

Недавно я изучил DSPy — передовой фреймворк, разработанный группой Stanford NLP, направленный на алгоритмическую оптимизацию промптов языковых моделей (LM). За последние три дня я собрал некоторые первоначальные впечатления и ценные наблюдения о DSPy. Отмечу, что мои наблюдения не призваны заменить официальную документацию DSPy. Фактически, я настоятельно рекомендую ознакомиться с их документацией и README хотя бы раз перед погружением в этот пост. Моё обсуждение здесь отражает предварительное понимание DSPy после нескольких дней изучения его возможностей. Существует несколько продвинутых функций, таких как DSPy Assertions, Typed Predictor и настройка весов LM, которые я еще не успел тщательно изучить.
 stanfordnlp
stanfordnlpНесмотря на мой опыт работы в Jina AI, которая в основном фокусируется на поисковых основах, мой интерес к DSPy не был напрямую обусловлен его потенциалом в Retrieval-Augmented Generation (RAG). Вместо этого меня заинтересовала возможность использования DSPy для автоматической настройки промптов для решения некоторых задач генерации.
Если вы новичок в DSPy и ищете доступную отправную точку, или если вы знакомы с фреймворком, но считаете официальную документацию запутанной или сложной, эта статья предназначена для вас. Я также решил не придерживаться строго идиом DSPy, которые могут показаться пугающими для новичков. Итак, давайте углубимся.
tagЧто мне нравится в DSPy
tagDSPy замыкает цикл промпт-инжиниринга
Больше всего меня воодушевляет подход DSPy к замыканию цикла промпт-инжиниринга, превращая то, что обычно является ручным, кустарным процессом, в структурированный, четко определенный рабочий процесс машинного обучения: подготовка наборов данных, определение модели, обучение, оценка и тестирование. По моему мнению, это самый революционный аспект DSPy.
Путешествуя по Bay Area и общаясь со многими основателями стартапов, сосредоточенных на оценке LLM, я часто слышал обсуждения метрик, галлюцинаций, наблюдаемости и соответствия требованиям. Однако эти разговоры часто не переходят к критически важным следующим шагам: Имея все эти метрики, что делать дальше? Можно ли считать стратегическим подходом корректировку формулировок в наших промптах в надежде, что определенные волшебные слова (например, "моя бабушка умирает") могут улучшить наши метрики? Этот вопрос оставался без ответа у многих стартапов по оценке LLM, и я тоже не мог с ним справиться — пока не открыл для себя DSPy. DSPy представляет четкий, программный метод оптимизации промптов на основе конкретных метрик или даже оптимизации всего конвейера LLM, включая как промпты, так и веса LLM.
Харрисон, CEO LangChain, и Логан, бывший глава Developer Relations в OpenAI, оба заявили в подкасте Unsupervised Learning, что 2024 год должен стать поворотным годом для оценки LLM. Именно поэтому я считаю, что DSPy заслуживает больше внимания, чем получает сейчас, поскольку DSPy предоставляет критически важный недостающий элемент головоломки.
tagDSPy разделяет логику и текстовое представление
Другой аспект DSPy, который впечатляет меня, заключается в том, что он формулирует промпт-инжиниринг в воспроизводимый и LLM-агностический модуль. Для достижения этого он извлекает логику из промпта, создавая четкое разделение между логикой и текстовым представлением, как показано ниже.
