


После замечательного успеха предыдущей версии Embeddings V2, мы рады объявить о запуске нашей новейшей двуязычной модели текстовых эмбеддингов для китайского и английского языков: jina-embeddings-v2-base-zh. Эта новая модель унаследовала исключительную длину токена в 8K от Jina Embeddings V2, теперь с надежной поддержкой как китайского, так и английского языков.
jina-embeddings-v2-base-zh выделяется своим исключительным качеством и производительностью, достигнутыми благодаря тщательной и сбалансированной предварительной обработке высококачественных двуязычных данных. Такой подход обеспечивает значительное снижение предвзятости, часто наблюдаемой в моделях, обученных на несбалансированных многоязычных данных.
tagОсновные особенности
- Двуязычная модель: Эта модель кодирует тексты как на английском, так и на китайском языках, позволяя использовать любой из языков в качестве запроса или целевого документа. Тексты с эквивалентными значениями на этих языках отображаются в одном пространстве эмбеддингов, что является основой для многочисленных многоязычных приложений.
- Расширенная длина токена 8K: Наша модель способна обрабатывать значительно большие текстовые фрагменты, что превосходит возможности большинства других моделей с открытым исходным кодом.
- Компактность и эффективность: С размером 322 МБ (161 миллион параметров) и выходными размерностями 768, наша модель разработана для высокой производительности на стандартном компьютерном оборудовании без GPU, что повышает её доступность.
tagЛидирующая производительность в C-MTEB
В китайском рейтинге MTEB наша Jina Embeddings v2, поддерживающая как китайский, так и английский языки, выделяется как одна из лучших моделей размером менее 0.5 ГБ. Что делает её особенной, так это впечатляющая возможность обработки токенов длиной 8K, уникальная особенность в своей категории.
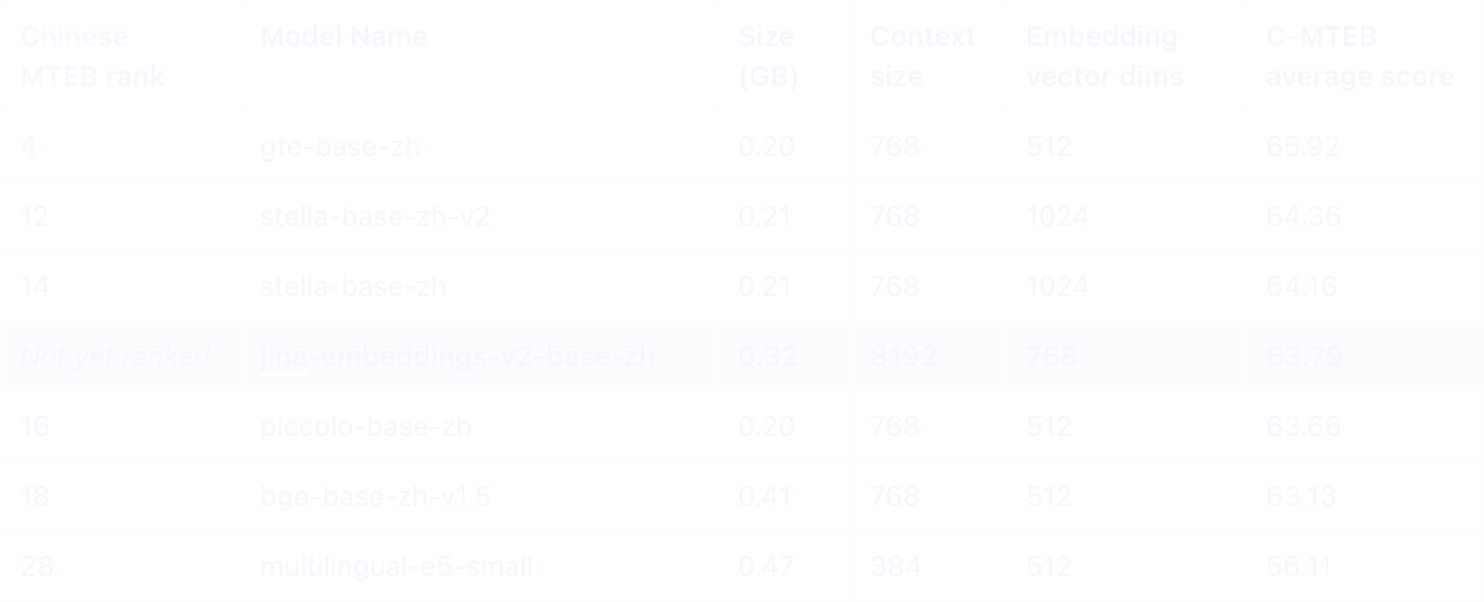
Среди китайских моделей аналогичного размера только многоязычная модель E5 и наша jina-embeddings-v2-base-zh предлагают поддержку английского языка, обеспечивая эффективные кросс-языковые приложения. Примечательно, что Jina демонстрирует значительно превосходящую производительность во всех категориях, связанных с китайским языком.

