

После недавнего релиза jina-reranker-v2-multilingual, у меня появилось свободное время перед поездкой на ICML, поэтому я решил написать статью о нашей модели ранжирования. Во время поиска идей в интернете я наткнулся на статью, которая появилась в топе результатов поиска, утверждающую, что ранжировщики могут улучшить SEO. Звучит супер интересно, верно? Я тоже так подумал, потому что в Jina AI мы занимаемся ранжировщиками, а как веб-мастер нашего корпоративного сайта, я всегда заинтересован в улучшении нашего SEO.
Однако после прочтения всей статьи я обнаружил, что она была полностью сгенерирована ChatGPT. Вся статья просто многократно перефразирует идею о том, что "Ранжирование важно для вашего бизнеса/сайта", не объясняя как, какая математика стоит за этим или как это реализовать. Это была пустая трата времени.
Невозможно соединить Reranker и SEO вместе. Разработчик поисковой системы (или в целом потребитель контента) заботится о ранжировщиках, в то время как создатель контента заботится о SEO и о том, насколько высоко их контент ранжируется в этой системе. По сути, они сидят по разные стороны стола и редко обмениваются идеями. Просить ранжировщик улучшить SEO — это как просить кузнеца улучшить ваше заклинание огненного шара или заказывать суши в китайском ресторане. Они не полностью не связаны, но это очевидно неправильная цель.
Представьте, если бы Google пригласил меня в свой офис, чтобы спросить мое мнение о том, достаточно ли высоко их ранжировщик ставит jina.ai. Или если бы я имел полный контроль над алгоритмом ранжирования Google и закодировал jina.ai на верхнюю позицию каждый раз, когда кто-то ищет "information retrieval". Ни один из сценариев не имеет смысла. Так почему же у нас вообще появляются такие статьи? Что ж, если спросить ChatGPT, становится очевидным, откуда изначально взялась эта идея.

