



Сегодня мы рады представить jina-embeddings-v3, передовую модель текстовых эмбеддингов с 570 миллионами параметров. Она достигает лучших в своем классе результатов на многоязычных данных и задачах поиска с длинным контекстом, поддерживая входную длину до 8192 токенов. Модель имеет специфичные для задач адаптеры Low-Rank Adaptation (LoRA), позволяющие генерировать высококачественные эмбеддинги для различных задач, включая поиск по запросам-документам, кластеризацию, классификацию и сопоставление текстов.
По результатам оценки на MTEB English, Multilingual и LongEmbed, jina-embeddings-v3 превосходит последние проприетарные эмбеддинги от OpenAI и Cohere в английских задачах, а также превосходит multilingual-e5-large-instruct во всех многоязычных задачах. С размерностью выходного вектора по умолчанию 1024, пользователи могут произвольно уменьшать размерности эмбеддингов до 32 без потери производительности благодаря интеграции Matryoshka Representation Learning (MRL).


jina-embeddings-v2-(zh/es/de) относится к нашему набору двуязычных моделей, которые тестировались только на китайских, испанских и немецких моноязычных и кросс-языковых задачах, исключая все другие языки. Кроме того, мы не приводим оценки для openai-text-embedding-3-large и cohere-embed-multilingual-v3.0, так как эти модели не оценивались на полном наборе многоязычных и кросс-языковых задач MTEB.
baai-bge-m3, так и подход на основе ALiBi, используемый в jina-embeddings-v2.На момент релиза 18 сентября 2024 года jina-embeddings-v3 является лучшей многоязычной моделью и занимает 2-е место в рейтинге MTEB English среди моделей с менее чем 1 миллиардом параметров. v3 поддерживает в общей сложности 89 языков, включая 30 языков с наилучшей производительностью: арабский, бенгальский, китайский, датский, голландский, английский, финский, французский, грузинский, немецкий, греческий, хинди, индонезийский, итальянский, японский, корейский, латышский, норвежский, польский, португальский, румынский, русский, словацкий, испанский, шведский, тайский, турецкий, украинский, урду и вьетнамский.
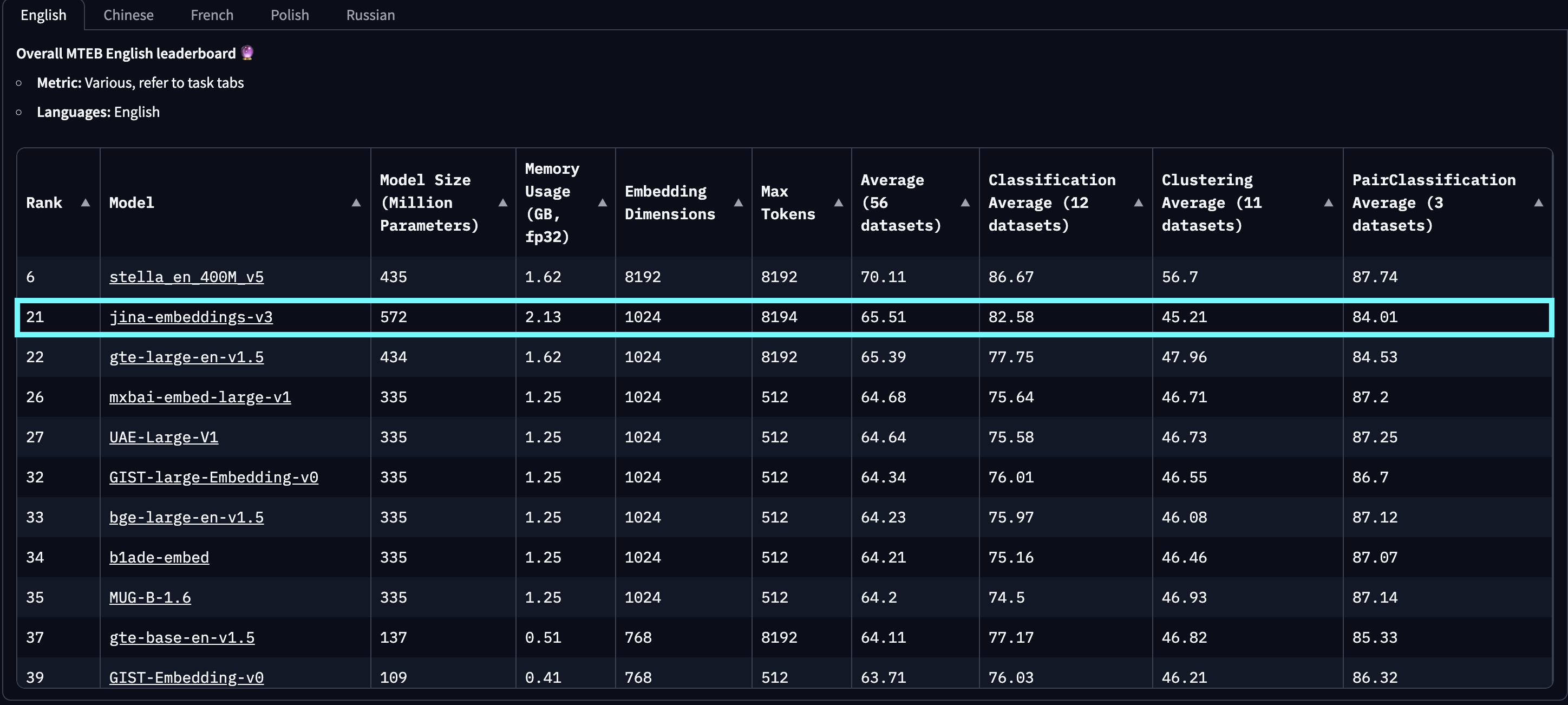

