

Классификация - это распространенная задача для эмбеддингов. Текстовые эмбеддинги могут категоризировать текст по предопределенным меткам для обнаружения спама или анализа тональности. Мультимодальные эмбеддинги, такие как jina-clip-v1, могут применяться для фильтрации контента или аннотации тегов. Недавно классификация также нашла применение в маршрутизации запросов к соответствующим LLM на основе сложности и стоимости, например, простые арифметические запросы могут быть направлены к небольшой языковой модели. Сложные задачи рассуждения могут быть направлены к более мощным, но более дорогим LLM.
Сегодня мы представляем новый Classifier API от Jina AI's Search Foundation. Поддерживая классификацию zero-shot и few-shot в режиме онлайн, он построен на наших последних моделях эмбеддингов, таких как jina-embeddings-v3 и jina-clip-v1. Classifier API основан на онлайн пассивно-агрессивном обучении, позволяющем адаптироваться к новым данным в реальном времени. Пользователи могут начать с zero-shot классификатора и использовать его немедленно. Затем они могут постепенно обновлять классификатор, отправляя новые примеры или когда происходит концептуальный сдвиг. Это обеспечивает эффективную, масштабируемую классификацию различных типов контента без обширных начальных размеченных данных. Пользователи также могут публиковать свои классификаторы для общего пользования. Когда выходят наши новые эмбеддинги, такие как предстоящий мультиязычный jina-clip-v2, пользователи могут немедленно получить к ним доступ через Classifier API, обеспечивая актуальные возможности классификации.

tagZero-Shot Классификация
Classifier API предлагает мощные возможности zero-shot классификации, позволяющие категоризировать текст или изображения без предварительного обучения на размеченных данных. Каждый классификатор начинается с возможностей zero-shot, которые позже могут быть улучшены дополнительными тренировочными данными или обновлениями - тема, которую мы рассмотрим в следующем разделе.
tagПример 1: Маршрутизация LLM Запросов
Вот пример использования classifier API для маршрутизации LLM запросов:
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-embeddings-v3",
"labels": [
"Simple task",
"Complex reasoning",
"Creative writing"
],
"input": [
"Calculate the compound interest on a principal of $10,000 invested for 5 years at an annual rate of 5%, compounded quarterly.",
"分析使用CRISPR基因编辑技术在人类胚胎中的伦理影响。考虑潜在的医疗益处和长期社会后果。",
"AIが自意識を持つディストピアの未来を舞台にした短編小説を書いてください。人間とAIの関係や意識の本質をテーマに探求してください。",
"Erklären Sie die Unterschiede zwischen Merge-Sort und Quicksort-Algorithmen in Bezug auf Zeitkomplexität, Platzkomplexität und Leistung in der Praxis.",
"Write a poem about the beauty of nature and its healing power on the human soul.",
"Translate the following sentence into French: The quick brown fox jumps over the lazy dog."
]
}'Этот пример демонстрирует использование jina-embeddings-v3 для маршрутизации пользовательских запросов на нескольких языках (английском, китайском, японском и немецком) по трем категориям, которые соответствуют трем разным размерам LLM. Формат ответа API следующий:
{
"usage": {"total_tokens": 256, "prompt_tokens": 256},
"data": [
{"object": "classification", "index": 0, "prediction": "Simple task", "score": 0.35216382145881653},
{"object": "classification", "index": 1, "prediction": "Complex reasoning", "score": 0.34310275316238403},
{"object": "classification", "index": 2, "prediction": "Creative writing", "score": 0.3487184941768646},
{"object": "classification", "index": 3, "prediction": "Complex reasoning", "score": 0.35207709670066833},
{"object": "classification", "index": 4, "prediction": "Creative writing", "score": 0.3638903796672821},
{"object": "classification", "index": 5, "prediction": "Simple task", "score": 0.3561534285545349}
]
}Ответ включает:
usage: Информация об использовании токенов.data: Массив результатов классификации, по одному для каждого входа.- Каждый результат содержит предсказанную метку (
prediction) и оценку уверенности (score).scoreдля каждого класса вычисляется через softmax нормализацию - для zero-shot он основан на косинусном сходстве между входными эмбеддингами и эмбеддингами меток под task-LoRAclassification; в то время как для few-shot он основан на изученных линейных преобразованиях входного эмбеддинга для каждого класса - в результате получаются вероятности, сумма которых равна 1 по всем классам. indexсоответствует позиции входа в исходном запросе.
