Вложения
Высокопроизводительные мультимодальные многоязычные встраивания с длинным контекстом для приложений поиска, RAG и агентов.
Встраивание API
Попробуйте наши модели внедрения мирового класса, чтобы улучшить свои системы поиска и RAG. Начните с бесплатной пробной версии!
chevron_leftchevron_right
Пример входных данных
Измените их и посмотрите, как изменится реакция!
Organic skincare for sensitive skin with aloe vera and chamomile: Imagine the soothing embrace of nature with our organic skincare range, crafted specifically for sensitive skin. Infused with the calming properties of aloe vera and chamomile, each product provides gentle nourishment and protection. Say goodbye to irritation and hello to a glowing, healthy complexion. |
Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung unserer Bio-Hautpflege, speziell für empfindliche Haut entwickelt. Mit den beruhigenden Eigenschaften von Aloe Vera und Kamille pflegen und schützen unsere Produkte Ihre Haut auf natürliche Weise. Verabschieden Sie sich von Hautirritationen und genießen Sie einen strahlenden Teint. |
Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder de la naturaleza con nuestra línea de cuidado de la piel orgánico, diseñada especialmente para pieles sensibles. Enriquecidos con aloe vera y manzanilla, estos productos ofrecen una hidratación y protección suave. Despídete de las irritaciones y saluda a una piel radiante y saludable. |
针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,温和滋润,保护您的肌肤不受刺激。让您的肌肤告别不适,迎来健康光彩。 |
新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。ネオンアイライナーからホログラフィックハイライターまで、クリエイティビティを解き放ち、毎回ユニークなルックを演出しましょう。 |
upload
Запрос
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer " \
-d @- <<EOFEOF
{
"normalized": true,
"embedding_type": "float",
"input": [
"Organic skincare for sensitive skin with aloe vera and chamomile: Imagine the soothing embrace of nature with our organic skincare range, crafted specifically for sensitive skin. Infused with the calming properties of aloe vera and chamomile, each product provides gentle nourishment and protection. Say goodbye to irritation and hello to a glowing, healthy complexion.",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung unserer Bio-Hautpflege, speziell für empfindliche Haut entwickelt. Mit den beruhigenden Eigenschaften von Aloe Vera und Kamille pflegen und schützen unsere Produkte Ihre Haut auf natürliche Weise. Verabschieden Sie sich von Hautirritationen und genießen Sie einen strahlenden Teint.",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder de la naturaleza con nuestra línea de cuidado de la piel orgánico, diseñada especialmente para pieles sensibles. Enriquecidos con aloe vera y manzanilla, estos productos ofrecen una hidratación y protección suave. Despídete de las irritaciones y saluda a una piel radiante y saludable.",
"针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,温和滋润,保护您的肌肤不受刺激。让您的肌肤告别不适,迎来健康光彩。",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。ネオンアイライナーからホログラフィックハイライターまで、クリエイティビティを解き放ち、毎回ユニークなルックを演出しましょう。"
]
}
EOFEOF
v5-omni: Единое встраивание для всех
Текст, изображение, аудио, видео — одно общее пространство для встраивания, два размера. v5-omni-small (1,6 млрд) — это наиболее производительная модель омни с открытыми весами при параметрах менее 2 млрд. v5-omni-nano (0,9 млрд) обеспечивает конкурентоспособный поиск при параметрах менее 1 млрд. Обе модели побайтно совместимы с v5-text — переиндексация не требуется.

v5-text: Новые передовые малоформатные многоязычные эмбеддинги
jina-embeddings-v5-text обеспечивает качество встраивания пятого поколения в двух эффективных размерах — малом (677 МБ) и нано (239 МБ) — с адаптерами LoRA, специфичными для конкретных задач, размерами Matryoshka, контекстом 32K и квантизацией GGUF/MLX для развертывания на периферии сети, устанавливая новые стандарты в задачах MMTEB, MTEB English и поиска информации.

