


Новое! Часть II: глубокое погружение в граничные сигналы и заблуждения.
Около года назад, в октябре 2023 года, мы выпустили первую в мире модель embedding с открытым исходным кодом с контекстной длиной 8K, jina-embeddings-v2-base-en. С тех пор ведутся дискуссии о полезности длинного контекста в embedding-моделях. Для многих приложений кодирование документа длиной в тысячи слов в единое embedding-представление не является идеальным. Многие сценарии использования требуют извлечения меньших частей текста, и системы поиска на основе плотных векторов часто работают лучше с меньшими текстовыми сегментами, так как семантика с меньшей вероятностью будет "переупакована" в векторах embedding.
Retrieval-Augmented Generation (RAG) является одним из наиболее известных приложений, требующих разделения документов на меньшие текстовые чанки (скажем, в пределах 512 токенов). Эти чанки обычно хранятся в векторной базе данных с векторными представлениями, сгенерированными моделью текстового embedding. Во время выполнения та же модель embedding кодирует запрос в векторное представление, которое затем используется для идентификации релевантных сохраненных текстовых чанков. Эти чанки впоследствии передаются большой языковой модели (LLM), которая синтезирует ответ на запрос на основе извлеченных текстов.

Короче говоря, embedding меньших чанков кажется более предпочтительным, отчасти из-за ограниченных размеров входных данных последующих LLM, а также потому что существует опасение, что важная контекстная информация в длинном контексте может быть разбавлена при сжатии в единый вектор.
Но если индустрии нужны только модели embedding с контекстной длиной 512, в чем смысл обучения моделей с контекстной длиной 8192?
В этой статье мы пересматриваем этот важный, хотя и неудобный вопрос, исследуя ограничения наивного конвейера разбиения на чанки и embedding в RAG. Мы представляем новый подход, называемый "Late Chunking", который использует богатую контекстную информацию, предоставляемую моделями embedding с длиной 8192, для более эффективного embedding чанков.
tagПроблема потерянного контекста
Простой конвейер RAG (разбиение на чанки-embedding-извлечение-генерация) не лишен проблем. В частности, этот процесс может разрушить зависимости дальнего контекста. Другими словами, когда релевантная информация распределена между несколькими чанками, извлечение текстовых сегментов из контекста может сделать их неэффективными, что делает этот подход особенно проблематичным.
На изображении ниже статья из Википедии разбита на чанки по предложениям. Можно видеть, что фразы вроде "его" и "город" ссылаются на "Берлин", который упоминается только в первом предложении. Это затрудняет для модели embedding связывание этих ссылок с правильной сущностью, тем самым создавая векторное представление более низкого качества.

