



В последнее время было много споров о рисках того, как AI-компании поглощают все данные в интернете, имеют ли они на это "разрешение" или нет. Мы рассмотрим вопрос "разрешения" позже – есть причина, почему мы заключили это слово в кавычки. Но что будет означать для LLM, когда открытый веб будет полностью исчерпан, поставщики контента закроют свои двери, и останется лишь тонкий ручеек новых данных для сбора?
tagОпасности AI-скрапинга
AI-компании относятся к интернету как к шведскому столу с данными, не утруждая себя правилами этикета. Достаточно посмотреть на Runway, собирающую видео с YouTube для обучения своей модели (вопреки условиям использования YouTube), Anthropic, делающую миллион запросов в день к iFixit и иск New York Times против OpenAI и Microsoft за использование защищенных авторским правом материалов.
Попытки блокировать скраперы в вашем robots.txt или условиях использования никак не помогают. Те скраперы, которым все равно, будут скрапить в любом случае, в то время как более добросовестные будут заблокированы. Нет никаких стимулов для скраперов играть по правилам. Мы можем видеть это в действии в недавней статье от Data Provenance Initiative:
Это не просто абстрактная проблема – iFixit теряет деньги и тратит ресурсы DevOps. ReadTheDocs накопил более $5,000 расходов на трафик всего за один месяц, с почти 10 ТБ за один день, из-за агрессивных краулеров. Если вы управляете веб-сайтом и подвергаетесь атаке краулера, который не следует правилам? Это может означать конец.
Так что же делать веб-сайту? Если AI-компании не собираются играть по правилам, ожидайте появления платных стен и уменьшения свободно доступного контента. Свободного веба больше нет. Все, что осталось – это "плати, чтобы играть".
tagЛегален ли скрапинг вообще?
Является ли скрапинг проблематичным? Да. Легален ли он? Тоже да. Веб-скрапинг легален в США, Европейском Союзе, Японии, Южной Корее и Канаде. Ни одна страна, похоже, не имеет законов, специально регулирующих эту практику, но суды по всему миру в целом согласны, что законно использовать автоматизацию для посещения веб-сайтов, которые открыты для всеобщего просмотра, и делать частные копии их содержимого.
Люди иногда полагают, что, разместив какое-то уведомление на веб-странице или в файле robots.txt, они могут запретить скрапинг или другие законные способы использования их веб-сайта и его содержимого. Это не работает. Такие уведомления не имеют юридической силы, а robots.txt является конвенцией IETF, которая не имеет силы закона. Без какого-либо акта подтверждения, как минимум нажатия кнопки "Я принимаю Условия использования", вы не можете навязывать условия посетителям вашего веб-сайта, и даже тогда они часто юридически не имеют силы.
 Joshua J. Kaufman
Joshua J. KaufmanОднако, хотя скрапинг легален, существуют некоторые ограничения:
- Практики, которые могут снизить удобство использования веб-сайта для других, например, слишком частые или быстрые обращения веб-скрапера, могут иметь гражданские или даже уголовные последствия в крайних случаях.
- Во многих странах есть законы, криминализирующие несанкционированный доступ к компьютерам. Если есть части веб-сайта, которые явно не предназначены для доступа широкой публики, их скрапинг может быть незаконным.
- Во многих странах есть законы, запрещающие обход технологий защиты от копирования. Если веб-сайт установил меры для предотвращения скачивания некоторого контента, вы можете нарушить закон, если все равно будете его скрапить.
- Веб-сайты с явными условиями использования, требующими подтверждения их принятия, могут запретить скрапинг и подать на вас в суд, если вы это сделаете, но результаты неоднозначны.
В США нет явного закона о скрапинге, но попытки использовать Закон о компьютерном мошенничестве и злоупотреблениях 1986 года для его запрета потерпели неудачу, последний раз в деле Девятого округа hiQ Labs против LinkedIn в 2019 году. Законодательство США сложное, с множеством судебных прецедентов и системой юрисдикций штатов и федеральных округов, что означает, что пока Верховный суд не вынесет решение по чему-либо, это не обязательно окончательно. (И иногда даже тогда не окончательно.)