Два способа покупки
Подпишитесь на наш API или приобретите подписку через облачных провайдеров.
radio_button_unchecked
cloud
С 3 поставщиками облачных услуг
Ваша компания использует AWS или Azure? Затем напрямую разверните наши модели базы поиска на этих платформах в вашей компании, чтобы ваши данные оставались в безопасности и соответствовали требованиям.
radio_button_checked

С API Jina Search Foundation
Самый простой способ получить доступ ко всем нашим продуктам. Пополняйте токены по мере использования.
Пополните этот ключ API дополнительными токенами
Пожалуйста, введите правильный ключ API для пополнения счета.
Понять ограничение скорости
Ограничения скорости — это максимальное количество запросов, которые можно сделать к API в течение минуты на IP-адрес/ключ API (RPM). Узнайте больше об ограничениях скорости для каждого продукта и уровня ниже.
keyboard_arrow_down




Локальное развертывание
Развертывайте модели Jina Embeddings в AWS Sagemaker и Microsoft Azure, а вскоре и в Google Cloud Services, или свяжитесь с нашим отделом продаж, чтобы получить индивидуальные развертывания Kubernetes для вашего виртуального частного облака и локальных серверов.
 AWS SageMaker
AWS SageMaker Вложения
Вложения Реранкер
Реранкер'%3e%3cpath%20fill='%23ffffff'%20d='M%20198.351562%2044.007812%20L%20112.046875%20118.847656%20L%2038.398438%20251.039062%20L%20104.804688%20251.039062%20Z%20M%20209.832031%2061.519531%20L%20173%20165.332031%20L%20243.621094%20254.0625%20L%20106.613281%20277.605469%20L%20331.15625%20277.605469%20Z%20M%20209.832031%2061.519531%20'%20fill-opacity='1'%20fill-rule='nonzero'/%3e%3c/g%3e%3c/svg%3e) Microsoft AzureВложенияРеранкер
Microsoft AzureВложенияРеранкер'%3e%3cpath%20fill='%23ffffff'%20d='M%20246.492188%20109.988281%20L%20274.53125%2081.949219%20L%20276.394531%2070.148438%20C%20225.308594%2023.683594%20144.097656%2028.960938%2098.03125%2081.136719%20C%2085.234375%2095.625%2075.753906%20113.695312%2070.691406%20132.363281%20L%2080.726562%20130.941406%20L%20136.804688%20121.703125%20L%20141.125%20117.28125%20C%20166.0625%2089.882812%20208.246094%2086.199219%20237.039062%20109.503906%20Z%20M%20246.492188%20109.988281%20'%20fill-opacity='1'%20fill-rule='nonzero'/%3e%3c/g%3e%3cg%20clip-path='url(%235696d21d1c)'%3e%3cpath%20fill='%23ffffff'%20d='M%20314.480469%20131.527344%20C%20308.042969%20107.796875%20294.804688%2086.457031%20276.40625%2070.132812%20L%20237.050781%20109.488281%20C%20253.671875%20123.066406%20263.128906%20143.511719%20262.730469%20164.964844%20L%20262.730469%20171.949219%20C%20282.066406%20171.949219%20297.746094%20187.628906%20297.746094%20206.964844%20C%20297.746094%20226.300781%20282.066406%20241.601562%20262.730469%20241.601562%20L%20192.59375%20241.601562%20L%20185.710938%20249.078125%20L%20185.710938%20291.09375%20L%20192.59375%20297.6875%20L%20262.730469%20297.6875%20C%20313.03125%20298.085938%20354.136719%20258.007812%20354.535156%20207.703125%20C%20354.777344%20177.207031%20339.734375%20148.617188%20314.480469%20131.527344%20'%20fill-opacity='1'%20fill-rule='nonzero'/%3e%3c/g%3e%3cg%20clip-path='url(%233d43eedc5d)'%3e%3cpath%20fill='%23ffffff'%20d='M%20122.542969%20297.6875%20L%20192.59375%20297.6875%20L%20192.59375%20241.613281%20L%20122.542969%20241.613281%20C%20117.582031%20241.613281%20112.691406%20240.535156%20108.183594%20238.472656%20L%2098.246094%20241.515625%20L%2070.007812%20269.550781%20L%2067.546875%20279.09375%20C%2083.386719%20291.050781%20102.707031%20297.773438%20122.542969%20297.6875%20'%20fill-opacity='1'%20fill-rule='nonzero'/%3e%3c/g%3e%3cg%20clip-path='url(%237591c6ee7a)'%3e%3cpath%20fill='%23ffffff'%20d='M%20122.542969%20115.789062%20C%2072.226562%20116.085938%2031.691406%20157.117188%2031.988281%20207.433594%20C%2032.160156%20235.527344%2045.285156%20261.972656%2067.546875%20279.105469%20L%20108.183594%20238.472656%20C%2090.554688%20230.511719%2082.71875%20209.765625%2090.679688%20192.136719%20C%2098.644531%20174.507812%20119.386719%20166.671875%20137.015625%20174.632812%20C%20144.777344%20178.144531%20151.007812%20184.359375%20154.519531%20192.136719%20L%20195.152344%20151.503906%20C%20177.863281%20128.894531%20150.992188%20115.6875%20122.542969%20115.789062%20'%20fill-opacity='1'%20fill-rule='nonzero'/%3e%3c/g%3e%3c/svg%3e) Google CloudВложения
Google CloudВложения
API-интеграция
Наш API для встраивания изначально интегрирован с различными известными базами данных, векторными хранилищами, платформами RAG и LLMOps. Для начала просто скопируйте и вставьте свой ключ API в любую из перечисленных интеграций для быстрого и беспроблемного запуска.
Векторный магазин
LLMOps
ТРЯПКА
Наблюдаемость

