


Поздно ночью полицейский находит пьяного человека, ползающего на четвереньках под уличным фонарем. Пьяный говорит офицеру, что ищет свой кошелек. Когда офицер спрашивает, уверен ли он, что потерял кошелек именно здесь, мужчина отвечает, что, вероятнее всего, он уронил его на другой стороне улицы. "Тогда почему вы ищете здесь?" - озадаченно спрашивает офицер. "Потому что здесь светлее", - объясняет пьяный.
Дэвид Х. Фридман, Почему научные исследования так часто ошибочны: Эффект уличного фонаря, журнал Discover, декабрь 2010
Бенчмарки уже давно являются ключевым компонентом современных практик машинного обучения, но у них есть очень серьезная проблема: мы не можем определить, измеряют ли наши бенчмарки что-то действительно полезное.
Это большая проблема, и эта статья представит часть решения: AIR-Bench. Этот совместный проект с Пекинской академией искусственного интеллекта представляет собой новый подход к метрикам ИИ, призванный улучшить качество и полезность наших бенчмарков.


tagЭффект уличного фонаря
Научные и операционные исследования уделяют большое внимание измерениям, но измерения – это не простая вещь. В медицинском исследовании вы можете хотеть узнать, сделало ли лекарство или лечение пациентов более здоровыми, увеличило ли продолжительность их жизни или улучшило их состояние каким-либо образом. Но здоровье и улучшение качества жизни трудно измерить напрямую, и может потребоваться десятилетия, чтобы выяснить, продлило ли лечение чью-то жизнь.
Поэтому исследователи используют прокси-показатели. В медицинском исследовании это может быть что-то вроде физической силы, уменьшения боли, снижения кровяного давления или какая-либо другая переменная, которую можно легко измерить. Одна из проблем медицинских исследований заключается в том, что прокси-показатель может на самом деле не указывать на тот лучший результат для здоровья, которого вы хотите достичь с помощью лекарства или лечения.
Измерение – это прокси для чего-то полезного, что имеет для вас значение. Возможно, вы не можете измерить эту вещь, поэтому вы измеряете что-то другое, что-то, что вы можете измерить, и у вас есть основания полагать, что это коррелирует с полезной вещью, которая вас действительно интересует.
Фокус на измерениях был важным достижением исследований операций 20-го века и имел некоторые глубокие и положительные эффекты. Total Quality Management, набор доктрин, которому приписывают подъем Японии к экономическому доминированию в 1980-х годах, почти полностью посвящен постоянному измерению прокси-переменных и оптимизации практик на этой основе.
Но фокус на измерениях создает некоторые известные, большие проблемы:
- Измерение может перестать быть хорошим прокси, когда вы принимаете решения на его основе.
- Часто существуют способы искусственно увеличить показатель, которые не улучшают ничего, что приводит к возможности обмана или веры в то, что вы делаете прогресс, делая вещи, которые не помогают.
Некоторые люди считают, что большинство медицинских исследований может быть просто ошибочным отчасти из-за этой проблемы. Разрыв между тем, что можно измерить, и реальными целями является одной из причин, упоминаемых для объяснения катастрофы американской войны во Вьетнаме.
Это иногда называют "Эффектом уличного фонаря", по историям, подобным той, что в начале этой страницы, о пьяном, который ищет что-то не там, где потерял, а там, где светлее. Прокси-измерение подобно поиску там, где есть свет, потому что нет света там, где находится то, что мы хотим увидеть.