В ЕС также нет специальных законов о скрапинге, но это давно распространенная и неоспариваемая практика. Положение о текстовом и интеллектуальном анализе данных в Директиве ЕС об авторском праве 2019 года настойчиво подразумевает, что скрапинг в целом легален.
Самые большие юридические проблемы возникают не с самим актом скрапинга, а с тем, что происходит после. Авторское право все еще применяется к данным, которые вы скрапите из веба. Вы можете хранить личную копию, но не можете распространять или перепродавать ее без потенциальных юридических проблем.
Масштабный веб-скрапинг почти всегда означает копирование "персональных данных", как определено в различных законах о защите данных и конфиденциальности. Европейский GDPR (Общий регламент по защите данных) определяет "персональные данные" как:
[Л]юбая информация, относящаяся к идентифицированному или идентифицируемому физическому лицу ('субъекту данных'); идентифицируемое физическое лицо – это лицо, которое может быть идентифицировано, прямо или косвенно, в частности, посредством ссылки на такой идентификатор, как имя, идентификационный номер, данные о местоположении, онлайн-идентификатор или один или несколько факторов, специфичных для физической, физиологической, генетической, умственной, экономической, культурной или социальной идентичности этого физического лица;
[GDPR, Ст. 4.1]
Если у вас есть хранилище персональных данных о любом лице, проживающем в ЕС, или о деятельности, происходящей в ЕС, у вас есть юридические обязательства по GDPR. Его охват настолько широк, что вы должны предполагать, что это верно для любой большой коллекции данных. Неважно, собрали ли вы данные или кто-то другой, если они у вас есть сейчас, вы несете за них ответственность. Если вы не выполняете свои обязательства по GDPR, ЕС может наказать вас независимо от того, в какой стране вы живете или где хранятся или обрабатываются данные.
Канадский PIPEDA (Закон о защите личной информации и электронных документах) похож на GDPR. Японский APPI (Закон о защите личной информации) охватывает многие те же области. Великобритания включила большинство элементов GDPR в свои внутренние законы при выходе из ЕС, и если они не будут изменены позже, они все еще действуют.
В США нет сопоставимого закона о защите данных на федеральном уровне, но CCPA (Закон о защите конфиденциальности потребителей Калифорнии) имеет положения, аналогичные GDPR, и применяется, если у вас есть данные о людях или деятельности в штате Калифорния.
Большинство развитых стран имеют законы о защите данных, которые ограничивают, по крайней мере в некоторых аспектах, то, что вы можете делать с массивными коллекциями данных из веба. Большинство судебных разбирательств по всему миру, касающихся скрапинга, были связаны с тем, как использовались данные, а не с тем, как они были собраны.
Таким образом, веб-скрапинг почти всегда легален. Сложности возникают с тем, что происходит после.
tagЛегально ли обучение AI на основе скрапинга?
Вероятно.
Веб-скрапинг в почти всех реальных случаях будет включать контент, защищенный авторским правом. Реальный вопрос: Можно ли использовать защищенный авторским правом контент для обучения AI без разрешения владельца?
Есть много отдельных юридических моментов, которые не полностью разрешены, но:
- В Европе Статья 4 Директивы ЕС об авторском праве 2019 года делает это законным с некоторыми оговорками.
- В Японии Статья 30(4) Закона об авторском праве, с поправками 2018 года, интерпретируется как разрешающая использование защищенных авторским правом произведений для обучения ИИ без разрешения.
