



Мультимодальный поиск, объединяющий текст и изображения в единый поисковый опыт, набрал популярность благодаря таким моделям, как OpenAI CLIP. Эти модели эффективно преодолевают разрыв между визуальными и текстовыми данными, позволяя связывать изображения с релевантным текстом и наоборот.
Хотя CLIP и подобные модели мощные, у них есть заметные ограничения, особенно при обработке длинных текстов или сложных текстовых взаимосвязей. Здесь на помощь приходит jina-clip-v1.
Разработанный для решения этих проблем, jina-clip-v1 предлагает улучшенное понимание текста, сохраняя при этом надежные возможности сопоставления текста и изображений. Он предоставляет более оптимизированное решение для приложений, использующих обе модальности, упрощая процесс поиска и устраняя необходимость жонглировать отдельными моделями для текста и изображений.
В этой статье мы рассмотрим, что jina-clip-v1 привносит в мультимодальные поисковые приложения, демонстрируя эксперименты, которые показывают, как он улучшает как точность, так и разнообразие результатов через интегрированные текстовые и визуальные эмбеддинги.
tagЧто такое CLIP?
CLIP (Contrastive Language–Image Pretraining) — это архитектура ИИ-модели, разработанная OpenAI, которая связывает текст и изображения путем изучения совместных представлений. CLIP по сути представляет собой текстовую модель и модель изображений, объединенные вместе — он преобразует оба типа входных данных в общее пространство эмбеддингов, где похожие тексты и изображения располагаются близко друг к другу. CLIP был обучен на огромном наборе пар изображение-текст, что позволяет ему понимать взаимосвязь между визуальным и текстовым контентом. Это позволяет ему хорошо обобщать знания в разных областях, делая его высокоэффективным в сценариях обучения с нулевым выстрелом, таких как генерация подписей или поиск изображений.