В более технической литературе "Эффект уличного фонаря" обычно связывают с Законом Гудхарта, названным в честь критики британского экономиста Чарльза Гудхарта правительства Тэтчер, которое уделяло большое внимание прокси-показателям процветания. Закон Гудхарта имеет несколько формулировок, но наиболее часто цитируется следующая:
[К]аждый показатель, который становится целью, становится плохим показателем[…]
Кит Хоскинс, 1996 "Ужасная идея подотчетности": вписывание людей в измерение объектов.00s
В ИИ известным примером этого является метрика BLEU, используемая в исследованиях машинного перевода. Разработанная в 2001 году в IBM, BLEU – это способ автоматизировать оценку систем машинного перевода, и она была ключевым фактором в буме машинного перевода 2000-х годов. Как только стало легко присваивать вашей системе оценку, вы могли работать над ее улучшением. И оценки BLEU постоянно улучшались. К 2010 году стало практически невозможно опубликовать исследовательскую статью по машинному переводу в журнале или на конференции, если она не превосходила лучший показатель BLEU, независимо от того, насколько инновационной была статья или насколько хорошо она могла справляться с какой-то конкретной проблемой, с которой другие системы справлялись плохо.
Самым простым способом попасть на конференцию было найти какой-нибудь незначительный способ поиграть с параметрами вашей модели, получить оценку BLEU немного выше, чем у Google Translate, и затем подать заявку. Эти результаты были по сути бесполезны. Достаточно было просто взять какие-то новые тексты для перевода, чтобы увидеть, что они редко были лучше и часто хуже, чем передовые системы.
Вместо использования BLEU для оценки прогресса в машинном переводе, получение лучшей оценки BLEU стало целью. Как только это произошло, она перестала быть полезным способом оценки прогресса.
tagЯвляются ли наши AI-бенчмарки хорошими прокси?