- Каждый результат содержит предсказанную метку (
tagПример 2: Категоризация Изображений и Текста
Давайте рассмотрим мультимодальный пример с использованием jina-clip-v1. Эта модель может классифицировать как текст, так и изображения, что делает ее идеальной для категоризации контента различных типов медиа. Рассмотрим следующий API-вызов:
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-clip-v1",
"labels": [
"Food and Dining",
"Technology and Gadgets",
"Nature and Outdoors",
"Urban and Architecture"
],
"input": [
{"text": "A sleek smartphone with a high-resolution display and multiple camera lenses"},
{"text": "Fresh sushi rolls served on a wooden board with wasabi and ginger"},
{"image": "https://picsum.photos/id/11/367/267"},
{"image": "https://picsum.photos/id/22/367/267"},
{"text": "Vibrant autumn leaves in a dense forest with sunlight filtering through"},
{"image": "https://picsum.photos/id/8/367/267"}
]
}'Обратите внимание, как мы загружаем изображения в запросе, вы также можете использовать строку base64 для представления изображения. API возвращает следующие результаты классификации:
{
"usage": {"total_tokens": 12125, "prompt_tokens": 12125},
"data": [
{"object": "classification", "index": 0, "prediction": "Technology and Gadgets", "score": 0.30329811573028564},
{"object": "classification", "index": 1, "prediction": "Food and Dining", "score": 0.2765541970729828},
{"object": "classification", "index": 2, "prediction": "Nature and Outdoors", "score": 0.29503118991851807},
{"object": "classification", "index": 3, "prediction": "Urban and Architecture", "score": 0.2648046910762787},
{"object": "classification", "index": 4, "prediction": "Nature and Outdoors", "score": 0.3133063316345215},
{"object": "classification", "index": 5, "prediction": "Technology and Gadgets", "score": 0.27474141120910645}
]
}tagПример 3: Определение Подлинности Контента в Jina Reader
Интересное применение zero-shot классификации - определение доступности веб-сайта через Jina Reader. Хотя это может показаться простой задачей, на практике она удивительно сложна. Заблокированные сообщения сильно различаются от сайта к сайту, появляясь на разных языках и указывая различные причины (платный доступ, ограничения частоты, сбои сервера). Это разнообразие делает сложным полагаться на regex или фиксированные правила для охвата всех сценариев.
import requests
import json
response1 = requests.get('https://r.jina.ai/https://jina.ai')
url = 'https://api.jina.ai/v1/classify'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer $YOUR_API_KEY_HERE'
}
data = {
'model': 'jina-embeddings-v3',
'labels': ['Blocked', 'Accessible'],
'input': [{'text': response1.text[:8000]}]
}
response2 = requests.post(url, headers=headers, data=json.dumps(data))
print(response2.text)Скрипт получает контент через r.jina.ai и классифицирует его как "Blocked" или "Accessible" используя Classifier API. Например, https://r.jina.ai/https://www.crunchbase.com/organization/jina-ai вероятно будет "Blocked" из-за ограничений доступа, в то время как https://r.jina.ai/https://jina.ai должен быть "Accessible".
{"usage":{"total_tokens":185,"prompt_tokens":185},"data":[{"object":"classification","index":0,"prediction":"Blocked","score":0.5392698049545288}]}Classifier API может эффективно различать подлинный контент и заблокированные результаты от Jina Reader.
