




Один из ключевых вызовов в многоязычных моделях — это "языковой разрыв" («language gap») — явление, когда фразы с одинаковым значением на разных языках не так тесно выровнены или сгруппированы, как должны быть. В идеале текст на одном языке и его эквивалент на другом должны иметь схожие представления — то есть эмбеддинги, которые очень близки друг к другу — позволяя кросс-языковым приложениям одинаково работать с текстами на разных языках. Однако модели часто неявно учитывают язык текста, создавая "языковой разрыв", который приводит к субоптимальной производительности при работе с разными языками.
В этой статье мы исследуем этот языковой разрыв и то, как он влияет на производительность моделей текстовых эмбеддингов. Мы провели эксперименты для оценки семантического выравнивания перефразировок на одном языке и переводов между разными языковыми парами, используя нашу модель jina-xlm-roberta и новейшую jina-embeddings-v3. Эти эксперименты показывают, насколько хорошо фразы с похожими или идентичными значениями группируются вместе при различных условиях обучения.

Мы также экспериментировали с методами обучения для улучшения кросс-языкового семантического выравнивания, в частности с внедрением параллельных многоязычных данных во время контрастного обучения. В этой статье мы поделимся нашими выводами и результатами.
tagОбучение многоязычной модели создает и уменьшает языковой разрыв
Обучение моделей текстовых эмбеддингов обычно включает многоэтапный процесс с двумя основными частями:
- Masked Language Modeling (MLM): Предварительное обучение обычно включает очень большие объемы текста, в которых некоторые токены случайно маскируются. Модель обучается предсказывать эти маскированные токены. Эта процедура учит модель шаблонам языка или языков в обучающих данных, включая зависимости выбора между токенами, которые могут возникать из синтаксиса, лексической семантики и прагматических ограничений реального мира.
- Contrastive Learning: После предварительного обучения модель дополнительно обучается на отобранных или полуотобранных данных, чтобы сближать эмбеддинги семантически похожих текстов и (опционально) отдалять непохожие. Это обучение может использовать пары, триплеты или даже группы текстов, семантическое сходство которых уже известно или хотя бы надежно оценено. Оно может включать несколько подэтапов, и существует множество стратегий обучения для этой части процесса, при этом часто публикуются новые исследования, и нет четкого консенсуса относительно оптимального подхода.
Чтобы понять, как возникает языковой разрыв и как его можно устранить, нам нужно рассмотреть роль обоих этапов.
tagПредварительное обучение с маскированием языка
Некоторые кросс-языковые способности моделей текстовых эмбеддингов приобретаются во время предварительного обучения.
Родственные и заимствованные слова позволяют модели изучать некоторое кросс-языковое семантическое выравнивание из больших объемов текстовых данных. Например, английское слово banana и французское слово banane (и немецкое Banane) достаточно частотны и похожи по написанию, что модель эмбеддингов может узнать, что слова, похожие на "banan-", имеют схожие паттерны распределения в разных языках. Она может использовать эту информацию, чтобы в некоторой степени узнать, что другие слова, которые не выглядят одинаково в разных языках, также имеют схожие значения, и даже понять, как переводятся грамматические структуры.
Однако это происходит без явного обучения.
