




Сегодня мы выпускаем Jina Reranker v2 (jina-reranker-v2-base-multilingual), нашу новейшую и самую эффективную модель нейронного переранжирования в семействе поисковых основ. С Jina Reranker v2 разработчики систем RAG/поиска получат следующие преимущества:
- Многоязычность: Более релевантные результаты поиска на более чем 100 языках, превосходящие
bge-reranker-v2-m3; - Агентность: Современное переранжирование документов с учетом вызова функций и text-to-SQL для агентного RAG;
- Поиск кода: Максимальная производительность при поиске кода, и
- Сверхбыстрая работа: пропускная способность в 15 раз больше документов, чем у
bge-reranker-v2-m3, и в 6 раз больше, чем у jina-reranker-v1-base-en.
Вы можете начать использовать Jina Reranker v2 через наш Reranker API, где мы предлагаем 1 млн бесплатных токенов для всех новых пользователей.

В этой статье мы подробно расскажем о новых функциях, поддерживаемых Jina Reranker v2, покажем, как наша модель переранжирования работает по сравнению с другими современными моделями (включая Jina Reranker v1), и объясним процесс обучения, который привел Jina Reranker v2 к достижению максимальной производительности в точности задач и пропускной способности документов.
tagКраткий обзор: Зачем нужен переранжировщик
Хотя модели эмбеддингов являются наиболее широко используемым и понятным компонентом в поисковой основе, они часто жертвуют точностью ради скорости поиска. Поисковые модели на основе эмбеддингов обычно являются моделями с двумя энкодерами, где каждый документ встраивается и сохраняется, затем запросы также встраиваются, и поиск основывается на сходстве эмбеддинга запроса с эмбеддингами документов. В этой модели многие нюансы взаимодействий на уровне токенов между запросами пользователей и найденными документами теряются, потому что исходный запрос и документы никогда не могут "увидеть" друг друга – это делают только их эмбеддинги. Это может привести к снижению точности поиска – области, в которой превосходно работают модели переранжирования с перекрестным энкодером.

Переранжировщики решают эту проблему отсутствия детальной семантики, используя архитектуру перекрестного энкодера, где пары запрос-документ кодируются вместе для получения оценки релевантности вместо эмбеддинга. Исследования показали, что для большинства систем RAG использование модели переранжирования улучшает семантическое обоснование и снижает галлюцинации.
tagМногоязычная поддержка в Jina Reranker v2
В свое время Jina Reranker v1 выделялся достижением современных показателей на четырех ключевых англоязычных тестах. Сегодня мы значительно расширяем возможности переранжирования в Jina Reranker v2 с многоязычной поддержкой более 100 языков и кросс-языковых задач!
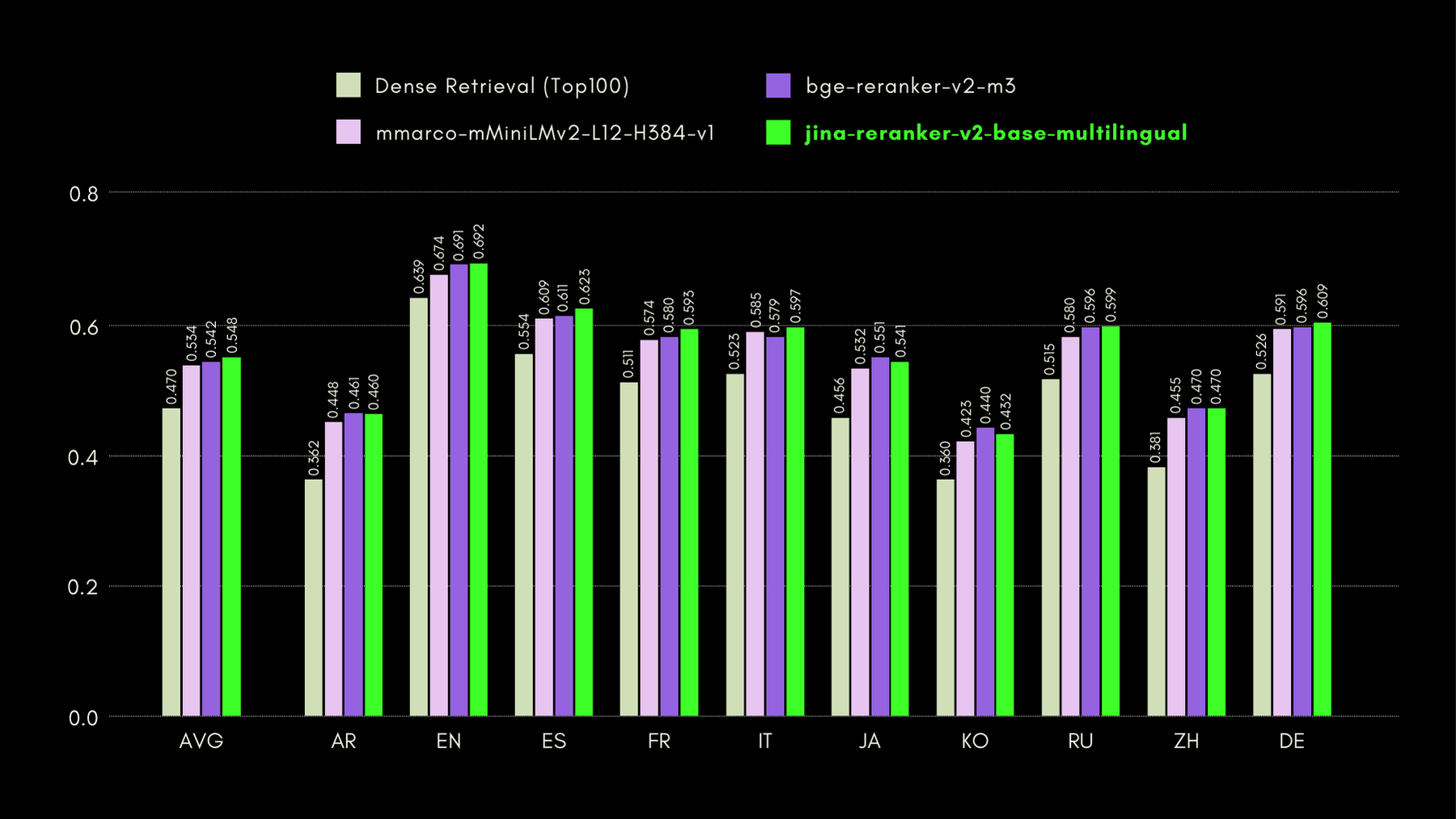
Для оценки кросс-языковых и англоязычных возможностей Jina Reranker v2 мы сравниваем его производительность с аналогичными моделями переранжирования по трем тестам, перечисленным ниже:
MKQA: Многоязычные вопросы и ответы на основе знаний
Этот набор данных включает вопросы и ответы на 26 языках, полученные из реальных баз знаний, и предназначен для оценки кросс-языковой производительности систем вопросов и ответов. MKQA состоит из англоязычных запросов и их ручных переводов на неанглийские языки, вместе с ответами на нескольких языках, включая английский.