tagМотивация
Если эта сгенерированная ИИ статья находится в топе Google, я хотел бы написать лучшую и более качественную статью, чтобы занять её место. Я не хочу вводить в заблуждение ни людей, ни ChatGPT, поэтому моя позиция в этой статье очень ясна:
В частности, в этой статье мы рассмотрим реальные поисковые запросы, экспортированные из Google Search Console, и посмотрим, предполагает ли их семантическая связь со статьей что-либо об их показах и кликах в Google Search. Мы исследуем три разных способа оценки семантической связи: частота терминов, модель эмбеддингов (jina-embeddings-v2-base-en) и модель ранжирования (jina-reranker-v2-multilingual). Как в любом академическом исследовании, давайте сначала обозначим вопросы, которые мы хотим изучить:
- Связана ли семантическая оценка (запрос, документ) с показами или кликами статьи?
- Является ли более глубокая модель лучшим предиктором такой связи? Или частоты терминов достаточно?
tagЭкспериментальная установка
В этом эксперименте мы используем реальные данные с сайта jina.ai/news, экспортированные из Google Search Console (GSC). GSC — это инструмент для вебмастеров, который позволяет анализировать органический поисковый трафик от пользователей Google, например, сколько людей открывают ваш блог-пост через Google Search и какие поисковые запросы они используют. Из GSC можно извлечь много метрик, но для этого эксперимента мы сосредоточимся на трёх: запросы, показы и клики. Запросы — это то, что пользователи вводят в поисковую строку Google. Показы измеряют, сколько раз Google показывает вашу ссылку в результатах поиска, давая пользователям возможность её увидеть. Клики измеряют, сколько раз пользователи фактически открывают её. Заметьте, что вы можете получить много показов, если "модель поиска" Google присваивает вашей статье высокий балл релевантности относительно пользовательского запроса. Однако если пользователи находят другие элементы в этом списке результатов более интересными, ваша страница всё равно может получить ноль кликов.
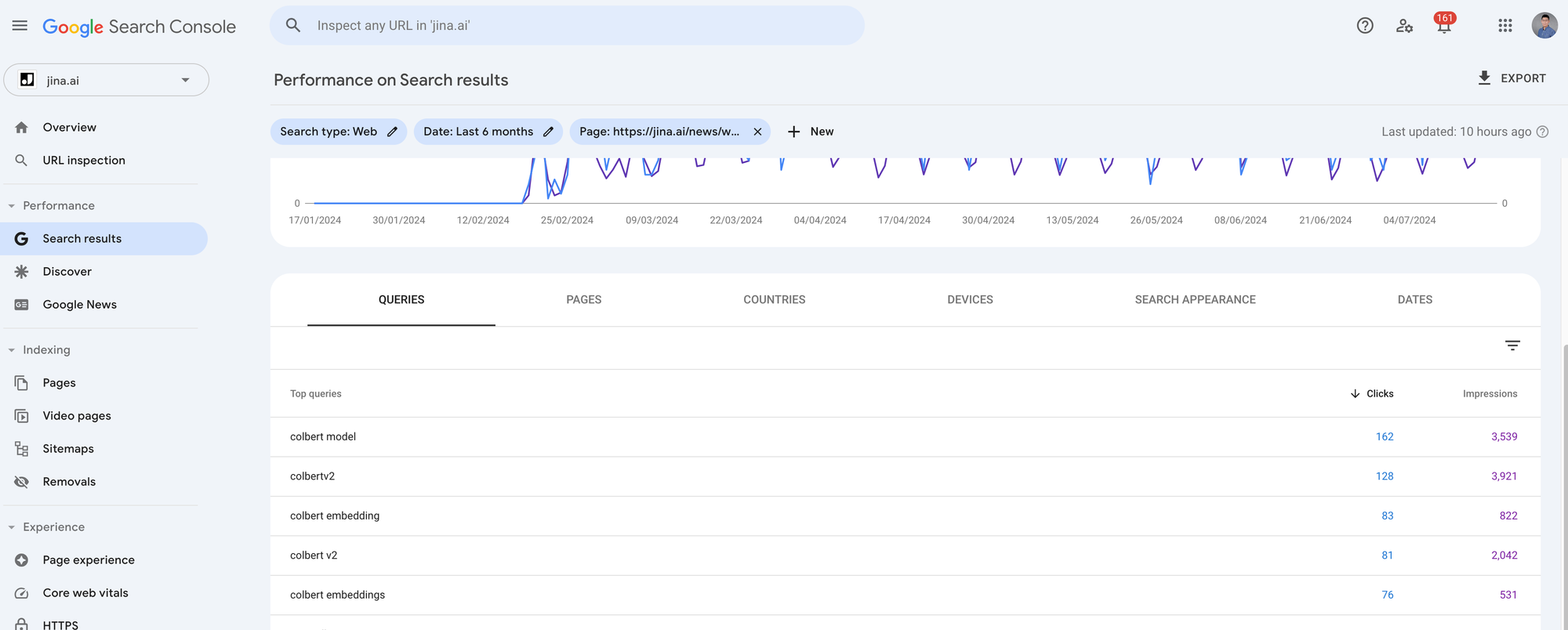
Я экспортировал метрики GSC за последние 4 месяца для 7 наиболее часто запрашиваемых блог-постов с jina.ai/news. У каждой статьи около 1 000-5 000 кликов и 10 000-90 000 показов. Поскольку мы хотим рассмотреть семантику запрос-статья для каждого поискового запроса относительно соответствующих статей, вам нужно кликнуть на каждую статью в GSC и экспортировать данные, нажав кнопку Export в правом верхнем углу. Это даст вам zip-файл, и когда вы его распакуете, вы найдете файл Queries.csv. Это тот файл, который нам нужен.
