



Jina CLIP v1 (jina-clip-v1) — это новая мультимодальная модель для эмбеддингов, которая расширяет возможности оригинальной модели CLIP от OpenAI. С этой новой моделью пользователи получают единую модель эмбеддингов, которая обеспечивает передовую производительность как для текстового поиска, так и для кросс-модального поиска текста и изображений. Jina AI улучшила производительность OpenAI CLIP на 165% в текстовом поиске и на 12% в поиске по изображениям, сохранив идентичную или немного лучшую производительность в задачах поиска текста по изображению и изображения по тексту. Это улучшенное качество делает Jina CLIP v1 незаменимой для работы с мультимодальными входными данными.
В этой статье мы сначала обсудим недостатки оригинальной модели CLIP и как мы решили их с помощью уникального метода совместного обучения. Затем мы продемонстрируем эффективность нашей модели на различных тестах поиска. Наконец, мы предоставим подробные инструкции о том, как пользователи могут начать работу с Jina CLIP v1 через наш API для эмбеддингов и Hugging Face.
tagАрхитектура CLIP для мультимодального ИИ
В январе 2021 года OpenAI выпустила модель CLIP (Contrastive Language–Image Pretraining). CLIP имеет простую, но гениальную архитектуру: она объединяет две модели эмбеддингов — одну для текстов и одну для изображений — в единую модель с единым выходным пространством эмбеддингов. Ее текстовые и изображенные эмбеддинги напрямую сопоставимы друг с другом, что делает расстояние между текстовым эмбеддингом и эмбеддингом изображения пропорциональным тому, насколько хорошо этот текст описывает изображение, и наоборот.
Это оказалось очень полезным для мультимодального информационного поиска и классификации изображений без предварительного обучения. Без дополнительного специального обучения CLIP хорошо справлялась с распределением изображений по категориям с метками на естественном языке.

Модель текстовых эмбеддингов в оригинальном CLIP представляла собой специальную нейронную сеть всего с 63 миллионами параметров. Что касается изображений, OpenAI выпустила CLIP с набором моделей ResNet и ViT. Каждая модель была предварительно обучена для своей отдельной модальности, а затем обучена на изображениях с подписями для получения схожих эмбеддингов для подготовленных пар изображение-текст.