На графике ниже мы приводим показатели recall@10 для каждого включенного переранжировщика, включая "dense retriever" в качестве базового уровня, выполняющего традиционный поиск на основе эмбеддингов:
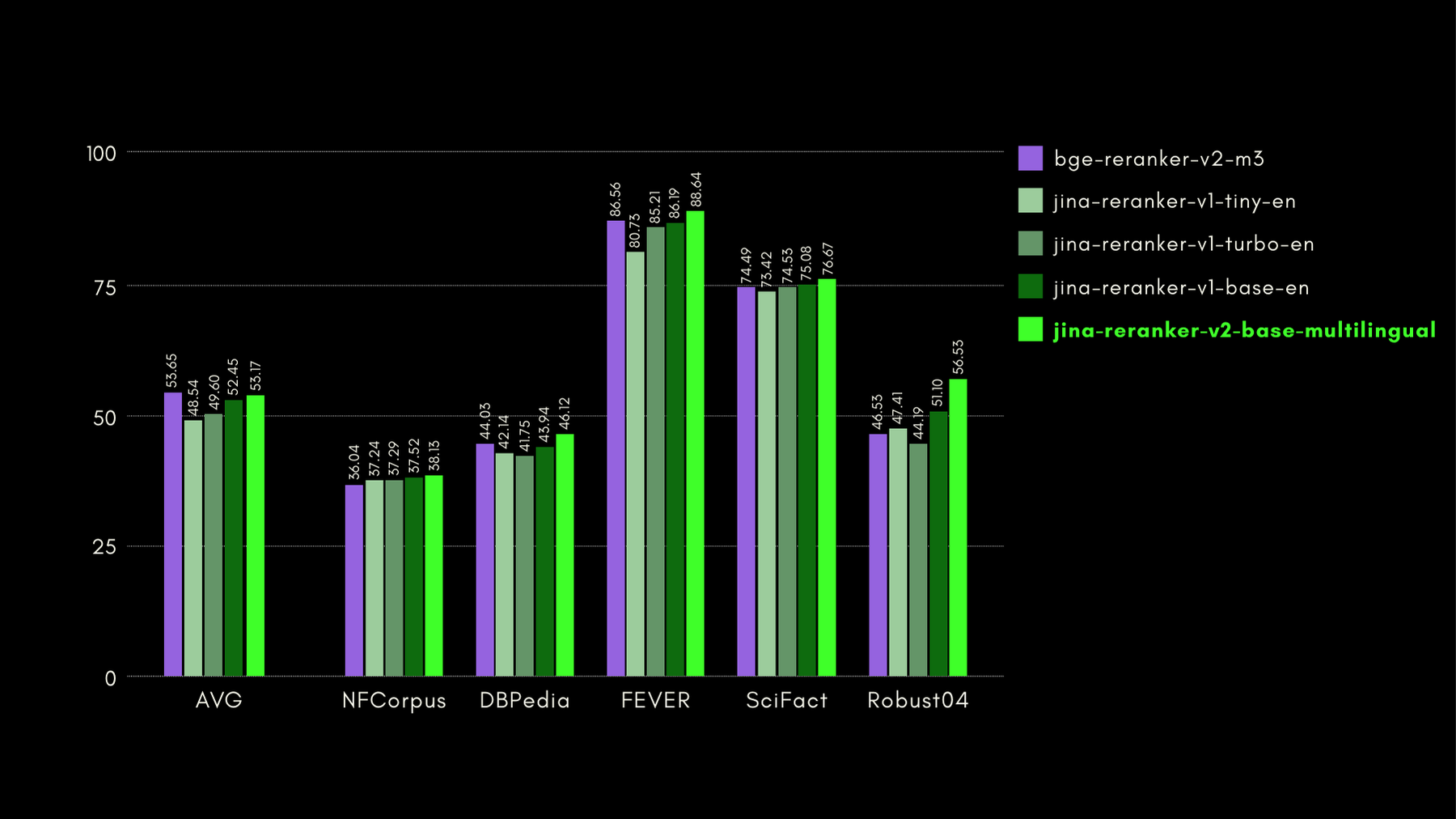
BEIR: Гетерогенный тест по различным задачам IR
Этот репозиторий с открытым исходным кодом содержит тесты поиска для многих языков, но мы фокусируемся только на англоязычных задачах. Они состоят из 17 наборов данных без каких-либо обучающих данных, и основное внимание в этих наборах данных уделяется оценке точности поиска нейронных или лексических поисковых систем.