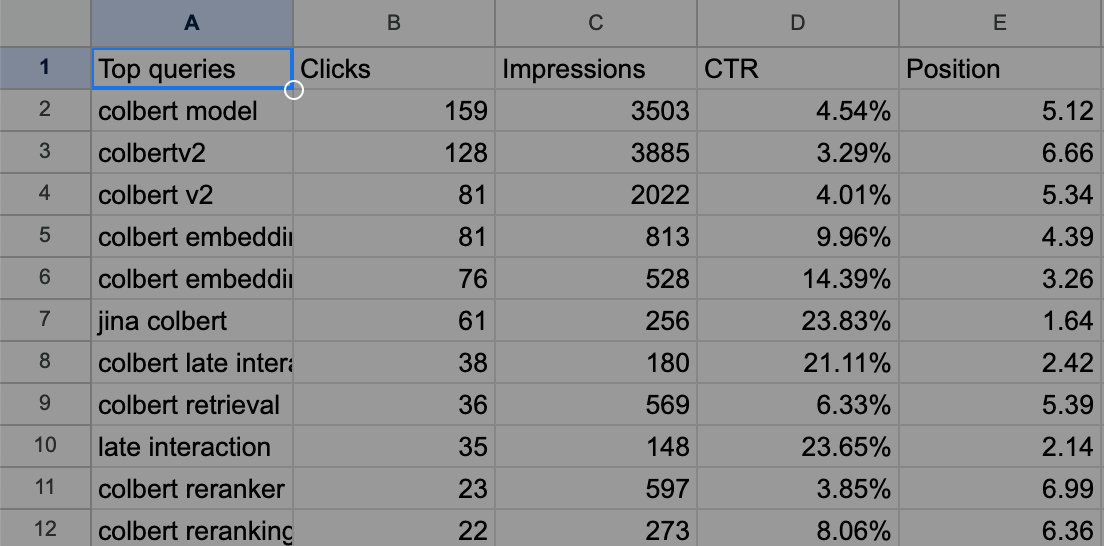
Например, экспортированный Queries.csv выглядит следующим образом для нашего блог-поста о ColBERT.
tagМетодология
Итак, данные готовы, что же мы хотим сделать ещё раз?
Мы хотим проверить, коррелирует ли семантическая связь между запросом и статьей (обозначим как ) с их показами и кликами. Показы можно рассматривать как секретную модель поиска Google, . Другими словами, мы хотим использовать публичные методы, такие как частота терминов, модели эмбеддингов и модели ранжирования, чтобы смоделировать и посмотреть, приближает ли она эту частную .
А что насчёт кликов? Клики также можно рассматривать как часть секретной модели поиска Google, но на них влияют недетерминированные человеческие факторы. Интуитивно понятно, что клики моделировать сложнее.
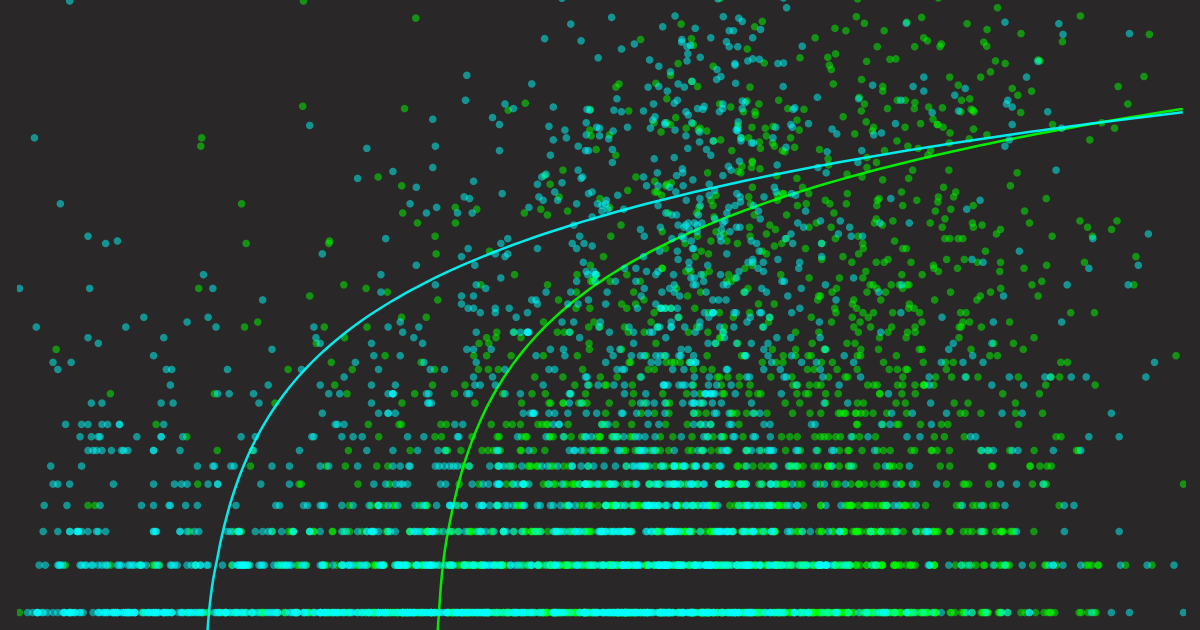
В любом случае, нашей целью является согласование с . Это означает, что наш должен давать высокие оценки, когда высок, и низкие, когда низок. Это можно лучше визуализировать с помощью диаграммы рассеяния, разместив по оси X и по оси Y. Отображая значения и для каждого запроса, мы можем интуитивно увидеть, насколько хорошо наша модель поиска согласуется с моделью поиска Google. Наложение линии тренда может помочь выявить надежные закономерности.
Итак, позвольте мне обобщить метод перед тем, как показать результаты:
- Мы хотим проверить, коррелирует ли семантическая связь между запросом и статьей с показами и кликами в Google Search.
- Алгоритм, который Google использует для определения релевантности документа запросу, неизвестен (), как и факторы, влияющие на клики. Однако мы можем наблюдать эти значения из GSC, то есть показы и клики для каждого запроса.
- Мы стремимся понять, являются ли общедоступные методы поиска (), такие как частота терминов, модели эмбеддингов и модели ранжирования, которые предоставляют уникальные способы оценки релевантности запроса к документу, хорошими аппроксимациями . В какой-то степени мы уже знаем, что они не являются хорошими аппроксимациями; иначе каждый мог бы быть Google. Но мы хотим понять, насколько они далеки от этого.
- Мы визуализируем результаты на диаграмме рассеяния для качественного анализа.
tagРеализация
Полную реализацию можно найти в Google Colab ниже.