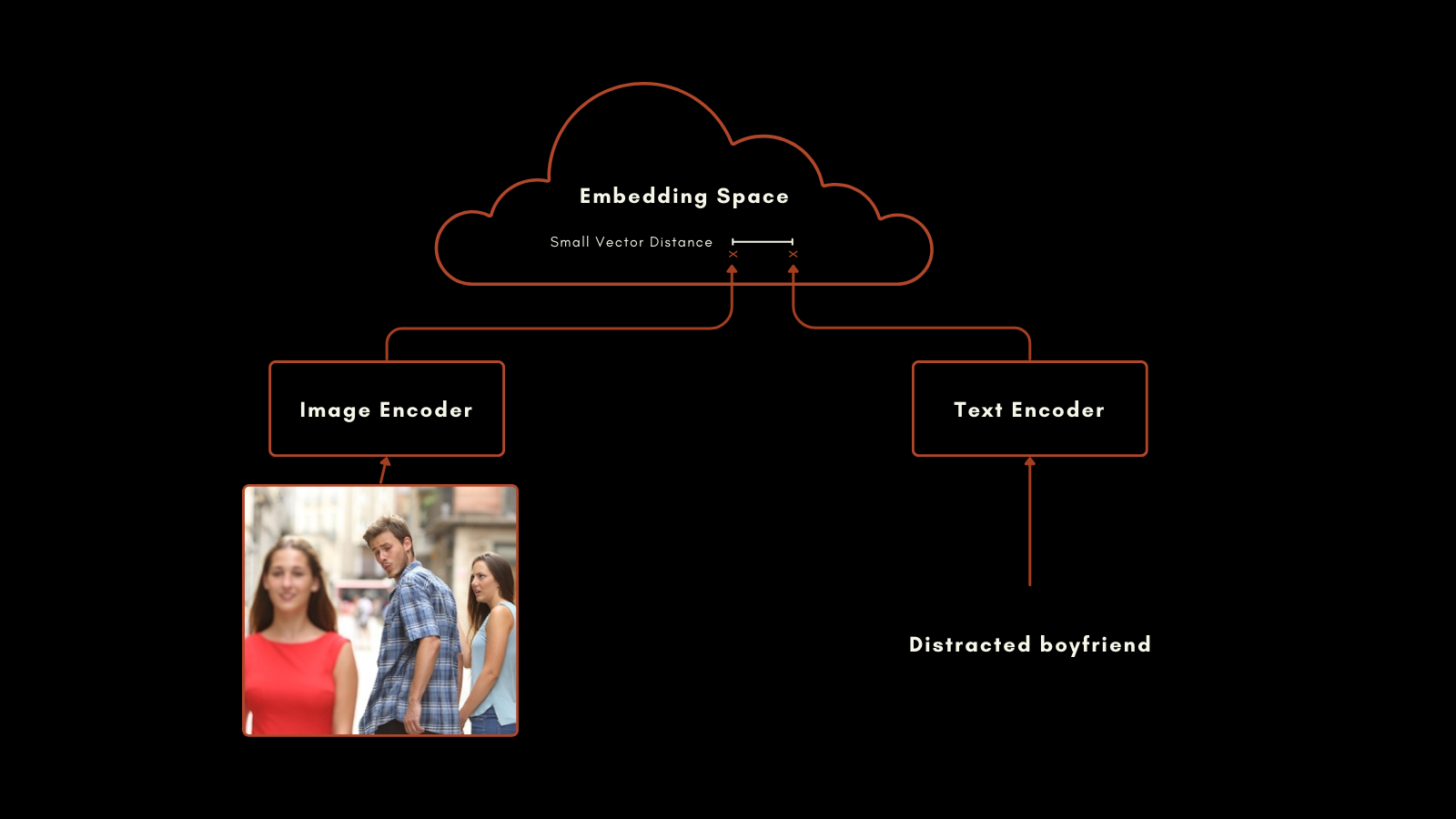
Этот подход дал впечатляющие результаты. Особенно примечательна его производительность в классификации без предварительного обучения. Например, хотя обучающие данные не включали маркированные изображения астронавтов, CLIP могла правильно идентифицировать фотографии астронавтов на основе своего понимания связанных концепций в текстах и изображениях.
Однако у OpenAI CLIP есть два важных недостатка:
- Первый — это очень ограниченная емкость текстового ввода. Она может принимать максимум 77 токенов ввода, но эмпирический анализ показывает, что на практике она не использует более 20 токенов для создания эмбеддингов. Это потому, что CLIP обучалась на изображениях с подписями, а подписи обычно очень короткие. Это контрастирует с современными моделями текстовых эмбеддингов, которые поддерживают несколько тысяч токенов.
- Второй — производительность ее текстовых эмбеддингов в сценариях только текстового поиска очень низкая. Подписи к изображениям — это очень ограниченный вид текста, который не отражает широкий спектр случаев использования, которые ожидаются от модели текстовых эмбеддингов.
В большинстве реальных случаев использования текстовый и текстово-изображенческий поиск комбинируются или как минимум оба доступны для задач. Поддержание второй модели эмбеддингов для текстовых задач фактически удваивает размер и сложность вашей системы ИИ.
Новая модель Jina AI напрямую решает эти проблемы, и jina-clip-v1 использует прогресс, достигнутый за последние несколько лет, чтобы обеспечить передовую производительность в задачах, включающих все комбинации текстовых и изображенческих модальностей.
tagПредставляем Jina CLIP v1
Jina CLIP v1 сохраняет оригинальную схему OpenAI CLIP: две модели, совместно обученные для создания выходных данных в одном пространстве эмбеддингов.
Для кодирования текста мы адаптировали архитектуру Jina BERT v2, используемую в моделях Jina Embeddings v2. Эта архитектура поддерживает современное окно ввода в 8 тысяч токенов и выдает 768-мерные векторы, создавая более точные эмбеддинги из длинных текстов. Это более чем в 100 раз превышает поддержку 77 токенов ввода в оригинальной модели CLIP.
