


tagКраткие выводы
- V3 - это новая модель, поэтому при переходе с v2 вам нужно будет переиндексировать все ваши документы. Эмбеддинги v3 нельзя использовать для поиска по эмбеддингам v2 и наоборот.
- V3 превосходит v2 в 96% случаев, при этом v2 иногда соответствует или немного превосходит v3 в задачах суммаризации на английском языке. Учитывая продвинутые возможности v3 и многоязычную поддержку, в большинстве случаев она должна быть вашим предпочтительным выбором вместо v2.
- V3 вводит три новых параметра API:
task,dimensionsиlate_chunking. Для лучшего понимания этих параметров ознакомьтесь с разделом в нашем блоге. - По умолчанию V3 выдает 1024-мерные векторы, по сравнению с 768-мерными в v2. Благодаря матрёшечному обучению теперь в v3 можно выбирать произвольную размерность выходных данных. Параметр
dimensionsпозволяет балансировать между объемом хранилища и производительностью при минимальных затратах, выбирая предпочтительный размер эмбеддинга. - Если у вас есть проект, построенный на API v2, и вы только меняете название модели на jina-embeddings-v3, ваш проект может не работать, потому что размерность по умолчанию теперь 1024. Вы можете установить
dimensions=768, если хотите сохранить ту же структуру данных или размер, что и в v2. Однако даже при одинаковых размерностях эмбеддинги V3 и V2 не взаимозаменяемы. - Двуязычные модели V2 (
v2-base-de,v2-base-es,v2-base-zh) устарели - v3 изначально многоязычна и поддерживает 89 языков. V3 также в определенной степени поддерживает кросс-языковые задачи. - Однако модель для программного кода v2 jina-embeddings-v2-base-code остается нашей лучшей для задач кодирования. В нашем бенчмарке v2 набирает 0.7753, в то время как общий эмбеддинг v3 (без установленного
task) набирает 0.7537, а неопубликованный code LoRA адаптер v3 набирает 0.7564. Это делает v2 примерно на 2.8% лучше, чем v3 для задач кодирования. - API V3 генерирует достойные общие эмбеддинги, когда
taskне установлен. Однако мы настоятельно рекомендуем устанавливатьtaskдля получения более качественных эмбеддингов, специфичных для задачи. - Чтобы имитировать поведение v2 в v3, используйте
task="text-matching", а не оставляйтеtaskнеустановленным. Но мы настоятельно рекомендуем исследовать различные варианты задач вместо использованияtext-matchingкак универсального решения. - Если вы используете v2 для поиска информации, переключитесь на типы задач поиска v3 (
retrieval.passageиretrieval.query) для получения лучших результатов. - Если вы работаете над совершенно новым типом задачи (что очень редко, и мы хотели бы узнать больше о вашей задаче), попробуйте начать с
task=None. - Если вы использовали трюк с перефразированием меток в v2 для задач zero-shot классификации, рассмотрите возможность просто установить
task="classification"в v3 и попробовать без перефразирования меток. Это потому, что v3 имеет оптимизированные эмбеддинги для задач классификации, поэтому теоретически перефразирование меток больше не нужно. - Хотя и v2, и v3 поддерживают до 8192 токенов в длине контекста, v3 справляется с этим гораздо эффективнее, как видно из бенчмарка ниже. Это также обеспечивает более прочную основу для применения "позднего разбиения" в v3.

- API V3 добавляет "позднее разбиение", классную функцию для получения контекстуальных эмбеддингов чанков с использованием длины 8192 токена, что приводит к более релевантным результатам поиска. Обратите внимание, что
late_chunkingподдерживается только API, а не при локальном запуске модели. - Когда включен
late_chunking, общее количество токенов в пакетеinputограничено 8192. Это ограничение гарантирует, что входные данные помещаются в контекстную длину v3 за один раз, что критически важно для сохранения контекстуальных эмбеддингов чанков. - По скорости v3 должна быть быстрее или как минимум соответствовать скорости v2, даже несмотря на то, что размер параметров в 3 раза больше. Это благодаря реализации FlashAttention2, используемой в v3. Однако не все GPU поддерживают это, поэтому v3 также работает без FA2 – в этом случае она может быть немного медленнее v2. Имейте в виду, что использование v3 через наш API может включать задержки сети, ограничения скорости и проблемы с зонами доступности, поэтому задержка там не является точным отражением истинной производительности v3.