Хотя обе модели имеют контекст в 8K токенов, jina-embeddings-v2-base-zh значительно превосходит text-embedding-ada-002 от OpenAI, особенно в задачах, связанных с китайским языком.

tagПоддержка глобальной экспансии китайских предприятий
Наша китайско-английская модель эмбеддингов является мощным инструментом для китайских компаний, стремящихся к глобальному развитию (出海). Она беспрепятственно обрабатывает китайские тексты, предоставляя высококачественные эмбеддинги, которые легко интегрируются с ведущими векторными базами данных, поисковыми системами и RAG-приложениями.
jina-embeddings-v2-base-zh особенно полезна для разработки ИИ-приложений, адаптированных для китайско-английского контекста, что крайне важно для бизнеса, расширяющегося на международном уровне. Вот некоторые конкретные случаи использования:
- Анализ и управление документами: Она может анализировать и управлять большим количеством документов, помогая в международных юридических и бизнес-операциях.
- Поисковые приложения на базе ИИ: Улучшает функции поиска в многоязычной среде, облегчая глобальным пользователям поиск релевантной информации на китайском и английском языках.
- Чат-боты и системы вопросов-ответов с поддержкой RAG: Создает эффективных двуязычных ботов для обслуживания клиентов, улучшая взаимодействие с клиентами по всему миру.
- Приложения для обработки естественного языка: Включает анализ настроений для понимания глобальных рыночных тенденций, моделирование тем для международных маркетинговых стратегий и классификацию текстов для управления глобальной коммуникацией.
- Рекомендательные системы: Адаптирует рекомендации продуктов и контента для разнообразной глобальной аудитории, используя данные на китайском и английском языках.
Используя эту модель, китайские предприятия могут эффективно преодолевать языковой барьер в своих ИИ-приложениях, повышая свою глобальную конкурентоспособность и охват рынка.
tagНачало работы с jina-embeddings-v2-base-zh через API
Начните интегрировать нашу модель в свой рабочий процесс немедленно через API Embeddings. Просто посетите наш портал Embeddings, получите бесплатный ключ доступа или пополните существующий, а затем выберите jina-embeddings-v2-base-zh из выпадающего меню. Начать работу так просто!