После выпуска CLIP другие модели, такие как SigLiP, LiT и EvaCLIP, расширили его основу, улучшив такие аспекты, как эффективность обучения, масштабирование и мультимодальное понимание. Эти модели часто используют более крупные наборы данных, улучшенные архитектуры и более сложные методы обучения, чтобы расширить границы согласования текста и изображений, продвигая вперед область моделей изображение-язык.
Хотя CLIP может работать только с текстом, у него есть существенные ограничения. Во-первых, он был обучен только на коротких текстовых подписях, а не на длинных текстах, обрабатывая максимум около 77 слов. Во-вторых, CLIP отлично справляется с соединением текста и изображений, но испытывает трудности при сравнении текста с другим текстом, например, при распознавании того, что строки a crimson fruit и a red apple могут относиться к одному и тому же предмету. Здесь проявляют себя специализированные текстовые модели, такие как jina-embeddings-v3.
Эти ограничения усложняют поисковые задачи, включающие как текст, так и изображения, например, в онлайн-магазине "shop the look", где пользователь может искать модные товары, используя либо текстовую строку, либо изображение. При индексации ваших товаров необходимо обрабатывать каждый из них несколько раз - один раз для изображения, один раз для текста и еще раз с помощью специальной текстовой модели. Аналогично, когда пользователь ищет товар, ваша система должна выполнить поиск как минимум дважды, чтобы найти как текстовые, так и визуальные совпадения:
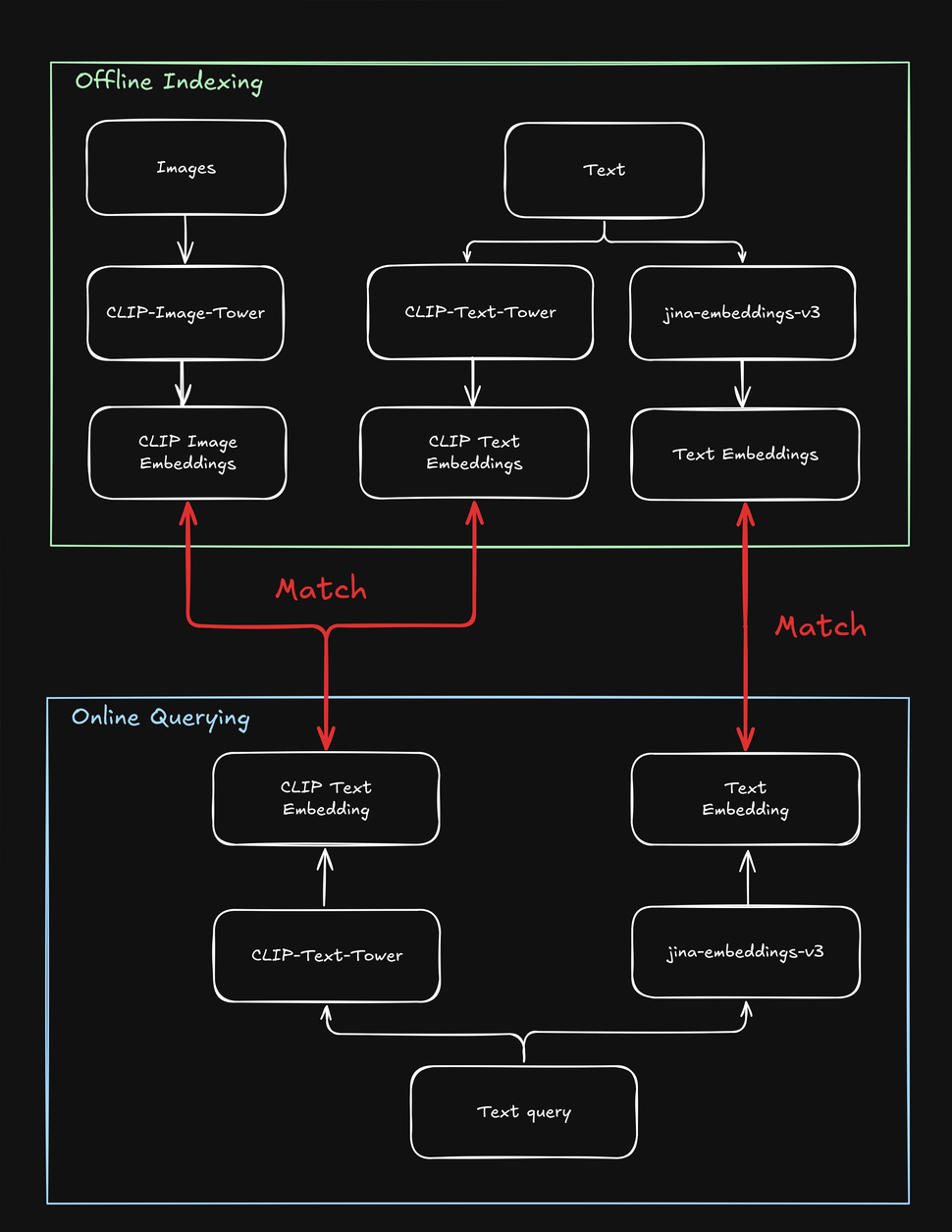
tagКак jina-clip-v1 решает недостатки CLIP
Чтобы преодолеть ограничения CLIP, мы создали jina-clip-v1, способный понимать более длинные тексты и эффективнее сопоставлять текстовые запросы с текстами и изображениями. Что делает jina-clip-v1 таким особенным? Во-первых, он использует более умную модель понимания текста (JinaBERT), помогающую понимать более длинные и сложные фрагменты текста (например, описания товаров), а не только короткие подписи (например, названия товаров). Во-вторых, мы обучили jina-clip-v1 быть хорошим сразу в двух вещах: как в сопоставлении текста с изображениями, так и в сопоставлении текста с другими фрагментами текста.