jina-embeddings-v2. Этот график был создан путем выбора топ-100 моделей эмбеддингов из рейтинга MTEB, исключая те, для которых отсутствует информация о размере, обычно закрытые или проприетарные модели. Также были отфильтрованы материалы, идентифицированные как очевидный троллинг.Кроме того, по сравнению с эмбеддингами на основе LLM, которые недавно привлекли внимание, такими как e5-mistral-7b-instruct, имеющими размер параметров 7.1 миллиардов (в 12 раз больше) и выходную размерность 4096 (в 4 раза больше), но предлагающими только 1% улучшение на английских задачах MTEB, jina-embeddings-v3 является гораздо более экономичным решением, делая его более подходящим для производства и периферийных вычислений.
tagАрхитектура модели
| Характеристика | Описание |
|---|---|
| База | jina-XLM-RoBERTa |
| Базовые параметры | 559M |
| Параметры с LoRA | 572M |
| Максимальное количество входных токенов | 8192 |
| Максимальные выходные размерности | 1024 |
| Слои | 24 |
| Словарь | 250K |
| Поддерживаемые языки | 89 |
| Внимание | FlashAttention2, также работает без него |
| Пулинг | Mean pooling |
Архитектура jina-embeddings-v3 показана на рисунке ниже. Для реализации базовой архитектуры мы адаптировали модель XLM-RoBERTa с несколькими ключевыми модификациями: (1) обеспечение эффективного кодирования длинных текстовых последовательностей, (2) возможность кодирования эмбеддингов под конкретные задачи и (3) повышение общей эффективности модели с помощью последних технологий. Мы продолжаем использовать оригинальный токенизатор XLM-RoBERTa. Хотя jina-embeddings-v3 со своими 570 миллионами параметров больше, чем jina-embeddings-v2 со 137 миллионами, она все еще значительно меньше моделей эмбеддингов, дообученных из LLM.

jina-XLM-RoBERTa с пятью LoRA адаптерами для четырех различных задач.Ключевым нововведением в jina-embeddings-v3 является использование LoRA адаптеров. Введены пять специфических для задач LoRA адаптеров для оптимизации эмбеддингов под четыре задачи. Входные данные модели состоят из двух частей: текста (длинный документ для эмбеддинга) и задачи. jina-embeddings-v3 поддерживает четыре задачи и реализует пять адаптеров на выбор: retrieval.query и retrieval.passage для эмбеддингов запросов и пассажей в асимметричных задачах поиска, separation для задач кластеризации, classification для задач классификации и text-matching для задач, связанных с семантическим сходством, таких как STS или симметричный поиск. LoRA адаптеры составляют менее 3% от общего числа параметров, добавляя минимальные накладные расходы на вычисления.