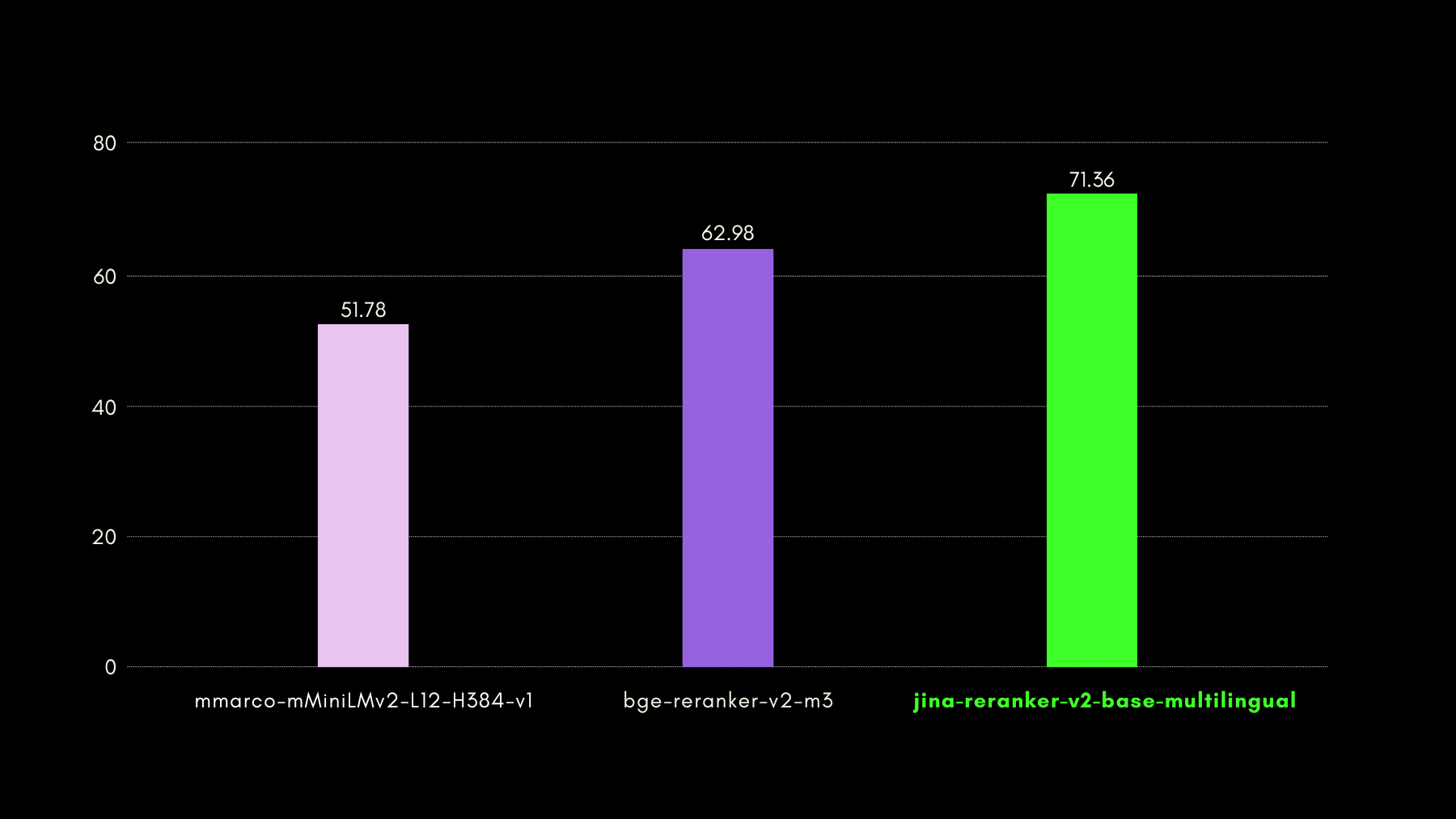
На графике ниже мы приводим NDCG@10 для BEIR с каждым включенным переранжировщиком. Результаты на BEIR явно показывают, что новые многоязычные возможности jina-reranker-v2-base-multilingual не ухудшают его способности поиска на английском языке, которые, более того, значительно улучшены по сравнению с jina-reranker-v1-base-en.
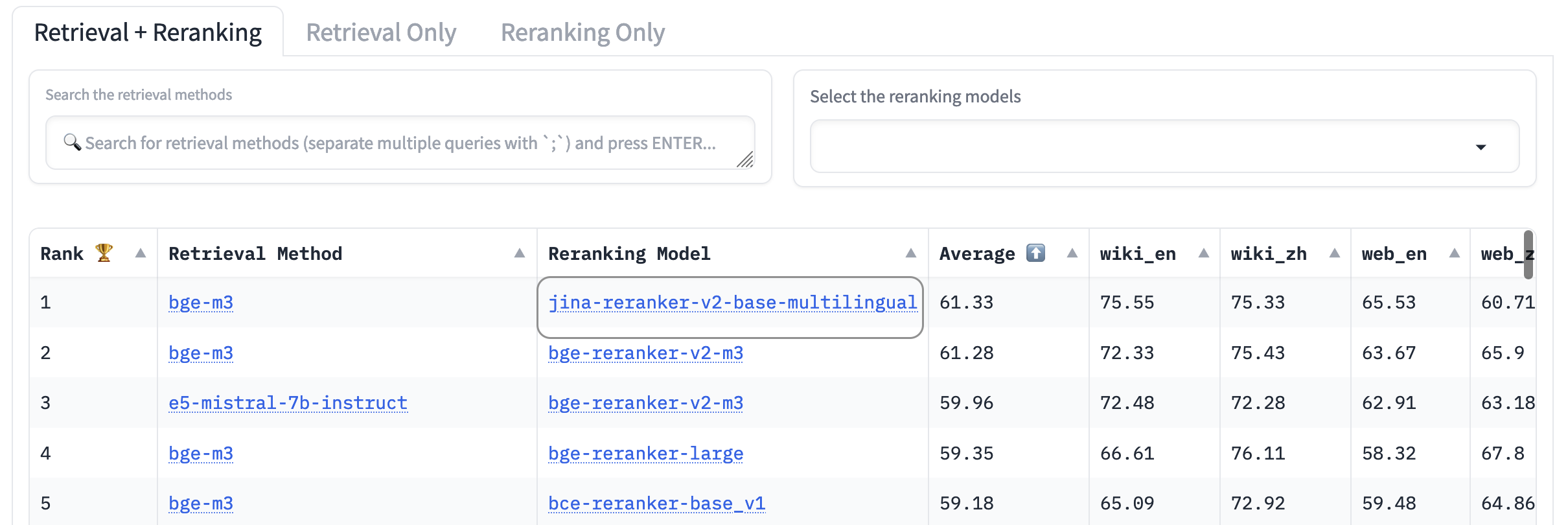
AirBench: Автоматизированный гетерогенный тест IR
Мы совместно создали и опубликовали бенчмарк AirBench для RAG-систем вместе с BAAI. Этот бенчмарк использует автоматически сгенерированные синтетические данные для пользовательских доменов и задач, не раскрывая публично ground truth, чтобы тестируемые модели не могли переобучиться на наборе данных.
На момент написания jina-reranker-v2-base-multilingual превосходит все остальные включенные модели ранжирования, занимая первое место в рейтинге.
tagОбзор Tooling-Agents: Обучение LLM использованию инструментов
С начала большого AI-бума несколько лет назад люди заметили, что AI-модели плохо справляются с задачами, в которых компьютеры должны быть хороши. Например, рассмотрим этот диалог с Mistral-7b-Instruct-v0.1:

На первый взгляд это может показаться правильным, но на самом деле 203 умножить на 7724 равно 1 567 972.
Почему же LLM ошибается более чем в десять раз? Это потому, что LLM не обучены выполнять математические или другие виды рассуждений, и отсутствие внутренней рекурсии практически гарантирует, что они не могут решать сложные математические задачи. Они обучены говорить или выполнять другие задачи, которые по своей природе не требуют точности.
Однако LLM охотно галлюцинируют ответы. С их точки зрения, 15 824 772 - это вполне правдоподобный ответ для 204 × 7 724. Просто он совершенно неверный.
Агентный RAG меняет роль генеративных LLM с того, в чем они плохи — мышление и знание фактов — на то, в чем они хороши: понимание прочитанного и синтез информации в естественный язык. Вместо того чтобы просто генерировать ответ, RAG находит информацию, релевантную вашему запросу, в доступных источниках данных и представляет её языковой модели. Её задача не в том, чтобы придумать ответ, а в том, чтобы представить ответы, найденные другой системой, в естественной и отзывчивой форме.