- В отличие от v2, v3 находится под лицензией с открытым исходным кодом CC BY-NC 4.0. Её можно использовать в коммерческих целях через наш API, AWS или Azure, как указано ниже. Исследовательское и некоммерческое использование также разрешено. Для коммерческого использования на месте свяжитесь с нашей командой продаж для получения разрешения и лицензирования.


tagПодробное рассмотрение с примерами
tagПрощай, двуязычные модели, привет, многоязычность
На момент написания Embeddings v3 является лучшей многоязычной моделью и занимает второе место в рейтинге MTEB для английского языка среди моделей с менее чем миллиардом параметров. Она поддерживает 89 языков, с исключительной производительностью в 30 из них, включая арабский, бенгальский, китайский, датский, голландский, английский, финский, французский, грузинский, немецкий, греческий, хинди, индонезийский, итальянский, японский, корейский, латышский, норвежский, польский, португальский, румынский, русский, словацкий, испанский, шведский, тайский, турецкий, украинский, урду и вьетнамский.
Если вы использовали английскую, англо-немецкую, англо-испанскую или англо-китайскую модель v2, теперь вы можете просто перейти на единую модель v3, изменив параметр model и выбрав тип задачи:
# v2 English-German
data = {
"model": "jina-embeddings-v2-base-de",
"input": [
"The Force will be with you. Always.",
"Die Macht wird mit dir sein. Immer.",
"The ability to destroy a planet is insignificant next to the power of the Force.",
"Die Fähigkeit, einen Planeten zu zerstören, ist nichts im Vergleich zur Macht der Macht."
]
}
late_chunking определяет, будет ли модель обрабатывать весь документ целиком перед его разделением на фрагменты, сохраняя больше контекста в длинных текстах. С точки зрения пользователя, форматы ввода и вывода остаются прежними, но значения эмбеддингов будут отражать контекст всего документа, а не вычисляться независимо для каждого фрагмента.- При использовании
late_chunking=Trueобщее количество токенов (суммарно по всем фрагментам вinput) в одном запросе ограничено 8192 — максимальной длиной контекста для v3. - При использовании
late_chunking=Falseэто ограничение по токенам не применяется, и общее количество токенов ограничено только лимитом запросов API эмбеддингов.
Чтобы включить позднюю фрагментацию, передайте late_chunking=True в вызовах API.
Преимущество поздней фрагментации можно увидеть при поиске в истории чата:
history = [
"Sita, have you decided where you'd like to go for dinner this Saturday for your birthday?",
"I'm not sure. I'm not too familiar with the restaurants in this area.",
"We could always check out some recommendations online.",
"That sounds great. Let's do that!",
"What type of food are you in the mood for on your special day?",
"I really love Mexican or Italian cuisine.",
"How about this place, Bella Italia? It looks nice.",
"Oh, I've heard of that! Everyone says it's fantastic!",
"Shall we go ahead and book a table there then?",
"Yes, I think that would be a perfect choice! Let's call and reserve a spot."