Наиболее широко используемым бенчмарком для моделей embeddings является тестовый набор MTEB, который состоит из 56 конкретных тестов. Они усредняются по категориям и в целом для получения набора оценок по классам. На момент написания верхняя часть рейтинга MTEB выглядит так:
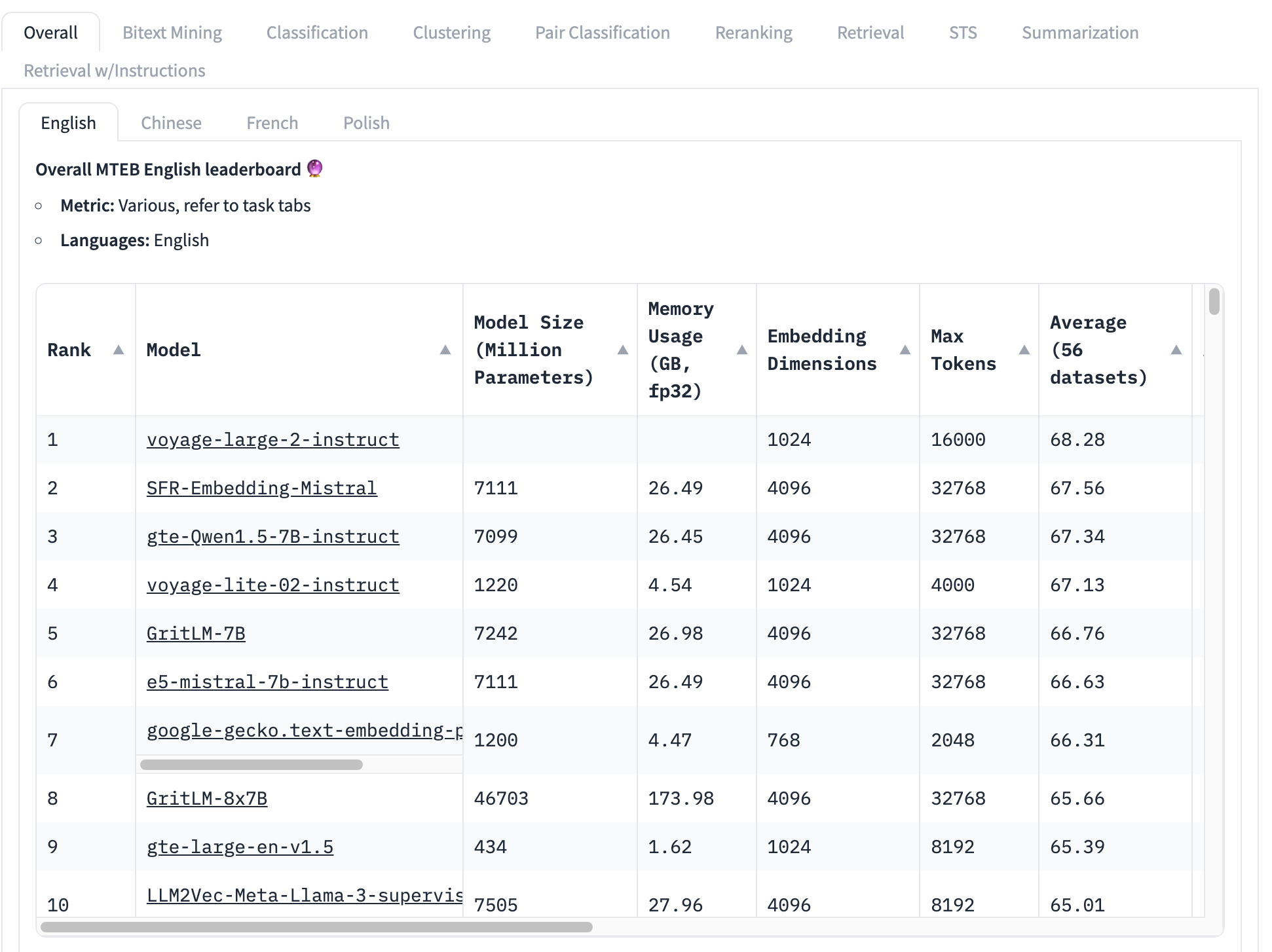
Модель embeddings, занимающая первое место, имеет общий средний балл 68.28, следующая за ней – 67.56. Глядя на эту таблицу, очень трудно понять, является ли эта разница большой или нет. Если разница небольшая, то другие факторы могут быть более важными, чем то, какая модель имеет наивысший балл:
- Размер модели: Модели имеют разные размеры, отражающие различные требования к вычислительным ресурсам. Маленькие модели работают быстрее, используют меньше памяти и требуют менее дорогого оборудования. В этом топ-10 мы видим модели с размерами от 434 миллионов параметров до более чем 46 миллиардов – разница в 100 раз!
- Размер embeddings: Размерности embeddings варьируются. Меньшая размерность означает, что векторы embeddings используют меньше памяти и хранилища, а сравнение векторов (основное использование embeddings) происходит намного быстрее. В этом списке мы видим размерности embeddings от 768 до 4096 – всего пятикратная разница, но все же значительная при создании коммерческих приложений.
- Размер окна контекстного ввода: Контекстные окна различаются как по размеру, так и по качеству, от 2048 токенов до 32768. Кроме того, разные модели используют разные подходы к позиционному кодированию и управлению входными данными, что может создавать предвзятость в пользу определенных частей входных данных.
Короче говоря, общее среднее значение – это очень неполный способ определить, какая модель embeddings лучше.
Даже если мы посмотрим на оценки по конкретным задачам, например, приведенные ниже для поиска, мы сталкиваемся с теми же проблемами снова и снова. Независимо от того, какую оценку модель получает на этом наборе тестов, нет способа узнать, какие модели будут работать лучше всего для вашего конкретного уникального случая использования.