- В США нет закона, конкретно регулирующего эту ситуацию, однако на протяжении многих лет считалось само собой разумеющимся, что статистический анализ материалов, защищенных авторским правом, является законным, даже когда результатом является коммерческий продукт. Хотя судебные дела Authors Guild, Inc. v. Google, Inc. и Authors Guild, Inc. v. HathiTrust конкретно не касаются ИИ, они настолько расширяют сферу действия "добросовестного использования" в рамках законодательства США, что трудно представить, как обучение ИИ может быть незаконным. Американская правовая система не дает явного ответа, и несколько дел, проверяющих этот вывод, находятся на рассмотрении в судах.
Ряд более мелких юрисдикций также определили, что это законно, и, насколько мне известно, ни одна из них до сих пор не признала это незаконным.
Европейское законодательство об авторском праве позволяет владельцам защищенных авторским правом данных ограничивать использование своих произведений для обучения ИИ, указывая на это "надлежащим образом". В настоящее время нет указаний, как именно они должны это делать.
Японское законодательство об авторском праве ограничивает использование материалов, защищенных авторским правом, когда это может "необоснованно ущемлять интересы владельца авторских прав". Это обычно означает, что правообладатель должен показать, как конкретная модель ИИ снижает экономическую ценность их работы, чтобы иметь возможность предъявить иск.
Следует отметить, что Google, Microsoft, OpenAI, Adobe и Shutterstock предложили возместить убытки любому пользователю их генеративных ИИ-продуктов, который столкнется с юридическими проблемами на основании авторского права. Это явный признак того, что их юристы считают их действия законными согласно законодательству США.
tagЧто означает жадный скрейпинг для ИИ
Бум скрейпинга ИИ превращает интернет в цифровой Дикий Запад. Эти скрейперы относятся к robots.txt как к вчерашним новостям, бомбардируя сайты вроде iFixit бесконечными запросами. Это не просто раздражает – это потенциально разрушительно для веба и заставляет нас переосмыслить работу открытого интернета. Или как он может перестать работать в ближайшем будущем. Только с экономической и социальной точки зрения может измениться многое:
Разрушение доверия: Эта гонка за данными для ИИ может привести к массовому разрушению доверия в интернете. Представьте будущее, где каждый сайт встречает вас с подозрением, заставляя доказывать, что вы человек, прежде чем вы сможете даже взглянуть на их контент. Речь идет о большем количестве CAPTCHA, стен авторизации, тестов "кликните по всем светофорам". Это как пытаться попасть в подпольный бар, но вместо секретного пароля нужно убедить охранника, что вы не очень умная машина.
Ограниченный контент, созданный людьми: Создатели контента, уже опасающиеся кражи своих работ, начинают укреплять оборону. Мы можем увидеть рост платных стен, разделов только для подписчиков и блокировок контента. Дни свободного просмотра и обучения могут стать ностальгическим воспоминанием, как звуки dial-up модема или статусы в AIM. Если обычные люди не могут получить доступ, то и злонамеренному скрейперу будет еще сложнее проникнуть.
Судебные дела: Может потребоваться годы или даже десятилетия, прежде чем будут решены все юридические вопросы, связанные с ИИ. Интернету около тридцати лет, и некоторые его правовые аспекты все еще остаются неясными. Независимо от того, правы вы или нет, если вы не можете позволить себе провести годы в суде, выясняя, что разрешено, а что нет, вам есть о чем беспокоиться.
Мелкие разоряются, толстосумы богатеют: Эта мания скрейпинга не просто неприятность – она создает реальную нагрузку на веб-инфраструктуру. Сайтам, борющимся с наплывом трафика от ИИ, может потребоваться обновление до более мощных серверов, что недешево. Небольшие сайты и интересные личные проекты могут быть вытеснены из игры, оставляя нам веб (и данные для обучения LLM), где доминируют те, кто достаточно богат, чтобы пережить бурю или заключить лицензионные соглашения с компаниями ИИ. Это сценарий "выживания богатейших", который может сделать интернет (и знания LLM) гораздо менее разнообразным и интересным. Закрывая доступ к свободно доступным данным, они могут затем взимать плату за вход с корпораций ИИ или просто лицензировать данные тому, кто больше заплатит. Нет денег? Вышибала покажет вам на дверь.
tagДанные, сгенерированные ИИ, спешат на помощь?