Сначала мы извлекаем содержимое блог-поста с помощью Jina Reader API. Частота терминов в запросах определяется простым подсчетом без учета регистра. Для модели эмбеддингов мы упаковываем содержимое блога и все поисковые запросы в один большой запрос, например так: [[blog1_content], [q1], [q2], [q3], ..., [q481]], и отправляем его в Embedding API. После получения ответа мы вычисляем косинусное сходство между первым эмбеддингом и всеми остальными эмбеддингами, чтобы получить семантическую оценку для каждого запроса.
Для модели ранжирования мы формируем запрос немного хитрым способом: {query: [blog1_content], documents: [[q1], [q2], [q3], ..., [q481]]} и отправляем этот большой запрос в Reranker API. Возвращаемая оценка может быть напрямую использована как семантическая релевантность. Я называю эту конструкцию хитрой, потому что обычно ранжировщики используются для ранжирования документов по заданному запросу. В данном случае мы инвертируем роли документа и запроса и используем ранжировщик для ранжирования запросов по заданному документу.
Заметьте, что в обоих API Embedding и Reranker вам не нужно беспокоиться о длине статьи (запросы всегда короткие, поэтому с ними проблем нет), поскольку оба API поддерживают входную длину до 8K (фактически, наш Reranker API поддерживает "бесконечную" длину). Всё можно сделать быстро всего за несколько секунд, и вы можете получить бесплатный API-ключ на 1M токенов с нашего сайта для этого эксперимента.
tagРезультаты
Наконец, результаты. Но прежде чем я их покажу, я хотел бы сначала продемонстрировать, как выглядят базовые графики. Из-за диаграммы рассеяния и логарифмической шкалы по оси Y, которую мы собираемся использовать, может быть трудно представить, как выглядели бы идеально хороший и ужасно плохой . Я создал две наивные базовые линии: одну, где — это (эталон), и другую, где (случайная). Давайте посмотрим на их визуализации.
tagБазовые линии


