



Tony Stark, Iron Man 2
We’re all used to our digital assistants. They can schedule alarms, read the weather and reel off a few corny jokes. But how can we take that further? Can we use our voice to interact with the world (and other machines) in newer and more interesting ways?
Right now, most digital assistants operate in a mostly single-modal capacity. Your voice goes in, their voice comes out. Maybe they perform a few other actions along the way, but you get the idea.
This single-modality way of working is kind of like the Iron Man Mark I armor. Sure, it’s the best at what it does, but we want to do more. Especially since we have all these cool new toys today.
Let’s do the metaphorical equivalent of strapping some lasers and rocket boots onto boring old Alexa. We’ll build a speech recognition system of our own with the ability to generate beautiful AI-powered imagery. And we can apply the lessons from that to build even more complex applications further down the line.
Instead of a single-modal assistant like Alexa or Siri, we’re moving into the bright world of multi-modality, where we can use text to generate images, audio to generate video, or basically any modality (i.e. type of media) to create (or search) any other kind of modality.
You don’t need to be a Stark-level genius to make this happen. Hell, you barely need to be a Hulk level intellect. We’ll do it all in under 90 lines of code.
And what’s more, we’ll do all that with a cloud-native microservice architecture and deploy it to Kubernetes.
tagPreliminary research
AI has been exploding over the past few years, and we’re rapidly moving from primitive single-modality models (e.g. Transformers for text, Big Image Transfer for images) to multi-modal models that can handle different kinds of data at once (e.g. CLIP, which can handle text, images, and audio all at once).
But hell, even that’s yesterday’s news. Just this year we’ve seen an explosion in tools that can generate images from text prompts (again with that multi-modality), like DiscoArt, DALL-E 2 and Stable Diffusion. That’s not to mention some of the other models out there, which can generate video from text prompts or generate 3D meshes from images.
Let’s create some images with Stable Diffusion (since we’re using that to build our example):



But it’s not just multi-modal text-to-image generation that’s hot right now. Just a few weeks ago, OpenAI released Whisper, an automatic speech-recognition system robust enough to handle to accents, background noise, and technical language.
This post will integrate Whisper and Stable Diffusion, so a user can speak a phrase, Whisper will convert it to text, and Stable Diffusion will use that text to create an image.
tagExisting works
This isn’t really a new concept. Many people have written papers on it or created examples before:
- S2IGAN: Speech-to-Image Generation via Adversarial Learning
- Direct Speech-to-Image Translation
- Using AI to Generate Art - A Voice-Enabled Art Generation Tool
- Built with AssemblyAI - Real-time Speech-to-Image Generation
The difference is that our example will use cutting edge models, be fully scalable, leverage a microservices architecture, and be simple to deploy to Kubernetes. What’s more, it’ll do all of that in fewer lines of code than the above examples.
tagThe problem
With all these new AI models for multi-modal generation, your imagination is the limit when it comes to thinking of what you can build. But just thinking something isn’t the same as building it. And therein lies some of the key problems:
Dependency Hell
Building fully-integrated monolithic systems is relatively straightforward, but tying together too many cutting edge deep learning models can lead to dependency conflicts. These models were built to showcase cool tech, not to play nice with others.
That’s like if Iron Man’s rocket boots were incompatible with his laser cannons. He’d be flying around shooting down Chitauri, then plummet out of the sky like a rock as his boots crashed.
That’s right everyone. This is no longer about just building a cool demo. We are saving. Iron Man’s. Life. [2]
Choosing a data format
If we’re dealing with multiple modalities, choosing a data format to interoperate between these different models is painful. If we’re just dealing with a single modality like text, we can use plain old strings. If we’re dealing with images we could use image tensors. In our example, we’re dealing with audio and images. How much pain will that be?