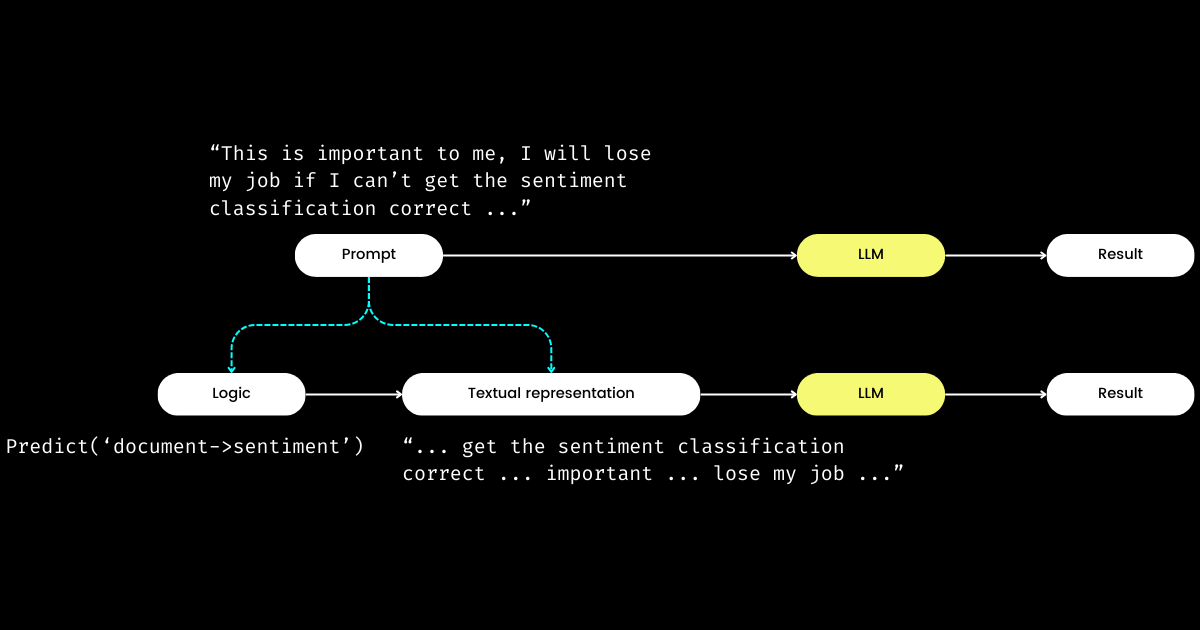
dspy.Module) и её текстового представления. Логика неизменна, воспроизводима, тестируема и LLM-агностична. Текстовое представление — это просто следствие логики.Концепция DSPy о логике как неизменной, тестируемой и LLM-агностичной "причине", где текстовое представление является лишь её "следствием", может изначально показаться озадачивающей. Это особенно верно в свете широко распространенного убеждения, что "будущее языков программирования — это естественный язык". Принимая идею, что "промпт-инжиниринг — это будущее", можно испытать момент замешательства при столкновении с философией дизайна DSPy. Вопреки ожиданиям упрощения, DSPy вводит массив модулей и синтаксис сигнатур, казалось бы, возвращая естественно-языковые промпты к сложности программирования на C!
Но почему выбран такой подход? По моему пониманию, в основе программирования промптов лежит базовая логика, а коммуникация служит усилителем, потенциально улучшая или ухудшая её эффективность. Директива "Do sentiment classification" представляет базовую логику, тогда как фраза вроде "Follow these demonstrations or I will fire you" — это один из способов её коммуникации. Аналогично реальным взаимодействиям, трудности в выполнении задач часто возникают не из-за неправильной логики, а из-за проблем в коммуникации. Это объясняет, почему многие, особенно не носители языка, находят промпт-инжиниринг сложным. Я наблюдал, как высококвалифицированные программисты в моей компании испытывают трудности с промпт-инжинирингом не из-за отсутствия логики, а потому что они не "говорят на нужной волне". Разделяя логику и промпт, DSPy позволяет детерминированно программировать логику через dspy.Module, позволяя разработчикам сосредоточиться на логике так же, как они делали бы это в традиционной разработке, независимо от используемой LLM.
Итак, если разработчики фокусируются на логике, то кто управляет текстовым представлением? DSPy берет на себя эту роль, используя ваши данные и метрики оценки для улучшения текстового представления — всё от определения нарративного фокуса до оптимизации подсказок и выбора хороших демонстраций. Примечательно, что DSPy может даже использовать метрики оценки для тонкой настройки весов LLM!