Этот пример использует jina-embeddings-v3 и предлагает быстрый, автоматизированный способ мониторинга доступности веб-сайтов, полезный для систем агрегации контента или веб-скрапинга, особенно в многоязычных условиях.
tagПример 4: Фильтрация Утверждений от Мнений для Обоснования
Еще одно интересное применение классификации с нулевым обучением — фильтрация утверждений, похожих на факты, от мнений в длинных документах. Обратите внимание, что классификатор сам по себе не может определить, является ли что-то фактически верным. Вместо этого он идентифицирует текст, который написан в стиле фактического утверждения, которое затем можно проверить через API проверки достоверности, что часто довольно затратно. Этот двухэтапный процесс является ключом к эффективной проверке фактов: сначала отфильтровываются все мнения и чувства, затем оставшиеся утверждения отправляются на проверку.
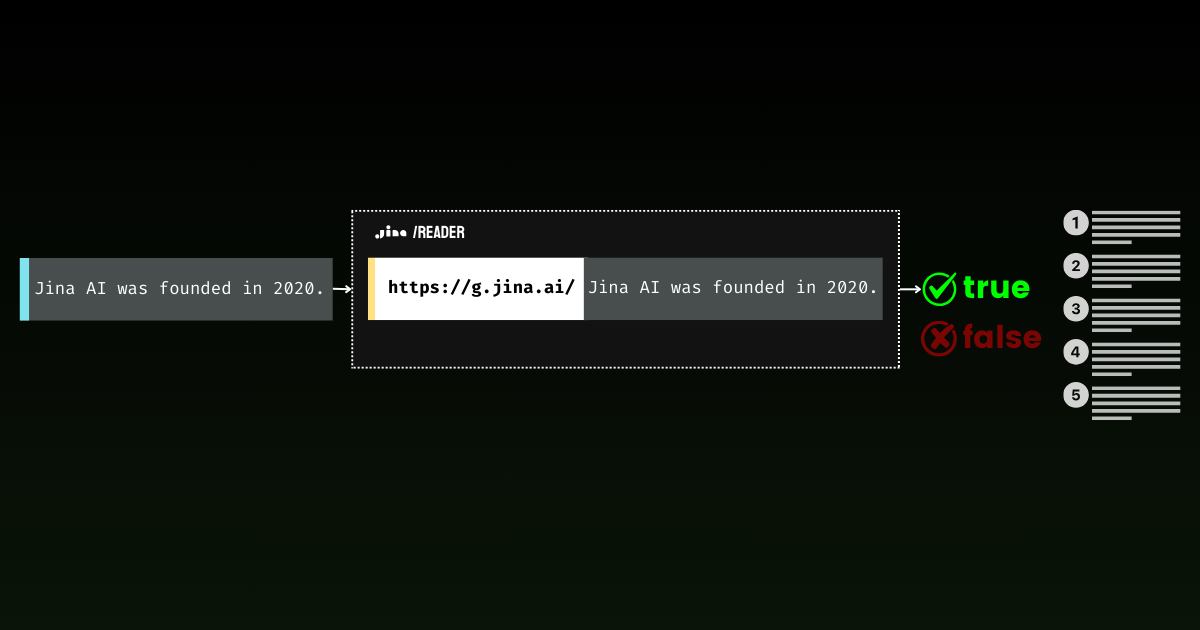
Рассмотрим этот абзац о Космической гонке 1960-х годов:
The Space Race of the 1960s was a breathtaking testament to human ingenuity. When the Soviet Union launched Sputnik 1 on October 4, 1957, it sent shockwaves through American society, marking the undeniable start of a new era. The silvery beeping of that simple satellite struck fear into the hearts of millions, as if the very stars had betrayed Western dominance. NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973. While some cynics claimed this was a waste of resources, the technological breakthroughs were absolutely worth every penny spent. On July 20, 1969, Neil Armstrong and Buzz Aldrin achieved the most magnificent triumph in human history by walking on the moon, their footprints marking humanity's destiny among the stars. The Soviet space program, despite its early victories, ultimately couldn't match the superior American engineering and determination. The moon landing was not just a victory for America - it represented the most inspiring moment in human civilization, proving that our species was meant to reach beyond our earthly cradle.