Мы протестировали модель jina-xlm-roberta, предварительно обученный базис jina-embeddings-v3, чтобы увидеть, насколько хорошо она изучила кросс-языковые эквивалентности из предварительного обучения с маскированием языка. Мы построили двумерные UMAP представления предложений набора английских предложений, переведенных на немецкий, голландский, упрощенный китайский и японский языки. Результаты показаны на рисунке ниже:
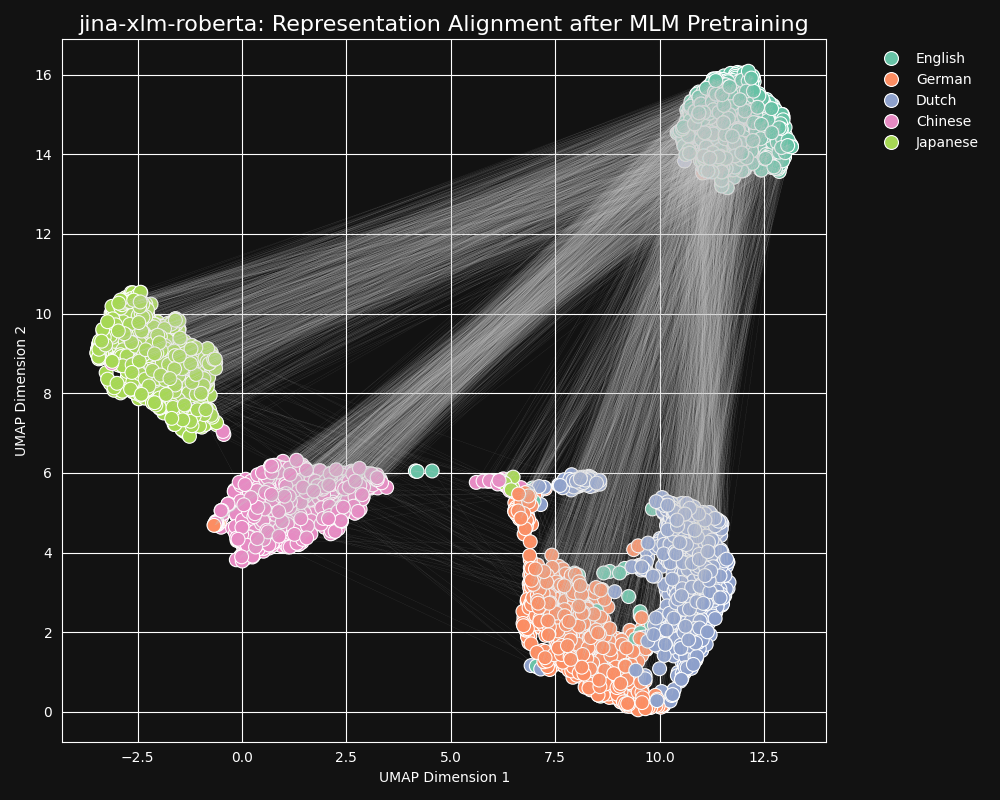
Эти предложения сильно склонны формировать языково-специфичные кластеры в пространстве эмбеддингов
jina-xlm-roberta, хотя вы можете видеть несколько выбросов в этой проекции, которые могут быть побочным эффектом двумерной проекции.Вы можете видеть, что предварительное обучение очень сильно сгруппировало вместе эмбеддинги предложений на одном языке. Это проекция в два измерения распределения в пространстве гораздо более высокой размерности, поэтому все еще возможно, что, например, немецкое предложение, которое является хорошим переводом английского, может все еще быть немецким предложением, чей эмбеддинг ближе всего к эмбеддингу его английского источника. Но это показывает, что эмбеддинг английского предложения, вероятно, ближе к другому английскому предложению, чем к семантически идентичному или почти идентичному немецкому.
Обратите также внимание, как немецкий и голландский образуют гораздо более близкие кластеры, чем другие пары языков. Это не удивительно для двух относительно близкородственных языков. Немецкий и голландский достаточно похожи, что они иногда частично взаимопонятны.
Японский и китайский также кажутся ближе друг к другу, чем к другим языкам. Хотя они не связаны друг с другом таким же образом, в письменном японском обычно используются кандзи (漢字), или ханьцзы по-китайски. Японский разделяет большинство этих письменных символов с китайским, и оба языка имеют много слов, написанных одним или несколькими кандзи/ханьцзы вместе. С точки зрения MLM, это такое же видимое сходство, как между голландским и немецким.
Мы можем увидеть этот "языковой разрыв" проще, рассмотрев только два языка с двумя предложениями в каждом:

Поскольку MLM естественным образом группирует тексты по языкам, "my dog is blue" и "my cat is red" сгруппированы вместе, далеко от их немецких эквивалентов. В отличие от "разрыва модальностей", обсуждаемого в предыдущем блог-посте, мы считаем, что это возникает из-за поверхностных сходств и различий между языками: похожих написаний, использования одинаковых последовательностей символов в печати и, возможно, сходств в морфологии и синтаксической структуре — общих порядков слов и общих способов построения слов.
Короче говоря, в какой бы степени модель ни изучала кросс-языковые эквивалентности в предварительном обучении MLM, этого недостаточно, чтобы преодолеть сильное смещение в сторону группировки текстов по языкам. Это оставляет большой языковой разрыв.
tagКонтрастное обучение
В идеале мы хотим, чтобы модель эмбеддингов была безразлична к языку и кодировала в своих эмбеддингах только общие значения. В такой модели мы бы не видели группировку по языкам и не имели бы языкового разрыва. Предложения на одном языке должны быть очень близки к хорошим переводам и далеки от других предложений, которые означают что-то другое, даже на том же языке, как показано на рисунке ниже:

Предварительное обучение MLM этого не достигает, поэтому мы используем дополнительные методы контрастного обучения для улучшения семантического представления текстов в эмбеддингах.
Контрастное обучение включает использование пар текстов, которые заведомо схожи или различны по значению, и триплетов, где одна пара заведомо более схожа, чем другая. Веса корректируются во время обучения, чтобы отразить эти известные отношения между парами и триплетами текстов.