Мы обучили Jina Reranker v2 учитывать схемы SQL-баз данных и вызов функций. Это требует иной семантики, чем обычный поиск текста. Он должен понимать задачи и код, и мы специально обучили наш ранжировщик для этой функциональности.
tagJina Reranker v2 для запросов к структурированным данным
Хотя модели embedding и reranker уже хорошо работают с неструктурированными данными, поддержка структурированных табличных данных все еще отсутствует в большинстве моделей.
Jina Reranker v2 понимает намерение запроса к источникам структурированных баз данных, таких как MySQL или MongoDB, и присваивает правильную оценку релевантности схеме структурированной таблицы на основе входного запроса.
Вы можете увидеть это ниже, где ранжировщик извлекает наиболее релевантные таблицы перед тем, как LLM получит задание сгенерировать SQL-запрос из запроса на естественном языке:
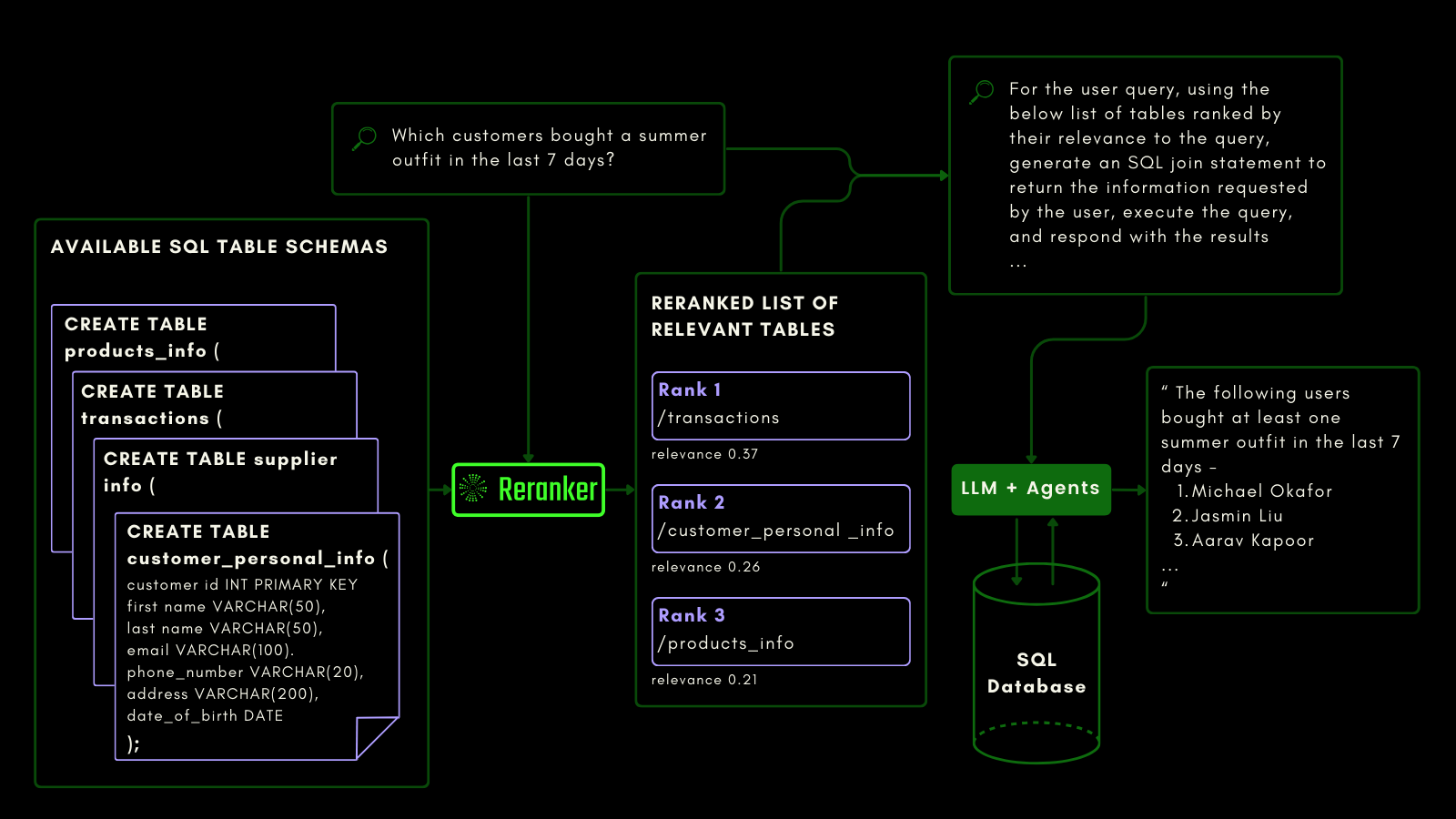
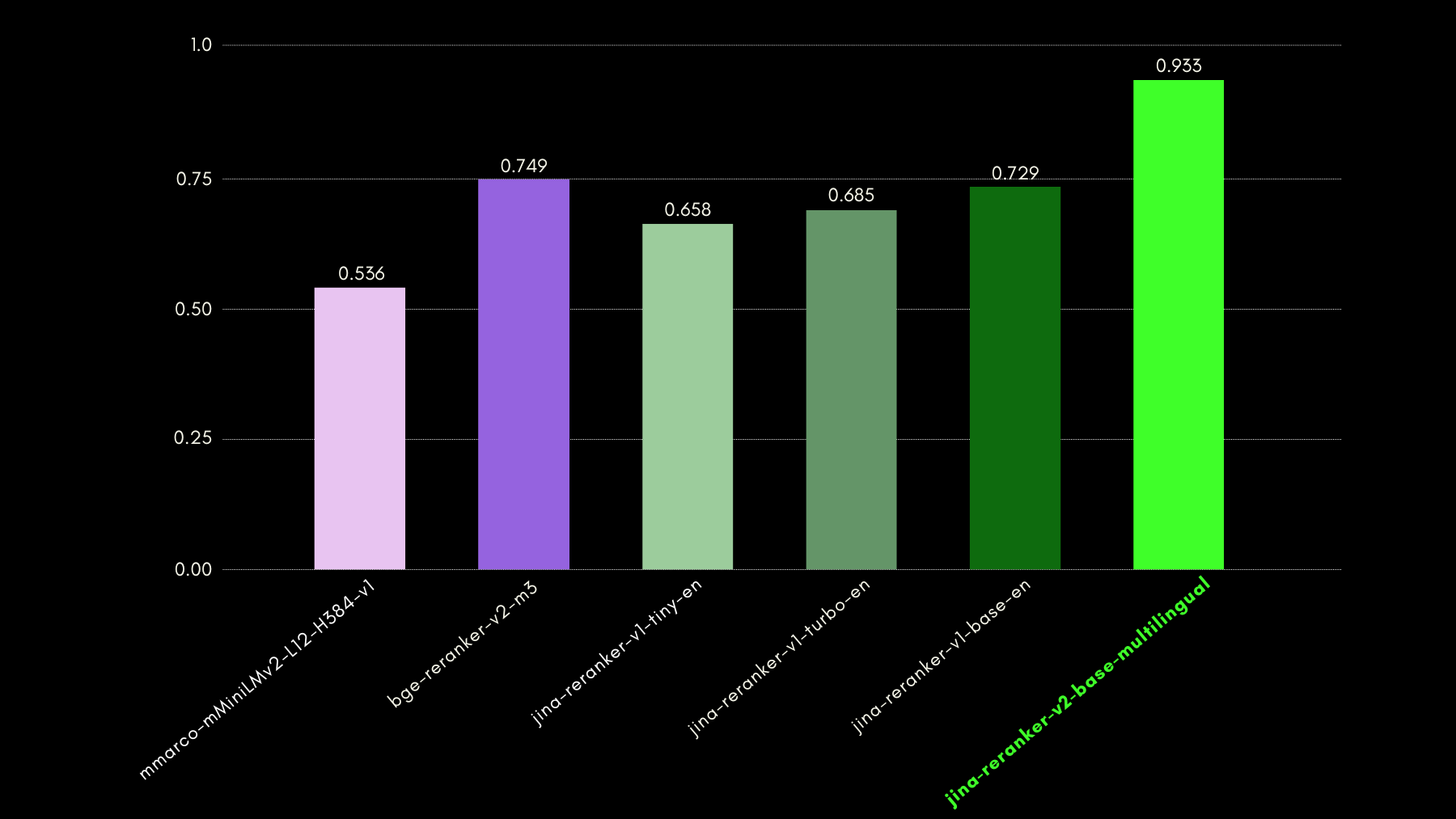
Мы оценили возможности понимания запросов, используя бенчмарк датасета NSText2SQL. Мы извлекли из столбца "instruction" оригинального датасета инструкции, написанные на естественном языке, и соответствующую схему таблицы.
График ниже сравнивает, используя метрику recall@3, насколько успешно модели ранжирования оценивают правильную схему таблицы, соответствующую запросу на естественном языке.
tagJina Reranker v2 для вызова функций
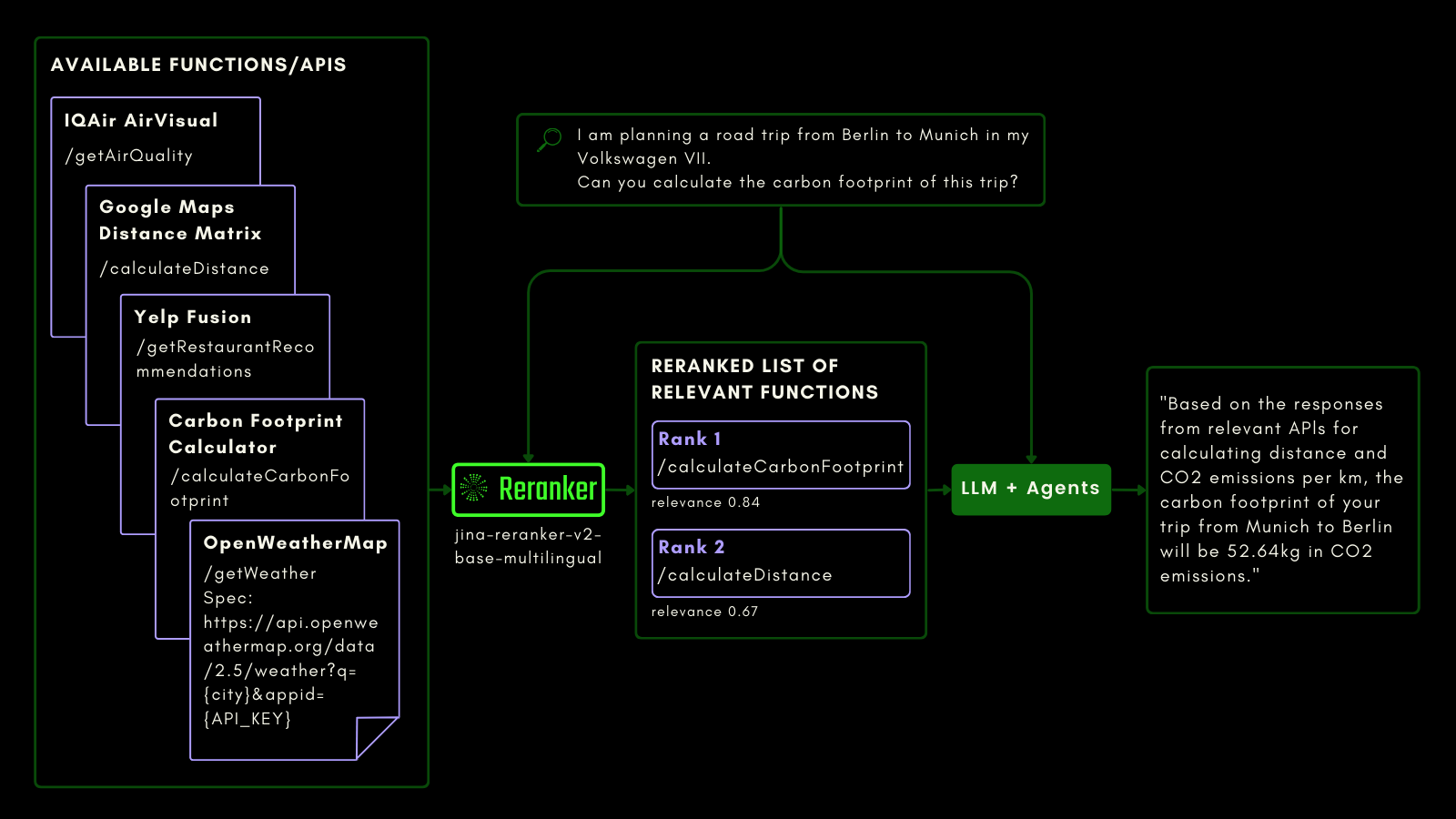
Как и при запросе к SQL-таблице, вы можете использовать агентный RAG для вызова внешних инструментов. Учитывая это, мы интегрировали вызов функций в Jina Reranker v2, позволяя ему понимать ваши намерения относительно внешних функций и соответствующим образом присваивать оценки релевантности спецификациям функций.