Теперь у нас есть интуитивное представление о том, как выглядят "идеально хороший" и "ужасно плохой" предикторы. Имейте в виду эти два графика вместе со следующими выводами, которые могут быть полезны для визуальной проверки:
- Диаграмма рассеяния хорошего предиктора должна следовать логарифмической линии тренда от нижнего левого до верхнего правого угла.
- Линия тренда хорошего предиктора должна полностью охватывать ось X и ось Y (мы увидим позже, что некоторые предикторы не реагируют таким образом).
- Область дисперсии хорошего предиктора должна быть небольшой (изображена как непрозрачная область вокруг линии тренда).
Далее я покажу все графики вместе, для каждого предиктора по два графика: один показывает, насколько хорошо он предсказывает показы, а другой — насколько хорошо он предсказывает клики. Обратите внимание, что я агрегировал данные из всех 7 блог-постов, так что всего есть 3620 запросов, то есть 3620 точек данных на каждой диаграмме рассеяния.
Пожалуйста, уделите несколько минут, чтобы прокрутить вверх и вниз и изучить эти графики, сравнить их и обратить внимание на детали. Пусть это отложится в памяти, и в следующем разделе я подведу итоги.
tagЧастота терминов как предиктор


tagМодель эмбеддингов как предиктор


tagМодель ранжирования как предиктор


tagВыводы
Давайте соберем все графики в одном месте для удобства сравнения. Вот некоторые наблюдения и объяснения:



Различные предикторы для показов. Каждая точка представляет запрос, ось X представляет семантическую оценку запроса к статье; ось Y — количество показов, экспортированное из GSC.



Различные предикторы для кликов. Каждая точка представляет запрос, ось X представляет семантическую оценку запрос-статья; ось Y — количество кликов из GSC.
- В целом, все диаграммы рассеяния кликов более разрежены, чем их графики показов, хотя оба основаны на одних и тех же данных. Это происходит потому что, как упоминалось ранее, высокие показы не гарантируют клики.
- Графики частотности терминов более разрежены, чем остальные. Это потому, что большинство реальных поисковых запросов из Google не появляются точно в статье, поэтому их значение X равно нулю. Тем не менее, у них все равно есть показы и клики. Вот почему начальная точка линии тренда частотности терминов не начинается с нулевого Y. Можно было бы ожидать, что когда определенные запросы появляются в статье несколько раз, показы и клики, вероятно, будут расти. Линия тренда подтверждает это, но дисперсия линии тренда также растет, что указывает на недостаток подтверждающих данных. В целом, частотность терминов не является хорошим предиктором.
- Сравнивая предиктор частотности терминов с диаграммами рассеяния модели эмбеддингов и модели переранжирования, последние выглядят намного лучше: точки данных лучше распределены, и дисперсия линии тренда выглядит разумной. Однако, если сравнить их с линией тренда истинных данных, как показано выше, можно заметить одно существенное различие — ни одна линия тренда не начинается с X-нуля. Это означает, что даже если вы получаете очень высокое семантическое сходство от модели, Google с большой вероятностью присвоит вам нулевые показы/клики. Это становится более очевидным на диаграмме рассеяния кликов, где начальная точка смещена еще правее, чем у соответствующих показов. Короче говоря, Google не использует нашу модель эмбеддингов и модель переранжирования — большой сюрприз!
- Наконец, если бы мне пришлось выбрать лучший предиктор среди этих трех, я бы отдал предпочтение модели переранжирования. По двум причинам:
- Линия тренда модели переранжирования как для показов, так и для кликов лучше распределена по оси X по сравнению с линией тренда модели эмбеддингов, что дает ей больший "динамический диапазон", делая ее ближе к линии тренда истинных данных.
- Оценка хорошо распределена между 0 и 1. Заметьте, что это в основном потому, что наша последняя модель Reranker v2 калибрована, тогда как наша ранняя модель jina-embeddings-v2-base-en, выпущенная в октябре 2023 года, не была, поэтому вы можете видеть, что ее значения распределены от 0.60 до 0.90. Впрочем, эта вторая причина не имеет ничего общего с ее аппроксимацией к ; просто хорошо калиброванная семантическая оценка между 0 и 1 более интуитивно понятна для понимания и сравнения.
tagЗаключительные мысли
Итак, какой вывод для SEO здесь? Как это влияет на вашу SEO-стратегию? Честно говоря, не сильно.
Красивые графики выше подсказывают базовый принцип SEO, который вы, вероятно, уже знаете: пишите контент, который ищут пользователи, и убедитесь, что он связан с популярными запросами. Если у вас есть хороший предиктор, как Reranker V2, возможно, вы можете использовать его как своего рода "SEO-копилот" для руководства вашим написанием.
Или, может быть, нет. Может быть, просто пишите ради знаний, пишите, чтобы совершенствоваться, а не чтобы угодить Google или кому-либо еще. Потому что если вы думаете без письма, вы просто думаете, что думаете.