Для дальнейшего повышения производительности и снижения потребления памяти мы интегрировали FlashAttention 2, поддерживаем контрольные точки активации и используем фреймворк DeepSpeed для эффективного распределенного обучения.
tagНачало работы
tagЧерез Jina AI Search Foundation API
Самый простой способ использовать jina-embeddings-v3 — посетить домашнюю страницу Jina AI и перейти в раздел Search Foundation API. Начиная с сегодняшнего дня, эта модель установлена по умолчанию для всех новых пользователей. Вы можете исследовать различные параметры и функции непосредственно оттуда.
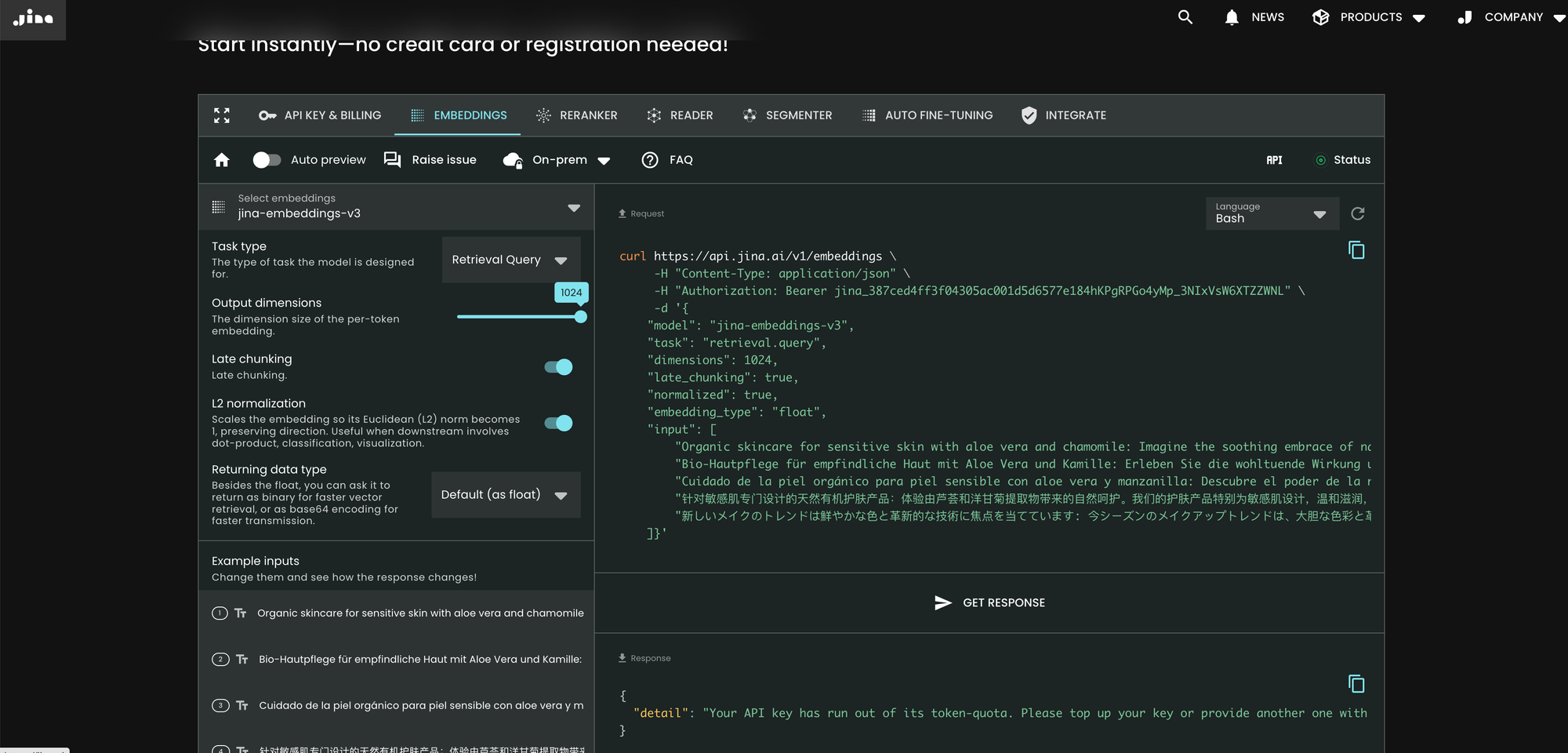
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jina_387ced4ff3f04305ac001d5d6577e184hKPgRPGo4yMp_3NIxVsW6XTZZWNL" \
-d '{
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 1024,
"late_chunking": true,
"input": [
"Organic skincare for sensitive skin with aloe vera and chamomile: ...",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung...",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder ...",
"针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,...",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。..."
