


At Jina AI, sentence embedding models are a critical component of many natural language processing and multimodal AI systems we develop. By encoding semantic information into vector representations, these models equip systems to assess similarity, retrieve relevant passages, and even generate embeddings tailored to specific downstream tasks.
However, a lingering concern around sentence embedding models has been their immense appetite for training data. Models like Sentence-BERT and Sentence-T5 are trained on billions of sentence pairs, demanding substantial computational resources. This causes both financial and environmental strains that limit access and adoption of these models.
In our new paper, we demonstrate that with careful data filtering and training methodology, compelling sentence embeddings can be attained using far less data than previously assumed. Our newly developed JINA EMBEDDINGS models deliver performance rivaling state-of-the-art models while reducing training samples by over 80%.

tagThe Power of Preprocessing
Many datasets for training sentence embedding models contain duplicates, non-English samples, and low-quality pairs with minimal semantic similarity. By meticulously removing such cases, we condensed our initial dataset from 1.5 billion pairs down to a refined 385 million high-quality samples.
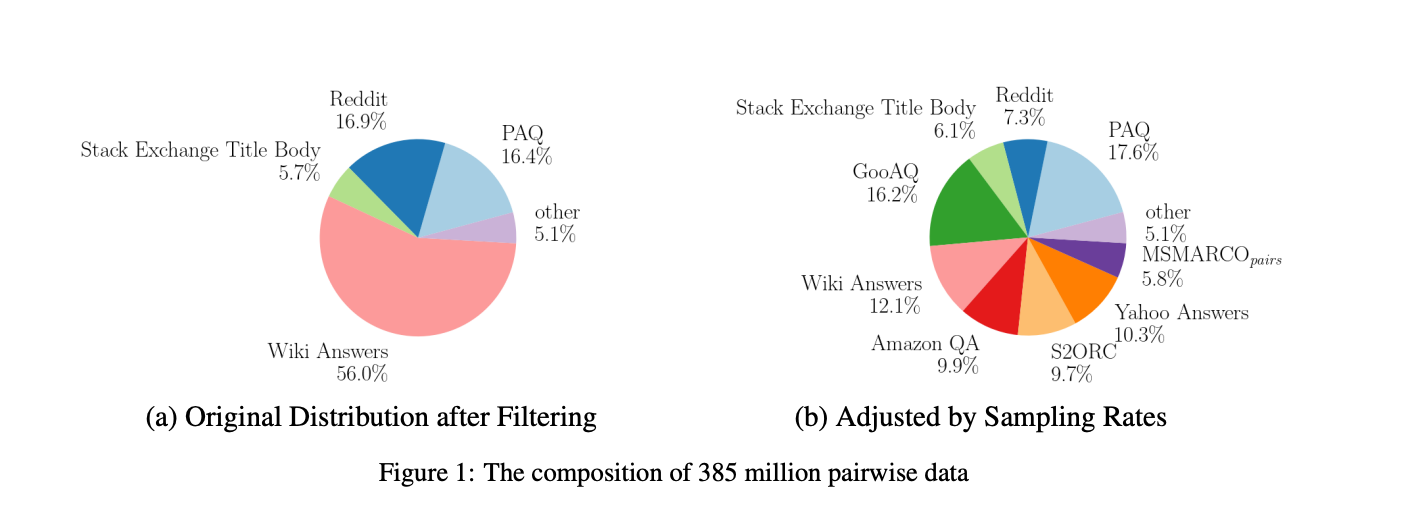
We applied a multi-step filtering process encompassing:
- De-duplication: Removing duplicate entries.
- Language filtering: Eliminating non-English sentences.
- Consistency filtering: Excluding pairs with low embedding similarity based on an auxiliary model. This screened out 84.3% of the Reddit dataset.
An ablation study on the impact of these steps showed consistency filtering, in particular, gave significant gains on retrieval tasks. This indicates that training on a smaller set of truly relevant pairs trumps indiscriminate exposure to billions of noisy examples.
tagShrewd Sampling During Training
In addition to filtering the data itself, we employed smart sampling strategies when creating training batches. Our parallelized approach trains on all datasets simultaneously, but ensures each batch contains examples from just one dataset.
The sampling rates for drawing datasets are weighted based on their relative sizes and quality. This prevents overfitting on smaller datasets while ensuring sufficient exposure to key high-value datasets.