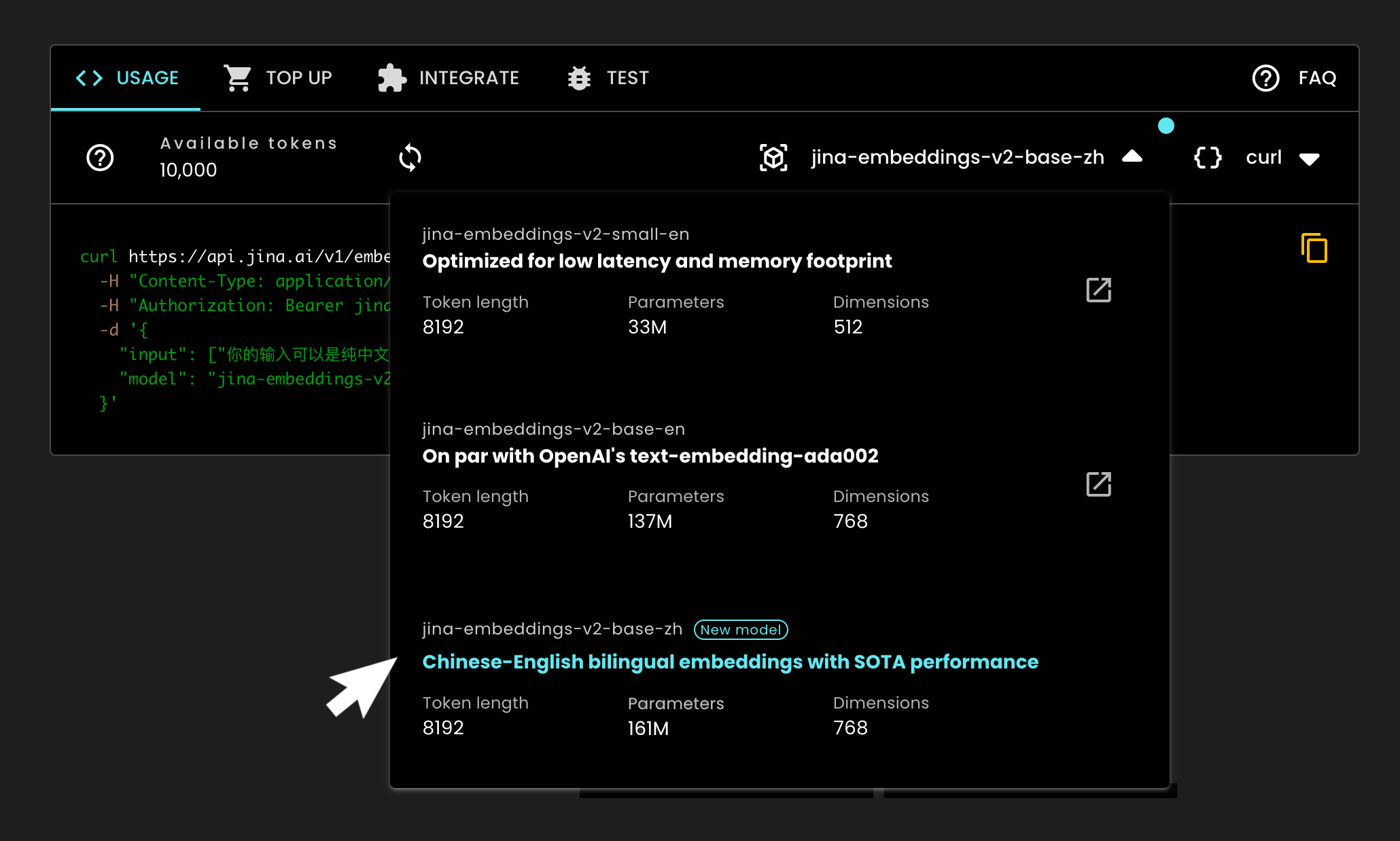
tagЧто дальше: Расширение языковой поддержки и интеграция с AWS Sagemaker
jina-embeddings-v2-base-zh скоро будет доступна через AWS Sagemaker и Hugging Face.