Этот текст намеренно смешивает различные типы письма — от утверждений, похожих на факты (например, "Спутник-1 был запущен 4 октября 1959 года"), до явных мнений ("впечатляющее свидетельство"), эмоционального языка ("вселил страх в сердца"), и интерпретативных утверждений ("обозначив несомненное начало новой эры").
Задача классификатора с нулевым обучением чисто семантическая — он определяет, написан ли фрагмент текста как утверждение или как мнение/интерпретация. Например, "The Soviet Union launched Sputnik 1 on October 4, 1959" написано как утверждение, в то время как "The Space Race was a breathtaking testament" явно написано как мнение.
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
# Step 1: Split text and classify
chunks = [chunk.strip() for chunk in text.split('.') if chunk.strip()]
labels = [
"subjective, opinion, feeling, personal experience, creative writing, position",
"fact"
]
# Classify chunks
classify_response = requests.post(
'https://api.jina.ai/v1/classify',
headers=headers,
json={
"model": "jina-embeddings-v3",
"input": [{"text": chunk} for chunk in chunks],
"labels": labels
}
)
# Sort chunks
subjective_chunks = []
factual_chunks = []
for chunk, classification in zip(chunks, classify_response.json()['data']):
if classification['prediction'] == labels[0]:
subjective_chunks.append(chunk)
else:
factual_chunks.append(chunk)
print("\nSubjective statements:", subjective_chunks)
print("\nFactual statements:", factual_chunks)И вы получите:
Subjective statements: ['The Space Race of the 1960s was a breathtaking testament to human ingenuity', 'The silvery beeping of that simple satellite struck fear into the hearts of millions, as if the very stars had betrayed Western dominance', 'While some cynics claimed this was a waste of resources, the technological breakthroughs were absolutely worth every penny spent', "The Soviet space program, despite its early victories, ultimately couldn't match the superior American engineering and determination"]
Factual statements: ['When the Soviet Union launched Sputnik 1 on October 4, 1957, it sent shockwaves through American society, marking the undeniable start of a new era', "NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973", "On July 20, 1969, Neil Armstrong and Buzz Aldrin achieved the most magnificent triumph in human history by walking on the moon, their footprints marking humanity's destiny among the stars", 'The moon landing was not just a victory for America - it represented the most inspiring moment in human civilization, proving that our species was meant to reach beyond our earthly cradle']Помните, то, что что-то написано как утверждение, не означает, что это правда. Поэтому нам нужен второй шаг — отправка этих утверждений в API проверки достоверности для фактической проверки. Например, давайте проверим это утверждение: "NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973" с помощью кода ниже.
ground_headers = {
'Accept': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
ground_response = requests.get(
f'https://g.jina.ai/{quote(factual_chunks[1])}',
headers=ground_headers
)
print(ground_response.json())который даст вам:
{'code': 200, 'status': 20000, 'data': {'factuality': 1, 'result': True, 'reason': "The statement is supported by multiple references confirming NASA's founding in 1958 and the significant financial investment in the Apollo program. The $28 billion figure aligns with the data provided in the references, which detail NASA's expenditures during the Apollo program from 1960 to 1973. Additionally, the context of NASA's budget peaking during this period further substantiates the claim. Therefore, the statement is factually correct based on the available evidence.", 'references': [{'url': 'https://en.wikipedia.org/wiki/Budget_of_NASA', 'keyQuote': "NASA's budget peaked in 1964–66 when it consumed roughly 4% of all federal spending. The agency was building up to the first Moon landing and the Apollo program was a top national priority, consuming more than half of NASA's budget.", 'isSupportive': True}, {'url': 'https://en.wikipedia.org/wiki/NASA', 'keyQuote': 'Established in 1958, it succeeded the National Advisory Committee for Aeronautics (NACA)', 'isSupportive': True}, {'url': 'https://nssdc.gsfc.nasa.gov/planetary/lunar/apollo.html', 'keyQuote': 'More details