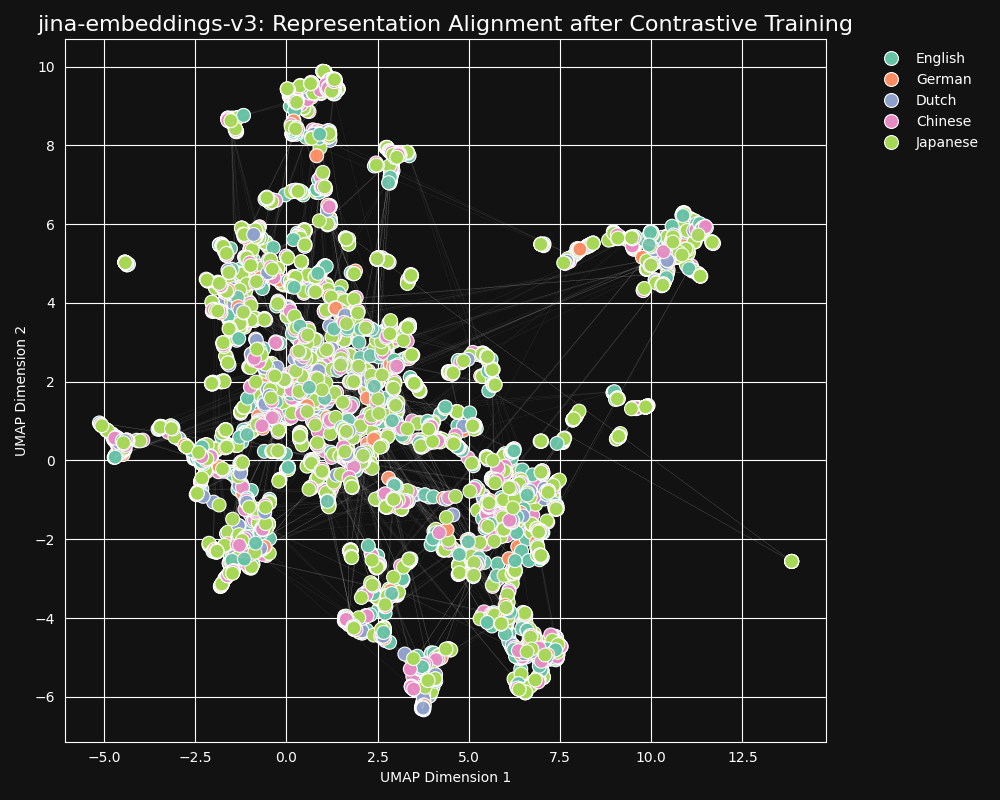
В нашем наборе данных для контрастного обучения представлено 30 языков, но 97% пар и триплетов находятся только на одном языке, и только 3% включают кросс-языковые пары или триплеты. Но этих 3% достаточно для получения драматического результата: эмбеддинги показывают очень слабую языковую кластеризацию, и семантически похожие тексты производят близкие эмбеддинги независимо от их языка, как показано в UMAP проекции эмбеддингов из jina-embeddings-v3.
Чтобы подтвердить это, мы измерили корреляцию Спирмена для представлений, сгенерированных моделями jina-xlm-roberta и jina-embeddings-v3 на наборе данных STS17.
Таблица ниже показывает корреляцию Спирмена между рейтингами семантического сходства для переведенных текстов на разных языках. Мы берем набор английских предложений и затем измеряем сходство их эмбеддингов с эмбеддингом определенного эталонного предложения, сортируя их в порядке от наиболее похожего к наименее похожему. Затем мы переводим все эти предложения на другой язык и повторяем процесс ранжирования. В идеальной кросс-языковой модели эмбеддингов два упорядоченных списка должны быть одинаковыми, и корреляция Спирмена должна быть равна 1.0.
График и таблица ниже показывают наши результаты сравнения английского с шестью другими языками из бенчмарка STS17, используя как jina-xlm-roberta, так и jina-embeddings-v3.
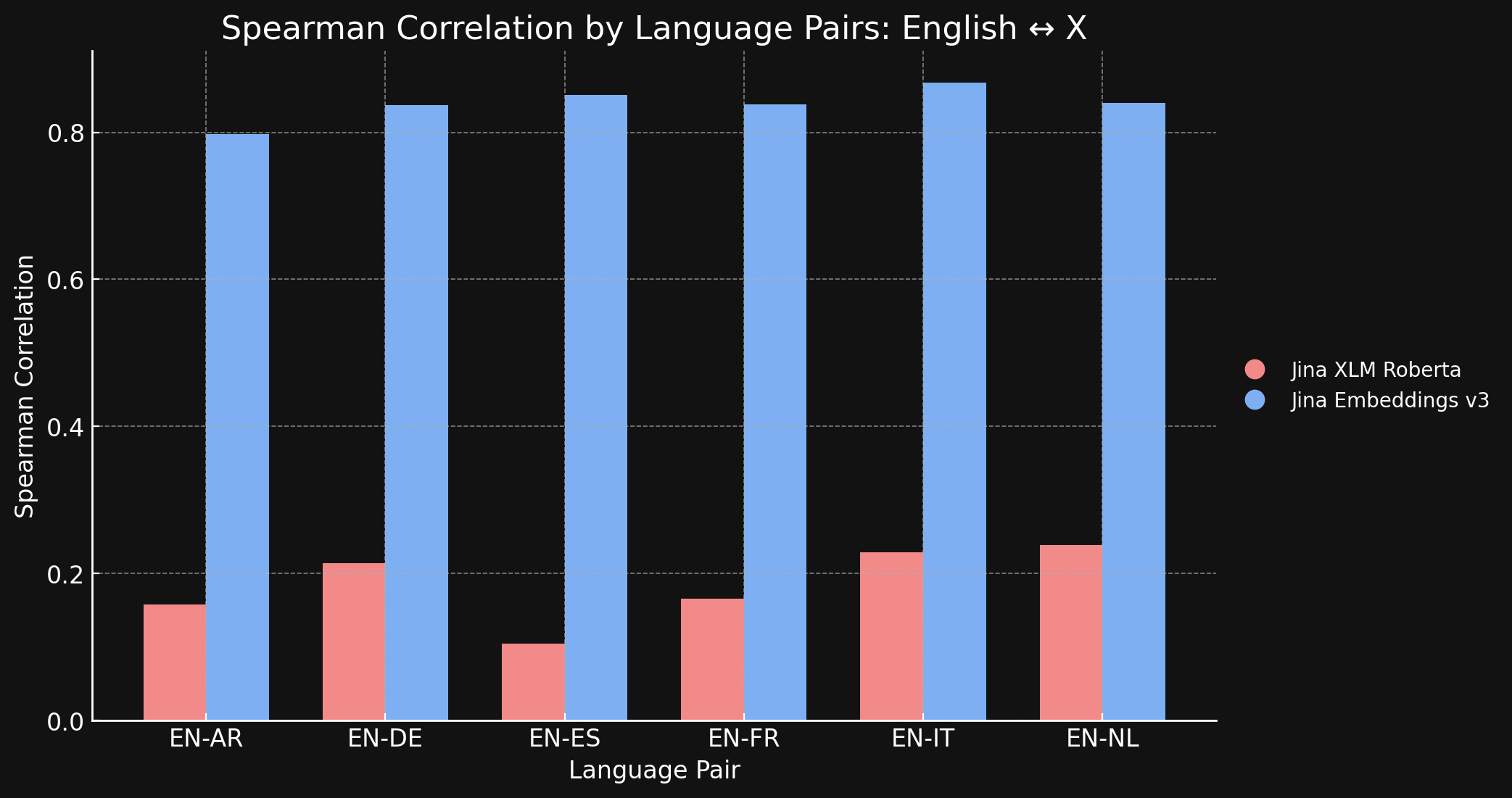
| Task | jina-xlm-roberta |
jina-embeddings-v3 |
|---|---|---|
| English ↔ Arabic | 0.1581 | 0.7977 |
| English ↔ German | 0.2136 | 0.8366 |
| English ↔ Spanish | 0.1049 | 0.8509 |
| English ↔ French | 0.1659 | 0.8378 |
| English ↔ Italian | 0.2293 | 0.8674 |
| English ↔ Dutch | 0.2387 | 0.8398 |
Здесь видна огромная разница, которую дает контрастивное обучение по сравнению с исходной предварительной подготовкой. Несмотря на то, что только 3% данных для обучения были многоязычными, модель jina-embeddings-v3 изучила достаточно кросс-языковой семантики, чтобы практически устранить языковой разрыв, полученный при предварительном обучении.