Для эмбеддингов изображений мы используем последнюю модель от Пекинской академии искусственного интеллекта: модель EVA-02. Мы эмпирически сравнили ряд моделей ИИ для изображений, тестируя их в кросс-модальных контекстах с аналогичным предварительным обучением, и EVA-02 явно превзошла остальные. Она также сопоставима с архитектурой Jina BERT по размеру модели, поэтому вычислительные нагрузки для задач обработки изображений и текста примерно одинаковы.
Эти решения дают пользователям важные преимущества:
- Лучшая производительность на всех тестах и всех комбинациях модальностей, и особенно большие улучшения в производительности текстовых эмбеддингов.
- Эмпирически превосходная производительность
EVA-02как в текстово-изображенческих, так и в чисто изображенческих задачах, с дополнительным преимуществом дополнительного обучения Jina AI, улучшающего производительность работы с изображениями. - Поддержка гораздо более длинных текстовых входных данных. Поддержка 8 тысяч токенов ввода в Jina Embeddings позволяет обрабатывать подробную текстовую информацию и соотносить ее с изображениями.
- Большая экономия места, вычислительных ресурсов, обслуживания кода и сложности, поскольку эта мультимодальная модель высокопроизводительна даже в немультимодальных сценариях.
tagОбучение
Часть нашего рецепта высокопроизводительного мультимодального ИИ — это наши обучающие данные и процедура. Мы заметили, что очень малая длина текстов, используемых в подписях к изображениям, является основной причиной низкой производительности только текстового поиска в моделях типа CLIP, и наше обучение специально разработано для исправления этого.
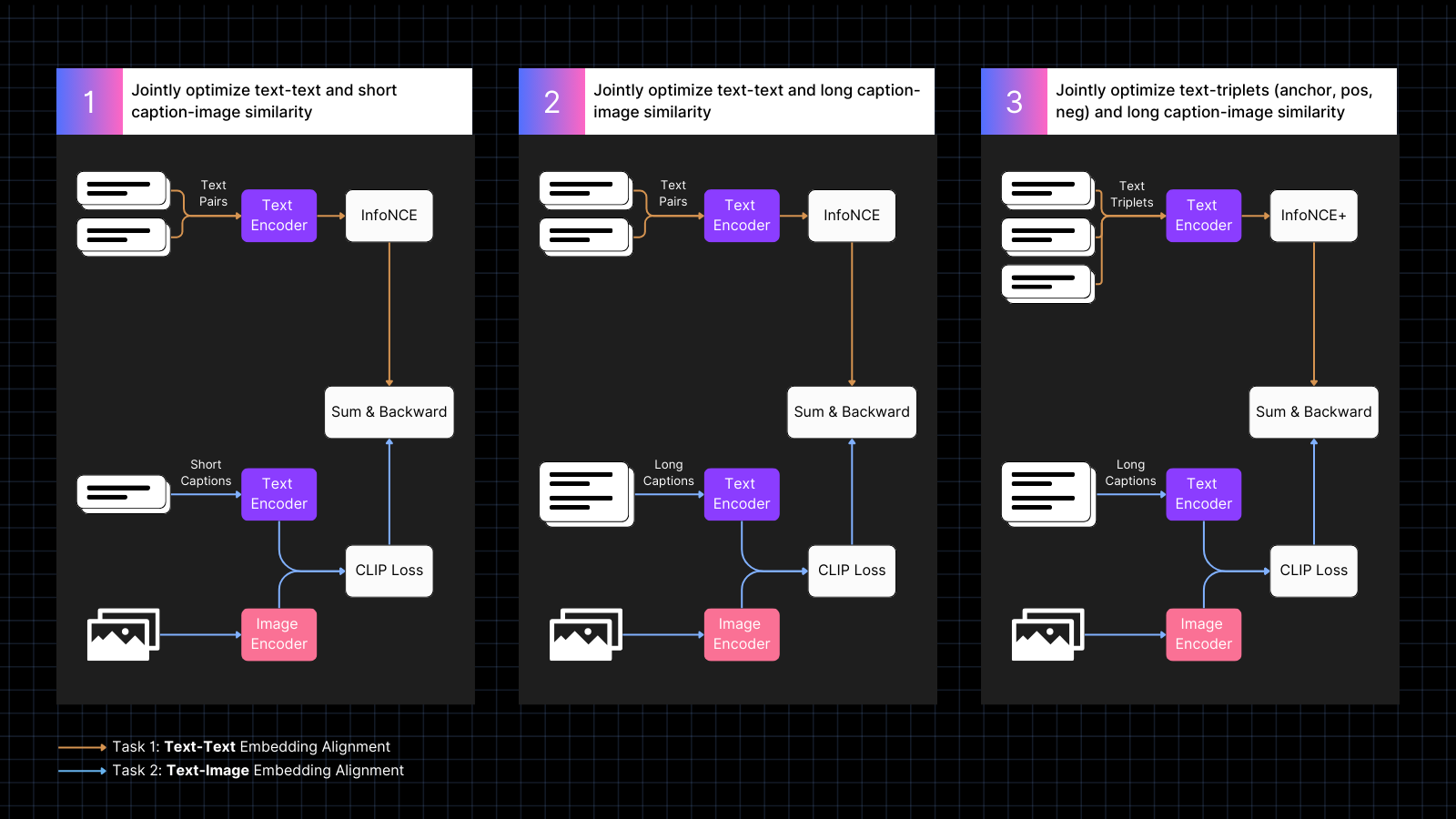
Обучение проходит в три этапа:
- Использование данных изображений с подписями для обучения выравниванию эмбеддингов изображений и текста, чередуясь с текстовыми парами со схожими значениями. Это совместное обучение оптимизирует оба типа задач одновременно. Производительность только текстового поиска модели снижается на этом этапе, но не так сильно, как если бы мы обучали только на парах изображение-текст.