Схема ниже объясняет (на примере), как LLM могут использовать Reranker для улучшения возможностей вызова функций и, в конечном итоге, пользовательского опыта агентного AI.
Мы оценили возможности понимания функций с помощью бенчмарка ToolBench. Бенчмарк собирает более 16 тысяч публичных API и соответствующих синтетически сгенерированных инструкций по их использованию в одиночных и мульти-API сценариях.
Вот результаты (метрика recall@3) в сравнении с другими моделями ранжирования:
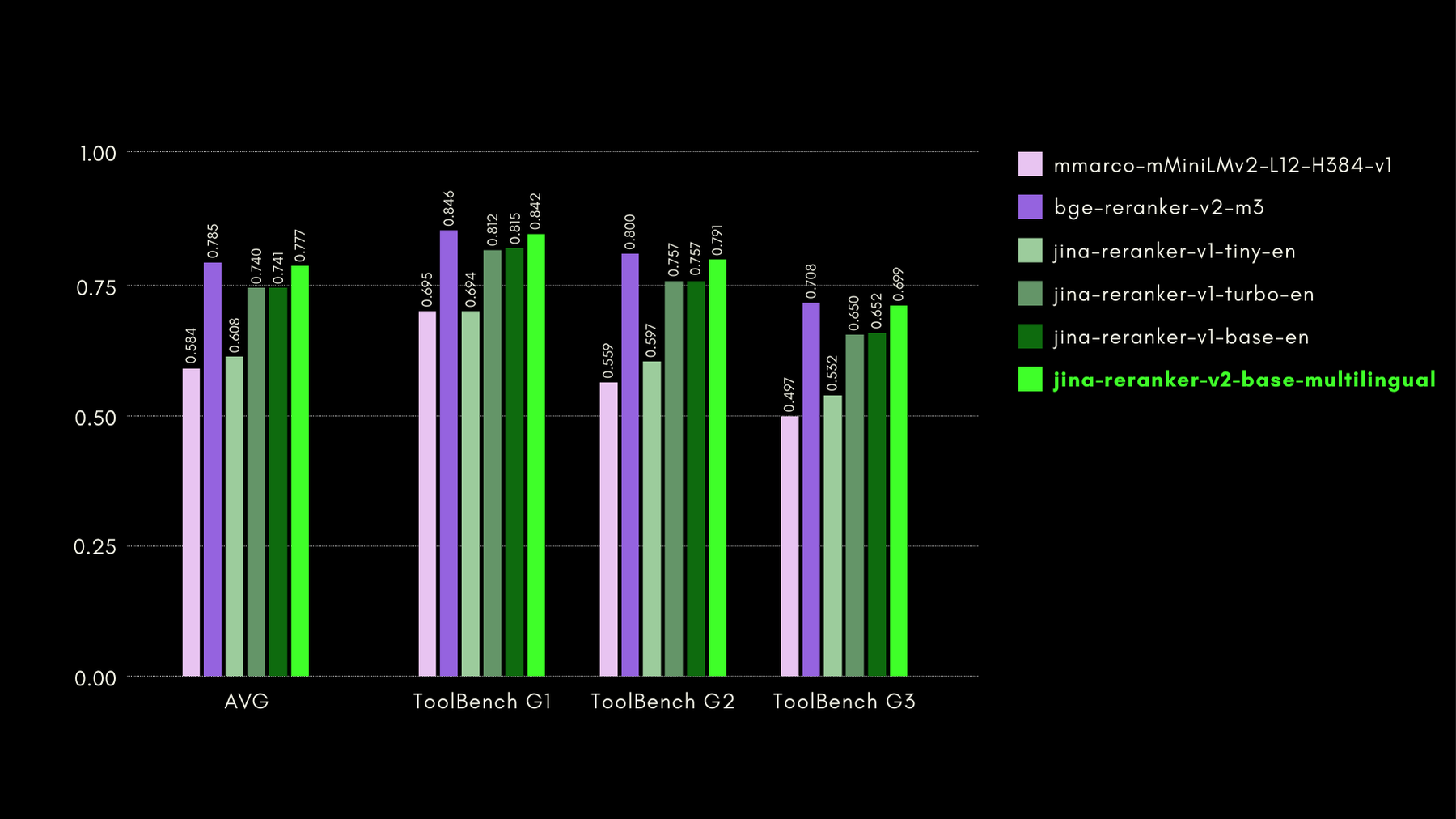
Как мы также покажем в следующих разделах, практически эталонная производительность jina-reranker-v2-base-multilingual сочетается с преимуществом вдвое меньшего размера по сравнению с bge-reranker-v2-m3 и почти в 15 раз большей скоростью.
tagJina Reranker v2 для поиска кода
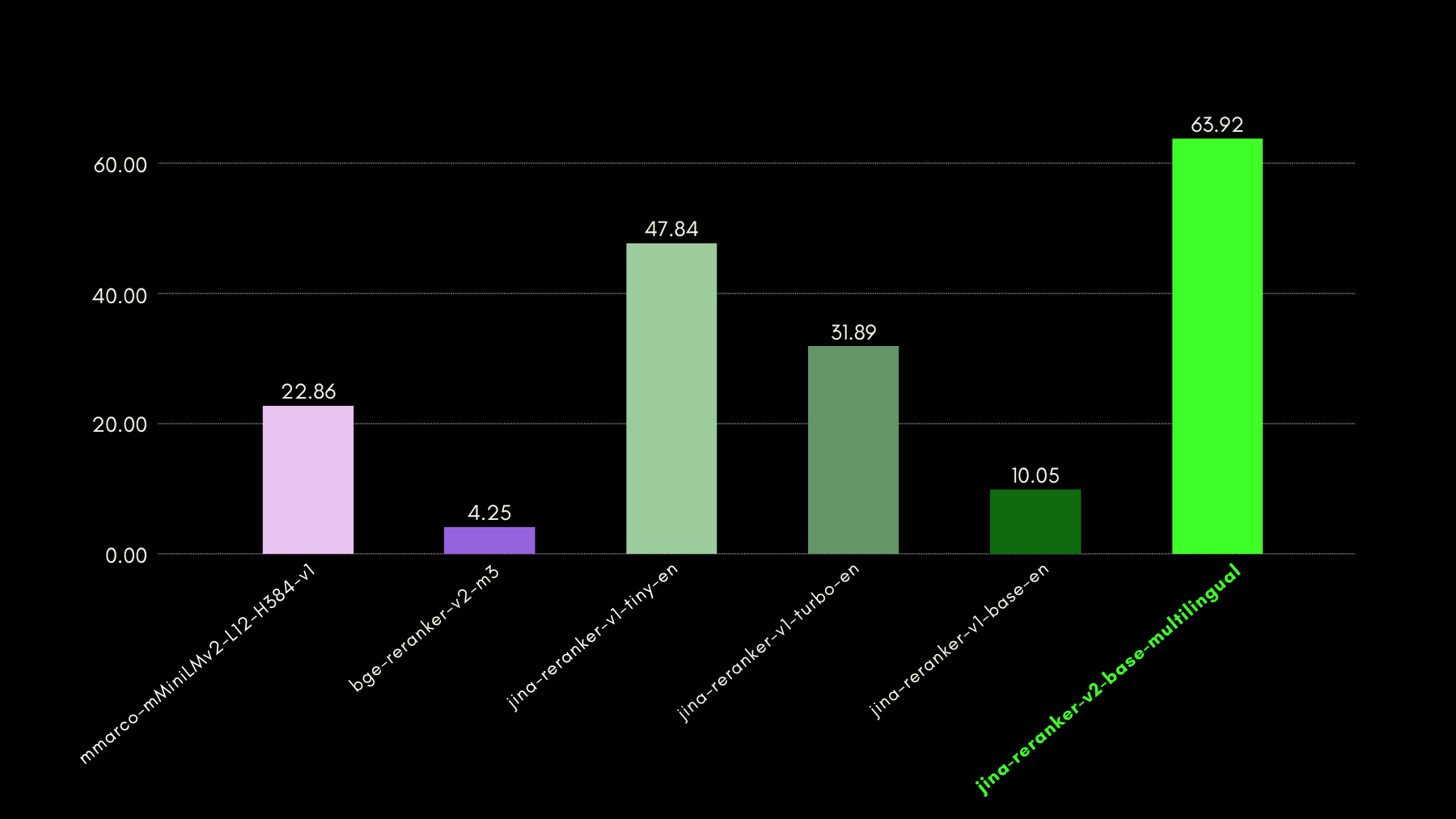
Jina Reranker v2, помимо обучения вызову функций и запросам структурированных данных, также улучшает поиск кода по сравнению с конкурирующими моделями аналогичного размера. Мы оценили его возможности поиска кода с помощью теста CodeSearchNet. Тест представляет собой комбинацию запросов в формате docstring и естественного языка с помеченными сегментами кода, релевантными запросам.
Вот результаты сравнения с другими моделями переранжирования по метрике MRR@10:
tagСверхбыстрый вывод с Jina Reranker v2
В то время как нейронные переранжировщики на основе кросс-энкодера отлично справляются с прогнозированием релевантности извлеченного документа, они работают медленнее, чем модели встраивания. А именно, сравнение запроса с n документами по одному намного медленнее, чем HNSW или любой другой метод быстрого поиска в большинстве векторных баз данных. Мы исправили эту медлительность в Jina Reranker v2.
- Наши уникальные подходы к обучению (описанные в следующем разделе) позволили нашей модели достичь эталонной производительности по точности с использованием всего 278 млн параметров. По сравнению, например, с
bge-reranker-v2-m3, имеющей 567 млн параметров, Jina Reranker v2 в два раза меньше. Это сокращение является первой причиной улучшенной пропускной способности (обработанных документов за 50 мс). - Даже при сопоставимом размере модели, Jina Reranker v2 обладает в 6 раз большей пропускной способностью по сравнению с нашей предыдущей передовой моделью Jina Reranker v1 для английского языка. Это связано с тем, что мы реализовали Jina Reranker v2 с использованием Flash Attention 2, который вводит оптимизации памяти и вычислений в слое внимания трансформер-моделей.
