



Разработчики и инженеры по эксплуатации высоко ценят инфраструктуру, которую можно легко настроить, быстро запустить и впоследствии эффективно развернуть в масштабируемой производственной среде без дополнительных сложностей. По этой причине Milvus Lite, новейшая облегченная векторная база данных от нашего партнера Milvus, является важным инструментом для Python-разработчиков для быстрой разработки поисковых приложений, особенно при использовании вместе с качественными и простыми в использовании базовыми моделями поиска.
В этой статье мы расскажем, как Milvus Lite интегрирует Jina Embeddings v2 и Jina Reranker v1 на примере приложения Retrieval Augmented Generation (RAG), построенного на основе чатов внутреннего публичного канала вымышленной компании, чтобы сотрудники могли получать точные и полезные ответы на вопросы, связанные с организацией.
tagОбзор Milvus Lite, Jina Embeddings и Jina Reranker
Milvus Lite — это новая облегченная версия ведущей векторной базы данных Milvus, которая теперь также предлагается как Python-библиотека. Milvus Lite использует тот же API, что и Milvus, развернутый на Docker или Kubernetes, но может быть легко установлен с помощью одной команды pip без настройки сервера.
С интеграцией Jina Embeddings v2 и Jina Reranker v1 в pymilvus, Python SDK Milvus, теперь у вас есть возможность напрямую встраивать документы, используя один и тот же Python-клиент для любого режима развертывания Milvus, включая Milvus Lite. Подробности интеграции Jina Embeddings и Reranker вы можете найти на страницах документации pymilvus.