MongoDB

DataStax

Qdrant

Pinecone

Chroma
Weaviate
Milvus
Epsilla
'%3e%3cg%20clip-path='url(%23clip1_1855_4873)'%3e%3cpath%20d='M24%2048C37.2548%2048%2048%2037.2548%2048%2024C48%2010.7452%2037.2548%200%2024%200C10.7452%200%200%2010.7452%200%2024C0%2037.2548%2010.7452%2048%2024%2048Z'%20fill='%239995F7'/%3e%3cpath%20d='M34.7344%2013.2656V34.7364H30.1118V21.866L25.8771%2034.7364H22.1563L17.8863%2021.8434V34.7364H13.2637V13.2656H18.7126L24.0406%2028.1337L29.3107%2013.2656H34.7344Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1855_4873'%3e%3crect%20width='48'%20height='48'%20fill='white'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_1855_4873'%3e%3crect%20width='48'%20height='48'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
MyScale
LlamaIndex

Haystack
Langchain
Dify
'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M47.0411%2016.7178V0.0339975H19.9095C12.6477%200.0339975%206.69079%206.0208%206.54804%2013.3944H6.54423V20.9514H9.80254V13.3944H9.80629C9.9491%207.8547%2014.4463%203.35742%2019.9095%203.35742H43.7804V13.3944H23.6055C21.6685%2013.3944%2019.8837%2014.4534%2019.8837%2016.7178H47.0411ZM0%2031.2822V47.9666H27.1292C34.391%2047.9666%2040.3478%2041.9799%2040.4906%2034.6062H40.4944V27.0486H37.2361V34.6056H37.2304C37.0902%2040.1453%2032.5923%2044.6458%2027.1292%2044.6458H3.25829V34.6056H23.4332C25.3701%2034.6056%2027.155%2033.5466%2027.155%2031.2822H0ZM6.51656%2037.9297H26.76C29.6453%2037.9297%2030.6811%2036.1285%2030.6811%2033.3516V20.1285H47.0411V34.9045C47.0411%2041.0933%2042.9446%2046.3521%2037.3807%2048C41.0988%2044.9774%2043.7829%2040.3769%2043.7829%2034.9045V23.4519H33.9395V33.3516C33.9395%2037.8418%2031.4062%2041.3192%2026.76%2041.3192H6.51656V37.9297ZM40.5221%2010.071H20.2786C17.3933%2010.071%2016.3575%2011.8722%2016.3575%2014.6484V27.8722H0V13.0955C0%206.90725%204.09661%201.64856%209.6604%200C5.9424%203.02257%203.25829%207.62312%203.25829%2013.0955V24.5481H13.0992V14.6484C13.0992%2010.1582%2015.6324%206.68085%2020.2786%206.68085H40.5221V10.071Z'%20fill='%237628F8'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1822_544'%3e%3crect%20width='48'%20height='48'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
SuperDuperDB
%20rotate(-89.93)'/%3e%3crect%20class='cls-1'%20x='30.52'%20y='10.19'%20width='3'%20height='47.42'%20transform='translate(-13.3%2044.91)%20rotate(-60.3)'/%3e%3ccircle%20id='_椭圆形'%20class='cls-1'%20cx='28.91'%20cy='31.28'%20r='5'/%3e%3cpolygon%20class='cls-1'%20points='42.43%2030.75%2035.08%2029.1%2036.37%2021.5%2039.33%2022.01%2038.51%2026.8%2043.09%2027.82%2042.43%2030.75'/%3e%3cpolygon%20class='cls-1'%20points='16.75%2045.55%209.43%2043.77%2010.86%2036.19%2013.8%2036.75%2012.9%2041.53%2017.46%2042.63%2016.75%2045.55'/%3e%3cpolygon%20class='cls-1'%20points='11.02%2028.19%209.54%2020.8%2017.01%2018.89%2017.75%2021.8%2013.04%2023%2013.96%2027.6%2011.02%2028.19'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
DashVector
Portkey

