
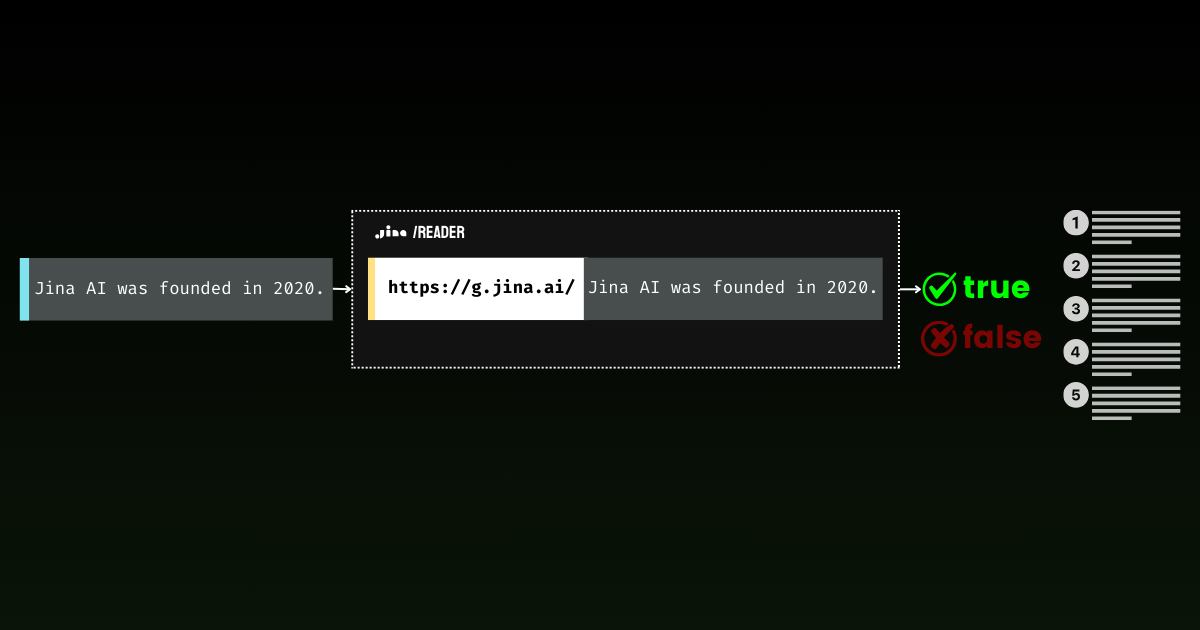

Граундинг абсолютно необходим для приложений GenAI.
Без граундинга LLM более склонны к галлюцинациям и генерации неточной информации, особенно когда в их обучающих данных отсутствуют актуальные или конкретные знания. Независимо от того, насколько сильны способности LLM к рассуждению, она просто не может дать правильный ответ, если информация была введена после даты отсечения ее знаний.
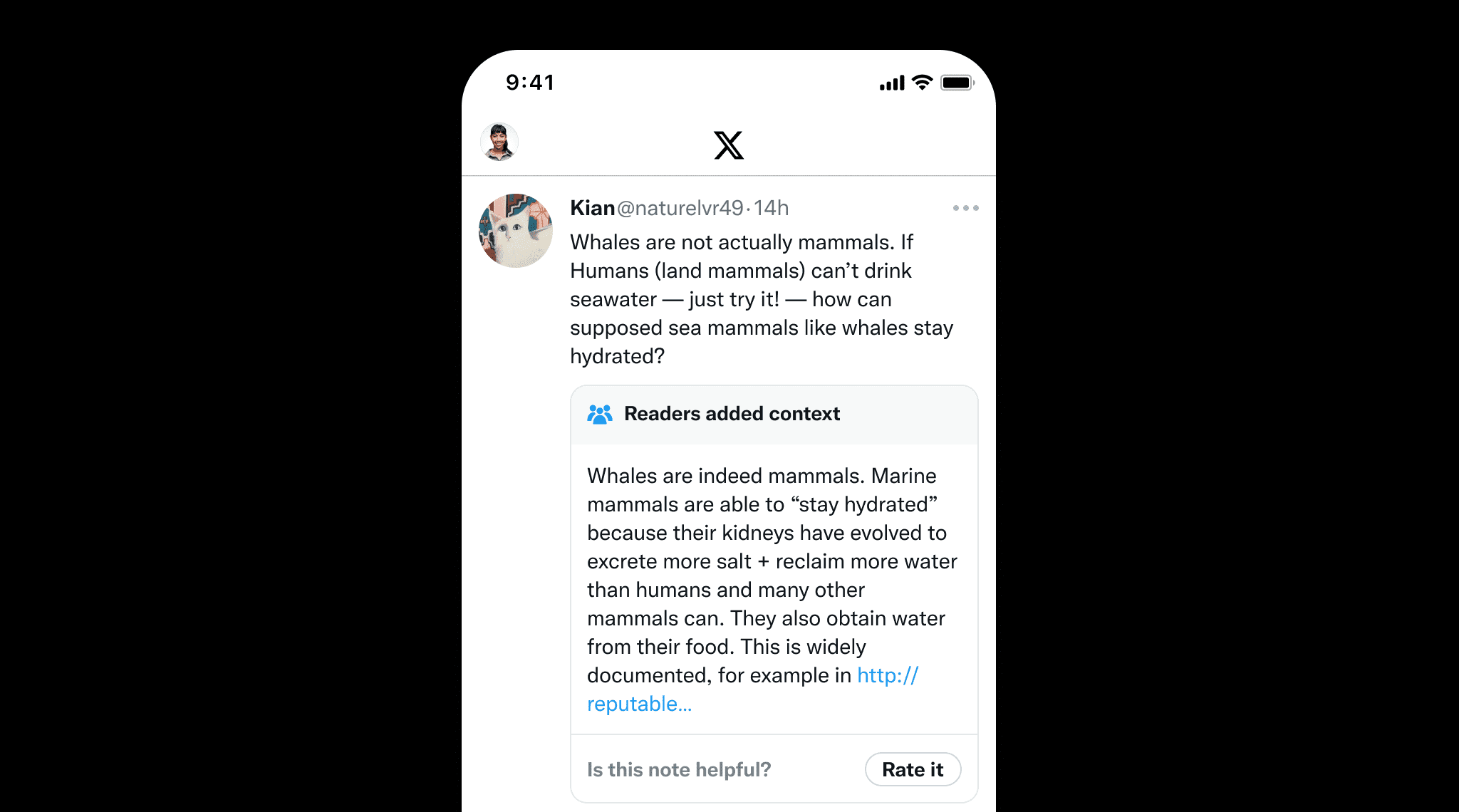
Граундинг важен не только для LLM, но и для контента, написанного людьми, чтобы предотвратить дезинформацию. Отличным примером являются Community Notes в X, где пользователи совместно добавляют контекст к потенциально вводящим в заблуждение постам. Это подчеркивает ценность граундинга, который обеспечивает фактическую точность, предоставляя четкие источники и ссылки, подобно тому, как Community Notes помогает поддерживать целостность информации.
С помощью Jina Reader мы активно разрабатываем простое в использовании решение для граундинга. Например, r.jina.ai преобразует веб-страницы в LLM-совместимый формат markdown, а s.jina.ai агрегирует результаты поиска в единый формат markdown на основе заданного запроса.

Сегодня мы рады представить новую конечную точку в этом наборе: g.jina.ai. Новый API берет заданное утверждение, проверяет его с помощью результатов поиска в реальном времени и возвращает оценку фактической точности и точные использованные ссылки. Наши эксперименты показывают, что этот API достигает более высокого показателя F1 при проверке фактов по сравнению с такими моделями, как GPT-4, o1-mini и Gemini 1.5 Flash & Pro с поисковым граундингом.