]
Если мы спросим What's a good restaurant? с Embeddings v2, результаты не очень релевантны:
| Document | Cosine Similarity |
|---|---|
| I'm not sure. I'm not too familiar with the restaurants in this area. | 0.7675 |
| I really love Mexican or Italian cuisine. | 0.7561 |
| How about this place, Bella Italia? It looks nice. | 0.7268 |
| What type of food are you in the mood for on your special day? | 0.7217 |
| Sita, have you decided where you'd like to go for dinner this Saturday for your birthday? | 0.7186 |
С v3 без поздней фрагментации мы получаем похожие результаты:
| Document | Cosine Similarity |
|---|---|
| I'm not sure. I'm not too familiar with the restaurants in this area. | 0.4005 |
| I really love Mexican or Italian cuisine. | 0.3752 |
| Sita, have you decided where you'd like to go for dinner this Saturday for your birthday? | 0.3330 |
| How about this place, Bella Italia? It looks nice. | 0.3143 |
| Yes, I think that would be a perfect choice! Let's call and reserve a spot. | 0.2615 |
Однако мы видим заметное улучшение производительности при использовании v3 и поздней фрагментации, где наиболее релевантный результат (хороший ресторан) находится на первом месте:
| Document | Cosine Similarity |
|---|---|
| How about this place, Bella Italia? It looks nice. | 0.5061 |
| Oh, I've heard of that! Everyone says it's fantastic! | 0.4498 |
| I really love Mexican or Italian cuisine. | 0.4373 |
| What type of food are you in the mood for on your special day? | 0.4355 |
| Yes, I think that would be a perfect choice! Let's call and reserve a spot. | 0.4328 |
Как видите, даже несмотря на то, что в лучшем совпадении вообще не упоминается слово "ресторан", поздняя фрагментация сохраняет исходный контекст и представляет его как правильный ответ. Она кодирует "ресторан" в название ресторана "Bella Italia", поскольку видит его значение в более широком тексте.
tagБаланс эффективности и производительности с Matryoshka Embeddings
Параметр dimensions в Embeddings v3 дает возможность сбалансировать эффективность хранения и производительность при минимальных затратах. Matryoshka embeddings v3 позволяют усекать векторы, создаваемые моделью, уменьшая размерности настолько, насколько это необходимо, сохраняя при этом полезную информацию. Меньшие эмбеддинги идеально подходят для экономии места в векторных базах данных и повышения скорости поиска. Вы можете оценить влияние на производительность в зависимости от того, насколько уменьшены размерности:
data = {
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 768, # 1024 by default
"input": [
"The Force will be with you. Always.",
"力量与你同在。永远。",
"La Forza sarà con te. Sempre.",
"フォースと共にあらんことを。いつも。"
]
}
response = requests.post(url, headers=headers, json=data)
tagFAQ
tagЯ уже разбиваю свои документы на фрагменты перед генерацией эмбеддингов. Дает ли поздняя фрагментация какие-либо преимущества перед моей системой?
Поздняя фрагментация имеет преимущества перед предварительной фрагментацией, поскольку сначала обрабатывает весь документ целиком, сохраняя важные контекстные связи в тексте перед его разделением на фрагменты. Это приводит к созданию более контекстно-богатых эмбеддингов, что может повысить точность поиска, особенно в сложных или длинных документах. Кроме того, поздняя фрагментация может помочь получить более релевантные ответы при поиске, поскольку модель имеет целостное понимание документа перед его сегментацией. Это приводит к лучшей общей производительности по сравнению с предварительной фрагментацией, где фрагменты обрабатываются независимо без полного контекста.
tagПочему v2 лучше справляется с классификацией пар, чем v3, и стоит ли беспокоиться?
Причина, по которой модели v2-base-(zh/es/de) показывают лучшие результаты в классификации пар (PC), в основном связана с тем, как рассчитывается средний балл. В v2 для оценки производительности PC учитывается только китайский язык, где модель embeddings-v2-base-zh показывает отличные результаты, что приводит к более высокому среднему баллу. Бенчмарки v3 включают четыре языка: китайский, французский, польский и русский. В результате общий балл кажется ниже по сравнению с оценкой v2 только для китайского языка. Однако v3 по-прежнему соответствует или превосходит такие модели, как multilingual-e5, по всем языкам для задач PC. Этот более широкий охват объясняет кажущуюся разницу, и снижение производительности не должно вызывать беспокойства, особенно для многоязычных приложений, где v3 остается очень конкурентоспособной.
tagДействительно ли v3 превосходит билингвальные модели v2 для конкретных языков?
При сравнении v3 с билингвальными моделями v2 разница в производительности зависит от конкретных языков и задач.