Вы можете увидеть результат вышеперечисленных шагов с точки зрения производительности Jina Reranker v2:
tagКак мы обучали Jina Reranker v2
Мы обучали jina-reranker-v2-base-multilingual в четыре этапа:
- Подготовка с английскими данными: Мы подготовили первую версию модели, обучив базовую модель только на англоязычных данных, включая пары (контрастное обучение) или триплеты (запрос, правильный ответ, неправильный ответ), пары запрос-схема функции и пары запрос-схема таблицы.
- Добавление межъязыковых данных: На следующем этапе мы добавили межъязыковые пары и триплеты наборов данных, чтобы улучшить многоязычные возможности базовой модели конкретно для задач поиска.
- Добавление всех многоязычных данных: На этом этапе мы сосредоточили обучение в основном на том, чтобы модель увидела максимально возможное количество наших данных. Мы дообучили контрольную точку модели со второго этапа всеми наборами данных пар и триплетов более чем на 100 языках с низкими и высокими ресурсами.
- Тонкая настройка с использованием добытых сложных негативных примеров: После наблюдения за производительностью переранжирования на третьем этапе мы выполнили тонкую настройку модели, добавив больше данных триплетов со специально подобранными примерами сложных негативных примеров для существующих запросов - ответов, которые поверхностно кажутся релевантными запросу, но на самом деле являются неправильными.
Такой четырехэтапный подход к обучению был основан на понимании того, что включение функций и табличных схем в процесс обучения как можно раньше позволило модели быть особенно осведомленной об этих случаях использования и научиться фокусироваться на семантике кандидатских документов больше, чем на языковых конструкциях.
tagJina Reranker v2 на практике
tagЧерез наш API Reranker
Самый быстрый и простой способ начать работу с Jina Reranker v2 - использовать API Jina Reranker.
Перейдите в раздел API на этой странице, чтобы интегрировать jina-reranker-v2-base-multilingual с использованием выбранного вами языка программирования.