Baseten
TiDB
LanceDB
Carbon
Наши публикации
Поймите, как наши модели поиска на границе были обучены с нуля, ознакомьтесь с нашими последними публикациями. Познакомьтесь с нашей командой в EMNLP, SIGIR, ICLR, NeurIPS и ICML!
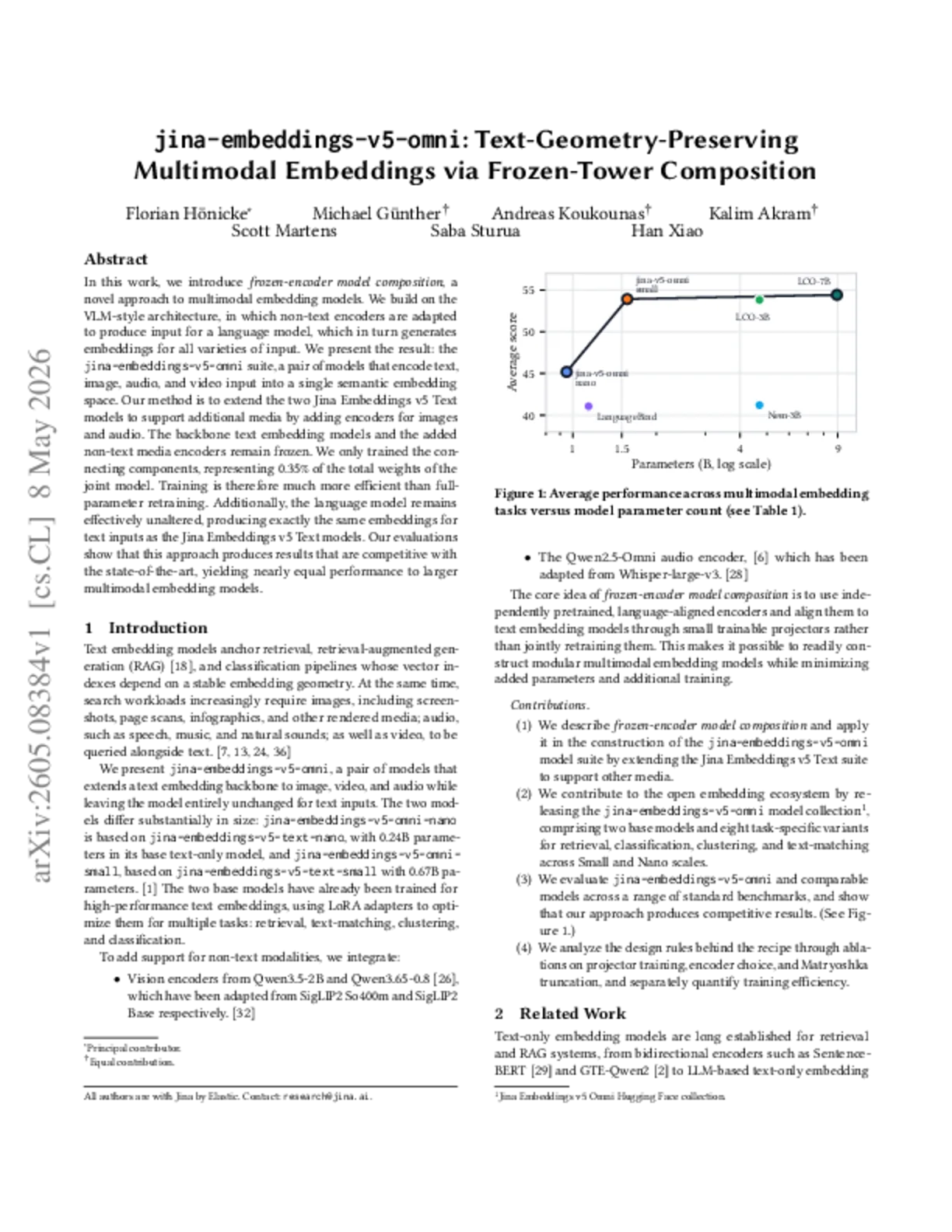
май 11, 2026