С OpenAI CLIP это не так: для индексации и запросов необходимо вызывать две модели (CLIP для изображений и коротких текстов, таких как подписи, и другой текстовый эмбеддинг для более длинных текстов, таких как описания). Это не только создает дополнительную нагрузку, но и замедляет поиск — операцию, которая должна быть очень быстрой. jina-clip-v1 делает все это в одной модели, без потери скорости:

Этот унифицированный подход открывает новые возможности, которые были сложны с более ранними моделями, потенциально изменяя наш подход к поиску. В этой статье мы провели два эксперимента:
- Улучшение результатов поиска путем комбинирования текстового и визуального поиска: Можем ли мы объединить то, что jina-clip-v1 понимает из текста, с тем, что он понимает из изображений? Что происходит, когда мы смешиваем эти два типа понимания? Меняет ли добавление визуальной информации наши результаты поиска? Короче говоря, можем ли мы получить лучшие результаты, если будем искать с помощью текста и изображений одновременно?
- Использование изображений для разнообразия результатов поиска: Большинство поисковых систем максимизируют текстовые совпадения. Но можем ли мы использовать понимание изображений jina-clip-v1 как "визуальное перемешивание"? Вместо того чтобы просто показывать наиболее релевантные результаты, мы могли бы включить визуально разнообразные. Речь идет не о поиске большего количества связанных результатов, а о показе более широкого спектра перспектив, даже если они менее тесно связаны. Делая это, мы можем обнаружить аспекты темы, о которых раньше не задумывались. Например, в контексте поиска моды, если пользователь ищет "разноцветное коктейльное платье", хотят ли они, чтобы верхние позиции выглядели одинаково (т.е. очень близкие совпадения) или предпочтут более широкий выбор (через визуальное перемешивание)?
Оба подхода ценны в различных случаях использования, где пользователи могут искать с помощью текста или изображений, например, в электронной коммерции, медиа, искусстве и дизайне, медицинской визуализации и не только.
tagУсреднение текстовых и визуальных эмбеддингов для выше среднего результата
Когда пользователь отправляет запрос (обычно в виде текстовой строки), мы можем использовать текстовую башню jina-clip-v1 для кодирования запроса в текстовый эмбеддинг. Сила jina-clip-v1 заключается в его способности понимать как текст, так и изображения, выравнивая текст-к-тексту и текст-к-изображению сигналы в одном семантическом пространстве.
Можем ли мы улучшить результаты поиска, если объединим предварительно проиндексированные текстовые и визуальные эмбеддинги каждого продукта путем их усреднения?
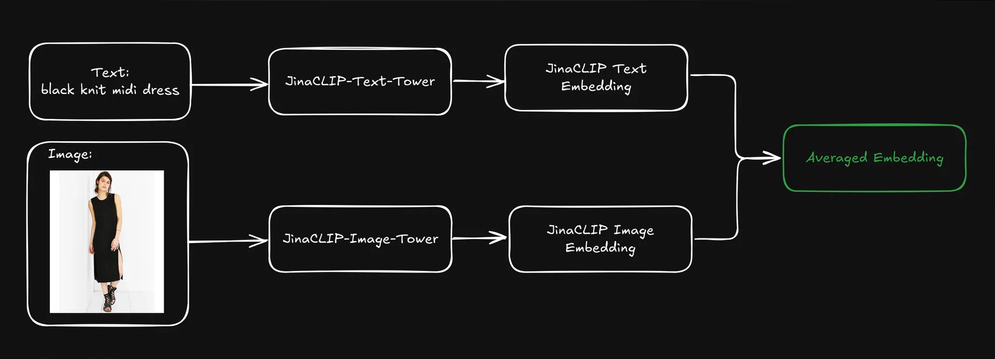
Это создает единое представление, включающее как текстовую информацию (например, описание продукта), так и визуальную информацию (например, изображение продукта). Затем мы можем использовать эмбеддинг текстового запроса для поиска по этим смешанным представлениям. Как это влияет на наши результаты поиска?