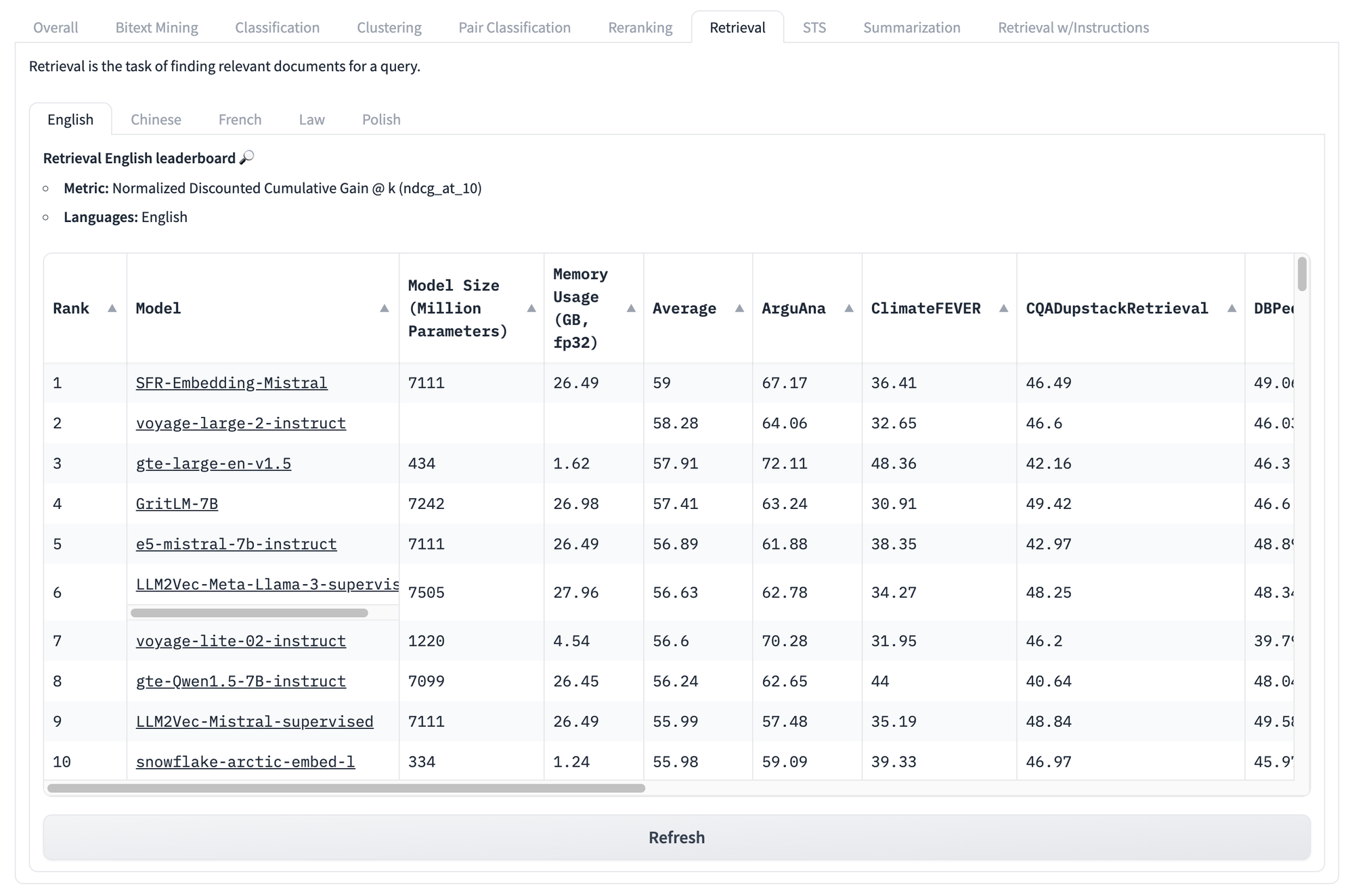
Но это не конец проблем с подобными бенчмарками.
Основная идея закона Гудхарта заключается в том, что любую метрику можно обойти, часто даже непреднамеренно. Например, бенчмарки MTEB состоят из данных из публичных источников, которые, вероятно, уже есть в ваших обучающих данных. Если вы специально не работаете над удалением данных бенчмарка из обучающей выборки, ваши результаты тестирования будут статистически некорректными.
Простого и всеобъемлющего решения не существует. Бенчмарк — это прокси-показатель, и мы никогда не можем быть уверены, что он отражает то, что мы хотим знать, но не можем измерить напрямую.
Но мы видим три основные проблемы с AI-бенчмарками, которые можно смягчить:
- Бенчмарки статичны по своей природе: одни и те же задачи, использующие одни и те же тексты.