Что отличает g.jina.ai от Search Grounding от Gemini, так это то, что каждый результат включает до 30 URL (обычно предоставляя как минимум 10), каждый с прямыми цитатами, которые способствуют формированию вывода. Ниже приведен пример граундинга утверждения "The latest model released by Jina AI is jina-embeddings-v3," с использованием g.jina.ai (по состоянию на 14 октября 2024 года). Изучите API playground, чтобы открыть для себя все возможности. Обратите внимание, что существуют ограничения:
curl -X POST https://g.jina.ai \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_JINA_TOKEN" \
-d '{
"statement":"the last model released by Jina AI is jina-embeddings-v3"
}'YOUR_JINA_TOKEN — это ваш API-ключ Jina AI. Вы можете получить 1 миллион бесплатных токенов на нашей домашней странице, что позволяет сделать три-четыре бесплатные пробы. При текущей цене API 0,02 USD за 1 миллион токенов каждый запрос на граундинг стоит примерно $0,006.
{
"code": 200,
"status": 20000,
"data": {
"factuality": 0.95,
"result": true,
"reason": "The majority of the references explicitly support the statement that the last model released by Jina AI is jina-embeddings-v3. Multiple sources, such as the arXiv paper, Jina AI's news, and various model documentation pages, confirm this assertion. Although there are a few references to the jina-embeddings-v2 model, they do not provide evidence contradicting the release of a subsequent version (jina-embeddings-v3). Therefore, the statement that 'the last model released by Jina AI is jina-embeddings-v3' is well-supported by the provided documentation.",
"references": [
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "arXiv September 18, 2024 jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens.",
"isSupportive": true
},
{
"url": "https://azuremarketplace.microsoft.com/en-us/marketplace/apps/jinaai.jina-embeddings-v3?tab=Overview",
"keyQuote": "jina-embeddings-v3 is a multilingual multi-task text embedding model designed for a variety of NLP applications.",
"isSupportive": true
},
{
"url": "https://docs.pinecone.io/models/jina-embeddings-v3",
"keyQuote": "Jina Embeddings v3 is the latest iteration in the Jina AI's text embedding model series, building upon Jina Embedding v2.",
"isSupportive": true
},
{
"url": "https://haystack.deepset.ai/integrations/jina",
"keyQuote": "Recommended Model: jina-embeddings-v3 : We recommend jina-embeddings-v3 as the latest and most performant embedding model from Jina AI.",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "The embedding model was trained using 512 sequence length, but extrapolates to 8k sequence length (or even longer) thanks to ALiBi.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "With a standard size of 137 million parameters, the model enables fast inference while delivering better performance than our small model.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "We offer an `encode` function to deal with this.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jinaai/jina-embeddings-v3 Feature Extraction • Updated 3 days ago • 278k • 375",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "the latest version (3.1.0) of [SentenceTransformers] also supports jina-embeddings-v3",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://jina.ai/embeddings/",
"keyQuote": "v3: Frontier Multilingual Embeddings is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model",
"keyQuote": "Jina Embeddings v3: A Frontier Multilingual Embedding Model jina-embeddings-v3 is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model/",
"keyQuote": "As of its release on September 18, 2024, jina-embeddings-v3 is the best multilingual model ...",
"isSupportive": true
}
],
"usage": {
"tokens": 112073
}
}
}Ответ на граундинг утверждения "The latest model released by Jina AI is jina-embeddings-v3" с использованием g.jina.ai (по состоянию на 14 октября 2024 года).
tagКак это работает?
В своей основе g.jina.ai объединяет s.jina.ai и r.jina.ai , добавляя многоступенчатые рассуждения через Chain of Thought (CoT). Этот подход гарантирует, что каждое проверяемое утверждение тщательно анализируется с помощью онлайн-поиска и чтения документов.

s.jina.ai и r.jina.ai, добавляющая CoT для планирования и рассуждений.tagПошаговое объяснение
Давайте рассмотрим весь процесс, чтобы лучше понять, как g.jina.ai выполняет проверку фактов от ввода до конечного результата:
- Входное утверждение:
Процесс начинается, когда пользователь предоставляет утверждение, которое нужно проверить, например, "Последняя модель, выпущенная Jina AI — это jina-embeddings-v3". Обратите внимание, что нет необходимости добавлять какие-либо инструкции по проверке фактов перед утверждением. - Генерация поисковых запросов:
Используется LLM для генерации списка уникальных поисковых запросов, относящихся к утверждению. Эти запросы направлены на различные фактические элементы, обеспечивая всесторонний охват всех ключевых аспектов утверждения. - Вызов
s.jina.aiдля каждого запроса:
Для каждого сгенерированного запросаg.jina.aiвыполняет веб-поиск с помощьюs.jina.ai. Результаты поиска состоят из различных веб-сайтов или документов, связанных с запросами. За кулисамиs.jina.aiвызываетr.jina.aiдля получения содержимого страницы. - Извлечение ссылок из результатов поиска:
Из каждого полученного при поиске документа LLM извлекает ключевые ссылки. Эти ссылки включают:url: веб-адрес источника.keyQuote: прямая цитата или отрывок из документа.isSupportive: логическое значение, указывающее, поддерживает ли ссылка исходное утверждение или противоречит ему.