Together with filtering, the weighted sampling reduces the actual number of training pairs encountered to only 180 million. This frugal fine-tuning strategy departs drastically from the data-hungry doctrines of Big Tech.
tagTriplet Training Targets Specificity
After pre-training on paired data, we incorporate a triplet training phase using smaller datasets. Here, each sample contains a query, positive match, and negative match. The model learns to embed the query closer to the positive than the negative.
This second stage exposes models to hard negatives, making embeddings more discriminative. It also incorporates custom negation data to help distinguish contradictory statements. Our jina-large-v1 model saw accuracy on hard negations improve from 16.6% to 65.4% after this triplet training.
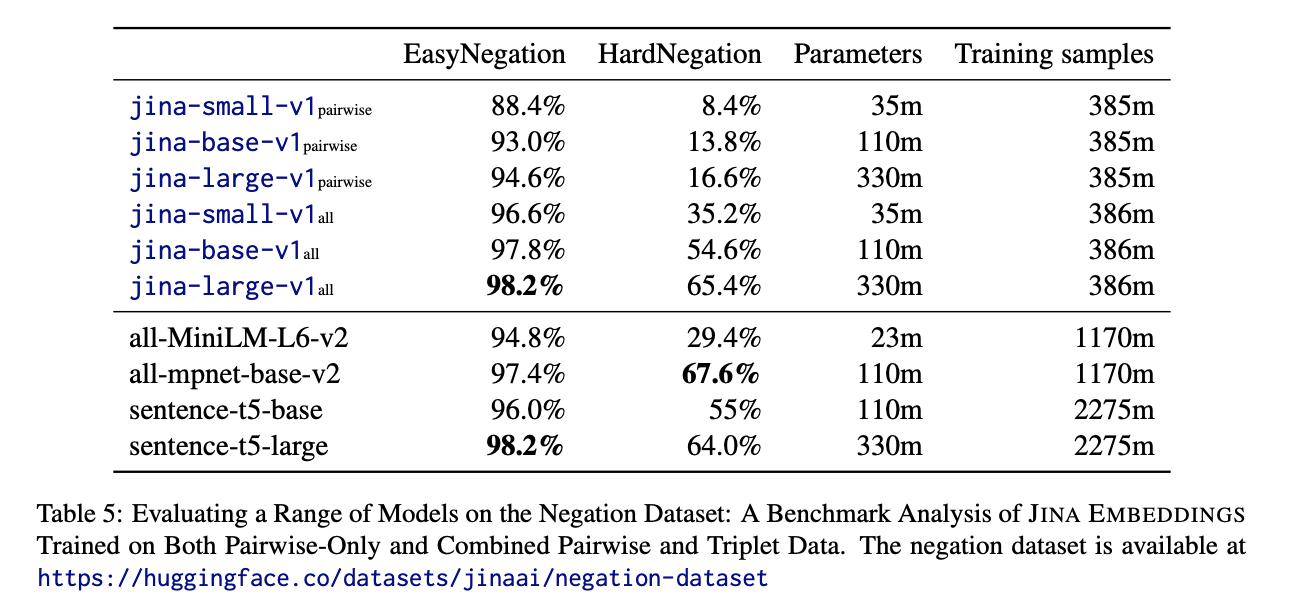
Adding triplet training atop strong pre-training on filtered pairs gives embeddings with strong generalizability and fine-grained specificity.
