

Существует множество препятствий для понимания AI-моделей, некоторые из них довольно серьезные, и они могут мешать внедрению AI-процессов. Но первое, с чем сталкиваются многие люди — это понимание того, что мы имеем в виду, когда говорим о токенах.

Одним из важнейших практических параметров при выборе языковой AI-модели является размер ее контекстного окна — максимальный размер входного текста — который измеряется в токенах, а не в словах, символах или других автоматически распознаваемых единицах.
Более того, сервисы эмбеддингов обычно тарифицируются "за токен", что означает, что токены важны для понимания вашего счета.
Это может быть очень запутанно, если вы не понимаете, что такое токен.
Но из всех запутанных аспектов современного AI, токены, вероятно, наименее сложны. В этой статье мы постараемся разъяснить, что такое токенизация, что она делает и почему мы делаем это именно так.
tagкратко
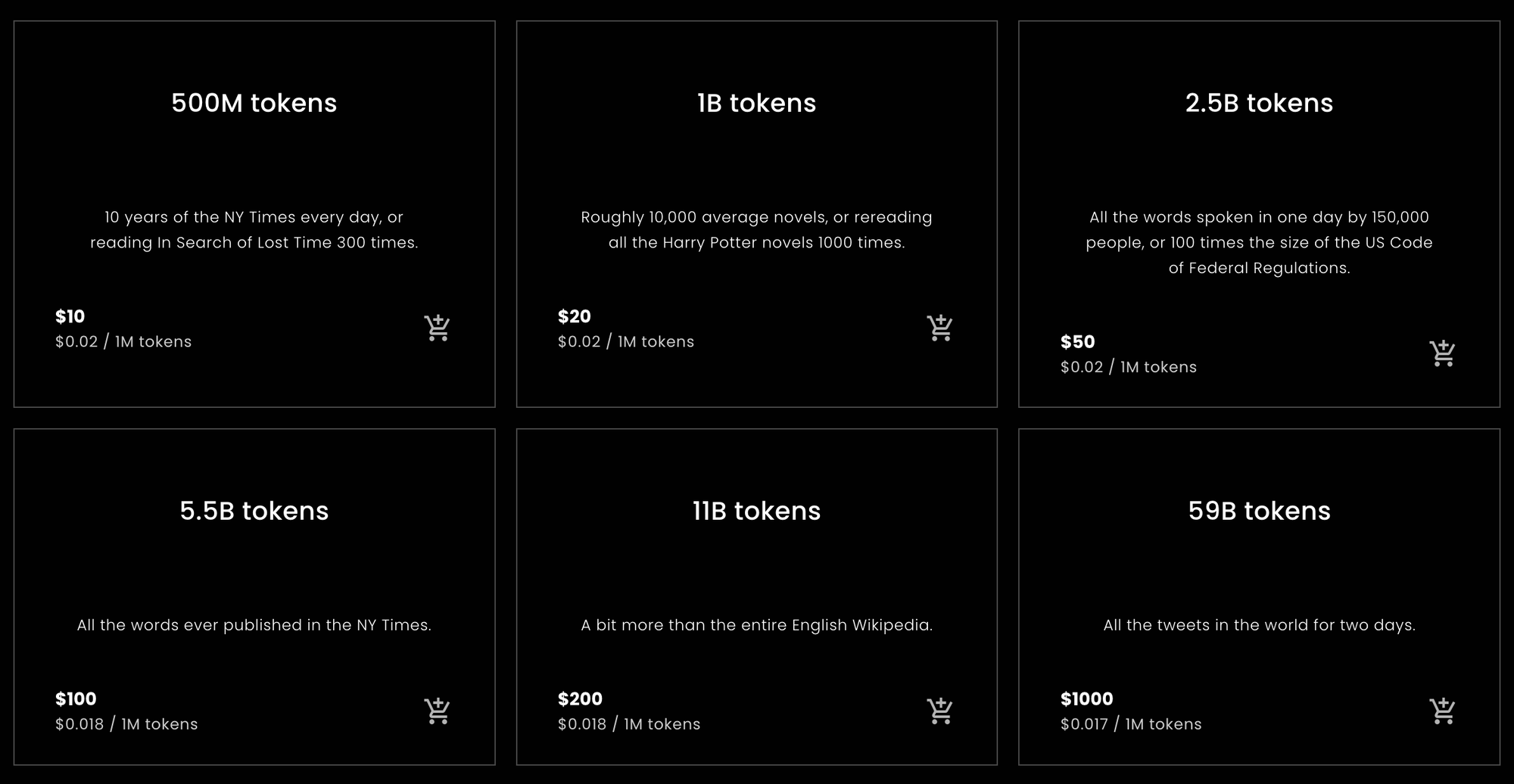
Для тех, кто хочет или нуждается в быстром ответе, чтобы понять, сколько токенов купить у Jina Embeddings или оценить, сколько им нужно будет купить, вот необходимая статистика.