В Jina AI мы неуклонно придерживаемся нашего обязательства быть лидером в области доступных эмбеддинг-технологий для глобальной аудитории. Мы активно разрабатываем дополнительные многоязычные предложения, фокусируясь на основных европейских и других международных языках, чтобы расширить наш охват. Следите за этими захватывающими обновлениями, включая интеграцию с AWS SageMaker, пока мы продолжаем расширять наши возможности.
tagОсобая благодарность нашим ранним тестировщикам
Мы безмерно благодарны избранным членам нашего китайского сообщества пользователей, которые тестировали предварительную версию (jina-embeddings-v2-base-zh-preview). Их проницательные отзывы были крайне важны для улучшения производительности официального релиза. Если у вас есть какие-либо наблюдения или предложения относительно качества наших моделей, мы тепло приглашаем вас присоединиться к нашему серверу Discord и поделиться с нами своими мыслями. Ваш вклад неоценим в нашем непрерывном пути совершенствования.


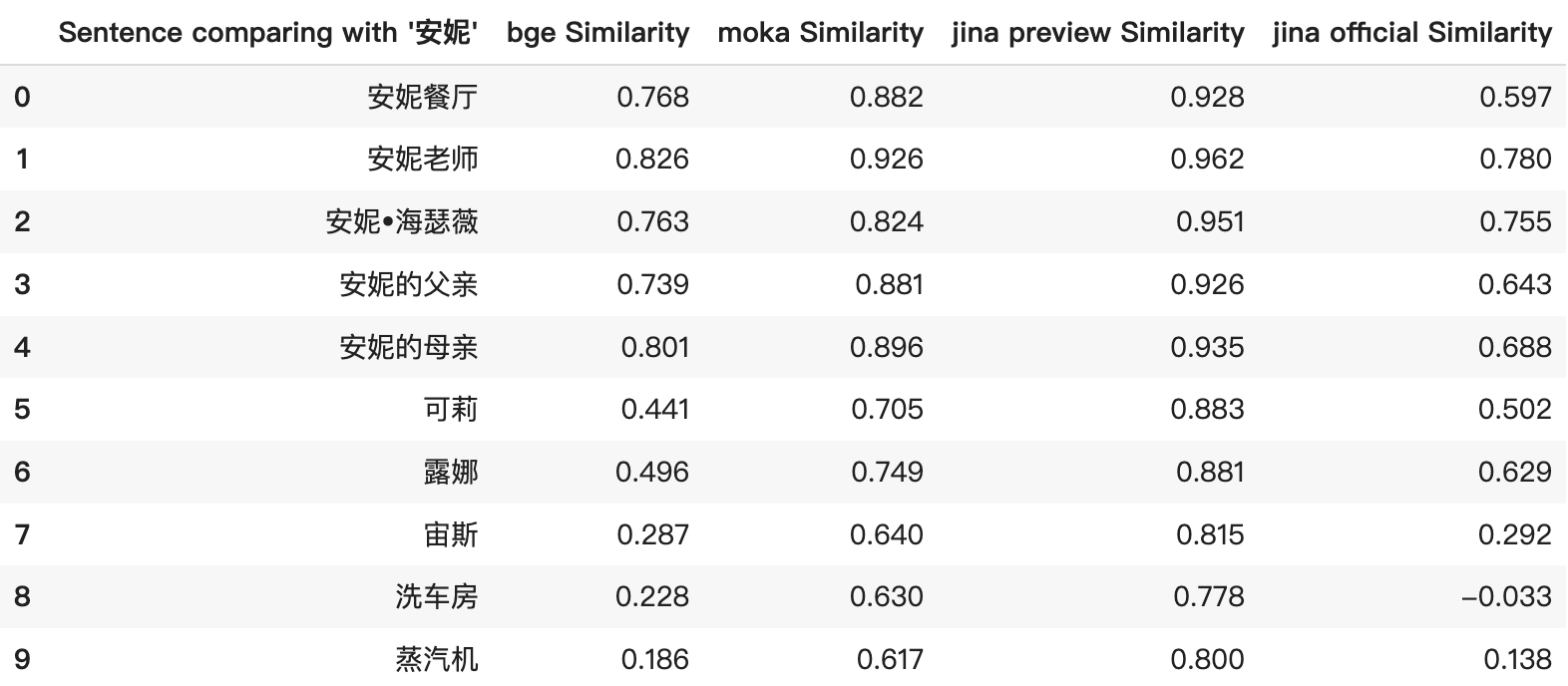
Улучшенное распределение оценок по сравнению с jina-embeddings-v2-base-zh-preview
jina-embeddings-v2-base-zh-preview имела завышенные оценки сходства, что приводило к высоким косинусным показателям даже для несвязанных элементов. Это было особенно заметно в топ-5 результатах на скриншоте ниже. Оценки сходства были стабильно высокими и не точно отражали реальную связь между элементами. Например, сравнение между "安妮" и "蒸汽机" получило обманчиво высокие оценки сходства.