Благодаря контекстному окну в 8 тысяч токенов и многоязычным возможностям, Jina Embeddings v2 кодирует широкую семантику текста и обеспечивает точный поиск. Добавляя Jina Reranker v1 в конвейер, вы можете дополнительно уточнить результаты, выполняя кросс-кодирование полученных результатов непосредственно с запросом для более глубокого понимания контекста.
tagMilvus и модели Jina AI в действии
Этот учебник сфокусируется на практическом примере: запросах к истории чатов компании в Slack для ответов на широкий спектр вопросов на основе прошлых разговоров.
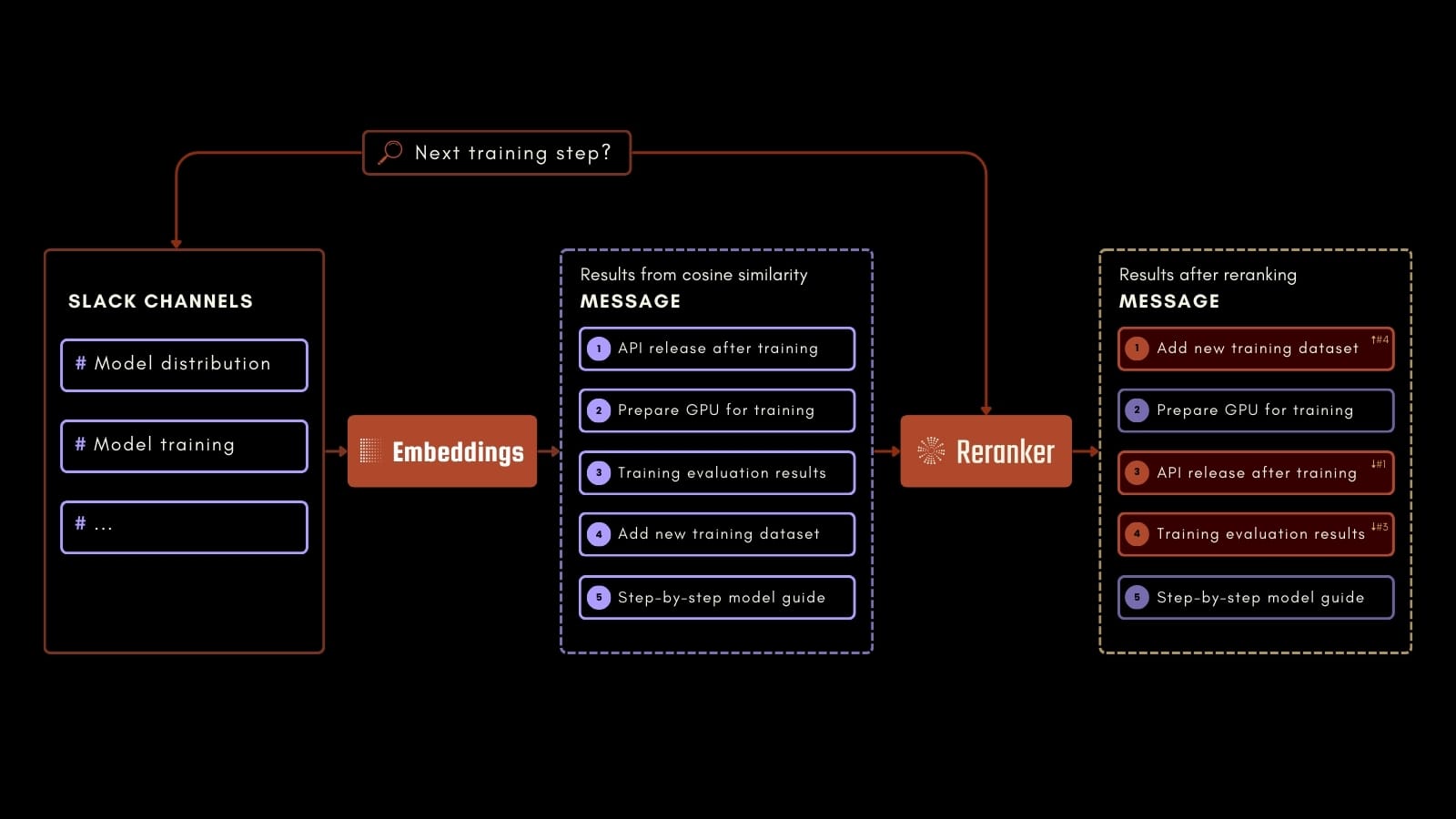
Например, сотрудник может спросить о следующем шаге в процессе обучения ИИ, как показано на схеме процесса выше. Используя Jina Embeddings, Jina Reranker и Milvus, мы можем точно определить релевантную информацию в сохраненных сообщениях Slack. Это приложение может повысить производительность на рабочем месте, облегчая доступ к ценной информации из прошлых коммуникаций.
Для генерации ответов мы будем использовать Mixtral 7B Instruct через интеграцию HuggingFace в Langchain. Для использования модели вам нужен токен доступа HuggingFace, который вы можете сгенерировать, как описано здесь.
Вы можете следовать примеру в Colab или скачав ноутбук.


tagО наборе данных
Набор данных, используемый в этом учебнике, был сгенерирован с помощью GPT-4 и предназначен для воспроизведения истории чатов каналов Slack компании Blueprint AI. Blueprint — это вымышленный AI-стартап, разрабатывающий собственные фундаментальные модели. Вы можете скачать набор данных здесь.