Захват данных не только встряхивает веб-сайты – он создает предпосылки для потенциального дефицита знаний ИИ. Когда открытый веб поднимает свои мосты, модели ИИ обнаруживают, что им не хватает свежих, качественных данных.
Этот дефицит данных может привести к неприятному случаю туннельного зрения ИИ. Без постоянного потока новой информации модели ИИ рискуют стать эхо-камерами устаревших знаний. Представьте, что вы спрашиваете ИИ о текущих событиях и получаете ответы, которые звучат как из прошлого года – или хуже, из параллельной вселенной, где факты взяли отпуск.
Если данные, созданные людьми, заблокированы, компаниям все равно нужно где-то брать свои тренировочные данные. Один из примеров – это синтетические данные: Данные, созданные LLM для обучения других LLM. Это включает широко используемые методы, такие как дистилляция моделей и генерация тренировочных данных для компенсации предвзятости.

Использование синтетических данных означает, что не нужно преодолевать препятствия для лицензирования данных, созданных людьми, что, как мы видели, становится все сложнее. Это также помогает сбалансировать ситуацию – многие данные в интернете не отражают разнообразие реального мира. Генерация синтетических данных может помочь сделать модель более репрезентативной для реальности (или иногда нет). Наконец, для медицинских и юридических случаев синтетические данные устраняют необходимость очистки данных от персональной информации.
Однако, обратная сторона медали заключается в том, что будущие модели также будут обучаться на созданных ИИ данных, которые вы действительно не хотите использовать для их обучения, а именно "Халтура": низкокачественные данные, сгенерированные ИИ, например, некогда любимый технический блог, теперь публикующий малоценные статьи, сгенерированные ИИ, под именами своих бывших сотрудников, рецепты, сгенерированные ИИ, для маловероятных блюд вроде мохито в медленноварке и мороженого с братвурстом, или Креветочный Иисус, захватывающий Facebook.
Поскольку это намного дешевле и проще, чем создание хорошего старомодного контента вручную, оно быстро заполоняет интернет.
Судя по тому, что мы видим сегодня, контент, сгенерированный ИИ, превосходит доступный контент, созданный людьми. GPT-5 будет обучаться (частично) на данных, созданных GPT-4. GPT-6, в свою очередь, будет обучаться на данных, созданных GPT-5. И так далее, и так далее.
tagКоллапс моделей и как его избежать
Использование собственных выходных данных в качестве входных плохо как для людей, так и для LLM. Даже если вы очень избирательны в том, сколько синтетических данных вы используете и какого типа, вы не можете гарантировать, что ваша модель не станет хуже
Для генеративных моделей ИИ в целом падение качества и разнообразия выходных данных экспериментально измеримо и происходит довольно быстро. У моделей, генерирующих изображения, появляются аномалии после нескольких поколений, а в одной статье большая языковая модель, обученная на данных Wikipedia, которая давала связные и точные ответы на запросы, к девятому поколению обучения на собственных выходных данных отвечала на запросы повторением слов "хвостатые зайцы" снова и снова.