tagАнглийский против мира: могут ли другие языки сравняться в выравнивании?
Мы обучили jina-embeddings-v3 на 89 языках, уделив особое внимание 30 широко используемым письменным языкам. Несмотря на наши усилия по созданию масштабного многоязычного обучающего корпуса, английский язык по-прежнему составляет почти половину данных, использованных нами при контрастивном обучении. Другие языки, включая широко используемые мировые языки, для которых доступно множество текстового материала, все еще относительно недопредставлены по сравнению с огромным объемом английских данных в обучающем наборе.
Учитывая это преобладание английского языка, являются ли английские представления более выровненными, чем представления других языков? Чтобы исследовать это, мы провели дополнительный эксперимент.
Мы создали набор данных parallel-sentences, состоящий из 1000 пар английских текстов, "якоря" и "положительного", где положительный текст логически следует из текста-якоря.

Например, первая строка таблицы ниже. Эти предложения не идентичны по смыслу, но они имеют совместимые значения. Они информативно описывают одну и ту же ситуацию.
Затем мы перевели эти пары на пять языков с помощью GPT-4: немецкий, голландский, китайский (упрощенный), китайский (традиционный) и японский. В заключение мы вручную проверили их качество.
| Language | Anchor | Positive |
|---|---|---|
| English | Two young girls are playing outside in a non-urban environment. | Two girls are playing outside. |
| German | Zwei junge Mädchen spielen draußen in einer nicht urbanen Umgebung. | Zwei Mädchen spielen draußen. |
| Dutch | Twee jonge meisjes spelen buiten in een niet-stedelijke omgeving. | Twee meisjes spelen buiten. |
| Chinese (Simplified) | 两个年轻女孩在非城市环境中玩耍。 | 两个女孩在外面玩。 |
| Chinese (Traditional) | 兩個年輕女孩在非城市環境中玩耍。 | 兩個女孩在外面玩。 |
| Japanese | 2人の若い女の子が都市環境ではない場所で遊んでいます。 | 二人の少女が外で遊んでいます。 |
Затем мы закодировали каждую пару текстов с помощью jina-embeddings-v3 и рассчитали косинусное сходство между ними. На рисунке и в таблице ниже показано распределение оценок косинусного сходства для каждого языка и среднее сходство:
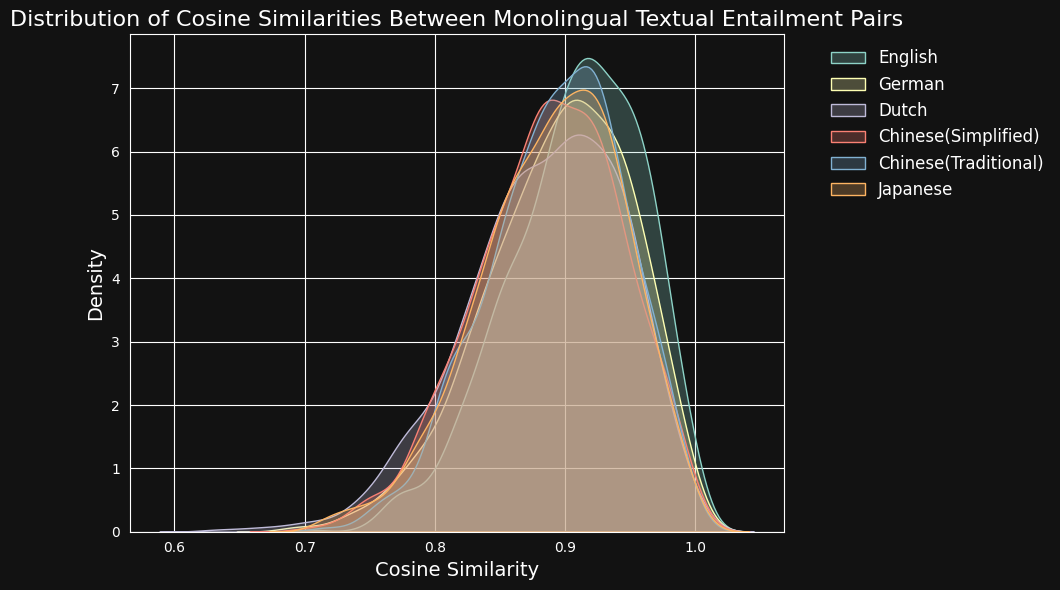
| Language | Average Cosine Similarity |
|---|---|
| English | 0.9078 |
| German | 0.8949 |
| Dutch | 0.8844 |
| Chinese (Simplified) | 0.8876 |
| Chinese (Traditional) | 0.8933 |
| Japanese | 0.8895 |
Несмотря на преобладание английского языка в обучающих данных, jina-embeddings-v3 распознает семантическое сходство в немецком, голландском, японском и обеих формах китайского языка примерно так же хорошо, как и в английском.
tagПреодоление языковых барьеров: межъязыковое выравнивание за пределами английского языка
Исследования выравнивания представлений между языками обычно изучают языковые пары, включающие английский язык. Такой фокус может, теоретически, скрывать реальную картину. Модель может просто оптимизировать представление всего максимально близко к английскому эквиваленту, не проверяя, правильно ли поддерживаются другие языковые пары.
Чтобы исследовать это, мы провели эксперименты с использованием датасета parallel-sentences, фокусируясь на межъязыковом выравнивании помимо просто английских двуязычных пар.
Таблица ниже показывает распределение косинусных сходств между эквивалентными текстами в разных языковых парах — текстами, являющимися переводами общего английского источника. В идеале все пары должны иметь косинус 1 — то есть идентичные семантические вложения. На практике это никогда не может произойти, но мы ожидаем, что хорошая модель будет иметь очень высокие косинусные значения для пар переводов.
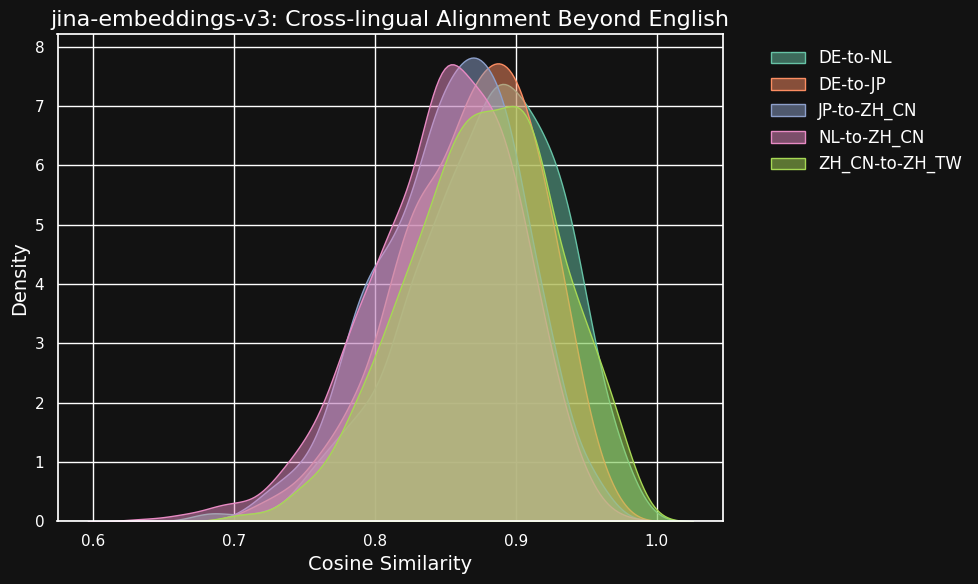
| Language Pair | Average Cosine Similarity |
|---|---|
| German ↔ Dutch | 0.8779 |
| German ↔ Japanese | 0.8664 |
| Chinese (Simplified) ↔ Japanese | 0.8534 |
| Dutch ↔ Chinese (Simplified) | 0.8479 |
| Chinese (Simplified) ↔ Chinese (Traditional) | 0.8758 |
Хотя показатели сходства между разными языками немного ниже, чем для совместимых текстов на одном языке, они все еще очень высоки. Косинусное сходство голландско-немецких переводов почти такое же высокое, как между совместимыми текстами на немецком языке.