- Обучение с использованием синтетических данных, которые сопоставляют изображения с более длинными текстами, сгенерированными моделью ИИ, описывающими изображение. Продолжение обучения с текстовыми парами одновременно. На этом этапе модель учится обращать внимание на более длинные тексты в сочетании с изображениями.
- Использование текстовых триплетов с сложными отрицательными примерами для дальнейшего улучшения производительности только текстового поиска путем обучения более тонким семантическим различиям. Одновременно продолжение обучения с использованием синтетических пар изображений и длинных текстов. На этом этапе производительность текстового поиска значительно улучшается без потери моделью каких-либо способностей работы с изображениями и текстом.
Для получения дополнительной информации о деталях обучения и архитектуре модели, пожалуйста, прочитайте нашу недавнюю статью:
tagНовый эталон в мультимодальных вложениях
Мы оценили производительность Jina CLIP v1 в текстовых задачах, задачах с изображениями и кросс-модальных задачах, включающих оба типа входных данных. Мы использовали бенчмарк MTEB для оценки текстовой производительности. Для задач с изображениями мы использовали бенчмарк CIFAR-100. Для кросс-модальных задач мы проводили оценку на наборах данных Flickr8k, Flickr30K и MSCOCO Captions, которые включены в CLIP Benchmark.
Результаты обобщены в таблице ниже:
| Model | Text-Text | Text-to-Image | Image-to-Text | Image-Image |
|---|---|---|---|---|
| jina-clip-v1 | 0.429 | 0.899 | 0.803 | 0.916 |
| openai-clip-vit-b16 | 0.162 | 0.881 | 0.756 | 0.816 |
| % increase vs OpenAI CLIP |
165% | 2% | 6% | 12% |
Как видно из этих результатов, jina-clip-v1 превосходит оригинальный CLIP от OpenAI во всех категориях и значительно лучше в задачах поиска только по тексту и только по изображениям. В среднем по всем категориям это улучшение производительности на 46%.
Более подробную оценку можно найти в нашей недавней статье.
tagНачало работы с API вложений
Вы можете легко интегрировать Jina CLIP v1 в свои приложения, используя Jina Embeddings API.