В официальном релизе мы доработали модель для получения более различимых и логичных оценок сходства, обеспечивая более точное представление взаимосвязей между элементами. Например, пересмотренная система оценок теперь представляет более широкий диапазон, давая более четкое представление об относительном сходстве между элементами.
Кроме того, Jina Embeddings теперь является единственной моделью встраивания с открытым исходным кодом, поддерживающей 8192 токена. Эта особенность подчеркивает её способность обрабатывать широкий спектр типов данных, от обширных документов до коротких фраз или даже отдельных слов/имен, таких как "安妮" и "露娜".
tagНовая двуязычная китайско-английская векторная модель с поддержкой 8K: необходимый инструмент для выхода бизнеса на международный рынок!
После того как наш Embeddings V2 получил широкое признание, сегодня мы представляем новую двуязычную китайско-английскую векторную модель: jina-embeddings-v2-base-zh. Эта модель не только унаследовала все преимущества V2, способность обрабатывать тексты длиной до восьми тысяч токенов, но также может плавно работать с китайским и английским контентом, открывая новые возможности для межъязыковых приложений.
Превосходная производительность jina-embeddings-v2-base-zh обязана качественному двуязычному набору данных, прошедшему через наш строгий и сбалансированный процесс предварительного обучения, первичной и вторичной настройки. Этот трехэтапный подход к обучению не только обобщил двуязычные способности модели, но и эффективно снизил предвзятость модели, решая распространенную проблему "неравномерности" в многоязычных моделях.
tagОбзор особенностей модели
Особенность 1: Бесшовная двуязычная интеграция
Модель jina-embeddings-v2-base-zh способна плавно обрабатывать китайский и английский текст как для поисковых запросов, так и для целевых документов. Семантически близкие тексты на обоих языках отображаются в одном векторном пространстве, создавая прочную основу для многоязычных приложений.
Особенность 2: Поддержка длинных текстов до 8K токенов
Наша модель поддерживает обработку текстов длиной до 8K токенов, что является уникальным среди моделей с открытым исходным кодом и предоставляет значительное преимущество при обработке длинных текстовых фрагментов.
Особенность 3: Эффективная компактная структура модели
Модель jina-embeddings-v2-base-zh имеет компактный размер 322MB (включая 161 миллион параметров) с выходной размерностью 768, может эффективно работать на обычном компьютерном оборудовании без необходимости в GPU, что значительно повышает её практичность и удобство использования.
tagПревосходная производительность модели
В жесткой конкуренции рейтинга CMTEB наша модель Jina Embeddings v2 выделяется в категории моделей размером менее 0.5GB. Она не только поддерживает китайский и английский текст, но также может обрабатывать тексты длиной до 8K токенов, что является редкостью среди подобных моделей.
Среди моделей аналогичного размера с поддержкой китайского языка только Multilingual E5 и наша jina-embeddings-v2-base-zh могут обрабатывать английский язык, что делает возможными межъязыковые приложения.