tagТокены на английское слово
При эмпирическом тестировании, описанном ниже в этой статье, различные английские тексты конвертировались в токены с соотношением примерно на 10% больше токенов, чем слов, при использовании моделей Jina Embeddings только для английского языка. Этот результат был довольно устойчивым.
Модели Jina Embeddings v2 имеют контекстное окно размером 8192 токена. Это означает, что если вы передадите модели Jina английский текст длиннее 7 400 слов, есть большая вероятность, что он будет обрезан.
tagТокены на китайский иероглиф
Для китайского языка результаты более переменчивы. В зависимости от типа текста, соотношения варьировались от 0,6 до 0,75 токенов на китайский иероглиф (汉字). Английские тексты, переданные в Jina Embeddings v2 для китайского языка, производят примерно такое же количество токенов, как и Jina Embeddings v2 для английского: примерно на 10% больше, чем количество слов.
tagТокены на немецкое слово
Соотношение слов к токенам в немецком языке более переменчиво, чем в английском, но менее, чем в китайском. В зависимости от жанра текста, в среднем получалось на 20-30% больше токенов, чем слов. При передаче английских текстов в Jina Embeddings v2 для немецкого и английского языков используется немного больше токенов, чем в моделях только для английского и китайского/английского языков: на 12-15% больше токенов, чем слов.
tagПредостережение
Это простые расчеты, но они должны быть приблизительно верны для большинства естественных текстов и большинства пользователей. В конечном счете, мы можем только обещать, что количество токенов всегда будет не больше количества символов в вашем тексте плюс два. Практически всегда оно будет намного меньше, но мы не можем заранее обещать какое-либо конкретное количество.
Это оценки, основанные на статистически наивных расчетах. Мы не гарантируем, сколько токенов потребует конкретный запрос.
Если вам нужен только совет о том, сколько токенов купить для Jina Embeddings, можете остановиться здесь. Другие модели эмбеддингов от компаний, отличных от Jina AI, могут иметь другие соотношения токенов к словам и токенов к китайским иероглифам, чем у моделей Jina, но в целом они не будут сильно отличаться.
Если вы хотите понять почему, остальная часть этой статьи представляет собой более глубокое погружение в токенизацию для языковых моделей.
tagСлова, токены, числа
Токенизация была частью обработки естественного языка еще до появления современных AI-моделей.
Немного банально говорить, что все в компьютере — это просто числа, но это в основном правда. Однако язык по своей природе не является просто набором чисел. Это может быть речь, состоящая из звуковых волн, или письмо, состоящее из отметок на бумаге, или даже изображение печатного текста или видео того, как кто-то использует язык жестов. Но чаще всего, когда мы говорим об использовании компьютеров для обработки естественного языка, мы имеем в виду тексты, состоящие из последовательностей символов: букв (a, b, c и т.д.), цифр (0, 1, 2…), знаков пунктуации и пробелов на разных языках и в разных текстовых кодировках.
Компьютерные инженеры называют их "строками".
AI-модели языка принимают на вход последовательности чисел. Так что вы можете написать предложение:
What is today's weather in Berlin?
Но после токенизации AI-модель получает на вход:
[101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102]
Токенизация — это процесс преобразования входной строки в определенную последовательность чисел, которую ваша AI-модель может понять.
Когда вы используете AI-модель через веб-API, который взимает плату с пользователей за токен, каждый запрос преобразуется в последовательность чисел, подобную показанной выше. Количество токенов в запросе — это длина этой последовательности чисел. Таким образом, если вы попросите Jina Embeddings v2 for English дать вам эмбеддинг для "What is today's weather in Berlin?", это будет стоить вам 11 токенов, потому что она преобразовала это предложение в последовательность из 11 чисел перед передачей его AI-модели.