]}'
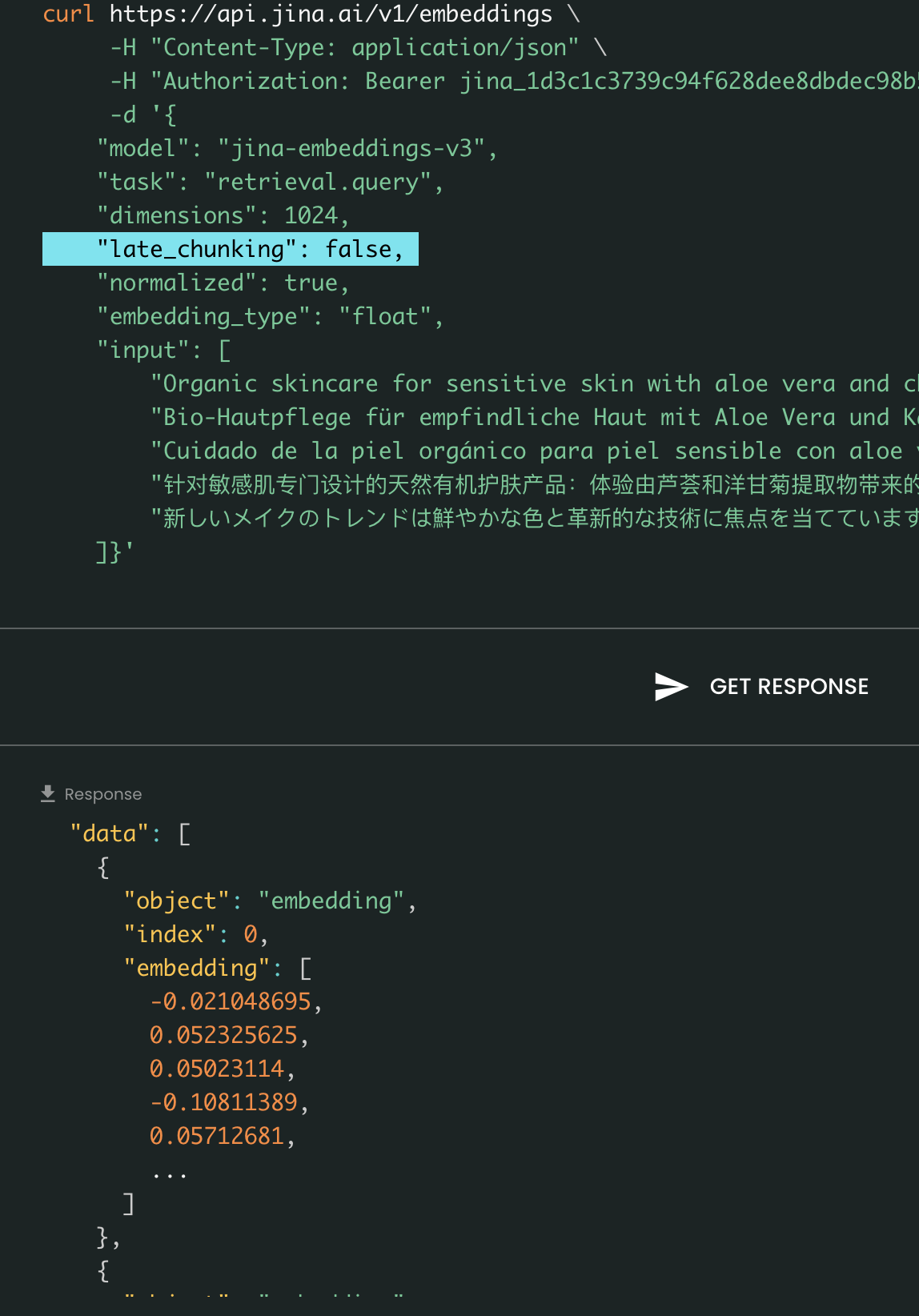
По сравнению с v2, v3 вводит три новых параметра в API: task, dimensions и late_chunking.