В настоящее время во всем мире только закрытая модель OpenAI text-embedding-ada-002 и Jina Embeddings поддерживают ввод длинных текстов до 8k токенов. При этом в обработке китайских задач Jina Embeddings демонстрирует значительные преимущества в производительности.
tagПоддержка китайских компаний в развитии глобального бизнеса
Наша двуязычная векторная модель jina-embeddings-v2-base-zh является мощным партнером для китайских компаний, выходящих на международный рынок. Она может бесшовно обрабатывать тексты на китайском и английском языках, предоставляет высококачественное векторное представление текста и легко интегрируется в передовые векторные базы данных, поисковые системы и RAG-приложения.
Эта модель особенно подходит для создания AI-приложений, адаптированных к китайско-английским сценариям, и имеет неоценимое значение для компаний, стремящихся к глобальному развитию. Вот несколько практических примеров применения:
- Анализ и управление документами: анализ и управление массивными документами для содействия международным юридическим и коммерческим операциям.
- AI-приложения для поиска: улучшение эффективности поиска в многоязычной среде, помощь глобальным пользователям в легком поиске информации на китайском и английском языках.
- Улучшенные чат-боты и системы вопросов-ответов: создание эффективных двуязычных сервисных ботов, оптимизация коммуникации с глобальными клиентами.
- Приложения для обработки естественного языка: включая анализ глобальных рыночных тенденций, тематическое моделирование международных рыночных стратегий и классификацию текстов для глобальных коммуникаций.
- Рекомендательные системы: использование данных на китайском и английском языках для персонализированных рекомендаций продуктов и контента для глобальной аудитории.
С помощью этой модели китайские компании могут преодолеть языковой барьер в AI-приложениях и получить преимущество на глобальном рынке.
tagЛегкий старт с jina-embeddings-v2-base-zh
Хотите быстро интегрировать нашу двуязычную векторную модель в свой рабочий процесс? Всего несколько простых шагов: посетите https://jina.ai/embeddings, получите бесплатный API-ключ или обновите существующий, затем выберите jina-embeddings-v2-base-zh в выпадающем меню, и модель готова к использованию!