Это означает, что если мы разделим длинную статью на чанки длиной в предложение, как в примере выше, система RAG может испытывать трудности с ответом на запрос вроде "Какое население Берлина?" Поскольку название города и население никогда не появляются вместе в одном чанке, и без более широкого контекста документа, LLM, представленная одним из этих чанков, не может разрешить анафорические ссылки вроде "он" или "город".
Существуют некоторые эвристики для смягчения этой проблемы, такие как повторная выборка с скользящим окном, использование нескольких длин контекстных окон и выполнение многопроходного сканирования документа. Однако, как и все эвристики, эти подходы работают как повезет; они могут работать в некоторых случаях, но нет теоретической гарантии их эффективности.
tagРешение: Late Chunking
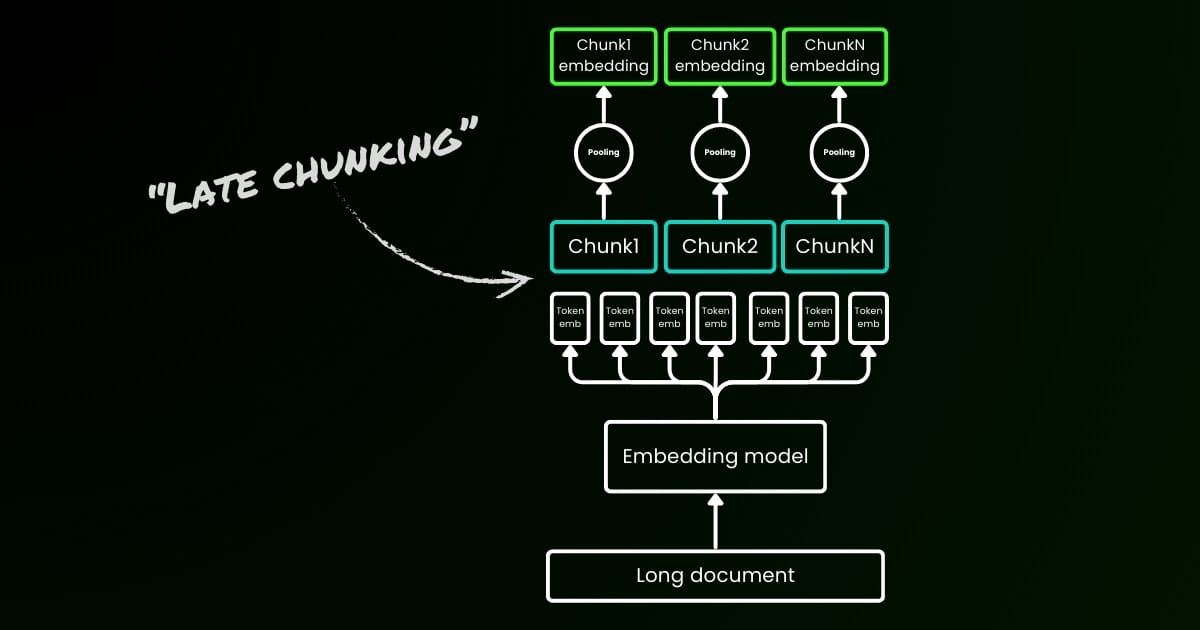
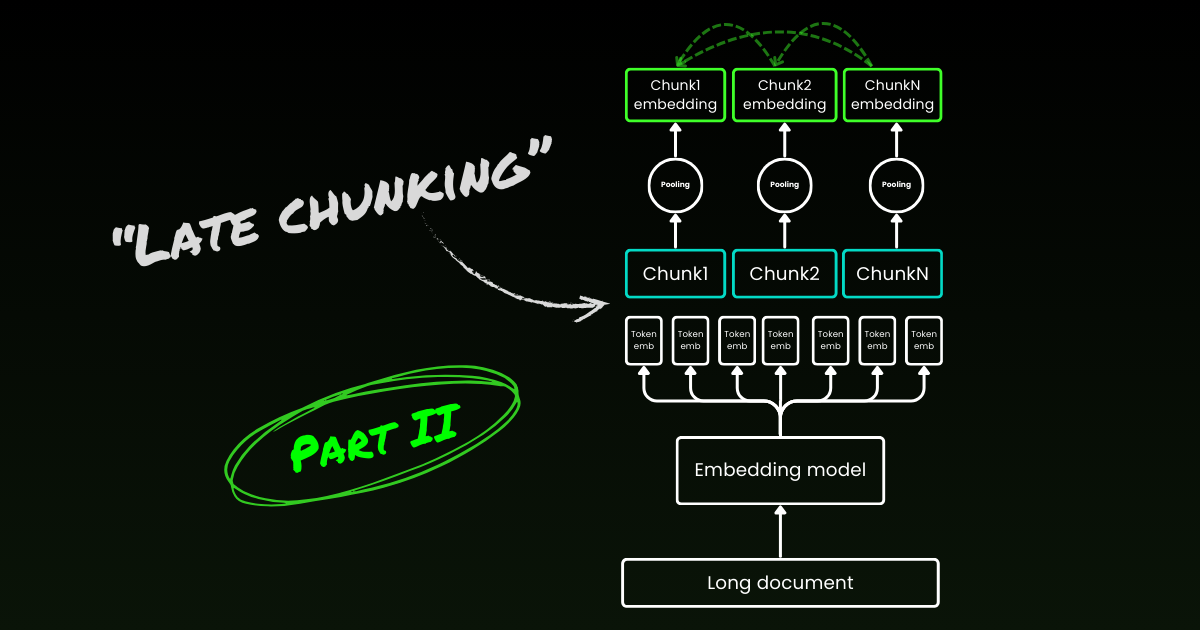
Наивный подход к кодированию (как видно в левой части изображения ниже) включает использование предложений, абзацев или максимальных ограничений длины для разделения текста a priori. После этого модель embedding многократно применяется к полученным чанкам. Для генерации единого embedding для каждого чанка многие модели embedding используют mean pooling на этих токен-уровневых embedding для вывода единого вектора embedding.