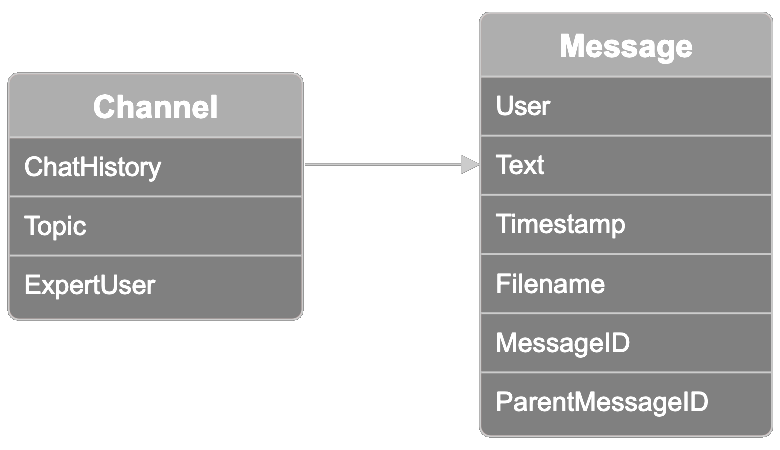
Данные организованы по каналам, каждый из которых представляет собой коллекцию связанных тем Slack. Каждый канал имеет тематическую метку, одну из десяти опций: распространение модели, обучение модели, тонкая настройка модели, этика и снижение предвзятости, обратная связь от пользователей, продажи, маркетинг, внедрение модели, креативный дизайн и управление продуктом. Один участник известен как "эксперт". Вы можете использовать это поле для проверки результатов поиска самого опытного пользователя по теме, что мы покажем ниже.
Каждый канал также содержит историю чата с ветками разговоров до 100 сообщений на канал. Каждое сообщение в наборе данных содержит следующую информацию:
- Пользователь, отправивший сообщение
- Текст сообщения, отправленный пользователем
- Временная метка сообщения
- Имя файла, который пользователь мог прикрепить к сообщению
- ID сообщения
- ID родительского сообщения, если сообщение было в ветке, начатой с другого сообщения
tagНастройка окружения
Для начала установите все необходимые компоненты:
pip install -U pymilvus
pip install -U "pymilvus[model]"
pip install langchain
pip install langchain-community
Скачайте набор данных:
import os
if not os.path.exists("chat_history.json"):
!wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/embeddings/milvus/chat_history.jsonУстановите ваш API-ключ Jina AI в переменную окружения. Вы можете сгенерировать его здесь.
import os
import getpass
os.environ["JINAAI_API_KEY"] = getpass.getpass(prompt="Jina AI API Key: ")Сделайте то же самое для вашего токена Hugging Face. Вы можете узнать, как его сгенерировать, здесь. Убедитесь, что он установлен на READ для доступа к Hugging Face Hub.
os.environ["HUGGINGFACEHUB_API_TOKEN"] = getpass.getpass(prompt="Hugging Face Token: ")tagСоздание коллекции Milvus
Создайте коллекцию Milvus для индексации данных:
from pymilvus import MilvusClient, DataType
# Specify a local file name as uri parameter of MilvusClient to use Milvus Lite
client = MilvusClient("milvus_jina.db")
schema = MilvusClient.create_schema(
auto_id=True,
enable_dynamic_field=True,
)
schema.add_field(field_name="id", datatype=DataType.INT64, description="The Primary Key", is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, description="The Embedding Vector", dim=768)
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")
client.create_collection(collection_name="milvus_jina", schema=schema, index_params=index_params)tagПодготовка данных
Парсинг истории чата и извлечение метаданных:
import json
with open("chat_history.json", "r", encoding="utf-8") as file:
chat_data = json.load(file)
messages = []
metadatas = []
for channel in chat_data:
chat_history = channel["chat_history"]
chat_topic = channel["topic"]
chat_expert = channel["expert_user"]
for message in chat_history:
text = f"""{message["user"]}: {message["message"]}"""
messages.append(text)
meta = {
"time_stamp": message["time_stamp"],
"file_name": message["file_name"],
"parent_message_nr": message["parent_message_nr"],
"channel": chat_topic,
"expert": True if message["user"] == chat_expert else False
}
metadatas.append(meta)
tagВнедрение данных чата
Создание эмбеддингов для каждого сообщения с помощью Jina Embeddings v2 для получения релевантной информации из чата:
from pymilvus.model.dense import JinaEmbeddingFunction
jina_ef = JinaEmbeddingFunction("jina-embeddings-v2-base-en")
embeddings = jina_ef.encode_documents(messages)tagИндексация данных чата
Индексация сообщений, их эмбеддингов и соответствующих метаданных:
collection_data = [{