AI-модели, основанные на архитектуре Transformer, имеют фиксированного размера контекстное окно, размер которого измеряется в токенах. Иногда это называют "входным окном", "размером контекста" или "длиной последовательности" (особенно на лидерборде MTEB Hugging Face). Это означает максимальный размер текста, который модель может видеть одновременно.
Так что если вы хотите использовать модель эмбеддингов, это максимально допустимый размер входных данных.
Модели Jina Embeddings v2 все имеют контекстное окно размером 8 192 токена. Другие модели будут иметь другие (как правило, меньшие) контекстные окна. Это означает, что какой бы текст вы ни подали на вход, токенизатор, связанный с этой моделью Jina Embeddings, должен преобразовать его не более чем в 8 192 токена.
tagОтображение языка в числа
Самый простой способ объяснить логику токенов следующий:
Для моделей естественного языка часть строки, которую представляет токен, — это слово, часть слова или знак пунктуации. Пробелы обычно не имеют явного представления в выводе токенизатора.
Токенизация является частью группы техник в обработке естественного языка, называемых сегментацией текста, а модуль, выполняющий токенизацию, называется, вполне логично, токенизатором.
Чтобы показать, как работает токенизация, мы собираемся токенизировать несколько предложений, используя самую маленькую модель Jina Embeddings v2 для английского языка: jina-embeddings-v2-small-en. Другая модель Jina Embeddings только для английского языка — jina-embeddings-v2-base-en — использует тот же токенизатор, поэтому нет смысла скачивать дополнительные мегабайты AI-модели, которые мы не будем использовать в этой статье.
Сначала установите модуль transformers в вашей среде Python или блокноте. Используйте
-U, чтобы установить последнюю версию, так как эта модель не работает с некоторыми старыми версиями:pip install -U transformers
Затем загрузите jina-embeddings-v2-small-en, используя AutoModel.from_pretrained:
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-small-en', trust_remote_code=True)
Для токенизации строки используйте метод encode объекта tokenizer модели:
model.tokenizer.encode("What is today's weather in Berlin?")
Результат - список чисел:
[101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102]
Чтобы преобразовать эти числа обратно в строковую форму, используйте метод convert_ids_to_tokens объекта tokenizer:
model.tokenizer.convert_ids_to_tokens([101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102])
Результат - список строк:
['[CLS]', 'what', 'is', 'today', "'", 's', 'weather', 'in',
'berlin', '?', '[SEP]']
Обратите внимание, что токенизатор модели:
- Добавил
[CLS]в начало и[SEP]в конец. Это необходимо по техническим причинам и означает, что каждый запрос на эмбеддинг будет стоить два дополнительных токена, помимо количества токенов самого текста. - Разделил пунктуацию и слова, превратив "Berlin?" в:
berlinи?, а "today's" вtoday,'иs. - Перевел все в нижний регистр. Не все модели делают это, но это может помочь при обучении для английского языка. Это может быть менее полезно в языках, где заглавные буквы имеют другое значение.
Разные алгоритмы подсчета слов в разных программах могут по-разному считать слова в этом предложении. OpenOffice считает это как шесть слов. Алгоритм сегментации текста Unicode (Unicode Standard Annex #29) считает семь слов. Другое программное обеспечение может прийти к другим числам, в зависимости от того, как они обрабатывают пунктуацию и клитики вроде "'s".
Токенизатор этой модели создает девять токенов для этих шести или семи слов, плюс два дополнительных токена, необходимых для каждого запроса.
Теперь давайте попробуем с менее распространенным названием места, чем Берлин:
token_ids = model.tokenizer.encode("I live in Kinshasa.")
tokens = model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
Результат:
['[CLS]', 'i', 'live', 'in', 'kin', '##sha', '##sa', '.', '[SEP]']
Название "Kinshasa" разбито на три токена: kin, ##sha и ##sa. ## указывает, что этот токен не является началом слова.
Если мы дадим токенизатору что-то совершенно чужеродное, количество токенов по отношению к количеству слов увеличится еще больше:
token_ids = model.tokenizer.encode("Klaatu barada nikto")
tokens = model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
['[CLS]', 'k', '##la', '##at', '##u', 'bar', '##ada', 'nik', '##to', '[SEP]']
Три слова превращаются в восемь токенов, плюс токены [CLS] и [SEP].