- Бенчмарки универсальны: они малоинформативны для реальных сценариев.
- Бенчмарки негибкие: они не могут адаптироваться к разнообразным сценариям использования.
AI создает такие проблемы, но иногда также создает и решения. Мы считаем, что можем использовать AI-модели для решения этих проблем, по крайней мере в том, что касается AI-бенчмарков.
tagИспользование AI для тестирования AI: AIR-Bench
AIR-Bench является открытым исходным кодом и доступен под лицензией MIT. Вы можете просмотреть или загрузить код из его репозитория на GitHub.
 AIR-Bench
AIR-BenchtagЧто он делает?
AIR-Bench привносит важные функции в тестирование AI:
- Специализация для приложений поиска и RAG
Этот бенчмарк ориентирован на реалистичные приложения информационного поиска и конвейеры генерации с дополнением из retrieved данных. - Гибкость в отношении домена и языка
AIR значительно упрощает создание бенчмарков из данных определенной предметной области или для другого языка, или даже из ваших собственных данных для конкретных задач. - Автоматическая генерация данных
AIR-Bench генерирует тестовые данные, и набор данных регулярно обновляется, снижая риск утечки данных.
tagТаблица лидеров AIR-Bench на HuggingFace
Мы ведем таблицу лидеров, аналогичную таблице MTEB, для текущего релиза задач, сгенерированных AIR-Bench. Мы будем регулярно обновлять бенчмарки, добавлять новые и расширять охват для большего количества AI-моделей.

tagКак это работает?
Основная идея подхода AIR заключается в том, что мы можем использовать большие языковые модели (LLM) для генерации новых текстов и новых задач, которых не может быть ни в одном обучающем наборе.
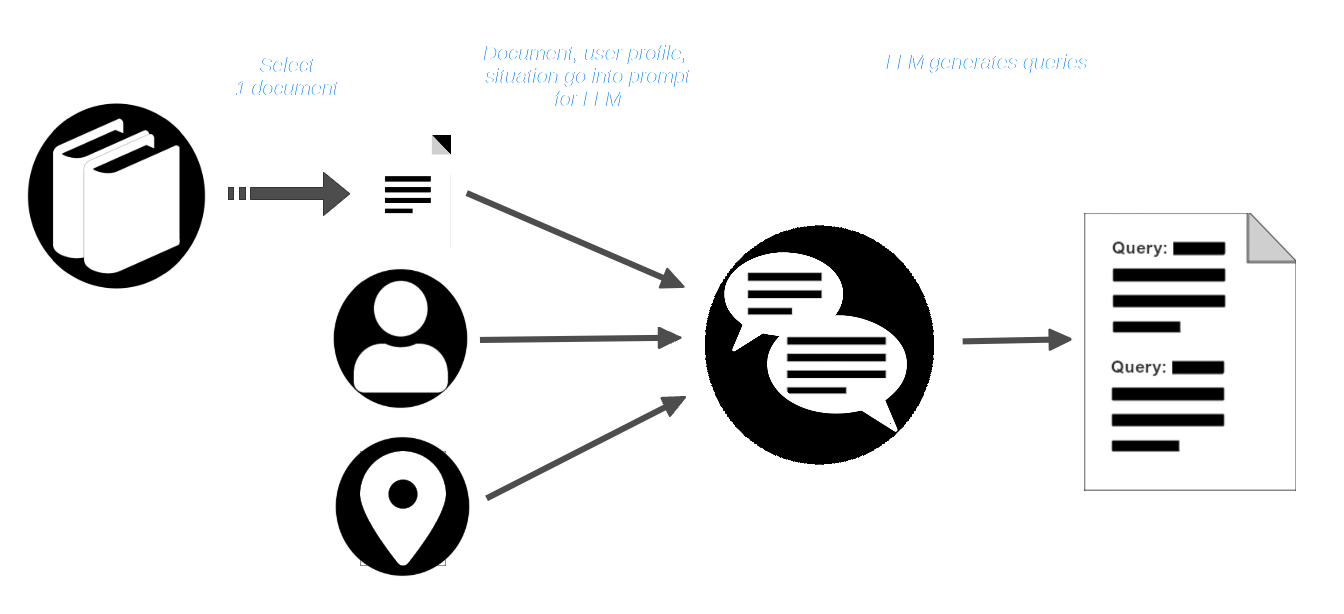
AIR-Bench использует творческие способности LLM, прося их разыграть сценарий. Пользователь выбирает коллекцию документов — реальную, которая может быть частью обучающих данных некоторых моделей — и затем представляет пользователя с определенной ролью и ситуацию, в которой ему потребуется использовать этот корпус документов.