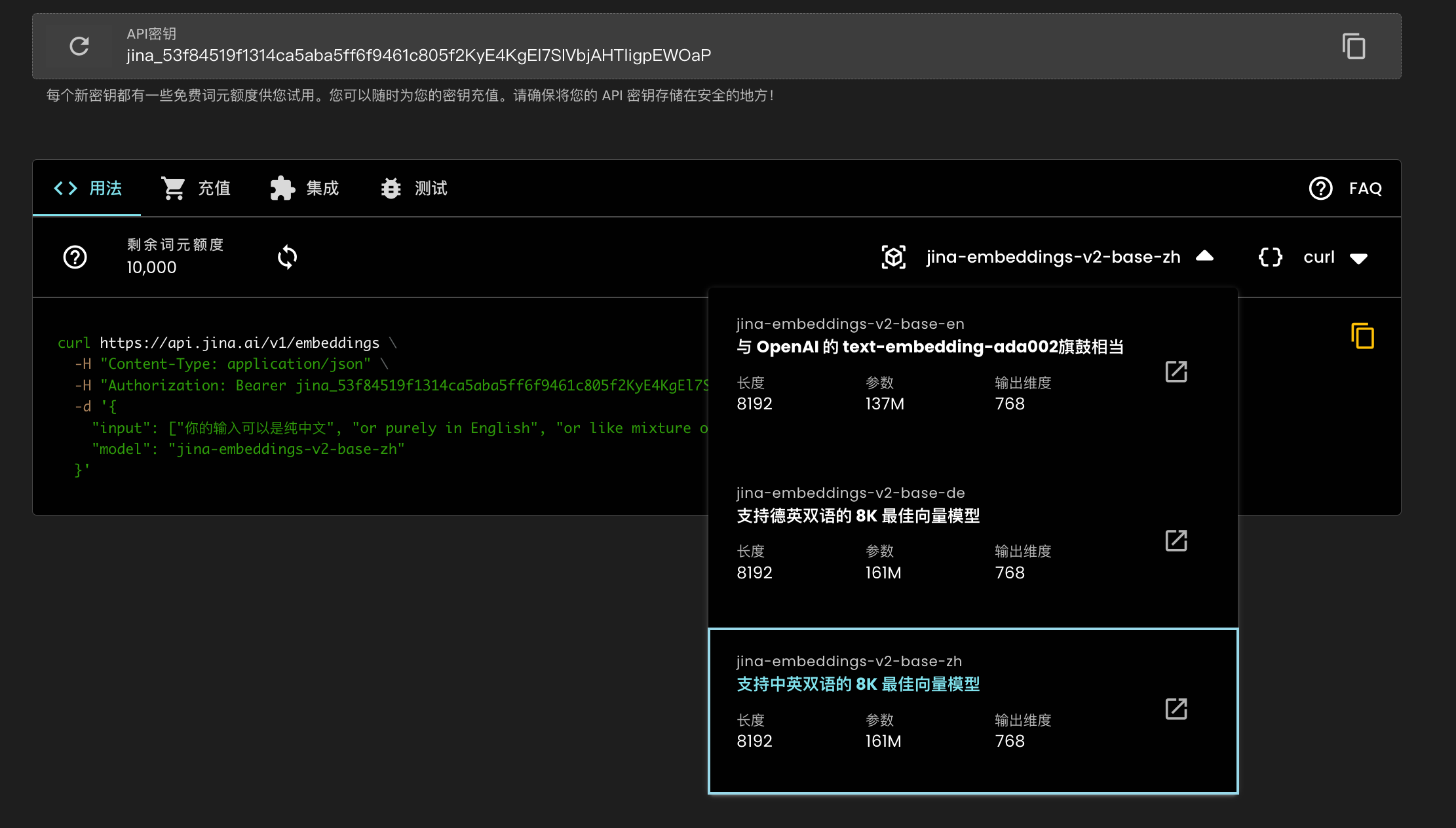
tagВзгляд в будущее: многоязычная поддержка и глубокая интеграция с AWS SageMaker
jina-embeddings-v2-base-zh скоро будет доступна на AWS SageMaker и HuggingFace, предоставляя пользователям еще более удобный сервис.
Мы активно развиваем многоязычные векторные модели, особенно поддержку европейских и других международных языков, чтобы удовлетворить разнообразные потребности глобальных пользователей. Следите за нашими захватывающими обновлениями, включая глубокую интеграцию с AWS SageMaker, мы продолжаем расширять и углублять наши сервисы.
tagБлагодарность: Спасибо ранним тестировщикам за ценный вклад
Мы искренне благодарим китайское сообщество, участвовавшее в тестировании jina-embeddings-v2-base-zh-preview. Ваши ценные отзывы сыграли важную роль в оптимизации нашей модели. Если у вас есть какие-либо предложения или идеи во время использования, пожалуйста, не стесняйтесь обращаться к нам. Каждый ваш отзыв является движущей силой нашего постоянного улучшения.
Релизная версия решила проблему инфляции оценок предварительной версии
По сравнению с предыдущей предварительной версией, релизная версия модели предоставляет более распределенные и разумные оценки сходства. В предварительной версии наша модель демонстрировала явление инфляции оценок сходства, где даже совершенно несвязанные слова, такие как "Анни" и "паровая машина", получали высокие оценки косинусного сходства. В релизной версии мы оптимизировали модель для обеспечения более разумных оценок сходства, которые точнее отражают взаимосвязь между содержанием.
Кроме того, Jina Embeddings теперь поддерживает обработку текста длиной до 8192 токенов, демонстрируя свою способность эффективно обрабатывать как длинные статьи, так и короткие фразы, и даже отдельные слова или имена (например, сравнение "Анни" и "Луны"). Это улучшение не только повысило точность модели, но и усилило ее гибкость и практичность при обработке разнообразных данных.