Tying it all together
But the biggest challenge of all is mixing different models to create a fully-fledged application. Sure, you can wrap one model in a web API, containerize it, and deploy it on the cloud. But as soon as you need to chain together two models to create a slightly-more-complex application it gets messy. Especially if you want to build a true microservices-based application than can, for instance, replicate some part of your pipeline to avoid downtime. How do you communicate between the different models? And that’s not to mention deploying on a cloud-native platform like Kubernetes or having observability and monitoring for your pipeline.
tagThe solution
Jina AI is building a comprehensive MLOps platform around multimodal AI to help developers and businesses solve challenges like speech-to-image. To integrate Whisper and Stable Diffusion in a clean, scalable, deployable way, we’ll:
- Use Jina to wrap the deep learning models into Executors.
- Combine these Executors into a complex Jina Flow (a cloud-native AI application with replication, sharding, etc).
- Use DocArray to stream our data (with different modalities) through the Flow, where it will be processed by each Executor in turn.
- Deploy all of that to Kubernetes/JCloud with full observability.
 jina-aijina-ai
jina-aijina-aiThese pipelines and building blocks are not just concepts: A Flow is a cloud-native application, while each Executor is a microservice.
Jina translates the conceptual composition of building blocks at the programming language level (By module/class separation) into a cloud-native composition, with each Executor as its own microservice. These microservices can be seamlessly replicated and sharded. The Flow and the Executors are powered by state of the art networking tools and relies on duplex streaming networking.
This solves the problems we outlined above:
- Dependency Hell - each model will be wrapped into it’s own microservice, so dependencies don’t interfere with each other
- Choosing a data format - DocArray handles whatever we throw at it, be it audio, text, image or anything else.
- Tying it all together - A Jina Flow orchestrates the microservices and provides an API for users to interact with them. With Jina’s cloud-native functionality we can easily deploy to Kubernetes or JCloud and get monitoring and observability.
jina-aitagBuilding Executors
Every kind of multi-modal search or creation task requires several steps, which differ depending on what you’re trying to achieve. In our case, the steps are:
- Take a user’s voice as input in the UI.
- Transcribe that speech into text using Whisper.
- Take that text output and feed it into Stable Diffusion to generate an image.
- Display that image to the user in the UI.
In this example we’re just focusing on backend matters, so we’ll focus on just steps 2 and 3. For each of these we’ll wrap a model into an Executor:
- WhisperExecutor - transcribes a user’s voice input into text.
- StableDiffusionExecutor - generates images based on the text string generated by WhisperExecutor.
In Jina an Executor is a microservice that performs a single task. All Executors use Documents as their native data format. There’s more on that in the “streaming data” section.
We program each of these Executors at the programming language level (with module/class separation). Each can be seamlessly sharded, replicated, and deployed on Kubernetes. They’re even fully observable by default.
Executor code typically looks like the snippet below (taken from WhisperExecutor). Each function that a user can call has its own @requests decorator, specifying a network endpoint. Since we don’t specify a particular endpoint in this snippet, transcribe() gets called when accessing any endpoint:
class WhisperExecutor(Executor):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.model = whisper.load_model('base')
@requests
def transcribe(self, docs: DocumentArray, **kwargs):
for (i, doc_) in enumerate(docs):
model_output = self.model.transcribe(
doc_.uri if doc_.tensor is None else doc_.tensor
)
doc_.text = model_output['text']
doc_.tags['segments'] = model_output['segments']
doc_.tags['language'] = model_output['language']
return docs
tagBuilding a Flow
A Flow orchestrates Executors into a processing pipeline to build a multi-modal/cross-modal application. Documents “flow” through the pipeline and are processed by Executors.
You can think of Flow as an interface to configure and launch your microservice architecture, while the heavy lifting is done by the services (i.e. Executors) themselves. In particular, each Flow also launches a Gateway service, which can expose all other services through an API that you define. Its role is to link the Executors together. The Gateway ensures each request passes through the different Executors based on the Flow’s topology (i.e. it goes to Executor A before Executor B).