tagProof is in the Benchmarks
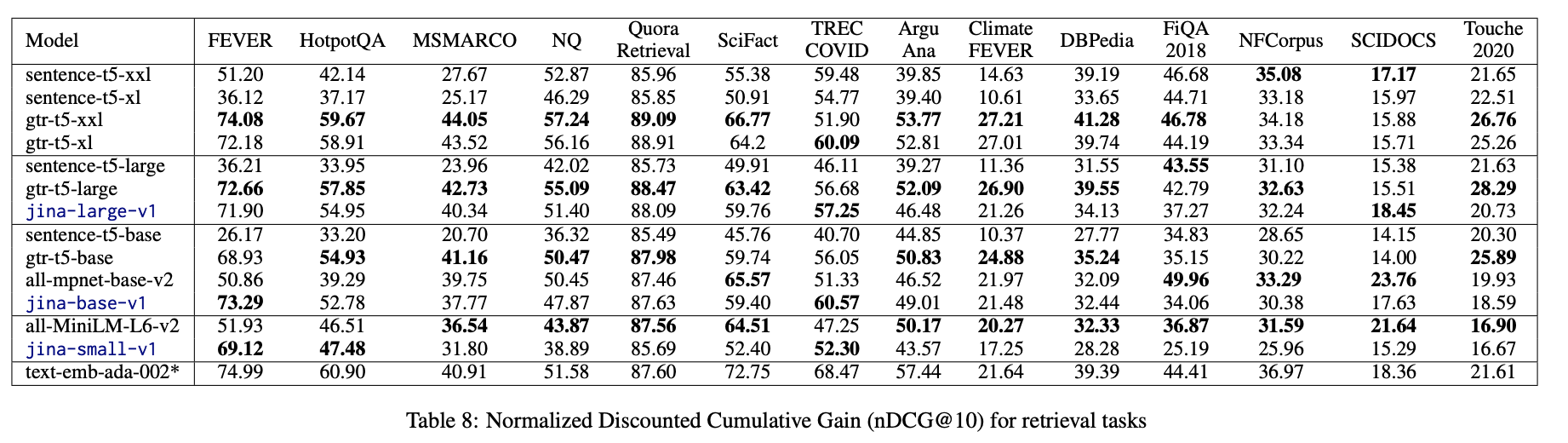
We benchmarked our JINA EMBEDDINGS against models like Sentence-T5 and competitors on established datasets including MTEB and BEIR.
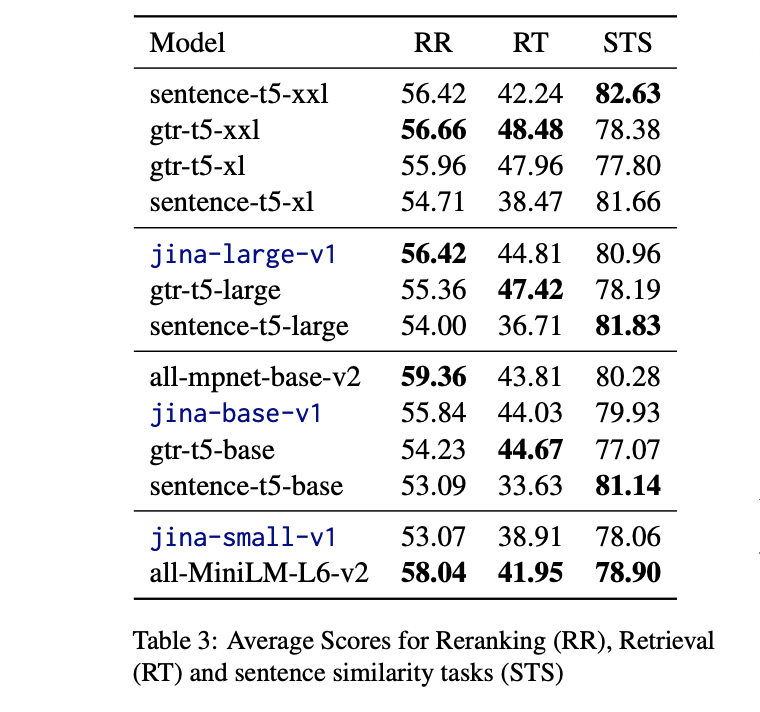
Remarkably, our 110 million parameter jina-base-v1 model matched or exceeded the performance of the 330 million parameter sentence-t5-large on numerous retrieval and reranking tasks. Even the small 35 million parameter jina-small-v1 showed competitive scores, demonstrating the data and training efficiencies unlock smaller yet powerful models.

tagThe Bigger Picture
With meticulous data curation and an inventive training approach, we push state-of-the-art sentence embedding performance while slashing the data demand by over 80%. This carries profound implications:
- Reduced resources: Lower data requirements cut computing infrastructure and energy needs for training.
- Increased accessibility: Efficient data usage unlocks performant small models, expanding access for organizations without massive compute budgets.
- Responsible AI: Judicious data usage and smaller models align with principles of responsible AI by limiting wasteful resource consumption.
Our work signifies masterful model development need not equate to mindless data consumption. Our technical ingenuity in creating the JINA EMBEDDINGS sets an important precedent - great NLP results can be achieved while exercising data frugality.