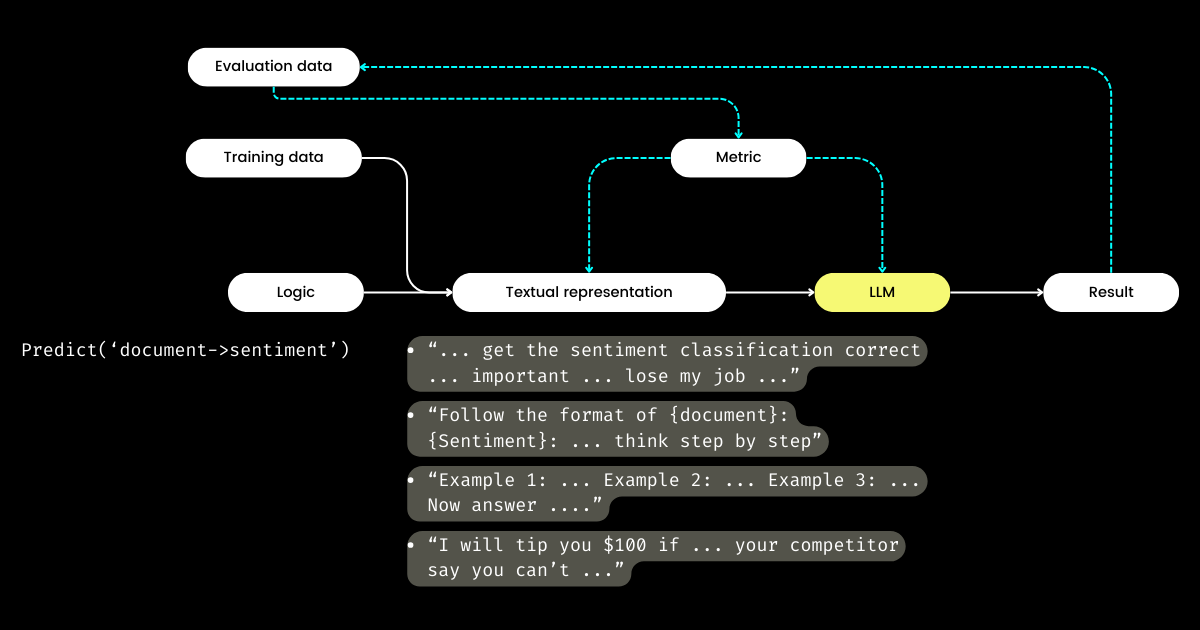
Для меня ключевые вклады DSPy — замыкание цикла обучения и оценки в промпт-инжиниринге и разделение логики от текстового представления — подчеркивают его потенциальную значимость для систем LLM/Agent. Безусловно амбициозное видение, но определенно необходимое!
tagЧто, по моему мнению, можно улучшить в DSPy
Во-первых, DSPy представляет крутую кривую обучения для новичков из-за своих идиом. Термины вроде signature, module, program, teleprompter, optimization и compile могут быть ошеломляющими. Даже для тех, кто хорошо разбирается в промпт-инжиниринге, навигация по этим концепциям внутри DSPy может быть сложным лабиринтом.
Эта сложность напоминает мой опыт работы с Jina 1.0, где мы ввели множество идиом, таких как chunk, document, driver, executor, pea, pod, querylang и flow (мы даже разработали милые стикеры, чтобы помочь пользователям запомнить!).






Большинство этих ранних концепций были удалены в последующих рефакторингах Jina. Сегодня только Executor, Document и Flow пережили "великую чистку". Мы добавили новую концепцию, Deployment, в Jina 3.0, так что всё уравновесилось. 🤷
Эта проблема не уникальна для DSPy или Jina; вспомните множество концепций и абстракций, представленных TensorFlow между версиями 0.x и 1.x. Я считаю, что эта проблема часто возникает на ранних стадиях программных фреймворков, когда есть стремление отразить академические обозначения непосредственно в кодовой базе для обеспечения максимальной точности и воспроизводимости. Однако не все пользователи ценят такие детальные абстракции, предпочтения варьируются от желания простых однострочных решений до требований большей гибкости. Я подробно обсуждал эту тему абстракций в программных фреймворках в блог-посте 2020 года, который может быть интересен читателям.


Во-вторых, документация DSPy иногда страдает от недостатка согласованности. Термины вроде module и program, teleprompter и optimizer, или optimize и compile (иногда называемые training или bootstrapping) используются взаимозаменяемо, что добавляет путаницы. Следовательно, я потратил свои первые часы с DSPy, пытаясь понять, что именно он optimizes и что включает в себя процесс bootstrapping.
Несмотря на эти препятствия, по мере более глубокого погружения в DSPy и повторного обращения к документации, вы, вероятно, испытаете моменты прозрения, когда всё начнёт складываться, раскрывая связи между его уникальной терминологией и знакомыми конструкциями, встречающимися во фреймворках вроде PyTorch. Однако у DSPy, несомненно, есть потенциал для улучшения в будущих версиях, особенно в плане повышения доступности фреймворка для промпт-инженеров без опыта работы с PyTorch.
tagРаспространённые проблемы для новичков в DSPy
В разделах ниже я собрал список вопросов, которые изначально тормозили мой прогресс с DSPy. Моя цель - поделиться этими знаниями в надежде, что они могут прояснить похожие проблемы для других учащихся.
tagЧто такое teleprompter, optimization и compile? Что именно оптимизируется в DSPy?
В DSPy "Teleprompters" - это оптимизатор (и похоже, что @lateinteraction обновляет документацию и код для большей ясности). Функция compile действует в сердце этого оптимизатора, аналогично вызову optimizer.optimize(). Думайте об этом как об эквиваленте тренировки в DSPy. Процесс compile() нацелен на настройку:
- few-shot демонстраций,
- инструкций,
- весов LLM
Однако большинство начальных руководств по DSPy не углубляются в настройку весов и инструкций, что приводит к следующему вопросу.
tagЧто такое bootstrap в DSPy?