Параметр task
Параметр task является критически важным и должен быть установлен в соответствии с последующей задачей. Получаемые эмбеддинги будут оптимизированы для этой конкретной задачи. Для более подробной информации обратитесь к списку ниже.
Значение task |
Описание задачи |
|---|---|
retrieval.passage |
Эмбеддинг документов в задаче поиска по запросам |
retrieval.query |
Эмбеддинг запросов в задаче поиска по запросам |
separation |
Кластеризация документов, визуализация корпуса |
classification |
Классификация текста |
text-matching |
(По умолчанию) Семантическое сходство текстов, общий симметричный поиск, рекомендации, поиск похожих элементов, дедупликация |
Обратите внимание, что API не генерирует сначала общий мета-эмбеддинг, а затем адаптирует его с помощью дополнительного дообученного MLP. Вместо этого он вставляет специфичный для задачи LoRA адаптер в каждый слой трансформера (всего 24 слоя) и выполняет кодирование за один проход. Дополнительные подробности можно найти в нашей статье на arXiv.
Параметр dimensions
Параметр dimensions позволяет пользователям выбрать компромисс между эффективностью использования пространства и производительностью при минимальных затратах. Благодаря технике MRL, используемой в jina-embeddings-v3, вы можете уменьшить размерность эмбеддингов сколько угодно (даже до одного измерения!). Меньшие эмбеддинги более экономны для векторных баз данных, а их влияние на производительность можно оценить по графику ниже.

Параметр late_chunking
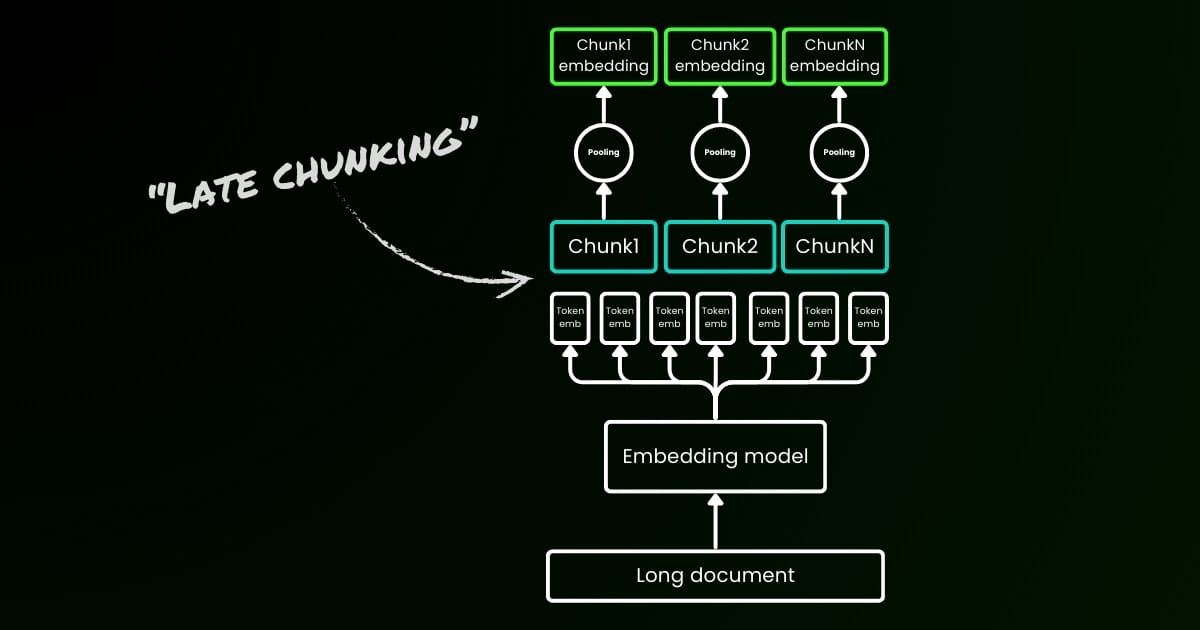
Наконец, параметр late_chunking управляет использованием нового метода разбиения на чанки, который мы представили в прошлом месяце для кодирования пакета предложений. Когда установлено значение true, наш API объединит все предложения в поле input и подаст их как единую строку в модель. Другими словами, мы рассматриваем предложения во входных данных так, как будто они изначально происходят из одного раздела, параграфа или документа. Внутренне модель встраивает эту длинную объединенную строку и затем выполняет позднее разбиение на чанки, возвращая список эмбеддингов, соответствующий размеру входного списка. Каждый эмбеддинг в списке, таким образом, обусловлен предыдущими эмбеддингами.