Это может быть неудивительно, поскольку немецкий и голландский — очень похожие языки. Аналогично, две разновидности китайского языка, протестированные здесь, не являются действительно разными языками, а лишь стилистически различными формами одного и того же языка. Но вы можете видеть, что даже очень непохожие языковые пары, такие как голландский и китайский или немецкий и японский, все еще показывают очень сильное сходство между семантически эквивалентными текстами.
Мы рассмотрели возможность того, что эти очень высокие значения сходства могут быть побочным эффектом использования ChatGPT в качестве переводчика. Чтобы проверить это, мы загрузили переведенные людьми транскрипты TED Talks на английском и немецком языках и проверили, будут ли выровненные переведенные предложения иметь такую же высокую корреляцию.
Результат оказался даже сильнее, чем для наших машинных переводов, как вы можете видеть на рисунке ниже.
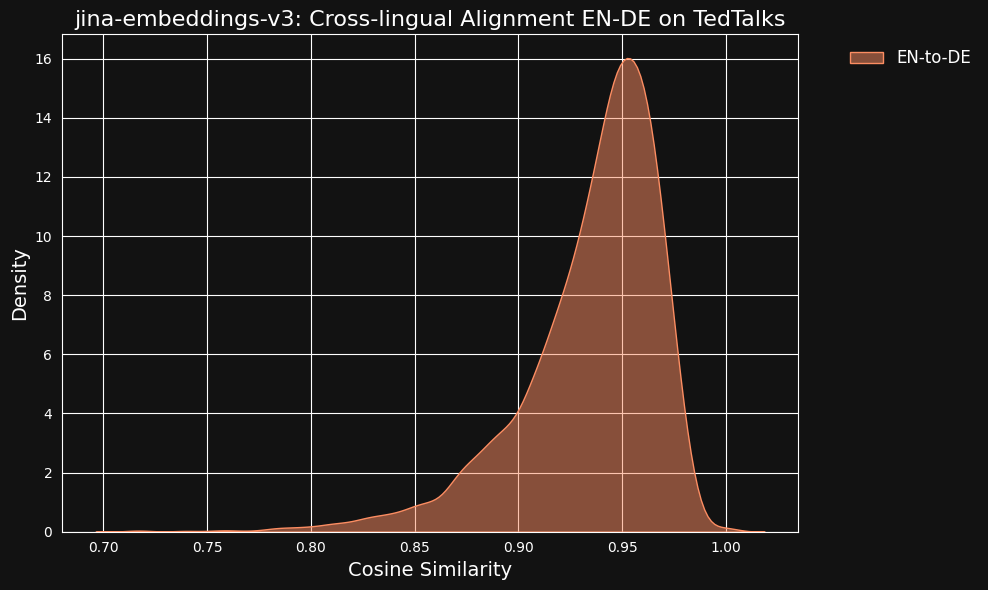
tagНасколько межъязыковые данные влияют на межъязыковое выравнивание?
Исчезающий языковой разрыв и высокий уровень межъязыковой производительности кажутся непропорциональными очень малой части обучающих данных, которая была явно межъязыковой. Только 3% контрастивных обучающих данных специально учат модель создавать выравнивания между языками.
Поэтому мы провели тест, чтобы проверить, вносят ли межъязыковые данные вообще какой-либо вклад.
Полное переобучение jina-embeddings-v3 без межъязыковых данных было бы слишком дорогим для небольшого эксперимента, поэтому мы загрузили модель xlm-roberta-base с Hugging Face и дополнительно обучили её с помощью контрастивного обучения, используя подмножество данных, которые мы использовали для обучения jina-embeddings-v3. Мы специально настроили количество межъязыковых данных для тестирования двух случаев: один без межъязыковых данных и один, где 20% пар были межъязыковыми. Вы можете видеть мета-параметры обучения в таблице ниже:
| Backbone | % Cross-Language | Learning Rate | Loss Function | Temperature |
xlm-roberta-base without X-language data | 0% | 5e-4 | InfoNCE | 0.05 |
xlm-roberta-base with X-language data | 20% | 5e-4 | InfoNCE | 0.05 |
Затем мы оценили межъязыковую производительность обеих моделей, используя бенчмарки STS17 и STS22 из MTEB и корреляцию Спирмана. Мы представляем результаты ниже:
tagSTS17
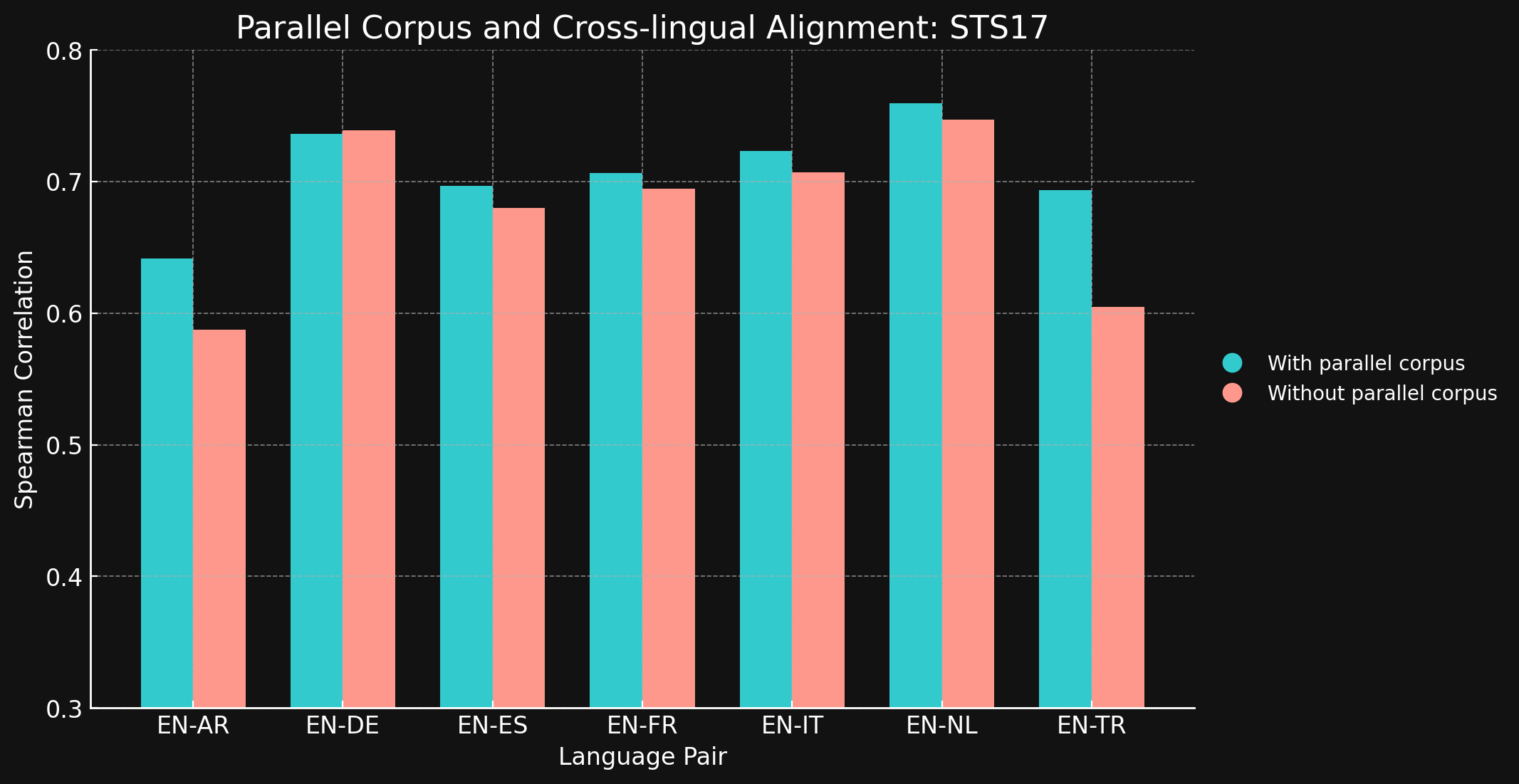
| Language Pair | With parallel corpora | Without parallel corpora |
| English ↔ Arabic | 0.6418 | 0.5875 |
| English ↔ German | 0.7364 | 0.7390 |
| English ↔ Spanish | 0.6968 | 0.6799 |
| English ↔ French | 0.7066 | 0.6944 |
| English ↔ Italian | 0.7232 | 0.7070 |
| English ↔ Dutch | 0.7597 | 0.7468 |
| English ↔ Turkish | 0.6933 | 0.6050 |
tagSTS22
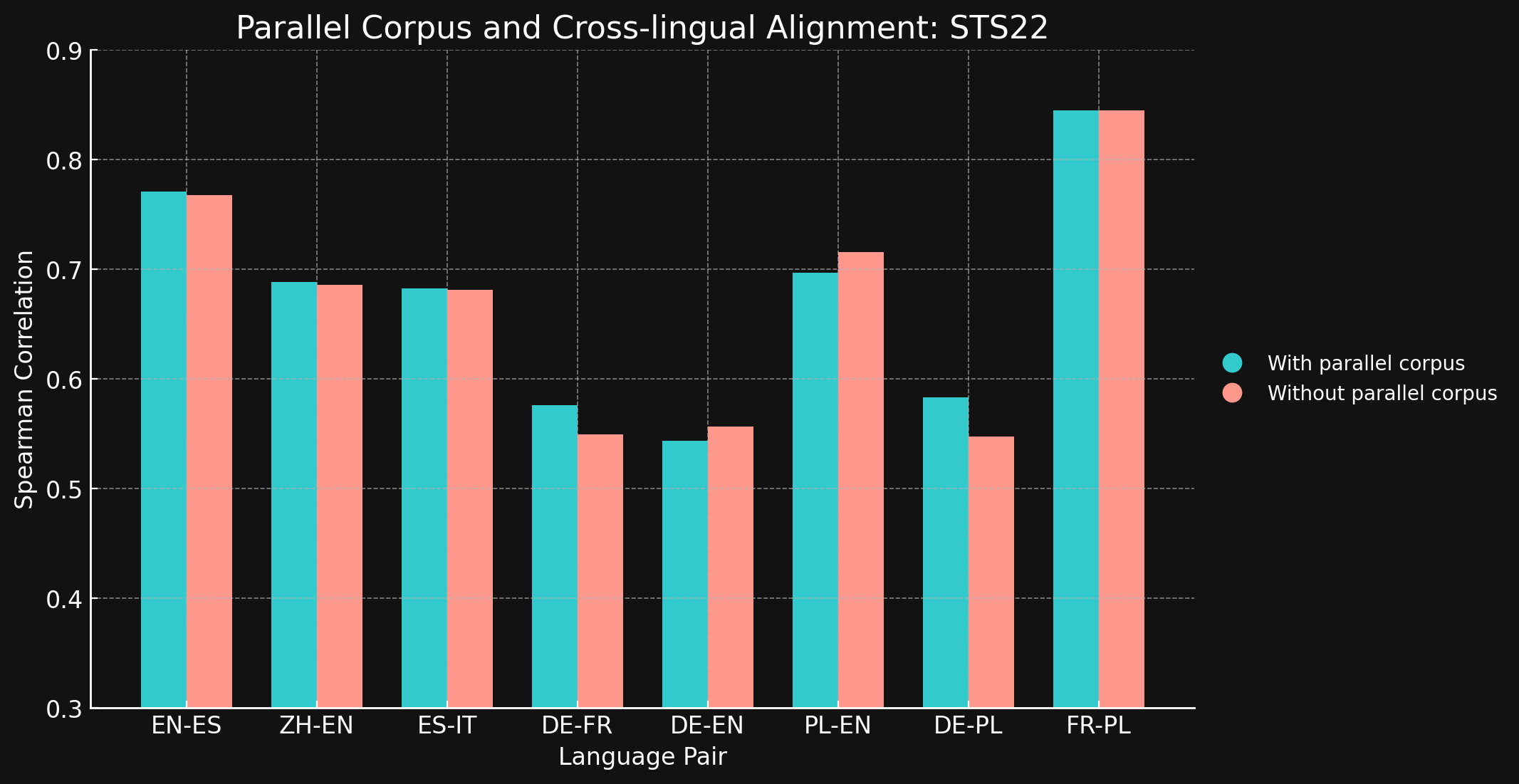
| Языковая пара | С параллельными корпусами | Без параллельных корпусов |
| English ↔ Spanish | 0.7710 | 0.7675 |
| Simplified Chinese ↔ English | 0.6885 | 0.6860 |
| Spanish ↔ Italian | 0.6829 | 0.6814 |
| German ↔ French | 0.5763 | 0.5496 |
| German ↔ English | 0.5439 | 0.5566 |
| Polish ↔ English | 0.6966 | 0.7156 |
| German ↔ English | 0.5832 | 0.5478 |
| French ↔ Polish | 0.8451 | 0.8451 |
Мы были удивлены, обнаружив, что для большинства протестированных языковых пар межъязыковые обучающие данные не принесли почти никакого улучшения. Трудно быть уверенным, что это останется верным для полностью обученных моделей с большими наборами данных, но это определенно свидетельствует о том, что явное межъязыковое обучение не добавляет много.
Однако стоит отметить, что STS17 включает пары английский/арабский и английский/турецкий. Это оба гораздо менее представленных языка в наших обучающих данных. Модель XML-RoBERTa, которую мы использовали, была предварительно обучена на данных, где арабский составлял 2,25%, а турецкий — 2,32%, что значительно меньше, чем для других тестируемых языков. Небольшой набор данных для контрастивного обучения, который мы использовали в этом эксперименте, содержал только 1,7% арабского и 1,8% турецкого.