Bootstrap относится к созданию самогенерируемых демонстраций для few-shot обучения в контексте, что является важной частью процесса compile() (т.е. оптимизации/тренировки, как я упоминал выше). Эти few-shot демонстрации генерируются из предоставленных пользователем размеченных данных; и одна демонстрация часто состоит из входных данных, выходных данных, обоснования (например, в Chains of Thought) и промежуточных входных и выходных данных (для многоэтапных промптов). Конечно, качественные few-shot демонстрации являются ключом к превосходному результату. Для этого DSPy позволяет определять пользовательские метрические функции, чтобы обеспечить выбор только тех демонстраций, которые соответствуют определённым критериям, что приводит к следующему вопросу.
tagЧто такое метрическая функция DSPy?
После практического опыта работы с DSPy я пришёл к выводу, что метрической функции нужно уделять гораздо больше внимания, чем это делается в текущей документации. Метрическая функция в DSPy играет ключевую роль как в фазах оценки, так и в тренировке, действуя также как функция "потерь" благодаря своей неявной природе (контролируется через trace=None):
def keywords_match_jaccard_metric(example, pred, trace=None):
# Jaccard similarity between example keywords and predicted keywords
A = set(normalize_text(example.keywords).split())
B = set(normalize_text(pred.keywords).split())
j = len(A & B) / len(A | B)
if trace is not None:
# act as a "loss" function
return j
return j > 0.8 # act as evaluationЭтот подход существенно отличается от традиционного машинного обучения, где функция потерь обычно непрерывна и дифференцируема (например, hinge/MSE), в то время как метрика оценки может быть совершенно другой и дискретной (например, NDCG). В DSPy функции оценки и потерь объединены в метрической функции, которая может быть дискретной и чаще всего возвращает логическое значение. Метрическая функция также может интегрировать LLM! В примере ниже я реализовал нечёткое сравнение с использованием LLM, чтобы определить, схожи ли предсказанное значение и эталонный ответ по порядку величины, например, "1 миллион долларов" и "$1M" вернут true.
class Assess(dspy.Signature):
"""Assess the if the prediction is in the same magnitude to the gold answer."""
gold_answer = dspy.InputField(desc='number, could be in natural language')
prediction = dspy.InputField(desc='number, could be in natural language')
assessment = dspy.OutputField(desc='yes or no, focus on the number magnitude, not the unit or exact value or wording')
def same_magnitude_correct(example, pred, trace=None):
return dspy.Predict(Assess)(gold_answer=example.answer, prediction=pred.answer).assessment.lower() == 'yes'Метрическая функция, при всей своей мощи, оказывает значительное влияние на пользовательский опыт DSPy, определяя не только финальную оценку качества, но и влияя на результаты оптимизации. Хорошо разработанная метрическая функция может привести к оптимизированным промптам, в то время как плохо составленная может привести к провалу оптимизации. При решении новой задачи с помощью DSPy вы можете обнаружить, что тратите столько же времени на разработку логики (т.е. DSPy.Module), сколько и на метрическую функцию. Такой двойной фокус на логике и метриках может быть пугающим для новичков.
tag"Bootstrapped 0 full traces after 20 examples in round 0" что это значит?
Это сообщение, тихо появляющееся во время compile(), заслуживает вашего пристального внимания, поскольку по сути означает, что оптимизация/компиляция не удалась, и полученный промпт не лучше простого few-shot. Что идет не так? Я обобщил некоторые советы, которые помогут вам отладить программу DSPy при появлении такого сообщения:
Ваша метрическая функция некорректна
Правильно ли реализована функция your_metric, используемая в BootstrapFewShot(metric=your_metric)? Проведите модульное тестирование. Возвращает ли your_metric когда-либо True, или она всегда возвращает False? Обратите внимание, что возврат True критически важен, поскольку это критерий, по которому DSPy считает пример "успешным" при бутстрапе. Если вы возвращаете True для каждой оценки, то каждый пример считается "успешным" при бутстрапе! Это, конечно, не идеально, но именно так вы можете настроить строгость метрической функции, чтобы изменить результат "Bootstrapped 0 full traces". Хотя в документации DSPy указано, что метрики также могут возвращать скалярные значения, изучив базовый код, я бы не рекомендовал это новичкам.