Токенизация в немецком языке похожа. С помощью модели Jina Embeddings v2 для немецкого языка, мы можем токенизировать перевод "What is today's weather in Berlin?" тем же способом, что и с английской моделью.
german_model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-de', trust_remote_code=True)
token_ids = german_model.tokenizer.encode("Wie wird das Wetter heute in Berlin?")
tokens = german_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
Результат:
['<s>', 'Wie', 'wird', 'das', 'Wetter', 'heute', 'in', 'Berlin', '?', '</s>']
Этот токенизатор немного отличается от английского тем, что <s> и </s> заменяют [CLS] и [SEP], но выполняют ту же функцию. Кроме того, текст не нормализуется по регистру — верхний и нижний регистры остаются как написаны — потому что в немецком языке заглавные буквы имеют другое значение, чем в английском.
(Для упрощения этой презентации я убрал специальный символ, обозначающий начало слова.)
Теперь давайте попробуем более сложное предложение из газетного текста:
Ein Großteil der milliardenschweren Bauern-Subventionen bleibt liegen – zu genervt sind die Landwirte von bürokratischen Gängelungen und Regelwahn.
sentence = """
Ein Großteil der milliardenschweren Bauern-Subventionen
bleibt liegen – zu genervt sind die Landwirte von
bürokratischen Gängelungen und Regelwahn.
"""
token_ids = german_model.tokenizer.encode(sentence)
tokens = german_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)Результат токенизации:
['<s>', 'Ein', 'Großteil', 'der', 'mill', 'iarden', 'schwer',
'en', 'Bauern', '-', 'Sub', 'ventionen', 'bleibt', 'liegen',
'–', 'zu', 'gen', 'ervt', 'sind', 'die', 'Landwirte', 'von',
'büro', 'krat', 'ischen', 'Gän', 'gel', 'ungen', 'und', 'Regel',
'wahn', '.', '</s>']
Здесь вы видите, что многие немецкие слова были разбиты на более мелкие части, и не обязательно по правилам немецкой грамматики. В результате длинное немецкое слово, которое считалось бы одним словом для счетчика слов, может состоять из любого количества токенов для AI-модели Jina.
Давайте сделаем то же самое на китайском, переведя "What is today's weather in Berlin?" как:
柏林今天的天气怎么样?
chinese_model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
token_ids = chinese_model.tokenizer.encode("柏林今天的天气怎么样?")
tokens = chinese_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
Результат токенизации:
['<s>', '柏林', '今天的', '天气', '怎么样', '?', '</s>']
В китайском языке обычно нет разрывов между словами в письменном тексте, но токенизатор Jina Embeddings часто объединяет несколько китайских иероглифов вместе:
| Token string | Pinyin | Meaning |
|---|---|---|
| 柏林 | Bólín | Berlin |
| 今天的 | jīntiān de | today's |
| 天气 | tiānqì | weather |
| 怎么样 | zěnmeyàng | how |
Давайте используем более сложное предложение из гонконгской газеты:
sentence = """
新規定執行首日,記者在下班高峰前的下午5時來到廣州地鐵3號線,
從繁忙的珠江新城站啟程,向機場北方向出發。
"""
token_ids = chinese_model.tokenizer.encode(sentence)
tokens = chinese_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
(Перевод: «В первый день вступления в силу новых правил репортер прибыл на линию 3 метро Гуанчжоу в 17:00, в час пик, отправившись со станции Чжуцзян Нью-Таун в направлении аэропорта»)
Результат:
['<s>', '新', '規定', '執行', '首', '日', ',', '記者', '在下', '班',
'高峰', '前的', '下午', '5', '時', '來到', '廣州', '地', '鐵', '3',
'號', '線', ',', '從', '繁忙', '的', '珠江', '新城', '站', '啟',
'程', ',', '向', '機場', '北', '方向', '出發', '。', '</s>']
Эти токены не соответствуют какому-либо конкретному словарю китайских слов (词典). Например, "啟程" - qǐchéng (отправляться, уезжать) обычно классифицируется как одно слово, но здесь разделено на два составляющих иероглифа. Аналогично, "在下班" обычно распознается как два слова, с разделением между "在" - zài (в, во время) и "下班" - xiàbān (конец рабочего дня, час пик), а не между "在下" и "班", как это сделал токенизатор.