SIGIR 2026
февраль 17, 2026

февраль 11, 2026

ICLR 2026
январь 22, 2026

декабрь 29, 2025

ICLR 2026
декабрь 04, 2025

AAAI 2026
октябрь 01, 2025

NeurIPS 2025
август 31, 2025

EMNLP 2025
июнь 24, 2025

ICLR 2025
март 04, 2025

ACL 2025
декабрь 17, 2024

ICLR 2025
декабрь 12, 2024

ECIR 2025
сентябрь 18, 2024

SIGIR 2025
сентябрь 07, 2024

EMNLP 2024
август 30, 2024

WWW 2025
июнь 21, 2024

ICML 2024
май 30, 2024

февраль 26, 2024

октябрь 30, 2023

EMNLP 2023
июль 20, 2023
Всего публикаций 20.
Изучение вложений
С чего начать встраивание? Мы вас прикроем. Узнайте о встраиваниях с нуля с помощью нашего подробного руководства.




Сравнение реранкера, векторного поиска и BM25
В таблице ниже представлено всестороннее сравнение Reranker, Vector/Embeddings Search и BM25, подчеркивая их сильные и слабые стороны в различных категориях.
| Реранкер | Векторный поиск | БМ25 | |
|---|---|---|---|
| Лучшее для | Повышенная точность и релевантность поиска | Начальная, быстрая фильтрация | Общий поиск текста по широкому кругу запросов |
| Детализация | Подробно: вложенный документ и сегмент запроса. | Широкий: все документы. | Средний уровень: различные фрагменты текста. |
| Сложность времени запроса | Высокий | Середина | Низкий |
| Индексация временной сложности | Не требуется | Высокий | Низкий, использует готовый индекс |
| Сложность времени обучения | Высокий | Высокий | Не требуется |
| Качество поиска | Превосходно для тонких запросов | Баланс между эффективностью и точностью | Согласованность и надежность для широкого круга запросов |
| Сильные стороны | Высокая точность и глубокое понимание контекста | Быстро и эффективно, с умеренной точностью. | Высокая масштабируемость и доказанная эффективность |
| Попробуйте API реранкера бесплатно | Попробуйте встроить API бесплатно |
Плакат «Эволюция вложений»
Откройте для себя идеальный плакат для вашего помещения с увлекательной инфографикой или захватывающими визуальными эффектами, прослеживающими эволюцию моделей встраивания текста с 1950 года.