Код ниже показывает, как вызвать API для получения вложений текстов и изображений, используя пакет requests в Python. Он передает текстовую строку и URL изображения на сервер Jina AI и возвращает оба кодирования.
<YOUR_JINA_AI_API_KEY> на активированный ключ API Jina. Вы можете получить пробный ключ с миллионом бесплатных токенов на странице Jina Embeddings.import requests
import numpy as np
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
url = 'https://api.jina.ai/v1/embeddings'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR_JINA_AI_API_KEY>'
}
data = {
'input': [
{"text": "Bridge close-shot"},
{"url": "https://fastly.picsum.photos/id/84/1280/848.jpg?hmac=YFRYDI4UsfbeTzI8ZakNOR98wVU7a-9a2tGF542539s"}],
'model': 'jina-clip-v1',
'encoding_type': 'float'
}
response = requests.post(url, headers=headers, json=data)
sim = cos_sim(np.array(response.json()['data'][0]['embedding']), np.array(response.json()['data'][1]['embedding']))
print(f"Cosine text<->image: {sim}")
tagИнтеграция с основными LLM-фреймворками
Jina CLIP v1 уже доступен для LlamaIndex и LangChain:
- LlamaIndex: Используйте
JinaEmbeddingс базовым классомMultimodalEmbeddingи вызывайтеget_image_embeddingsилиget_text_embeddings. - LangChain: Используйте
JinaEmbeddingsи вызывайтеembed_imagesилиembed_documents.
tagЦенообразование
Как текстовые, так и изображения тарифицируются по потреблению токенов.
Для текста на английском языке мы эмпирически подсчитали, что в среднем требуется 1.1 токена на каждое слово.
Для изображений мы считаем количество тайлов размером 224x224 пикселя, необходимых для покрытия вашего изображения. Некоторые из этих тайлов могут быть частично пустыми, но учитываются так же. Каждый тайл потребляет 1000 токенов для обработки.
Пример
Для изображения размером 750x500 пикселей:
- Изображение делится на тайлы размером 224x224 пикселя.
- Чтобы рассчитать количество тайлов, разделите ширину в пикселях на 224 и округлите до следующего целого числа.
750/224 ≈ 3.35 → 4 - Повторите для высоты в пикселях:
500/224 ≈ 2.23 → 3
- Чтобы рассчитать количество тайлов, разделите ширину в пикселях на 224 и округлите до следующего целого числа.
- Общее количество необходимых тайлов в этом примере:
4 (по горизонтали) x 3 (по вертикали) = 12 тайлов - Стоимость составит 12 x 1000 = 12000 токенов
tagКорпоративная поддержка
Мы представляем новую льготу для пользователей, которые приобретают план Production Deployment с 11 миллиардами токенов. Это включает:
- Три часа консультаций с нашими продуктовыми и инженерными командами для обсуждения ваших конкретных случаев использования и требований.
- Настроенный Python-блокнот, разработанный для вашего случая использования RAG (Retrieval-Augmented Generation) или векторного поиска, демонстрирующий как интегрировать модели Jina AI в ваше приложение.
- Назначение персонального менеджера и приоритетную поддержку по электронной почте для обеспечения быстрого и эффективного удовлетворения ваших потребностей.
tagOpen-Source Jina CLIP v1 на Hugging Face
Jina AI привержена открытой поисковой основе, и для этой цели мы делаем эту модель доступной бесплатно под лицензией Apache 2.0, на Hugging Face.
Вы можете найти пример кода для загрузки и запуска этой модели на вашей собственной системе или облачной установке на странице модели Hugging Face для jina-clip-v1.

tagИтоги
Новейшая модель Jina AI — jina-clip-v1 — представляет собой значительный прогресс в мультимодальных моделях вложений, предлагая существенное повышение производительности по сравнению с CLIP от OpenAI. С заметными улучшениями в задачах поиска только по тексту и только по изображениям, а также конкурентоспособной производительностью в задачах текст-в-изображение и изображение-в-текст, она является многообещающим решением для сложных случаев использования вложений.
В настоящее время эта модель поддерживает только англоязычные тексты из-за ограничений ресурсов. Мы работаем над расширением ее возможностей для поддержки большего количества языков.