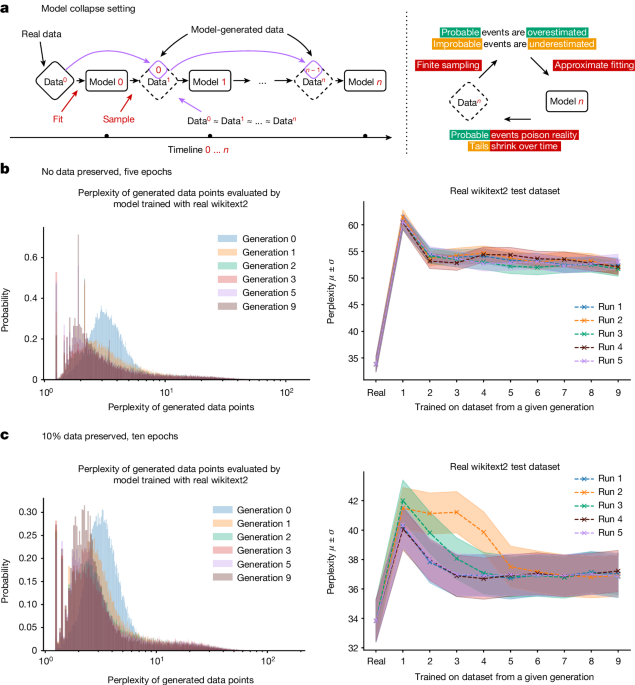
Это довольно просто объяснить: AI-модель является аппроксимацией своих обучающих данных. AI-модель, обученная на выводе другой AI-модели, является аппроксимацией аппроксимации. С каждым циклом обучения разница между аппроксимацией и "истинными" данными реального мира становится все больше и больше.
Мы называем это "коллапсом модели".
Поскольку AI-сгенерированные данные становятся все более распространенными, обучение новых моделей на данных, собранных из Интернета, рискует снизить производительность модели. У нас есть основания полагать, что пока количество реальных, созданных человеком данных не уменьшается, наши модели не станут намного хуже, но они и не станут лучше. Однако их обучение займет больше времени, если мы не сможем отделить AI-созданные данные от созданных человеком. Создание новых моделей станет дороже, без улучшения качества.
Ирония здесь очевидна. Ненасытный аппетит AI к данным может привести к их дефициту. Расстройство модельной аутофагии похоже на коровье бешенство для AI: как кормление коров отходами говядины привело к новому виду паразитарной болезни мозга, так и обучение AI на растущем количестве AI-выводов приводит к разрушительным ментальным патологиям.
Хорошая новость в том, что AI не может позволить себе заменить человечество, потому что ему нужны наши данные. Плохая новость в том, что он может затормозить свое собственное развитие, разрушая свои источники данных.
Чтобы избежать этого предсказуемого голода AI-знаний, нам нужно переосмыслить то, как мы обучаем и используем AI-модели. Мы уже видим такие решения, как Retrieval-Augmented Generation, который пытается избежать использования AI-моделей как источника фактической информации и рассматривает их вместо этого как устройства для оценки и реорганизации внешних источников информации. Другой путь вперед лежит через специализацию, где мы адаптируем модели для выполнения определенных классов задач, используя курируемые обучающие данные, сфокусированные на узких областях. Мы могли бы заменить предполагаемые модели общего назначения, такие как ChatGPT, специализированными AI: LawLLM, MedLLM, MyLittlePonyLLM и так далее.
Существуют и другие возможности, и трудно сказать, какие новые техники откроют исследователи. Возможно, есть лучший способ генерировать синтетические данные или способы получать лучшие модели из меньшего количества данных. Но нет гарантии, что дальнейшие исследования решат проблему.
В конечном итоге, этот вызов может заставить AI-сообщество проявить креативность. В конце концов, необходимость – мать изобретения, и ландшафт AI с дефицитом данных может спровоцировать действительно инновационные решения. Кто знает? Следующий большой прорыв в AI может прийти не от большего количества данных, а от того, как делать больше с меньшим.
tagЧто произойдет, если только мегакорпорации смогут позволить себе сбор данных?
Для многих людей сегодня интернет – это Facebook, Instagram и X, которые они видят через черный стеклянный прямоугольник в своих руках. Он гомогенизирован, "безопасен" и контролируется привратниками, которые решают (через политики и свои алгоритмы), что (и кого) вы видите, а что нет.
Так было не всегда. Всего пару десятилетий назад у нас были пользовательские блоги, независимые веб-сайты и многое другое. В восьмидесятых конкурировали десятки операционных систем и аппаратных стандартов. Но к 2010-м годам Apple и Microsoft победили, положив начало тенденции к гомогенизации.