"message": message,
"embedding": embedding,
"metadata": metadata
} for message, embedding, metadata in zip(messages, embeddings, metadatas)]
data = client.insert(
collection_name="milvus_jina",
data=collection_data
)tagЗапрос к истории чата
Время задать вопрос:
query = "Who knows the most about encryption protocols in my team?"Теперь создадим эмбеддинг запроса и получим релевантные сообщения. Здесь мы получаем пять наиболее релевантных сообщений и делаем их переранжирование с помощью Jina Reranker v1:
from pymilvus.model.reranker import JinaRerankFunction
query_vectors = jina_ef.encode_queries([query])
results = client.search(
collection_name="milvus_jina",
data=query_vectors,
limit=5,
)
results = results[0]
ids = [results[i]["id"] for i in range(len(results))]
results = client.get(
collection_name="milvus_jina",
ids=ids,
output_fields=["id", "message", "metadata"]
)
jina_rf = JinaRerankFunction("jina-reranker-v1-base-en")
documents = [results[i]["message"] for i in range(len(results))]
reranked_documents = jina_rf(query, documents)
reranked_messages = []
for reranked_document in reranked_documents:
idx = reranked_document.index
reranked_messages.append(results[idx])Наконец, сгенерируем ответ на запрос с помощью Mixtral 7B Instruct, используя переранжированные сообщения в качестве контекста:
from langchain.prompts import PromptTemplate
from langchain_community.llms import HuggingFaceEndpoint
llm = HuggingFaceEndpoint(repo_id="mistralai/Mixtral-8x7B-Instruct-v0.1")
prompt = """<s>[INST] Context information is below.\\n
It includes the five most relevant messages to the query, sorted based on their relevance to the query.\\n
---------------------\\n
{context_str}\\\\n
---------------------\\n
Given the context information and not prior knowledge,
answer the query. Please be brief, concise, and complete.\\n
If the context information does not contain an answer to the query,
respond with \\"No information\\".\\n
Query: {query_str}[/INST] </s>"""
prompt = PromptTemplate(template=prompt, input_variables=["query_str", "context_str"])
llm_chain = prompt | llm
answer = llm_chain.invoke({"query_str":query, "context_str":reranked_messages})
print(f"\n\nANSWER:\n\n{answer}")Ответ на наш вопрос:
"На основе контекстной информации, User5 кажется наиболее осведомленным о протоколах шифрования в вашей команде. Они упоминали, что новые протоколы значительно повышают безопасность данных, особенно для облачных развертываний."
Если вы просмотрите сообщения в chat_history.json, вы сможете сами проверить, является ли User5 самым экспертным пользователем.
tagИтоги
Мы рассмотрели, как настроить Milvus Lite, внедрить данные чата с помощью Jina Embeddings v2 и улучшить результаты поиска с помощью Jina Reranker v1 на практическом примере поиска в истории чата Slack. Milvus Lite упрощает разработку приложений на Python без необходимости сложных серверных настроек. Его интеграция с Jina Embeddings и Reranker направлена на повышение продуктивности, облегчая доступ к ценной информации на рабочем месте.
tagИспользуйте модели Jina AI и Milvus прямо сейчас
Milvus Lite с интегрированными Jina Embeddings и Reranker предоставляет вам полный конвейер обработки, готовый к использованию всего в несколько строк кода.
Мы будем рады узнать о ваших вариантах использования и обсудить, как расширение Jina AI Milvus может соответствовать потребностям вашего бизнеса. Свяжитесь с нами через наш веб-сайт или наш канал Discord, чтобы поделиться отзывами и быть в курсе наших последних моделей. По вопросам интеграции Milvus и Jina AI присоединяйтесь к сообществу Milvus.