Билингвальные модели v2 были сильно оптимизированы для своих языков. В результате в бенчмарках для этих конкретных языков, например, в классификации пар (PC) на китайском языке, v2 может показывать лучшие результаты. Это связано с тем, что дизайн embeddings-v2-base-zh был специально адаптирован для этого языка, позволяя ей отлично справляться в этой узкой области.
Однако v3 разработана для более широкой многоязычной поддержки, обрабатывая 89 языков и будучи оптимизированной для различных задач с помощью специфических LoRA адаптеров. Это означает, что хотя v3 не всегда может превзойти v2 в каждой отдельной задаче для конкретного языка (как PC для китайского), она, как правило, работает лучше в целом при оценке по нескольким языкам или в более сложных, специфических для задачи сценариях, таких как поиск и классификация.
Для многоязычных задач или при работе с несколькими языками v3 предлагает более сбалансированное и комплексное решение, используя лучшую генерализацию между языками. Однако для очень специфичных языковых задач, где билингвальная модель была тонко настроена, v2 может сохранять преимущество.
На практике выбор правильной модели зависит от конкретных потребностей вашей задачи. Если вы работаете только с определенным языком, для которого была оптимизирована v2, вы все еще можете получить конкурентоспособные результаты с v2. Но для более общих или многоязычных приложений v3, вероятно, является лучшим выбором благодаря своей универсальности и более широкой оптимизации.
tagПочему v2 лучше справляется с суммаризацией, чем v3, и нужно ли об этом беспокоиться?
v2-base-en показывает лучшие результаты в суммаризации (SM), поскольку ее архитектура была оптимизирована для таких задач, как семантическое сходство, которое тесно связано с суммаризацией. В отличие от этого, v3 разработана для поддержки более широкого спектра задач, особенно в задачах поиска и классификации, и больше подходит для сложных и многоязычных сценариев.
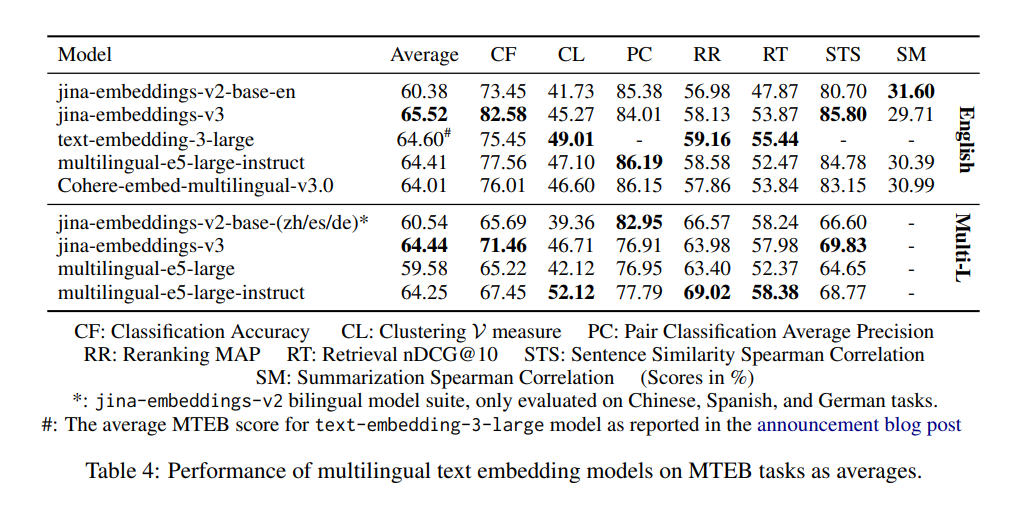
Однако эта разница в производительности SM не должна беспокоить большинство пользователей. Оценка SM основана всего на одной задаче суммаризации, SummEval, которая в основном измеряет семантическое сходство. Эта задача сама по себе не очень информативна или репрезентативна для более широких возможностей модели. Поскольку v3 превосходит в других критически важных областях, таких как поиск, вероятно, что разница в суммаризации не окажет значительного влияния на ваши реальные случаи использования.