Ваша логика (DSPy.Module) некорректна
Если метрическая функция корректна, тогда нужно проверить, правильно ли реализована ваша логика dspy.Module. Во-первых, убедитесь, что сигнатура DSPy правильно назначена для каждого шага. Встроенные сигнатуры, такие как dspy.Predict('question->answer'), просты в использовании, но для качества я настоятельно рекомендую реализацию с использованием сигнатур на основе классов. В частности, добавьте описательные докстринги к классу, заполните поля desc для InputField и OutputField — все это дает языковой модели подсказки о каждом поле. Ниже я реализовал два многоступенчатых DSPy.Module для решения задач Ферми, один со встроенной сигнатурой, другой с сигнатурой на основе классов.
class FermiSolver(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict('question -> initial_guess')
self.step2 = dspy.Predict('question, initial_guess -> calculated_estimation')
self.step3 = dspy.Predict('question, initial_guess, calculated_estimation -> variables_and_formulae')
self.step4 = dspy.ReAct('question, initial_guess, calculated_estimation, variables_and_formulae -> gathering_data')
self.step5 = dspy.Predict('question, initial_guess, calculated_estimation, variables_and_formulae, gathering_data -> answer')
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5Решатель задач Ферми, использующий только встроенные сигнатуры
class FermiStep1(dspy.Signature):
question = dspy.InputField(desc='Fermi problems involve the use of estimation and reasoning')
initial_guess = dspy.OutputField(desc='Have a guess – don't do any calculations yet')
class FermiStep2(FermiStep1):
initial_guess = dspy.InputField(desc='Have a guess – don't do any calculations yet')
calculated_estimation = dspy.OutputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
class FermiStep3(FermiStep2):
calculated_estimation = dspy.InputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
variables_and_formulae = dspy.OutputField(desc='Write a formula or procedure to solve your problem')
class FermiStep4(FermiStep3):
variables_and_formulae = dspy.InputField(desc='Write a formula or procedure to solve your problem')
gathering_data = dspy.OutputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
class FermiStep5(FermiStep4):
gathering_data = dspy.InputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
answer = dspy.OutputField(desc='the final answer, must be a numerical value')
class FermiSolver2(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict(FermiStep1)
self.step2 = dspy.Predict(FermiStep2)
self.step3 = dspy.Predict(FermiStep3)
self.step4 = dspy.Predict(FermiStep4)
self.step5 = dspy.Predict(FermiStep5)
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5Решатель задач Ферми, использующий сигнатуры на основе классов с более подробным описанием каждого поля.
Также проверьте часть def forward(self, ). Для многоступенчатых модулей убедитесь, что выход (или все выходы, как в FermiSolver) с последнего шага подается как вход на следующий шаг.
Ваша задача просто слишком сложна
Если и метрика, и модуль кажутся правильными, возможно, ваша задача просто слишком сложна, и реализованной логики недостаточно для её решения. Следовательно, DSPy находит невозможным создать бутстрап-примеры с вашей логикой и метрической функцией. В этом случае есть несколько вариантов:
- Использовать более мощную ЯМ. Например, заменить
gpt-35-turbo-instructнаgpt-4-turboв качестве ЯМ-ученика, использовать более сильную ЯМ в качестве учителя. Это часто бывает довольно эффективно. В конце концов, более сильная модель означает лучшее понимание промптов. - Улучшить вашу логику. Добавить или заменить некоторые шаги в вашем
dspy.Moduleна более сложные. Например, заменитьPredictнаChainOfThoughtProgramOfThought, добавить шагRetrieval. - Добавить больше обучающих примеров. Если 20 примеров недостаточно, стремитесь к 100! Тогда можно надеяться, что один пример пройдет проверку метрикой и будет выбран
BootstrapFewShot. - Переформулировать задачу. Часто задача становится нерешаемой, когда формулировка неверна. Но если посмотреть на неё под другим углом, всё может стать гораздо проще и очевиднее.
На практике процесс включает в себя сочетание проб и ошибок. Например, я столкнулся с особенно сложной задачей: генерацией SVG-иконки, похожей на иконки Google Material Design, на основе двух-трех ключевых слов. Моя начальная стратегия заключалась в использовании простого DSPy.Module, который использует dspy.ChainOfThought('keywords -> svg'), в сочетании с метрической функцией, оценивающей визуальное сходство между сгенерированным SVG и эталонным SVG Material Design, аналогично алгоритму pHash. Я начал с 20 обучающих примеров, но после первого раунда получил "Bootstrapped 0 full traces after 20 examples in round 0", что указывало на неудачу оптимизации. Увеличив набор данных до 100 примеров, пересмотрев модуль для включения нескольких этапов и настроив порог метрической функции, я в итоге получил 2 бутстрап-демонстрации и смог получить некоторые оптимизированные промпты.