Пример 1: Ранжирование вызовов функций
Чтобы ранжировать наиболее релевантные внешние функции/инструменты, отформатируйте запрос и документы (схемы функций), как показано ниже:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "I am planning a road trip from Berlin to Munich in my Volkswagen VII. Can you calculate the carbon footprint of this trip?",
"documents": [
"{'\''Name'\'': '\''getWeather'\'', '\''Specification'\'': '\''Provides current weather information for a specified city'\'', '\''spec'\'': '\''https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}'\'', '\''example'\'': '\''https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateDistance'\'', '\''Specification'\'': '\''Calculates the driving distance and time between multiple locations'\'', '\''spec'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}'\'', '\''example'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateCarbonFootprint'\'', '\''Specification'\'': '\''Estimates the carbon footprint for various activities, including transportation'\'', '\''spec'\'': '\''https://www.carboninterface.com/api/v1/estimates'\'', '\''example'\'': '\''{type: vehicle, distance: distance, vehicle_model_id: car}'\''}"
]
}'Не забудьте заменить <YOUR JINA AI TOKEN HERE> на ваш личный токен API Reranker
Вы должны получить:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 383,
"prompt_tokens": 383
},
"results": [
{
"index": 2,
"document": {
"text": "{'Name': 'calculateCarbonFootprint', 'Specification': 'Estimates the carbon footprint for various activities, including transportation', 'spec': 'https://www.carboninterface.com/api/v1/estimates', 'example': '{type: vehicle, distance: distance, vehicle_model_id: car}'}"
},
"relevance_score": 0.5422876477241516
},
{
"index": 1,
"document": {
"text": "{'Name': 'calculateDistance', 'Specification': 'Calculates the driving distance and time between multiple locations', 'spec': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}', 'example': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'}"
},
"relevance_score": 0.23283305764198303
},
{
"index": 0,
"document": {
"text": "{'Name': 'getWeather', 'Specification': 'Provides current weather information for a specified city', 'spec': 'https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}', 'example': 'https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'}"
},
"relevance_score": 0.05033063143491745
}
]
}Пример 2: Ранжирование SQL-запросов
Аналогично, чтобы получить оценки релевантности для структурированных схем таблиц для вашего запроса, вы можете использовать следующий пример API-вызова:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "which customers bought a summer outfit in the past 7 days?",
"documents": [
"CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));",
"CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));",
"CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));",
"CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
]
}'Ожидаемый ответ:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 253,
"prompt_tokens": 253
},
"results": [
{
"index": 2,
"document": {
"text": "CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));"
},
"relevance_score": 0.2789437472820282
},
{
"index": 0,
"document": {
"text": "CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));"
},
"relevance_score": 0.06477169692516327
},
{
"index": 3,
"document": {
"text": "CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
},
"relevance_score": 0.027742892503738403
},
{
"index": 1,
"document": {
"text": "CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));"
},
"relevance_score": 0.025516605004668236
}
]
}tagЧерез фреймворки RAG/LLM
Существующие интеграции Jina Reranker с фреймворками оркестрации LLM и RAG должны работать из коробки при использовании имени модели jina-reranker-v2-base-multilingual. Обратитесь к соответствующим страницам документации, чтобы узнать больше об интеграции Jina Reranker v2 в ваши приложения.
- Haystack от deepset: Jina Reranker v2 можно использовать с классом JinaRanker в Haystack:
from haystack import Document
from haystack_integrations.components.rankers.jina import JinaRanker
docs = [Document(content="Paris"), Document(content="Berlin")]
ranker = JinaRanker(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>")
ranker.run(query="City in France", documents=docs, top_k=1)
- LlamaIndex: Jina Reranker v2 можно использовать как модуль JinaRerank node postprocessor, инициализировав его:
import os
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>", top_n=1)
- Langchain: Используйте интеграцию Jina Rerank для использования Jina Reranker 2 в вашем существующем приложении. Модуль JinaRerank должен быть инициализирован с правильным именем модели:
from langchain_community.document_compressors import JinaRerank
reranker = JinaRerank(model="jina-reranker-v2-base-multilingual", jina_api_key="<YOUR JINA AI API KEY HERE>")
tagЧерез HuggingFace
Мы также открываем доступ (под лицензией CC-BY-NC-4.0) к модели jina-reranker-v2-base-multilingual на Hugging Face для исследовательских и оценочных целей.

Чтобы загрузить и запустить модель с Hugging Face, установите библиотеки transformers и einops:
pip install transformers einops
pip install ninja
pip install flash-attn --no-build-isolation
Войдите в свою учетную запись Hugging Face через CLI Hugging Face, используя ваш токен доступа Hugging Face:
huggingface-cli login --token <"HF-Access-Token">
Загрузите предварительно обученную модель:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(
'jinaai/jina-reranker-v2-base-multilingual',
torch_dtype="auto",
trust_remote_code=True,
)
model.to('cuda') # или 'cpu', если GPU недоступен
model.eval()
Определите запрос и документы для переранжирования:
query = "Organic skincare products for sensitive skin"
documents = [
"Organic skincare for sensitive skin with aloe vera and chamomile.",
"New makeup trends focus on bold colors and innovative techniques",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille",
"Neue Make-up-Trends setzen auf kräftige Farben und innovative Techniken",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla",
"Las nuevas tendencias de maquillaje se centran en colores vivos y técnicas innovadoras",
"针对敏感肌专门设计的天然有机护肤产品",
"新的化妆趋势注重鲜艳的颜色和创新的技巧",
"敏感肌のために特別に設計された天然有機スキンケア製品",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています",
]
Создайте пары предложений и вычислите оценки релевантности:
sentence_pairs = [[query, doc] for doc in documents]
scores = model.compute_score(sentence_pairs, max_length=1024)
Оценки будут списком чисел с плавающей точкой, где каждое число представляет оценку релевантности соответствующего документа к запросу. Более высокие оценки означают большую релевантность.
В качестве альтернативы используйте функцию rerank для переранжирования больших текстов путем автоматического разбиения запроса и документов на основе max_query_length и
max_length соответственно. Каждый фрагмент оценивается отдельно, а затем оценки каждого фрагмента объединяются для получения итоговых результатов переранжирования:results = model.rerank(
query,
documents,
max_query_length=512,
max_length=1024,
top_n=3
)
Эта функция возвращает не только оценку релевантности для каждого документа, но также их содержимое и позицию в исходном списке документов.
tagЧерез развертывание в частном облаке
Готовые пакеты для частного развертывания Jina Reranker v2 в учетных записях AWS и Azure скоро можно будет найти на наших страницах продавца в AWS Marketplace и Azure Marketplace соответственно.
tagКлючевые особенности Jina Reranker v2
Jina Reranker v2 представляет собой важное расширение возможностей для поисковой основы:
- Современный поиск с использованием кросс-кодирования открывает широкий спектр новых областей применения.
- Улучшенная многоязычная и межъязыковая функциональность устраняет языковые барьеры в ваших сценариях использования.
- Лучшая в своем классе поддержка вызова функций вместе с пониманием структурированных запросов данных выводит ваши возможности агентного RAG на новый уровень точности.
- Улучшенное извлечение компьютерного кода и данных в компьютерном формате выходит далеко за рамки простого поиска текстовой информации.
- Значительно более высокая пропускная способность документов гарантирует, что независимо от метода поиска, вы теперь можете быстрее переранжировать больше найденных документов и переложить большую часть детальных расчетов релевантности на jina-reranker-v2-base-multilingual.
Системы RAG становятся намного точнее с Reranker v2, помогая вашим существующим решениям по управлению информацией получать больше и лучше действенных результатов. Поддержка межъязыкового взаимодействия делает все это непосредственно доступным для многонациональных и многоязычных предприятий, с простым в использовании API по доступной цене.
Тестируя его с помощью эталонных тестов, основанных на реальных сценариях использования, вы можете сами убедиться, как Jina Reranker v2 поддерживает современную производительность в задачах, релевантных для реальных бизнес-моделей, все в одной модели ИИ, снижая ваши затраты и упрощая технологический стек.