Чтобы выяснить это, мы использовали набор данных Fashion200k, масштабный набор данных, специально созданный для задач, связанных с поиском модных изображений и кросс-модальным пониманием. Он состоит из более чем 200 000 изображений модных товаров, таких как одежда, обувь и аксессуары, вместе с соответствующими описаниями продуктов и метаданными.
 xthan
xthanМы дополнительно классифицировали каждый элемент по широкой категории (например, dress) и детальной категории (например, knit midi dress).
tagАнализ трех методов поиска
Чтобы понять, дает ли усреднение текстовых и визуальных эмбеддингов лучшие результаты поиска, мы экспериментировали с тремя типами поиска, каждый из которых использует текстовую строку (например, red dress) в качестве запроса:
- Query to Description с использованием текстовых эмбеддингов: Поиск по описаниям товаров на основе текстовых эмбеддингов.
- Query to Image с использованием кросс-модального поиска: Поиск по изображениям товаров на основе визуальных эмбеддингов.
- Query to Average Embedding: Поиск по усредненным эмбеддингам описаний и изображений товаров.
Сначала мы проиндексировали весь набор данных, а затем сгенерировали 1000 случайных запросов для оценки производительности. Мы кодировали каждый запрос в текстовый эмбеддинг и сопоставляли его отдельно, используя описанные выше методы. Мы измеряли точность по тому, насколько хорошо категории возвращаемых товаров соответствовали входному запросу.
Когда мы использовали запрос multicolor henley t-shirt dress, поиск Query-to-Description достиг наивысшей точности top-5, но последние три платья из топ-результатов были визуально идентичны. Это не идеально, так как эффективный поиск должен балансировать между релевантностью и разнообразием, чтобы лучше привлекать внимание пользователя.

Кросс-модальный поиск Query-to-Image использовал тот же запрос и показал противоположный подход, представив очень разнообразную коллекцию платьев. Хотя два из пяти результатов совпали с правильной широкой категорией, ни один не соответствовал детальной категории.

Поиск по усредненным текстовым и визуальным эмбеддингам дал наилучший результат: все пять результатов соответствовали широкой категории, а два из пяти совпали с детальной категорией. Кроме того, визуально дублирующиеся элементы были исключены, что обеспечило более разнообразный выбор. Использование текстовых эмбеддингов для поиска по усредненным текстовым и визуальным эмбеддингам, похоже, сохраняет качество поиска, одновременно учитывая визуальные подсказки, что приводит к более разнообразным и комплексным результатам.

tagМасштабирование: оценка с большим количеством запросов
Чтобы проверить, будет ли это работать в большем масштабе, мы продолжили эксперимент с дополнительными широкими и детальными категориями. Мы провели несколько итераций, получая разное количество результатов ("k-значения") каждый раз.
Как для широких, так и для детальных категорий, Query to Average Embedding стабильно достигал наивысшей точности для всех k-значений (10, 20, 50, 100). Это показывает, что комбинирование текстовых и визуальных эмбеддингов обеспечивает наиболее точные результаты для поиска релевантных элементов, независимо от того, является ли категория широкой или специфической:

| k | Search Type | Broad Category Precision (cosine similarity) | Fine-grained Category Precision (cosine similarity) |
|---|---|---|---|
| 10 | Query to Description | 0.9026 | 0.2314 |
| 10 | Query to Image | 0.7614 | 0.2037 |
| 10 | Query to Avg Embedding | 0.9230 | 0.2711 |
| 20 | Query to Description | 0.9150 | 0.2316 |
| 20 | Query to Image | 0.7523 | 0.1964 |
| 20 | Query to Avg Embedding | 0.9229 | 0.2631 |
| 50 | Query to Description | 0.9134 | 0.2254 |
| 50 | Query to Image | 0.7418 | 0.1750 |
| 50 | Query to Avg Embedding | 0.9226 | 0.2390 |
| 100 | Query to Description | 0.9092 | 0.2139 |
| 100 | Query to Image | 0.7258 | 0.1675 |
| 100 | Query to Avg Embedding | 0.9150 | 0.2286 |
- Query to Description с использованием текстовых эмбеддингов показал хорошие результаты в обеих категориях, но немного отстал от подхода с усредненными эмбеддингами. Это предполагает, что текстовые описания сами по себе предоставляют ценную информацию, особенно для более широких категорий, таких как "платье", но могут не хватать тонкости для точной детальной классификации (например, для различения разных типов платьев).