То же самое мы видим с веб-браузерами, смартфонами и сайтами социальных сетей. Мы начинаем со всплеска разнообразия и новых идей, прежде чем крупные игроки захватывают мяч и затрудняют игру для всех остальных.
При этом, хотя эти игроки и имели монополию, некоторым мелким рыбкам все же удалось проскользнуть. (Возьмем, например, Linux и Firefox). "Аутсайдер добивается успеха" вряд ли произойдет с LLM. Когда у маленьких игроков нет финансовых возможностей получить доступ к разнообразным и актуальным обучающим данным, они не могут создавать высококачественные модели. А без этого как они могут оставаться в бизнесе?
Гиганты имеют ресурсы, чтобы продолжать кормить свои AI-модели постоянным потоком свежей информации, даже когда более широкая сеть затягивает пояс. Между тем, более мелкие игроки и стартапы вынуждены довольствоваться остатками данных, пытаясь питать свои алгоритмы устаревшими крохами. Это разрыв в знаниях, который может нарастать как снежный ком. По мере того как богатые данными становятся еще богаче в плане понимания и возможностей, бедные данными рискуют отстать еще больше, их AI становятся все более устаревшими и менее конкурентоспособными с каждым днем. Речь идет не только о том, у кого самые блестящие AI-игрушки – речь о том, кто получит возможность формировать будущее технологий, коммерции и даже того, как мы получаем доступ к информации. Мы смотрим в будущее, где горстка технологических гигантов может держать ключи от самых продвинутых AI-королевств, в то время как все остальные останутся в цифровых темных веках.
Учитывая все привлекательное содержимое, доступное для лицензирования, маловероятно, что одна мегакорпорация будет той, кто лицензирует все, как Netflix в старые времена. Помните это? Вы подписывались на один сервис и получали каждое шоу, о котором когда-либо мечтали. Сегодня шоу распределены между Hulu, Netflix, Disney+ и как бы там ни называли HBO Max на этой неделе. Иногда любимое шоу может просто испариться в эфире. Это может быть будущим LLM: Google имеет приоритетный доступ к Reddit, в то время как OpenAI получает доступ к Financial Times. iFixit? Эти данные просто больше не существуют, хранятся лишь как пыльные эмбеддинги и никогда не обновляются. Вместо одной модели, правящей всеми, мы можем столкнуться с фрагментацией и изменением возможностей по мере того, как права на лицензирование перебрасываются между поставщиками AI.
tagВ заключение
Нравится нам это или нет, но веб-скрейпинг никуда не денется. Контент-провайдеры уже возводят барьеры, ограничивая доступ и открывая двери только тем, кто может позволить себе лицензировать контент. Это серьезно ограничивает ресурсы, на которых может обучаться любая LLM, в то время как небольшие компании вытесняются из борьбы за ценный контент, а остальные "трофеи" делятся между LLM технологических гигантов. Это напоминает пост-нетфликсовский мир стриминга, только теперь речь идет о знаниях.
Пока доступных данных, созданных человеком, становится все меньше, AI-генерируемая "каша" процветает. Обучение моделей на таких данных может привести к замедлению улучшений или даже к коллапсу модели. Единственный способ исправить это — мыслить нестандартно, что идеально подходит стартапам с их культурой инноваций и разрушения устоявшихся норм. Однако те самые данные, которые лицензируются только крупным игрокам, являются жизненно необходимыми для выживания таких стартапов.
Ограничивая справедливый доступ к данным, мега-корпорации не просто душат конкуренцию — они душат будущее самого AI, пресекая те самые инновации, которые могли бы вывести нас за пределы этого потенциального цифрового темного века.
AI-революция — это не будущее, AI — это настоящее. По словам Уильяма Гибсона: "Будущее уже здесь, просто оно неравномерно распределено". И оно может стать еще более неравномерно распределенным.
