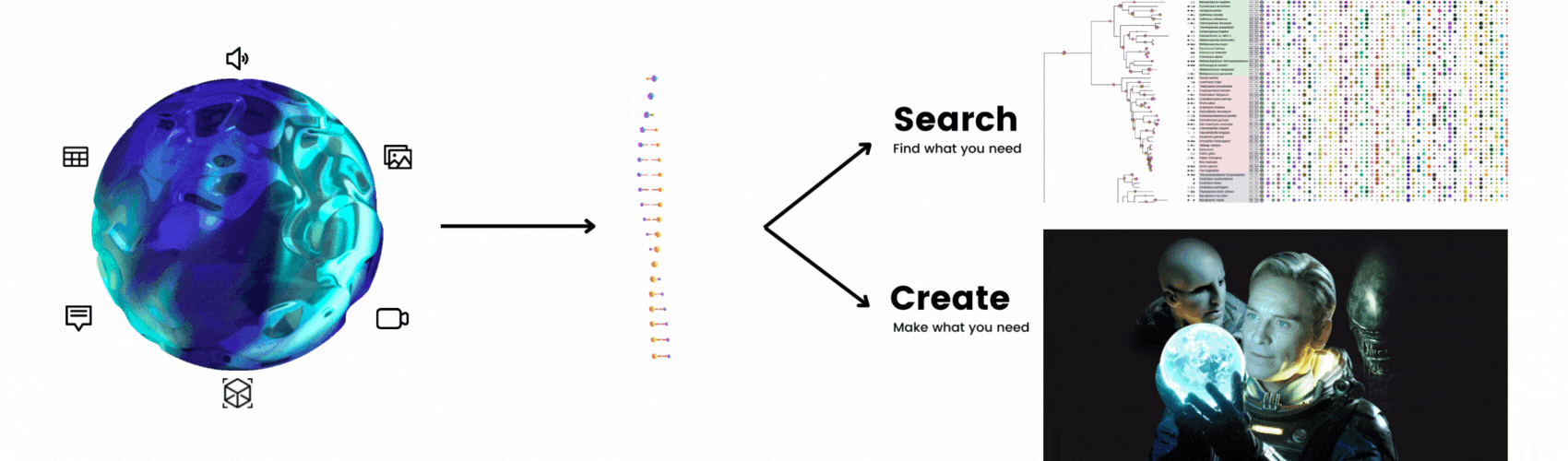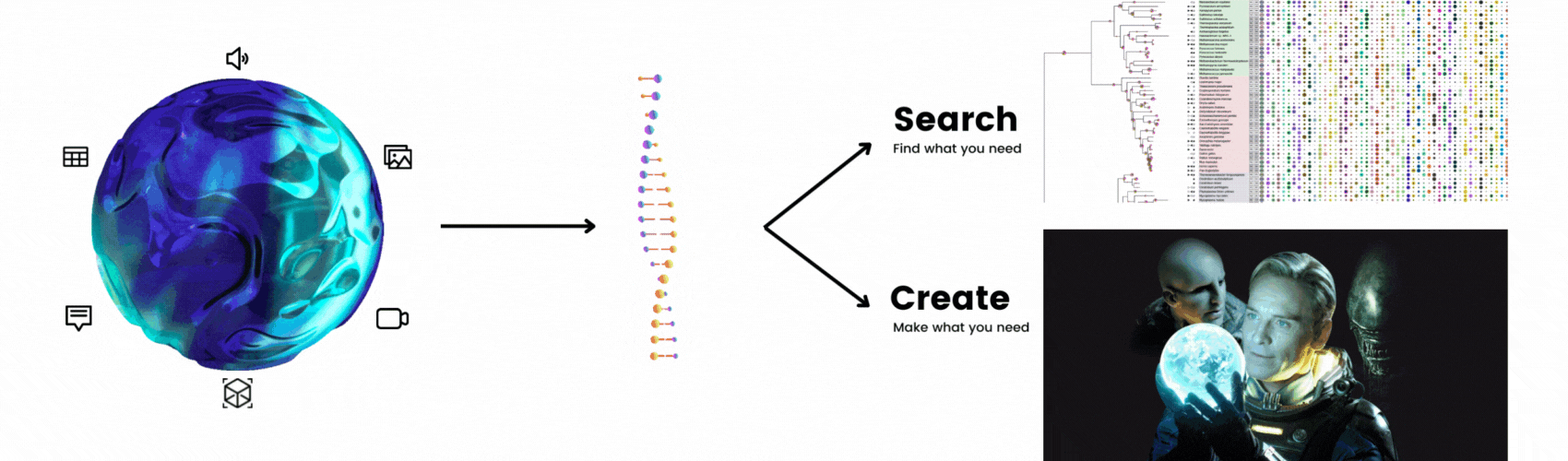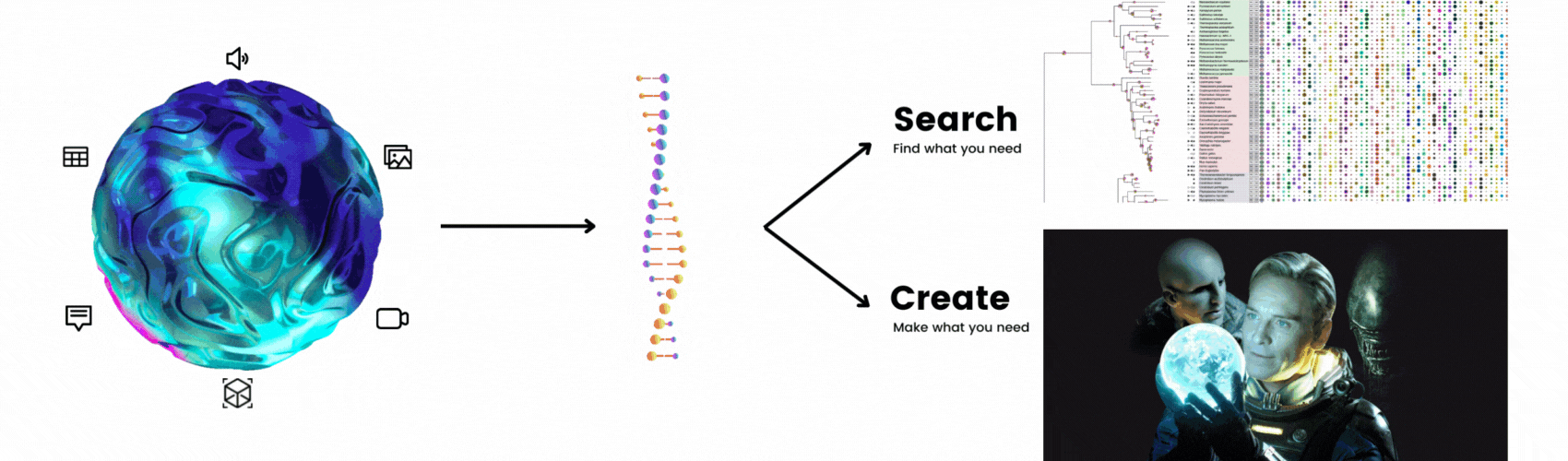
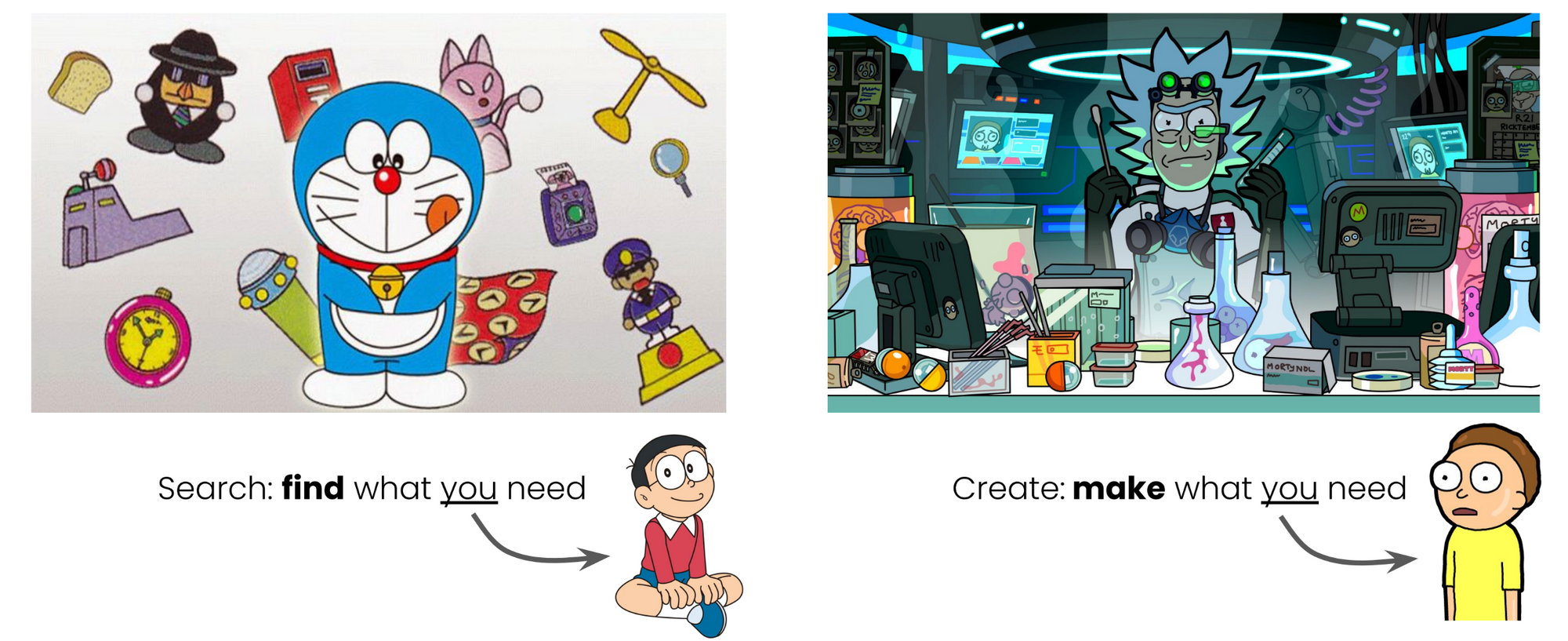
Or think of Doraemon and Rick. Both help their sidekick with out-of-this-world items to solve their problems. The difference is that Doraemon searches through his pocket for an existing item, whereas Rick creates something new from his garage workshop.
The duality of search and creation also poses an interesting thought experiment. Imagine living in a world where all images are created by AI rather than humans. Do we still need (neural) search? Namely, do we need to embed images into vectors and then use a vector database to index and sort them? The answer is NO. As the seed and prompts that uniquely represent the image are known before observing the image, the consequence now becomes the cause. Contrast this to the classic representation, where learning an image is the cause and representation is the consequence. To search images, we can simply store the seed (an integer) and the prompt (a string), which is nothing more than a good old BM25 or binary search. Of course, we humans appreciate photography and human-made artworks, so that parallel Earth is not our reality (yet). Nonetheless, this thought experiment gives a good reason why neural searchers should care about advances in generative AI, as the old way of handling multimodal data may become obsolete.
tagSummary
We are on the frontier of a new era in AI, where multimodal learning will soon dominate. This type of learning, combining multiple data types and modalities, has the potential to revolutionize the way we interact with machines. So far, multimodal AI has had great success in fields like computer vision and natural language processing. In future, expect multimodal AI to have an even greater impact. For instance, developing systems that understand the nuances of human communication, or creating more lifelike virtual assistants. The possibilities are endless, and we're just beginning to scratch the surface. So strap in and buckle up for the future, because the best is yet to come!
Want to work on multimodal AI, neural search, and generative AI? Join us and help lead the revolution!

Check out all jobs at Jina AI