Эти две языковые пары — единственные протестированные, где обучение с межъязыковыми данными показало явную разницу. Мы считаем, что явные межъязыковые данные более эффективны для языков, которые менее представлены в обучающих данных, но нам нужно больше исследовать эту область, прежде чем делать окончательные выводы. Роль и эффективность межъязыковых данных в контрастивном обучении — это область, в которой Jina AI ведет активные исследования.
tagЗаключение
Традиционные методы предварительного обучения языка, такие как Masked Language Modeling, оставляют "языковой разрыв", когда семантически похожие тексты на разных языках не выравниваются так близко, как должны. Мы показали, что режим контрастивного обучения Jina Embeddings очень эффективен в уменьшении или даже устранении этого разрыва.
Причины, по которым это работает, не совсем ясны. Мы используем явные межъязыковые пары текстов в контрастивном обучении, но только в очень малых количествах, и неясно, насколько большую роль они играют в обеспечении высококачественных межъязыковых результатов. Наши попытки показать четкий эффект в более контролируемых условиях не дали однозначного результата.
Однако очевидно, что jina-embeddings-v3 преодолел языковой разрыв предварительного обучения, что делает его мощным инструментом для многоязычных приложений. Он готов к использованию для любых задач, требующих одинаково высокой производительности на нескольких языках.
Вы можете использовать jina-embeddings-v3 через наш Embeddings API (с миллионом бесплатных токенов) или через AWS или Azure. Если вы хотите использовать его вне этих платформ или локально в вашей компании, просто помните, что он лицензирован под CC BY-NC 4.0. Свяжитесь с нами, если вы заинтересованы в коммерческом использовании.