Как обучались модели встраивания Jina?
keyboard_arrow_down
Какие у вас модели мультимодального встраивания?
keyboard_arrow_down
Какие языки поддерживают ваши модели?
keyboard_arrow_down
Какова максимальная длина ввода одного предложения?
keyboard_arrow_down
Какое максимальное количество предложений я могу включить в один запрос?
keyboard_arrow_down
Как отправить изображения в модели мультимодального встраивания?
keyboard_arrow_down
Как модели Jina Embeddings соотносятся с новейшими встраиваниями OpenAI и Cohere?
keyboard_arrow_down
Насколько плавным будет переход от text-embedding-3-large от OpenAI к вашему решению?
keyboard_arrow_down
Как рассчитываются токены при использовании моделей jina-clip?
keyboard_arrow_down
Предоставляете ли вы модели для встраивания изображений или аудио?
keyboard_arrow_down
Можно ли точно настроить модели Jina Embedding с использованием частных данных или данных компании?
keyboard_arrow_down
Могут ли ваши конечные точки размещаться в частном порядке на AWS, Azure или GCP?
keyboard_arrow_down
Что представляет собой параметр 'task' и когда его следует использовать?
keyboard_arrow_down
Что такое извлечение информации при позднем взаимодействии и какие модели его поддерживают?
keyboard_arrow_down
Что такое «позднее сегментирование» и когда его следует использовать?
keyboard_arrow_down
Почему API поддерживает длину контекста, отличающуюся от максимальной емкости модели?
keyboard_arrow_down
Почему jina-embeddings-v4 бесплатна и почему она работает медленно?
keyboard_arrow_down
Каковы ограничения скорости запросов к API Embeddings?
keyboard_arrow_down
Каковы ограничения по длине контекста для каждой модели встраивания?
keyboard_arrow_down
Каковы ограничения по размеру файлов для изображений и PDF-файлов?
keyboard_arrow_down
Ограничение скорости
Ограничения скорости отслеживаются тремя способами: RPM (запросы в минуту) и TPM (токены в минуту). Ограничения применяются для каждого IP/API-ключа и срабатывают при достижении порогового значения RPM или TPM. Когда вы указываете ключ API в заголовке запроса, мы отслеживаем ограничения скорости по ключу, а не по IP-адресу.
| Продукт | Конечная точка API | Описаниеarrow_upward | без API-ключаkey_off | с бесплатным API-ключомkey | с платным API-ключомkey | с премиум-ключом APIkey | Средняя задержка | Подсчет использования токенов | Разрешенный запрос | |
|---|---|---|---|---|---|---|---|---|---|---|
| API-интерфейс читателя | https://r.jina.ai | Преобразовать URL в текст, понятный LLM | 20 RPM | 500 RPM | 500 RPM | trending_up5000 RPM | 7.9s | Подсчитайте количество токенов в выходном ответе. | GET/POST | |
| API-интерфейс читателя | https://s.jina.ai | Поиск в Интернете и преобразование результатов в текст, понятный LLM | block | 100 RPM | 100 RPM | trending_up1000 RPM | 2.5s | Каждый запрос стоит фиксированное количество токенов, начиная с 10000 токенов. | GET/POST | |
| API реранкера | https://api.jina.ai/v1/rerank | Ранжировать документы по запросу | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart зависит от размера входных данных help | Подсчитайте количество токенов во входном запросе. | POST | |
| Встраивание API | https://api.jina.ai/v1/embeddings | Преобразование текста/изображений в векторы фиксированной длины | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart зависит от размера входных данных help | Подсчитайте количество токенов во входном запросе. | POST | |
| API классификатора | https://api.jina.ai/v1/train | Обучить классификатор с использованием маркированных примеров | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart зависит от размера входных данных | Токены подсчитываются как: input_tokens × num_iters | POST | |
| API классификатора (Несколько выстрелов) | https://api.jina.ai/v1/classify | Классифицируйте входные данные с помощью обученного классификатора с несколькими попытками | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart зависит от размера входных данных | Токены учитываются как: input_tokens | POST | |
| API классификатора (Нулевой выстрел) | https://api.jina.ai/v1/classify | Классифицируйте входные данные, используя классификацию с нулевым результатом | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart зависит от размера входных данных | Токены считаются как: input_tokens + label_tokens | POST | |
| API сегментатора | https://api.jina.ai/v1/segment | Токенизация и сегментация длинного текста | 20 RPM | 200 RPM | 200 RPM | 1,000 RPM | 0.3s | Токен не считается использованием. | GET/POST | |
| Глубокий поиск | https://deepsearch.jina.ai/v1/chat/completions | Рассуждайте, ищите и повторяйте, чтобы найти лучший ответ. | block | 50 RPM | 50 RPM | 500 RPM | 56.7s | Подсчитайте общее количество токенов за весь процесс. | POST |
Самостоятельная проверка лицензии CC BY-NC
play_arrow
Вы используете наш официальный API или официальные образы в Azure, AWS или GCP?
play_arrow
Да
play_arrow
Нет
Общие вопросы, связанные с API
code
Могу ли я использовать один и тот же ключ API для чтения, встраивания, переранжирования, классификации и тонкой настройки API?
keyboard_arrow_down
code
Могу ли я отслеживать использование токена моего ключа API?
keyboard_arrow_down
code
Что мне делать, если я забуду свой ключ API?
keyboard_arrow_down
code
Срок действия ключей API истекает?
keyboard_arrow_down
code
Могу ли я передавать токены между ключами API?
keyboard_arrow_down
code
Могу ли я отозвать свой ключ API?
keyboard_arrow_down
code
Почему первый запрос для некоторых моделей выполняется медленно?
keyboard_arrow_down
code
Используются ли данные из моего API для обучения ваших моделей?
keyboard_arrow_down
code
Каковы ограничения скорости запросов к API Jina?
keyboard_arrow_down
code
Существуют ли ограничения на размер пакета для API?
keyboard_arrow_down
Общие вопросы, связанные с выставлением счетов
attach_money
Выставление счетов зависит от количества предложений или запросов?
keyboard_arrow_down
attach_money
Доступна ли бесплатная пробная версия для новых пользователей?
keyboard_arrow_down
attach_money
Взимаются ли токены за неудачные запросы?
keyboard_arrow_down
attach_money
Какие способы оплаты принимаются?
keyboard_arrow_down
attach_money
Доступно ли выставление счетов за покупку токенов?
keyboard_arrow_down