The Flow in this example has a simple topology, with the WhisperExecutor and StableDiffusionExecutor from above piped together. The code below defines the Flow then opens a port for users to connect and stream data back and forth:
import os
from jina import Flow
from executors.whisper import WhisperExecutor
from executors.stablediffusion import StableDiffusionExecutor
hf_token = os.getenv('HF_TOKEN')
f = (
Flow(port=54322)
.add(uses=WhisperExecutor)
.add(uses=StableDiffusionExecutor, uses_with={'auth_token': hf_token})
)
with f:
f.block()
A Flow can be visualized with flow.plot():

tagStreaming data
Everything that comes into and goes out of our Flow is a Document, which is a class from the DocArray package. DocArray provides a common API for multiple modalities (in our case, audio, text, image), letting us mix concepts and create multi-modal Documents that can be sent over the wire.
That means that no matter what data modality we’re using, a Document can store it. And since all Executors use Documents (and DocumentArrays) as their data format, consistency is ensured.
In this speech-to-image example, the input Document is an audio sample of the user’s voice, captured by the UI. This is stored in a Document as a tensor.
If we regard the input Document as doc:
- Initially the
docis created by the UI and the user’s voice input is stored indoc.tensor. - The
docis send over the wire via gRPC call from the UI to the WhisperExecutor. - Then the WhisperExecutor takes that tensor and transcribes it to
doc.text. - The
docmoves onto the StableDiffusion Executor. - The StableDiffusion Executor reads in
doc.textand generates two images which get stored (as Documents) indoc.matches. - The UI receives the