С точки зрения пользователя, установка late_chunking не меняет формат входных или выходных данных. Вы заметите только изменение в значениях эмбеддингов, так как теперь они вычисляются на основе всего предыдущего контекста, а не независимо. Важно знать при использованииlate_chunking=True означает, что общее количество токенов (суммируя все токены в input) на запрос ограничено 8192, что является максимальной длиной контекста, допустимой для jina-embeddings-v3. Когда late_chunking=False, такого ограничения нет; общее количество токенов подчиняется только лимиту запросов API эмбеддингов.
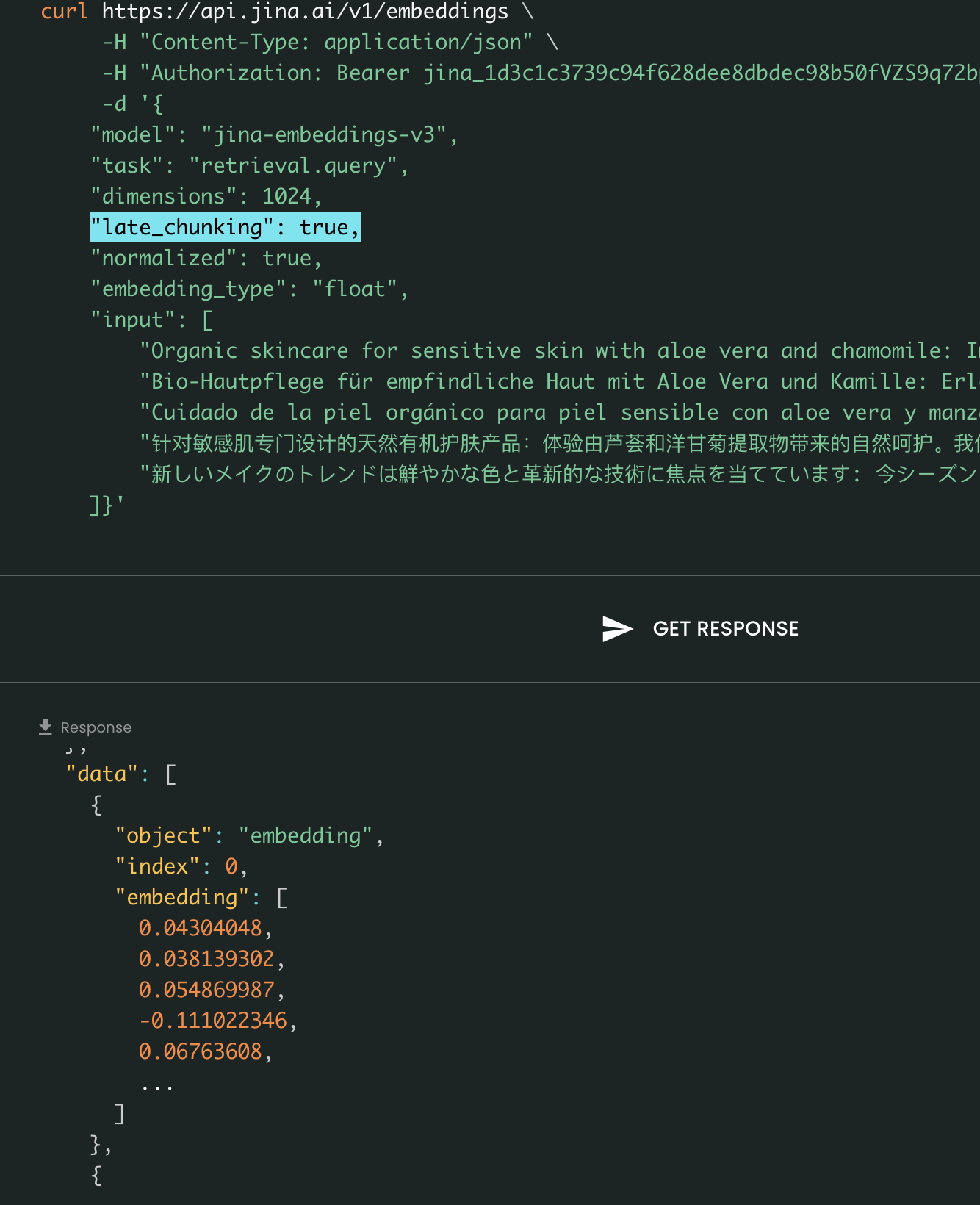
Позднее разбиение включено vs выключено: Формат ввода и вывода остается тем же, единственное отличие — в значениях эмбеддингов. Когда late_chunking включен, на эмбеддинги влияет весь предыдущий контекст в input, тогда как без него эмбеддинги вычисляются независимо.
tagЧерез Azure и AWS
jina-embeddings-v3 теперь доступен на AWS SageMaker и Azure Marketplace.


Если вам нужно использовать его за пределами этих платформ или локально в вашей компании, обратите внимание, что модель лицензирована под CC BY-NC 4.0. По вопросам коммерческого использования, не стесняйтесь связаться с нами.
tagЧерез векторные базы данных и партнеров
Мы тесно сотрудничаем с провайдерами векторных баз данных, такими как Pinecone, Qdrant и Milvus, а также с фреймворками оркестрации LLM, такими как LlamaIndex, Haystack и Dify. На момент релиза мы рады сообщить, что Pinecone, Qdrant, Milvus и Haystack уже интегрировали поддержку jina-embeddings-v3, включая три новых параметра: task, dimensions и late_chunking. Другие партнеры, уже интегрированные с API v2, также должны поддерживать v3, просто изменив название модели на jina-embeddings-v3. Однако они могут еще не поддерживать новые параметры, представленные в v3.