on Apollo lunar landings', 'isSupportive': True}, {'url': 'https://usafacts.org/articles/50-years-after-apollo-11-moon-landing-heres-look-nasas-budget-throughout-its-history/', 'keyQuote': 'NASA has spent its money so far.', 'isSupportive': True}, {'url': 'https://www.nasa.gov/history/', 'keyQuote': 'Discover the history of our human spaceflight, science, technology, and aeronautics programs.', 'isSupportive': True}, {'url': 'https://www.nasa.gov/the-apollo-program/', 'keyQuote': 'Commander for Apollo 11, first to step on the lunar surface.', 'isSupportive': True}, {'url': 'https://www.planetary.org/space-policy/cost-of-apollo', 'keyQuote': 'A rich data set tracking the costs of Project Apollo, free for public use. Includes unprecedented program-by-program cost breakdowns.', 'isSupportive': True}, {'url': 'https://www.statista.com/statistics/1342862/nasa-budget-project-apollo-costs/', 'keyQuote': 'NASA's monetary obligations compared to Project Apollo's total costs from 1960 to 1973 (in million U.S. dollars)', 'isSupportive': True}], 'usage': {'tokens': 10640}}}С оценкой достоверности 1, API проверки подтверждает, что это утверждение хорошо обосновано историческими фактами. Этот подход открывает захватывающие возможности, от анализа исторических документов до проверки фактов в новостных статьях в реальном времени. Объединяя классификацию с нулевым обучением с проверкой фактов, мы создаем мощный конвейер для автоматизированного анализа информации — сначала отфильтровывая мнения, затем проверяя оставшиеся утверждения с помощью надежных источников.
tagЗамечания о классификации с нулевым обучением
Использование семантических меток
При работе с классификацией с нулевым обучением крайне важно использовать семантически значимые метки, а не абстрактные символы или числа. Например, "Technology", "Nature" и "Food" гораздо эффективнее, чем "Class1", "Class2", "Class3" или "0", "1", "2". "Positive sentiment" эффективнее, чем "Positive" и "True". Модели встраивания понимают семантические отношения, поэтому описательные метки позволяют модели использовать свои предварительно обученные знания для более точной классификации. Наш предыдущий пост исследует, как создавать эффективные семантические метки для лучших результатов классификации.

Безсостояние
Классификация с нулевым обучением фундаментально безсостоятельна, в отличие от традиционных подходов машинного обучения. Это означает, что при одинаковых входных данных и модели результаты всегда будут согласованными, независимо от того, кто использует API и когда. Модель не учится и не обновляется на основе выполняемых классификаций; каждая задача независима. Это позволяет немедленно использовать без настройки или обучения и предлагает гибкость в изменении категорий между вызовами API.
Эта безсостоятельность резко контрастирует с подходами малого количества обучающих примеров и онлайн-обучения, которые мы рассмотрим далее. В этих методах модели могут адаптироваться к новым примерам, потенциально давая разные результаты с течением времени или между пользователями.
tagКлассификация с малым количеством обучающих примеров
Классификация с малым количеством обучающих примеров предлагает простой подход к созданию и обновлению классификаторов с минимальным количеством размеченных данных. Этот метод предоставляет две основные конечные точки: train и classify.
Конечная точка train позволяет создавать или обновлять классификатор с небольшим набором примеров. Ваш первый вызов train вернетclassifier_id, который вы можете использовать для последующего обучения, когда у вас появляются новые данные, замечаются изменения в распределении данных или необходимо добавить новые классы. Этот гибкий подход позволяет вашему классификатору развиваться со временем, адаптируясь к новым паттернам и категориям без необходимости начинать с нуля.
Аналогично zero-shot классификации, вы будете использовать конечную точку classify для выполнения предсказаний. Основное отличие в том, что вам нужно будет включить ваш classifier_id в запрос, но не нужно предоставлять варианты меток, так как они уже являются частью вашей обученной модели.
tagПример: Обучение классификатора тикетов поддержки
Давайте рассмотрим эти возможности на примере классификации тикетов службы поддержки для распределения между разными командами в быстрорастущем технологическом стартапе.