docback from the Flow. - Finally, the UI takes that output Document and renders each of the matches.
tagConnecting to a Flow
After opening the Flow, users can connect with Jina Client or a third-party client. In this example, the Flow exposes gRPC endpoints but could be easily changed (with one line of code) to implement RESTful, WebSockets or GraphQL endpoints instead.
tagDeploying a Flow
As a cloud-native framework, Jina shines brightest when coupled with Kubernetes. The documentation explains how to deploy a Flow on Kubernetes, but let’s get some insight into what’s happening under the hood.
As mentioned earlier, an Executor is a containerized microservice. Both Executors in our application are deployed independently on Kubernetes as a Deployment. This means Kubernetes handles their lifecycle, scheduling on the correct machine etc. In addition, the Gateway is deployed in the Deployment to flow the requests through the Executors. This translation to Kubernetes concepts is done on the fly by Jina. You simply need to define your Flow in Python.
Alternatively a Flow can be deployed on JCloud, which handles all of the above, as well as providing an out-of-the-box monitoring dashboard. To do so, the Python Flow needs to be converted to a YAML Flow (with a few JCloud specific parameters), and then deployed:
jc deploy flow.yaml
flow.yml in this repo.tagResults
Let’s take the app for a spin and give it some test queries:
With monitoring enabled (which is the default in JCloud), everything that happens inside the Flow can be monitored on a Grafana dashboard:
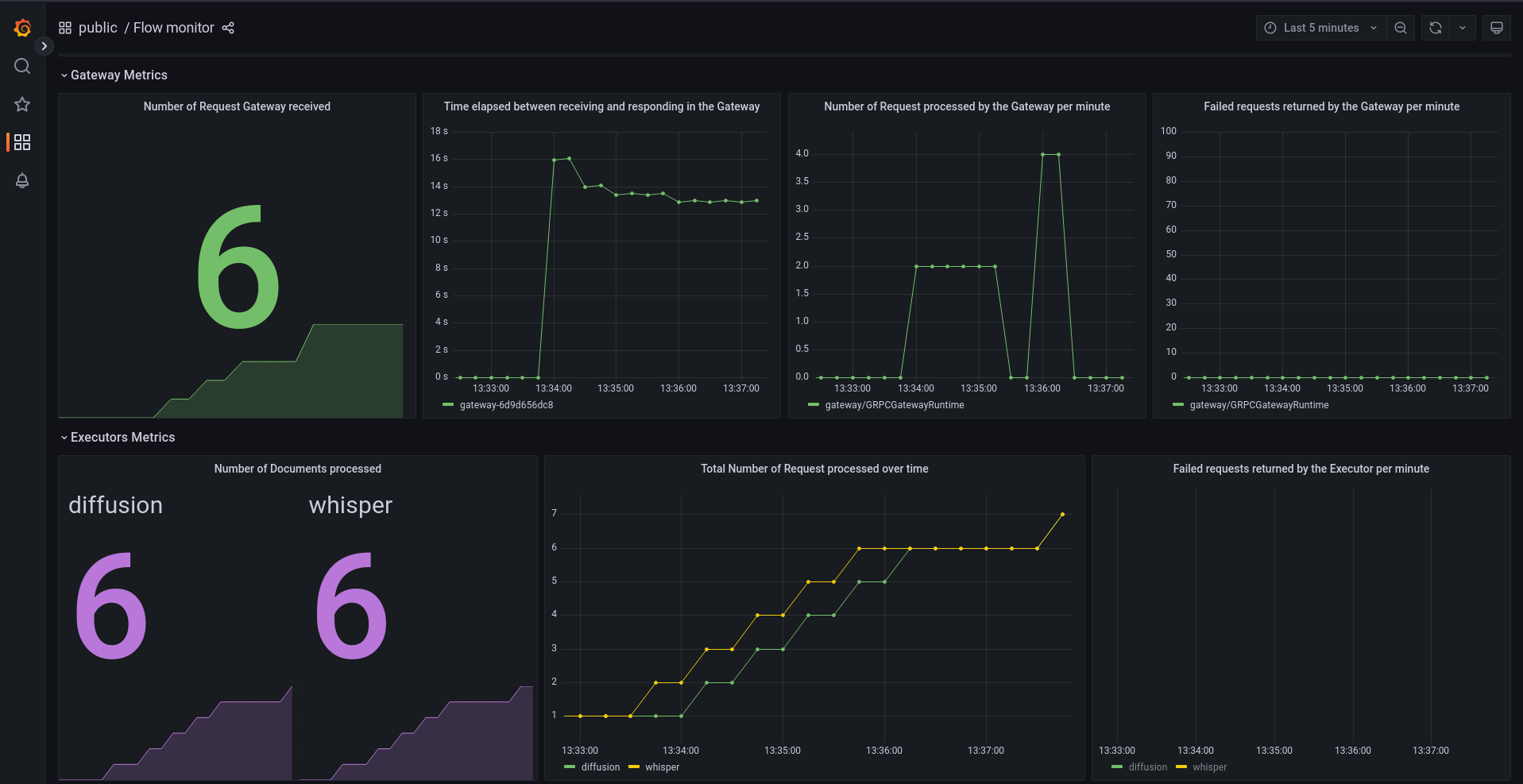
One advantage of monitoring is that it can help you optimize your application to make it more resilient in a cost-effective way by detecting bottlenecks. The monitoring shows that the StableDiffusion Executor is a performance bottleneck:
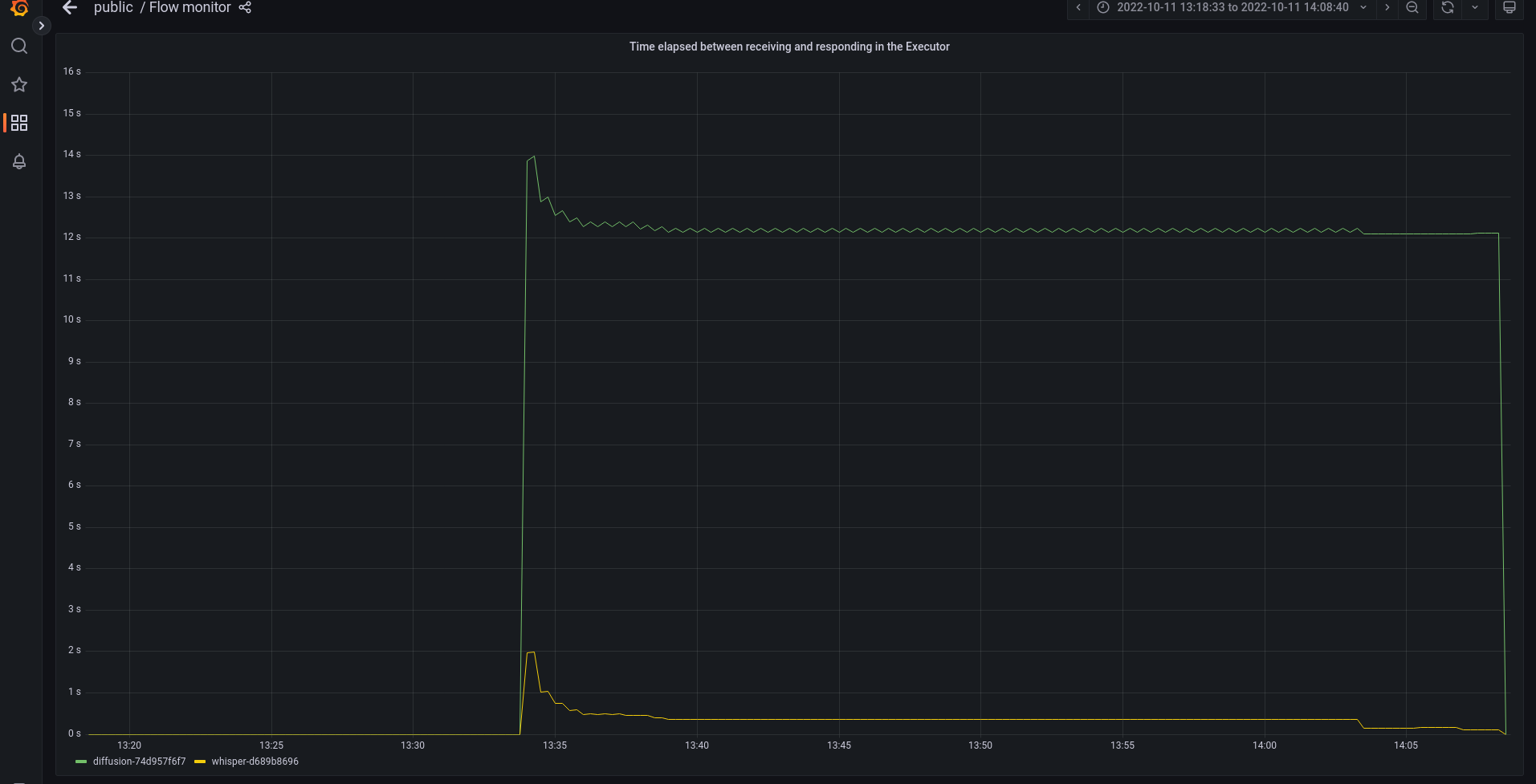
This means that latency would skyrocket under a heavy workload. To get around this, we can replicate the StableDiffusion Executor to split image generation between different machines, thereby increasing efficiency:
f = (
Flow(port=54322)
.add(uses=WhisperExecutor)
.add(uses=StableDiffusionExecutor, uses_with={'auth_token': hf_token}, replicas=2)
)
or in the YAML file (for JCloud):
- name: diffusion
uses: jinahub+docker://StableDiffusionExecutor
uses_with:
auth_token: YOUR_TOKEN
timeout_ready: -1 # slow download speed often leads to timeout
replicas: 2
jcloud:
resources:
gpu: 1
memory: 16tagConclusion
In this post we created a cloud-native audio-to-image generation tool using the state of the art AI models and the Jina AI MLOps platform.
With DocArray we used one data format to handle everything, allowing us to easily stream data back and forth. And with Jina we created a complex serving pipeline natively employing microservices, which we could then easily deploy to Kubernetes.
Since Jina provides a modular architecture, it’s straightforward to apply a similar solution to very different use cases, such as:
- Building a multi-modal PDF neural search engine, where a user can search for matching PDFs using strings or images.
- Building a multi-modal fashion neural search engine, where users can find products based on a string or image.
- Generating 3D models for movie scene design using a string or image as input.
- Generating complex blog posts using GPT-3.
All of these can be done in a manner that is cloud-native, scalable, and simple to deploy with Kubernetes.