- Query to Image с использованием кросс-модального поиска стабильно показывал самую низкую точность в обеих категориях. Это говорит о том, что, хотя визуальные характеристики могут помочь определить широкие категории, они менее эффективны для определения тонких различий конкретных модных предметов. Проблема различения детальных категорий исключительно по визуальным характеристикам особенно очевидна, когда визуальные различия могут быть тонкими и требуют дополнительного контекста, предоставляемого текстом.
- В целом, комбинирование текстовой и визуальной информации (через усредненные эмбеддинги) достигло высокой точности как в широких, так и в детальных задачах поиска модной одежды. Текстовые описания играют важную роль, особенно в определении широких категорий, в то время как изображения сами по себе менее эффективны в обоих случаях.
В целом, точность была значительно выше для широких категорий по сравнению с детальными категориями, в основном потому, что элементы в широких категориях (например, dress) были более представлены в наборе данных, чем детальные категории (например, henley dress), просто потому что последние являются подмножеством первых. По своей природе широкую категорию легче обобщить, чем детальную категорию. За пределами примера с модой легко определить, что что-то в целом является птицей. Гораздо сложнее определить, что это Райская птица Вогелкопа.
Еще одно важное замечание: информация в текстовом запросе легче соответствует другим текстам (таким как названия продуктов или описания), чем визуальным характеристикам. Поэтому, если текст используется как входные данные, тексты являются более вероятным выходом, чем изображения. Мы получаем лучшие результаты, комбинируя как изображения, так и текст (путем усреднения эмбеддингов) в нашем индексе.
tagПолучение результатов с помощью текста; их разнообразие с помощью изображений
В предыдущем разделе мы затронули проблему визуально дублирующихся результатов поиска. В поиске одной только точности не всегда достаточно. Во многих случаях поддержание краткого, но высоко релевантного и разнообразного ранжированного списка более эффективно, особенно когда запрос пользователя неоднозначен (например, если пользователь ищетblack jacket — имеют ли они в виду черную байкерскую куртку, бомбер, блейзер или какой-то другой вид?)
Теперь, вместо использования кросс-модальных возможностей jina-clip-v1, давайте используем текстовые эмбеддинги из текстовой башни для начального текстового поиска, а затем применим эмбеддинги изображений из башни изображений как "визуальный ранжировщик" для диверсификации результатов поиска. Это проиллюстрировано на диаграмме ниже:
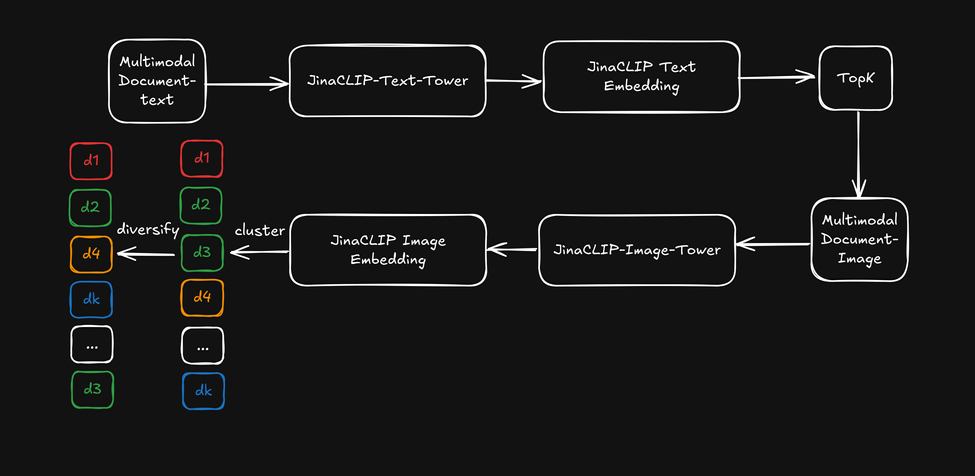
- Сначала получаем топ-k результатов поиска на основе текстовых эмбеддингов.