Начальное обучение
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-embeddings-v3",
"access": "private",
"input": [
{
"text": "I cant log into my account after the latest app update.",
"label": "team1"
},
{
"text": "My subscription renewal failed due to an expired credit card.",
"label": "team2"
},
{
"text": "How do I export my data from the platform?",
"label": "team3"
}
],
"num_iters": 10
}'Обратите внимание, что в few-shot обучении мы можем свободно использовать team1 team2 в качестве меток классов, даже если они не имеют внутреннего семантического значения. В ответе вы получите classifier_id, который представляет этот новый классификатор.
{
"classifier_id": "918c0846-d6ae-4f34-810d-c0c7a59aee14",
"num_samples": 3,
}
Запишите classifier_id, он понадобится вам для обращения к этому классификатору позже.
Обновление классификатора для адаптации к реструктуризации команды
По мере роста компании возникают новые типы проблем, и структура команды также меняется. Красота few-shot классификации заключается в её способности быстро адаптироваться к этим изменениям. Мы можем легко обновить классификатор, указав classifier_id и новые примеры, вводя новые категории команд (например, team4) или переназначая существующие типы проблем разным командам по мере развития организации.
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "Im getting a 404 error when trying to access the new AI chatbot feature.",
"label": "team4"
},
{
"text": "The latest security patch is conflicting with my company firewall.",
"label": "team1"
},
{
"text": "I need help setting up SSO for my organization account.",
"label": "team5"
}
],
"num_iters": 10
}'Использование обученного классификатора
При выполнении предсказаний вам нужно только предоставить входной текст и classifier_id. API обрабатывает сопоставление между вашим входом и ранее обученными классами, возвращая наиболее подходящую метку на основе текущего состояния классификатора.
curl -X 'POST' \
'https://api.jina.ai/v1/classify' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "The new feature is causing my dashboard to load slowly."
},
{
"text": "I need to update my billing information for tax purposes."
}
]
}'Few-shot режим имеет два уникальных параметра.
tagПараметр num_iters
Параметр num_iters настраивает, насколько интенсивно классификатор учится на ваших обучающих примерах. Хотя значение по умолчанию 10 хорошо работает в большинстве случаев, вы можете стратегически настраивать это значение в зависимости от вашей уверенности в обучающих данных. Для высококачественных примеров, которые критически важны для классификации, увеличьте num_iters, чтобы усилить их важность. И наоборот, для менее надежных примеров уменьшите num_iters, чтобы минимизировать их влияние на производительность классификатора. Этот параметр также может использоваться для реализации обучения с учетом времени, где более новые примеры получают большее количество итераций для адаптации к развивающимся паттернам при сохранении исторических знаний.
tagПараметр access
Параметр access позволяет контролировать, кто может использовать ваш классификатор. По умолчанию классификаторы являются приватными и доступны только вам. Установка доступа как "public" позволяет любому с вашим classifier_id использовать его с их собственным API ключом и квотой токенов. Это позволяет делиться классификаторами при сохранении конфиденциальности - пользователи не могут видеть ваши обучающие данные или конфигурацию, а вы не можете видеть их запросы на классификацию. Этот параметр актуален только для few-shot классификации, так как zero-shot классификаторы не имеют состояния. Нет необходимости делиться zero-shot классификаторами, поскольку идентичные запросы всегда будут давать одинаковые ответы независимо от того, кто их делает.
tagЗамечания о Few-Shot обучении
Few-shot классификация в нашем API имеет некоторые уникальные характеристики, которые стоит отметить. В отличие от традиционных моделей машинного обучения, наша реализация использует однопроходное онлайн-обучение - обучающие примеры обрабатываются для обновления весов классификатора, но не сохраняются после этого. Это означает, что вы не можете получить исторические обучающие данные, но это обеспечивает лучшую конфиденциальность и эффективность использования ресурсов.