Затем пользователь выбирает документ из корпуса и передает его вместе с профилем пользователя и описанием ситуации в LLM. LLM получает запрос на создание поисковых запросов, которые подходят для этого пользователя и ситуации и должны найти этот документ.
Затем конвейер AIR-Bench отправляет в LLM документ и запрос и создает синтетические документы, которые похожи на предоставленный, но которые не должны соответствовать запросу.
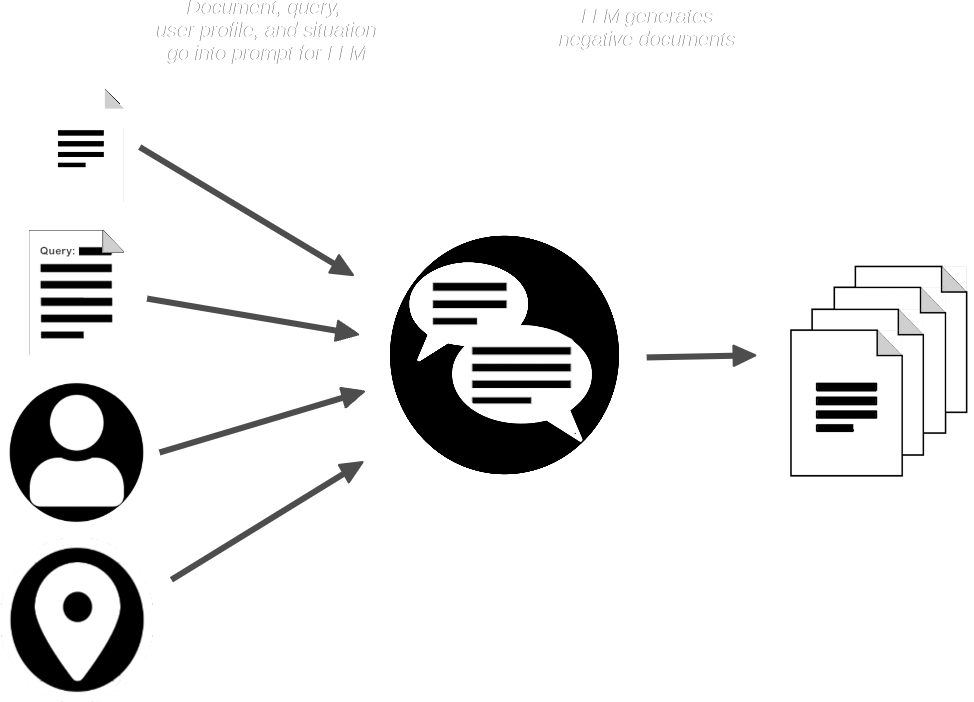
Теперь у нас есть:
- Коллекция запросов
- Соответствующий реальный документ для каждого запроса
- Небольшая коллекция ожидаемых несоответствующих синтетических документов
AIR-Bench объединяет синтетические документы с коллекцией реальных документов, а затем использует одну или несколько моделей эмбеддингов и ранжирования для проверки того, что запросы должны быть способны извлечь соответствующие документы. Он также использует LLM для проверки того, что каждый запрос релевантен документам, которые он должен извлечь.
Для получения более подробной информации об этом AI-центричном процессе генерации и контроля качества, прочитайте документацию по генерации данных в репозитории AIR-Bench на GitHub.