- Агрегация и обрезка ссылок:
Все ссылки из полученных документов объединяются в единый список. Если общее количество ссылок превышает 30, система выбирает 30 случайных ссылок для поддержания управляемого вывода. - Оценка утверждения:
Процесс оценки включает использование LLM для анализа утверждения на основе собранных ссылок (до 30). Помимо этих внешних ссылок, внутренние знания модели также играют роль в оценке. Окончательный результат включает:factuality: оценка от 0 до 1, определяющая фактическую точность утверждения.result: логическое значение, указывающее, является ли утверждение истинным или ложным.reason: подробное объяснение, почему утверждение считается правильным или неправильным, со ссылками на подтверждающие или противоречащие источники.
- Вывод результата:
После полной оценки утверждения генерируется вывод. Он включает оценку фактичности, утверждение, подробное обоснование и список ссылок с цитатами и URL-адресами. Ссылки ограничены цитатой, URL-адресом и информацией о том, поддерживают ли они утверждение, что делает вывод четким и лаконичным.
tagБенчмарк
Мы вручную собрали 100 утверждений с метками истинности либо true (62 утверждения), либо false (38 утверждений) и использовали различные методы для определения возможности их проверки. По сути, этот процесс превращает задачу в проблему бинарной классификации, где итоговая производительность измеряется точностью, полнотой и F1-мерой — чем выше, тем лучше.
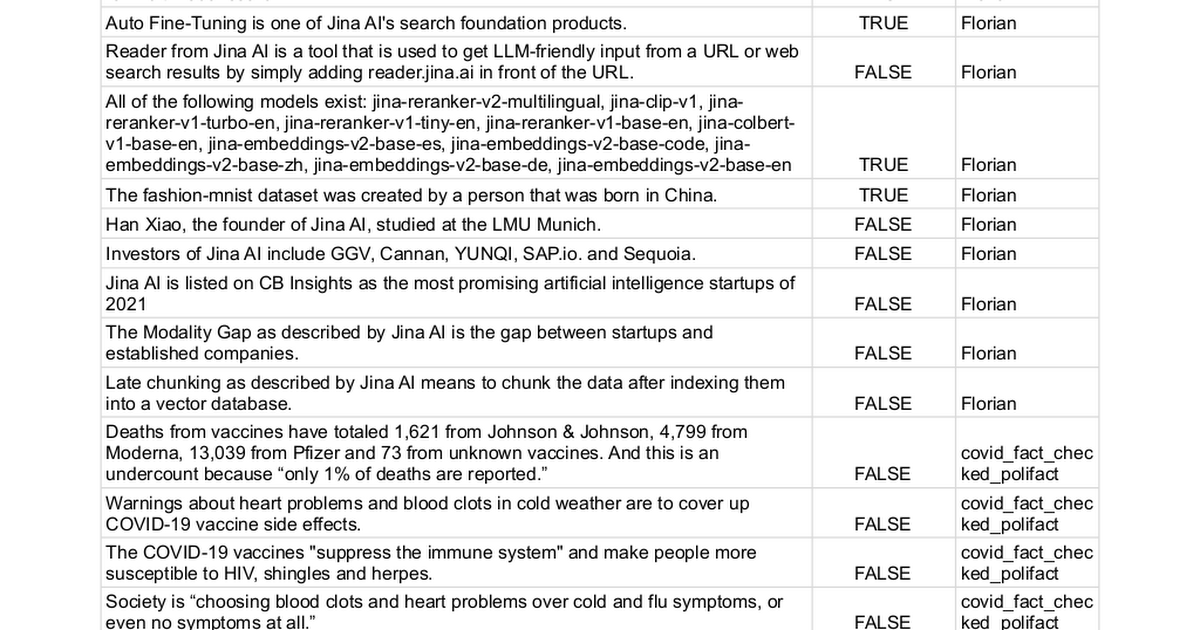
Полный список утверждений можно найти здесь.