Напротив, подход "Late Chunking", который мы предлагаем в этой статье, сначала применяет трансформерный слой модели embedding к всему тексту или к максимально возможной его части. Это генерирует последовательность векторных представлений для каждого токена, которая охватывает текстовую информацию из всего текста. Затем mean pooling применяется к каждому чанку этой последовательности токен-векторов, создавая embedding для каждого чанка, которые учитывают контекст всего текста. В отличие от наивного подхода к кодированию, который генерирует независимые и одинаково распределенные (i.i.d.) embedding чанков, late chunking создает набор embedding чанков, где каждый "обусловлен" предыдущими, тем самым кодируя больше контекстной информации для каждого чанка.
Очевидно, что для эффективного применения late chunking нам нужны модели embedding с длинным контекстом, такие как jina-embeddings-v2-base-en, которые поддерживают до 8192 токенов—примерно десять стандартных страниц текста. Текстовые сегменты такого размера с меньшей вероятностью будут иметь контекстные зависимости, требующие еще более длинного контекста для разрешения.
Важно подчеркнуть, что late chunking все еще требует граничных сигналов, но эти сигналы используются только после получения токен-уровневых embedding—отсюда термин "late" в его названии.
| Naive Chunking | Late Chunking | |
|---|---|---|
| The need of boundary cues | Yes | Yes |
| The use of boundary cues | Directly in preprocessing | After getting the token-level embeddings from the transformer layer |
| The resulting chunk embeddings | i.i.d. | Conditional |
| Contextual information of nearby chunks | Lost. Some heuristics (like overlap sampling) to alleviate this | Well-preserved by long-context embedding models |
tagРеализация и качественная оценка


Реализацию late chunking можно найти в Google Colab по ссылке выше. Здесь мы используем наш недавно выпущенный функционал в API Tokenizer, который использует все возможные граничные сигналы для сегментации длинного документа на осмысленные чанки. Более подробное обсуждение алгоритма, лежащего в основе этой функции, можно найти в X.