Во всех трех языках места разделения текста токенизатором напрямую не связаны с логическими местами, где их разделил бы человек при чтении.
Это не является особенностью только моделей Jina Embeddings. Такой подход к токенизации практически универсален в разработке AI-моделей. Хотя у двух разных AI-моделей могут быть неидентичные токенизаторы, на текущем этапе развития они практически все используют токенизаторы с таким поведением.
В следующем разделе будет обсуждаться конкретный алгоритм, используемый при токенизации, и логика, лежащая в его основе.
tagЗачем мы токенизируем? И почему именно так?
AI языковые модели принимают на вход последовательности чисел, которые представляют текстовые последовательности, но перед запуском базовой нейронной сети и созданием эмбеддинга происходит еще кое-что. Когда модели представляется список чисел, представляющих небольшие текстовые последовательности, она ищет каждое число во внутреннем словаре, который хранит уникальный вектор для каждого числа. Затем она объединяет их, и это становится входом для нейронной сети.
Это означает, что токенизатор должен уметь преобразовывать любой входной текст, который мы ему даем, в токены, присутствующие в словаре векторов модели. Если бы мы брали наши токены из обычного словаря, при первой же встрече с опечаткой, редким именем собственным или иностранным словом вся модель бы остановилась. Она не смогла бы обработать такой ввод.
В обработке естественного языка это называется проблемой слов вне словаря (out-of-vocabulary, OOV), и она встречается во всех типах текстов и во всех языках. Существует несколько стратегий решения проблемы OOV:
- Игнорировать ее. Заменять все, чего нет в словаре, токеном "неизвестно".
- Обойти ее. Вместо использования словаря, который сопоставляет текстовые последовательности с векторами, использовать тот, который сопоставляет отдельные символы с векторами. В английском в основном используется только 26 букв, поэтому это должно быть меньше и устойчивее к проблемам OOV, чем любой словарь.
- Найти частые подпоследовательности в тексте, поместить их в словарь и использовать символы (однобуквенные токены) для всего остального.
Первая стратегия означает потерю большого количества важной информации. Модель даже не может учиться на данных, которые она видит, если они принимают форму чего-то, чего нет в словаре. Многих вещей в обычном тексте просто нет даже в самых больших словарях.
Вторая стратегия возможна, и исследователи ее изучали. Однако это означает, что модель должна принимать гораздо больше входных данных и должна учиться гораздо большему. Это означает гораздо большую модель и гораздо больше обучающих данных для результата, который никогда не оказывался лучше третьей стратегии.
Языковые модели AI в основном все реализуют третью стратегию в той или иной форме. Большинство использует какой-либо вариант алгоритма Wordpiece [Schuster and Nakajima 2012] или похожую технику, называемую Byte-Pair Encoding (BPE). [Gage 1994, Senrich et al. 2016] Эти алгоритмы являются языконезависимыми. Это означает, что они работают одинаково для всех письменных языков без каких-либо знаний, кроме полного списка возможных символов. Они были разработаны для многоязычных моделей, таких как BERT от Google, которые принимают любые входные данные из интернета — сотни языков и тексты, отличные от человеческого языка, например компьютерные программы — чтобы их можно было обучать без сложной лингвистики.
Некоторые исследования показывают значительные улучшения при использовании более специфичных для языка токенизаторов. [Rust et al. 2021] Но создание таких токенизаторов требует времени, денег и опыта. Реализация универсальной стратегии, такой как BPE или Wordpiece, намного дешевле и проще.
Однако, как следствие, нет способа узнать, сколько токенов представляет конкретный текст, кроме как пропустить его через токенизатор и затем посчитать количество получившихся токенов. Поскольку наименьшая возможная подпоследовательность текста — это одна буква, можно быть уверенным, что количество токенов не будет больше, чем количество символов (минус пробелы) плюс два.