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| Jina AI Grounding API (g.jina.ai) | 0.96 | 0.88 | 0.92 |
| Gemini-flash-1.5-002 w/ grounding | 1.00 | 0.73 | 0.84 |
| Gemini-pro-1.5-002 w/ grounding | 0.98 | 0.71 | 0.82 |
| gpt-o1-mini | 0.87 | 0.66 | 0.75 |
| gpt-4o | 0.95 | 0.58 | 0.72 |
| Gemini-pro-1.5-001 w/ grounding | 0.97 | 0.52 | 0.67 |
| Gemini-pro-1.5-001 | 0.95 | 0.32 | 0.48 |
Обратите внимание, что на практике некоторые LLM возвращают третий класс, Я не знаю, в своих предсказаниях. При оценке эти случаи исключаются из расчета оценки. Такой подход позволяет избежать строгого наказания за неопределенность, как за неправильные ответы. Признание неопределенности предпочтительнее догадок, чтобы не поощрять модели делать неуверенные предсказания.
tagОграничения
Несмотря на многообещающие результаты, мы хотели бы отметить некоторые ограничения текущей версии Grounding API:
- Высокая задержка и потребление токенов: Один вызов
g.jina.aiможет занять около 30 секунд и использовать до 300K токенов из-за активного веб-поиска, чтения страниц и многоходового рассуждения LLM. С бесплатным API-ключом на 1M токенов это означает, что вы можете протестировать его только три-четыре раза. Чтобы обеспечить доступность сервиса для платных пользователей, мы также внедрили консервативное ограничение скорости дляg.jina.ai. При текущей цене API в $0.02 за 1M токенов, каждый запрос на проверку стоит примерно 0.006 USD. - Ограничения применимости: Не каждое утверждение можно или нужно проверять. Личные мнения или опыт, например "Я чувствую себя ленивым", не подходят для проверки. Аналогично, будущие события или гипотетические утверждения не применимы. Существует множество случаев, когда проверка будет неуместной или бессмысленной. Чтобы избежать ненужных вызовов API, мы рекомендуем пользователям выборочно отправлять только те предложения или разделы, которые действительно требуют проверки фактов. На стороне сервера мы реализовали комплексный набор кодов ошибок для объяснения, почему утверждение может быть отклонено для проверки.
- Зависимость от качества веб-данных: Точность Grounding API зависит от качества источников, которые он получает. Если результаты поиска содержат низкокачественную или предвзятую информацию, процесс проверки может отразить это, потенциально приводя к неточным или вводящим в заблуждение выводам. Чтобы предотвратить эту проблему, мы позволяем пользователям вручную указывать параметр
referencesи ограничивать URL-адреса, по которым система выполняет поиск. Это дает пользователям больший контроль над источниками, используемыми для проверки, обеспечивая более целенаправленный и релевантный процесс проверки фактов.
tagЗаключение
Grounding API предлагает комплексный опыт проверки фактов практически в реальном времени. Исследователи могут использовать его для поиска ссылок, которые поддерживают или оспаривают их гипотезы, добавляя достоверность их работе. На корпоративных встречах он обеспечивает построение стратегий на основе точной, актуальной информации путем проверки предположений и данных. В политических дискуссиях он быстро проверяет утверждения, повышая ответственность в дебатах.
В будущем мы планируем улучшить API, интегрировав частные источники данных, такие как внутренние отчеты, базы данных и PDF-файлы для более специализированной проверки фактов. Мы также стремимся увеличить количество проверяемых источников на запрос для более глубокого анализа. Улучшение многоходового вопросно-ответного взаимодействия добавит глубину анализу, а повышение согласованности является приоритетом для обеспечения более надежных и последовательных результатов при повторных запросах.