При применении позднего разбиения на примере из Википедии выше вы можете сразу увидеть улучшение семантического сходства. Например, в случае со словами "город" и "Берлин" в статье Википедии, векторы, представляющие "город", теперь содержат информацию, связывающую его с предыдущим упоминанием "Берлина", что делает его гораздо лучшим соответствием для запросов, связанных с этим названием города.
| Query | Chunk | Sim. on naive chunking | Sim. on late chunking |
|---|---|---|---|
| Berlin | Berlin is the capital and largest city of Germany, both by area and by population. | 0.849 | 0.850 |
| Berlin | Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. | 0.708 | 0.825 |
| Berlin | The city is also one of the states of Germany, and is the third smallest state in the country in terms of area. | 0.753 | 0.850 |
Вы можете наблюдать это в численных результатах выше, которые сравнивают эмбеддинг термина "Berlin" с различными предложениями из статьи о Берлине, используя косинусное сходство. Столбец "Sim. on IID chunk embeddings" показывает значения сходства между эмбеддингом запроса "Berlin" и эмбеддингами с использованием предварительного разбиения, в то время как "Sim. under contextual chunk embedding" представляет результаты с методом позднего разбиения.
tagКоличественная оценка на BEIR
Чтобы проверить эффективность позднего разбиения за пределами простого примера, мы протестировали его с использованием некоторых тестов поиска из BeIR. Эти задачи поиска состоят из набора запросов, корпуса текстовых документов и файла QRels, который хранит информацию об ID документов, релевантных каждому запросу.
Чтобы определить релевантные документы для запроса, документы разбиваются на фрагменты, кодируются в индекс эмбеддингов, и для каждого эмбеддинга запроса определяются наиболее похожие фрагменты с помощью k-ближайших соседей (kNN). Поскольку каждый фрагмент соответствует документу, ранжирование kNN фрагментов можно преобразовать в ранжирование kNN документов (сохраняя только первое вхождение для документов, появляющихся в ранжировании несколько раз). Затем это полученное ранжирование сравнивается с ранжированием, предоставленным эталонным файлом QRels, и вычисляются метрики поиска, такие как nDCG@10. Эта процедура показана ниже, а скрипт оценки можно найти в этом репозитории для воспроизводимости.
 jina-ai
jina-aiМы провели эту оценку на различных наборах данных BeIR, сравнивая наивное разбиение с нашим методом позднего разбиения. Для получения граничных подсказок мы использовали regex, который разделяет тексты на строки примерно по 256 токенов. И наивная, и поздняя оценка разбиения использовали jina-embeddings-v2-small-en в качестве модели эмбеддинга; уменьшенную версию модели v2-base-en, которая все еще поддерживает длину до 8192 токенов. Результаты можно найти в таблице ниже.
| Dataset | Avg. Document Length (characters) | Naive Chunking (nDCG@10) | Late Chunking (nDCG@10) | No Chunking (nDCG@10) |
|---|---|---|---|---|
| SciFact | 1498.4 | 64.20% | 66.10% | 63.89% |
| TRECCOVID | 1116.7 | 63.36% | 64.70% | 65.18% |
| FiQA2018 | 767.2 | 33.25% | 33.84% | 33.43% |
| NFCorpus | 1589.8 | 23.46% | 29.98% | 30.40% |
| Quora | 62.2 | 87.19% | 87.19% | 87.19% |
Во всех случаях позднее разбиение улучшило показатели по сравнению с наивным подходом. В некоторых случаях оно также превзошло кодирование всего документа в единый эмбеддинг, в то время как в других наборах данных отсутствие разбиения вообще давало лучшие результаты (Конечно, отсутствие разбиения имеет смысл только если нет необходимости ранжировать фрагменты, что на практике встречается редко). Если построить график разницы в производительности между наивным подходом и поздним разбиением в зависимости от длины документа, становится очевидным, что средняя длина документов коррелирует с большими улучшениями в показателях nDCG через позднее разбиение. Другими словами, чем длиннее документ, тем эффективнее становится стратегия позднего разбиения.

tagЗаключение
В этой статье мы представили простой подход, называемый "поздним разбиением", для встраивания коротких фрагментов с использованием возможностей моделей эмбеддинга с длинным контекстом. Мы продемонстрировали, как традиционное встраивание i.i.d. фрагментов не сохраняет контекстную информацию, что приводит к субоптимальному поиску; и как позднее разбиение предлагает простое, но высокоэффективное решение для сохранения и обусловливания контекстной информации внутри каждого фрагмента. Эффективность позднего разбиения становится все более значительной на более длинных документах — возможность, которая стала доступной только благодаря продвинутым моделям эмбеддинга с длинным контекстом, таким как jina-embeddings-v2-base-en. Мы надеемся, что эта работа не только подтверждает важность моделей эмбеддинга с длинным контекстом, но и вдохновляет на дальнейшие исследования в этой области.
Продолжайте чтение части II: глубокое погружение в граничные подсказки и заблуждения.