Чтобы получить хорошую оценку, нам нужно пропустить много текста через наш токенизатор и эмпирически рассчитать, сколько токенов мы получаем в среднем по сравнению с количеством введенных слов или символов. В следующем разделе мы проведем не очень систематические эмпирические измерения для всех доступных в настоящее время моделей Jina Embeddings v2.
tagЭмпирические оценки размеров выходных токенов
Для английского и немецкого языков я использовал алгоритм сегментации текста Unicode (Unicode Standard Annex #29) для подсчета слов в текстах. Этот алгоритм широко используется для выделения фрагментов текста при двойном щелчке. Это самое близкое к универсальному объективному счетчику слов, что доступно.
Я установил библиотеку polyglot в Python, которая реализует этот сегментатор текста:
pip install -U polyglot
Чтобы получить количество слов в тексте, можно использовать код вроде этого фрагмента:
from polyglot.text import Text
txt = "What is today's weather in Berlin?"
print(len(Text(txt).words))
Результат должен быть 7.
Для подсчета токенов фрагменты текста передавались токенизаторам различных моделей Jina Embeddings, как описано ниже, и каждый раз я вычитал два из количества возвращенных токенов.
tagАнглийский
(jina-embeddings-v2-small-en и jina-embeddings-v2-base-en)
Для расчета средних значений я загрузил два английских текстовых корпуса с Wortschatz Leipzig, коллекции свободно загружаемых корпусов на нескольких языках и в разных конфигурациях, размещенной Лейпцигским университетом:
- Корпус из миллиона предложений новостных данных на английском языке за 2020 год (
eng_news_2020_1M) - Корпус из миллиона предложений данных английской Википедии за 2016 год (
eng_wikipedia_2016_1M)
Оба можно найти на их странице загрузок английского языка.
Для разнообразия я также загрузил перевод Хэпгуда романа Виктора Гюго «Отверженные» с Project Gutenberg и копию Библии короля Якова, переведенной на английский язык в 1611 году.
Для всех четырех текстов я подсчитал слова, используя сегментатор Unicode, реализованный в polyglot, затем подсчитал токены, созданные jina-embeddings-v2-small-en, вычитая два токена для каждого запроса токенизации. Результаты следующие:
| Текст | Количество слов (сегментатор Unicode) | Количество токенов (Jina Embeddings v2 для английского) | Отношение токенов к словам (до 3 знаков после запятой) |
|---|---|---|---|
eng_news_2020_1M | 22 825 712 | 25 270 581 | 1,107 |
eng_wikipedia_2016_1M | 24 243 607 | 26 813 877 | 1,106 |
les_miserables_en | 688 911 | 764 121 | 1,109 |
kjv_bible | 1 007 651 | 1 099 335 | 1,091 |
Использование точных чисел не означает, что это точный результат. То, что документы столь разных жанров имеют на 9-11% больше токенов, чем слов, указывает на то, что вы можете ожидать примерно на 10% больше токенов, чем слов, согласно сегментатору Unicode. Текстовые редакторы часто не учитывают пунктуацию, в то время как сегментатор Unicode учитывает, поэтому не стоит ожидать, что подсчет слов в офисном ПО будет соответствовать этим данным.
tagНемецкий
(jina-embeddings-v2-base-de)
Для немецкого языка я загрузил три корпуса со страницы немецкого языка Wortschatz Leipzig:
deu_mixed-typical_2011_1M— Миллион предложений из сбалансированной смеси текстов разных жанров за 2011 год.deu_newscrawl-public_2019_1M— Миллион предложений новостных текстов за 2019 год.deu_wikipedia_2021_1M— Миллион предложений, извлеченных из немецкой Википедии в 2021 году.
А для разнообразия я также загрузил все три тома «Капитала» Карла Маркса из Deutsches Textarchiv.
Затем я следовал той же процедуре, что и для английского:
| Текст | Количество слов (Unicode Segmenter) | Количество токенов (Jina Embeddings v2 для немецкого и английского) | Отношение токенов к словам (до 3 знаков после запятой) |
|---|---|---|---|
deu_mixed-typical_2011_1M | 7 924 024 | 9 772 652 | 1,234 |
deu_newscrawl-public_2019_1M | 17 949 120 | 21 711 555 | 1,210 |
deu_wikipedia_2021_1M | 17 999 482 | 22 654 901 | 1,259 |
marx_kapital | 784 336 | 1 011 377 | 1,289 |
Эти результаты имеют больший разброс, чем у модели только для английского языка, но всё же показывают, что немецкий текст будет давать в среднем на 20-30% больше токенов, чем слов.