Через Pinecone

Через Qdrant

Через Milvus

Через Haystack

tagЗаключение
В октябре 2023 года мы выпустили jina-embeddings-v2-base-en, первую в мире модель эмбеддингов с открытым исходным кодом с контекстной длиной 8K. Это была единственная модель текстовых эмбеддингов, которая поддерживала длинный контекст и соответствовала OpenAI's text-embedding-ada-002. Сегодня, после года обучения, экспериментов и ценных уроков, мы с гордостью представляем jina-embeddings-v3 — новый рубеж в моделях текстовых эмбеддингов и важная веха нашей компании.
С этим релизом мы продолжаем совершенствоваться в том, чем мы известны: эмбеддинги с длинным контекстом, одновременно решая самую востребованную задачу как от индустрии, так и от сообщества — многоязычные эмбеддинги. В то же время мы поднимаем производительность на новую высоту. С новыми функциями, такими как Task-specific LoRA, MRL и позднее разбиение, мы верим, что jina-embeddings-v3 действительно станет фундаментальной моделью эмбеддингов для различных приложений, включая RAG, агентов и многое другое. По сравнению с недавними эмбеддингами на основе LLM, такими как NV-embed-v1/v2, наша модель высокоэффективна по параметрам, что делает её гораздо более подходящей для продакшена и периферийных устройств.
В дальнейшем мы планируем сосредоточиться на оценке и улучшении производительности jina-embeddings-v3 для низкоресурсных языков и дальнейшем анализе систематических ошибок, вызванных ограниченной доступностью данных. Более того, веса модели jina-embeddings-v3, вместе с её инновационными функциями и горячими обновлениями, послужат основой для наших будущих моделей, включая jina-clip-v2,jina-reranker-v3 и reader-lm-v2.