Хотя few-shot обучение является мощным, ему требуется период прогрева, чтобы превзойти zero-shot классификацию. Наши тесты показывают, что 200-400 обучающих примеров обычно предоставляют достаточно данных для достижения превосходной производительности. Однако вам не нужно предоставлять примеры для всех классов сразу - классификатор может масштабироваться для размещения новых классов со временем. Просто имейте в виду, что вновь добавленные классы могут испытывать короткий период холодного старта или дисбаланса классов, пока не будет предоставлено достаточное количество примеров.
tagТестирование производительности
Для нашего анализа эффективности мы оценили zero-shot и few-shot подходы на различных наборах данных, включая задачи классификации текста, такие как определение эмоций (6 классов) и обнаружение спама (2 класса), а также задачи классификации изображений, такие как CIFAR10 (10 классов). Система оценки использовала стандартное разделение на обучающую и тестовую выборки, при этом zero-shot не требовал обучающих данных, а few-shot использовал части обучающего набора. Мы отслеживали ключевые метрики, такие как размер обучающей выборки и количество целевых классов, что позволило провести контролируемые сравнения. Для обеспечения надежности, особенно для few-shot обучения, каждый ввод проходил через несколько итераций обучения. Мы сравнили эти современные подходы с традиционными базовыми методами, такими как линейный SVM и RBF SVM, чтобы обеспечить контекст для их производительности.



Показаны F1-оценки. Для полных настроек тестирования, пожалуйста, посмотрите эту таблицу Google.
Графики F1 показывают интересные закономерности для трех задач. Неудивительно, что классификация с нулевым обучением демонстрирует постоянную производительность с самого начала, независимо от размера обучающих данных. Напротив, малоразмерное обучение показывает быструю кривую обучения, изначально начинаясь ниже, но быстро превосходя производительность нулевого обучения по мере увеличения обучающих данных. Оба метода в итоге достигают сопоставимой точности около отметки в 400 образцов, причем малоразмерное обучение сохраняет небольшое преимущество. Эта закономерность справедлива как для многоклассовой, так и для классификации изображений, что говорит о том, что малоразмерное обучение может быть особенно выгодным при наличии некоторых обучающих данных, в то время как нулевое обучение обеспечивает надежную производительность даже без каких-либо обучающих примеров. В таблице ниже приведены различия между классификацией с нулевым и малоразмерным обучением с точки зрения пользователя API.
| Feature | Zero-shot | Few-shot |
|---|---|---|
| Primary Use Case | Default solution for general classification | For data outside v3/clip-v1's domain or time-sensitive data |
| Training Data Required | No | Yes |
| Labels Required in /train | N/A | Yes |
| Labels Required in /classify | Yes | No |
| Classifier ID Required | No | Yes |
| Semantic Labels Required | Yes | No |
| State Management | Stateless | Stateful |
| Continuous Model Updates | No | Yes |
| Access Control | No | Yes |
| Maximum Classes | 256 | 16 |
| Maximum Classifiers | N/A | 16 |
| Maximum Inputs per Request | 1,024 | 1,024 |
| Maximum Token Length per Input | 8,192 tokens | 8,192 tokens |
tagИтоги
API классификатора предлагает мощные возможности классификации с нулевым и малоразмерным обучением как для текста, так и для изображений, используя передовые модели эмбеддингов, такие как jina-embeddings-v3 и jina-clip-v1. Наши тесты показывают, что классификация с нулевым обучением обеспечивает надежную производительность без обучающих данных, что делает её отличной отправной точкой для большинства задач с поддержкой до 256 классов. Хотя малоразмерное обучение может достичь немного лучшей точности при наличии обучающих данных, мы рекомендуем начинать с классификации с нулевым обучением из-за её мгновенных результатов и гибкости.
Универсальность API поддерживает различные приложения, от маршрутизации запросов LLM до определения доступности веб-сайтов и категоризации многоязычного контента. Независимо от того, начинаете ли вы с нулевого обучения или переходите к малоразмерному обучению для специализированных случаев, API сохраняет единообразный интерфейс для беспрепятственной интеграции в ваш процесс. Мы особенно рады видеть, как разработчики будут использовать этот API в своих приложениях, и в будущем мы добавим поддержку новых моделей эмбеддингов, таких как jina-clip-v2.