- Для каждого из лучших результатов поиска извлекаем визуальные характеристики и кластеризуем их с помощью эмбеддингов изображений.
- Переупорядочиваем результаты поиска, выбирая по одному элементу из каждого кластера, и представляем пользователю диверсифицированный список.
После получения пятидесяти лучших результатов мы применили облегченную кластеризацию k-means (k=5) к эмбеддингам изображений, затем выбрали элементы из каждого кластера. Точность категорий осталась согласованной с производительностью Query-to-Description, так как мы использовали соответствие запроса категории продукта в качестве метрики измерения. Однако ранжированные результаты начали охватывать больше различных аспектов (таких как ткань, крой и узор) благодаря диверсификации на основе изображений. Для справки, вот пример разноцветного платья-хенли из предыдущего случая:

Теперь давайте посмотрим, как диверсификация влияет на результаты поиска при использовании поиска по текстовым эмбеддингам в сочетании с эмбеддингами изображений в качестве диверсифицирующего ранжировщика:

Ранжированные результаты происходят из текстового поиска, но начинают охватывать более разнообразные "аспекты" в первой пятерке примеров. Это достигает эффекта, похожего на усреднение эмбеддингов, без фактического усреднения.
Однако это имеет свою цену: нам необходимо применять дополнительный шаг кластеризации после получения топ-k результатов, что добавляет несколько дополнительных миллисекунд, в зависимости от размера начального ранжирования. Кроме того, определение значения k для кластеризации k-means включает некоторые эвристические предположения. Это та цена, которую мы платим за улучшенную диверсификацию результатов!
tagЗаключение
jina-clip-v1 эффективно преодолевает разрыв между текстовым и визуальным поиском, объединяя обе модальности в единой, эффективной модели. Наши эксперименты показали, что его способность обрабатывать более длинные, сложные текстовые входные данные вместе с изображениями обеспечивает превосходную производительность поиска по сравнению с традиционными моделями, такими как CLIP.
Наше тестирование охватывало различные методы, включая сопоставление текста с описаниями, изображениями и усредненными эмбеддингами. Результаты последовательно показывали, что комбинирование текстовых и визуальных эмбеддингов давало наилучшие результаты, улучшая как точность, так и разнообразие результатов поиска. Мы также обнаружили, что использование эмбеддингов изображений в качестве "визуального ранжировщика" повышало разнообразие результатов при сохранении релевантности.
Эти достижения имеют значительные последствия для реальных приложений, где пользователи осуществляют поиск, используя как текстовые описания, так и изображения. Благодаря одновременному пониманию обоих типов данных, jina-clip-v1 оптимизирует процесс поиска, предоставляя более релевантные результаты и обеспечивая более разнообразные рекомендации продуктов. Эта унифицированная возможность поиска выходит за рамки электронной коммерции и приносит пользу управлению медиа-активами, цифровым библиотекам и курированию визуального контента, упрощая поиск релевантного контента в различных форматах.
В то время как jina-clip-v1 в настоящее время поддерживает только английский язык, мы работаем над jina-clip-v2. Следуя по стопам jina-embeddings-v3 и jina-colbert-v2, эта новая версия станет современным многоязычным мультимодальным поисковиком, поддерживающим 89 языков. Это обновление откроет новые возможности для задач поиска и извлечения информации на разных рынках и в разных отраслях, делая его более мощной моделью эмбеддингов для глобальных приложений в электронной коммерции, медиа и других областях.