Английские тексты дают больше токенов с немецко-английским токенизатором, чем с токенизатором только для английского:
| Текст | Количество слов (Unicode Segmenter) | Количество токенов (Jina Embeddings v2 для немецкого и английского) | Отношение токенов к словам (до 3 знаков после запятой) |
|---|---|---|---|
eng_news_2020_1M | 24 243 607 | 27 758 535 | 1,145 |
eng_wikipedia_2016_1M | 22 825 712 | 25 566 921 | 1,120 |
Следует ожидать, что для встраивания английских текстов с двуязычным немецко-английским токенизатором потребуется на 12-15% больше токенов, чем с токенизатором только для английского.
tagКитайский
(jina-embeddings-v2-base-zh)
Китайский язык традиционно пишется без пробелов и до 20-го века не имел традиционного понятия "слов". Следовательно, размер китайского текста обычно измеряется в символах (字数). Поэтому вместо использования сегментатора Unicode я измерял длину китайских текстов, удаляя все пробелы и затем просто получая длину в символах.
Я загрузил три корпуса со страницы китайского корпуса Wortschatz Leipzig:
zho_wikipedia_2018_1M— Миллион предложений из китайскоязычной Википедии, извлечённых в 2018 году.zho_news_2007-2009_1M— Миллион предложений из китайских новостных источников, собранных с 2007 по 2009 год.zho-trad_newscrawl_2011_1M— Миллион предложений из новостных источников, использующих исключительно традиционные китайские иероглифы (繁體字).
Кроме того, для разнообразия я также использовал «Подлинную историю А-кью» (阿Q正傳), повесть Лу Синя (魯迅), написанную в начале 1920-х годов. Я загрузил версию с традиционными иероглифами из Project Gutenberg.
| Текст | Количество символов (字数) | Количество токенов (Jina Embeddings v2 для китайского и английского) | Отношение токенов к символам (до 3 знаков после запятой) |
|---|---|---|---|
zho_wikipedia_2018_1M | 45 116 182 | 29 193 028 | 0,647 |
zho_news_2007-2009_1M | 44 295 314 | 28 108 090 | 0,635 |
zho-trad_newscrawl_2011_1M | 54,585,819 | 40,290,982 | 0.738 |
Ah_Q | 41,268 | 25,346 | 0.614 |
Такой разброс в соотношении токенов к символам неожиданный, и особенно выброс для корпуса с традиционными иероглифами заслуживает дальнейшего исследования. Тем не менее, мы можем заключить, что для китайского языка вам потребуется меньше токенов, чем символов в вашем тексте. В зависимости от содержания, можно ожидать, что потребуется на 25% - 40% меньше.
Английские тексты в Jina Embeddings v2 для китайского и английского языков дали примерно то же количество токенов, что и в модели только для английского языка:
| Text | Word count (Unicode Segmenter) | Token count (Jina Embeddings v2 for Chinese and English) | Ratio of tokens to words (to 3 decimal places) |
|---|---|---|---|
eng_news_2020_1M | 24,243,607 | 26,890,176 | 1.109 |
eng_wikipedia_2016_1M | 22,825,712 | 25,060,352 | 1.097 |
tagОтносимся к токенам серьезно
Токены являются важной основой для языковых моделей ИИ, и исследования в этой области продолжаются.
Одним из мест, где модели ИИ оказались революционными, стало открытие того, что они очень устойчивы к зашумленным данным. Даже если конкретная модель не использует оптимальную стратегию токенизации, при достаточно большой сети, достаточном количестве данных и адекватном обучении, она может научиться делать правильные вещи из несовершенных входных данных.
Следовательно, на улучшение токенизации тратится гораздо меньше усилий, чем в других областях, но это может измениться.
Как пользователь эмбеддингов, который покупает их через API вроде Jina Embeddings, вы не можете точно знать, сколько токенов вам понадобится для конкретной задачи, и, возможно, придется провести собственное тестирование, чтобы получить точные цифры. Но оценки, приведенные здесь — около 110% от количества слов для английского, около 125% от количества слов для немецкого и около 70% от количества символов для китайского — должны быть достаточными для базового планирования бюджета.






