




В апреле 2024 года мы выпустили Jina Reader — простой API, который преобразует любой URL в дружественный для LLM markdown с помощью простого префикса: r.jina.ai. Несмотря на сложное сетевое программирование за кулисами, основная часть "чтения" довольно проста. Сначала мы используем безголовый браузер Chrome для получения исходного кода веб-страницы. Затем мы используем пакет Mozilla Readability для извлечения основного содержимого, удаляя такие элементы, как заголовки, нижние колонтитулы, панели навигации и боковые панели. Наконец, мы преобразуем очищенный HTML в markdown с помощью regex и библиотеки Turndown. Результатом является хорошо структурированный markdown-файл, готовый к использованию LLM для обоснования, обобщения и рассуждения.
В первые несколько недель после выпуска Jina Reader мы получили много отзывов, особенно касательно качества контента. Некоторые пользователи находили его слишком подробным, в то время как другие считали его недостаточно детальным. Также были сообщения о том, что фильтр Readability удалял неправильный контент или что Turndown испытывал трудности с преобразованием определенных частей HTML в markdown. К счастью, многие из этих проблем были успешно решены путем исправления существующего конвейера новыми регулярными выражениями или эвристиками.
С тех пор мы задаемся одним вопросом: вместо того, чтобы исправлять это большим количеством эвристик и регулярных выражений (что становится все сложнее поддерживать и не является мультиязычным), можем ли мы решить эту проблему end-to-end с помощью языковой модели?
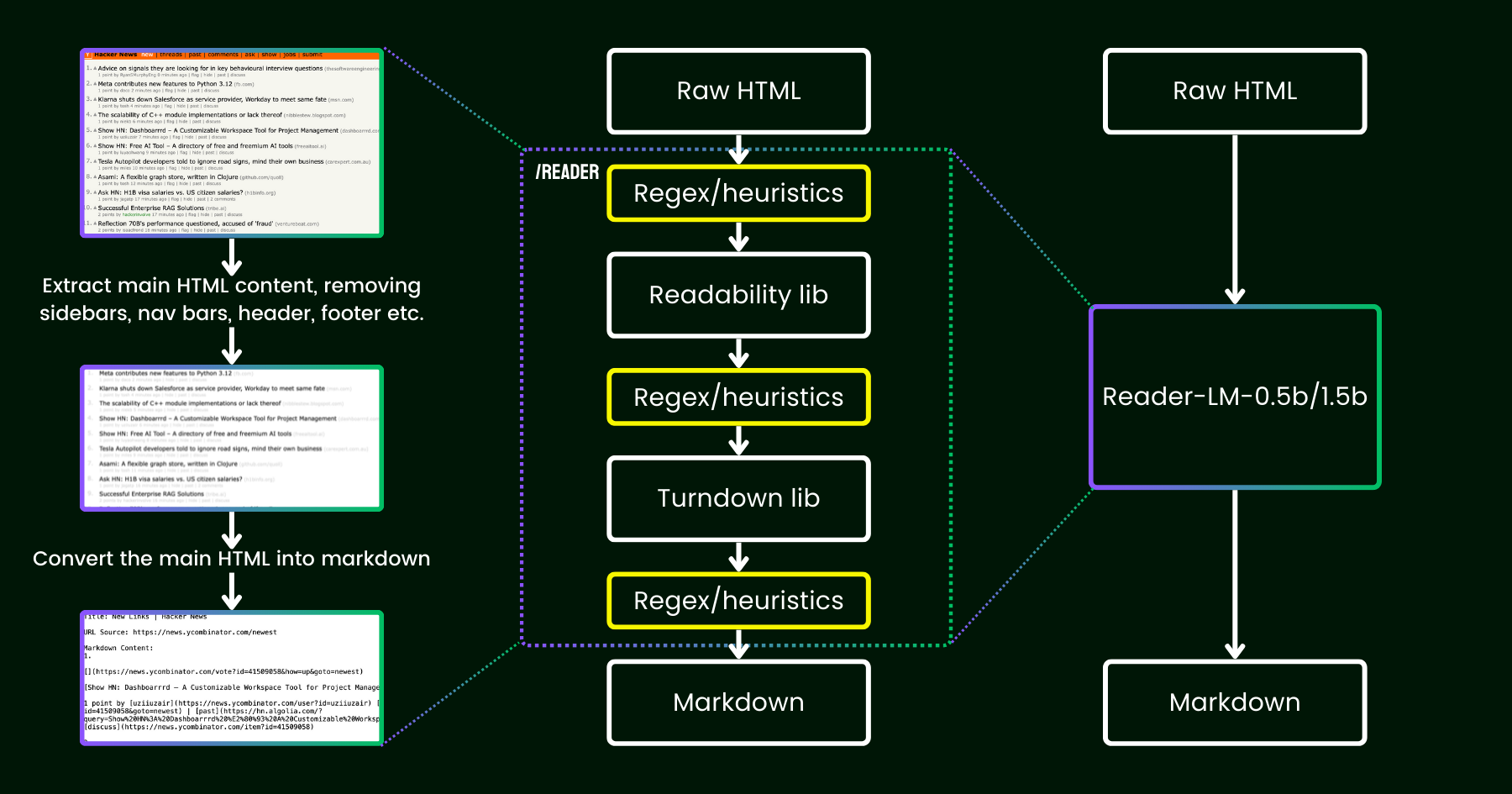
reader-lm, заменяющая конвейер readability+turndown+regex эвристики с помощью маленькой языковой модели.На первый взгляд, использование LLM для очистки данных может показаться избыточным из-за их низкой экономической эффективности и меньшей скорости. Но что, если мы рассмотрим маленькую языковую модель (SLM) — с менее чем 1 миллиардом параметров, которая может эффективно работать на периферии? Это звучит гораздо привлекательнее, верно? Но действительно ли это осуществимо или это просто мечты? Согласно закону масштабирования, меньшее количество параметров обычно приводит к снижению способностей рассуждения и обобщения. Поэтому SLM может даже испытывать трудности с генерацией какого-либо осмысленного содержания, если размер её параметров слишком мал. Давайте подробнее рассмотрим задачу преобразования HTML в Markdown:
- Во-первых, рассматриваемая задача не такая творческая или сложная, как типичные задачи LLM. В случае преобразования HTML в markdown модели в основном нужно выборочно копировать из входных данных в выходные (т.е. пропускать HTML-разметку, боковые панели, заголовки, нижние колонтитулы), с минимальными усилиями на генерацию нового содержания (в основном вставка markdown-синтаксиса). Это резко контрастирует с более широкими задачами, которые решают LLM, такими как генерация стихов или написание кода, где выходные данные требуют гораздо больше творчества и не являются прямым копированием из входных данных. Это наблюдение предполагает, что SLM может работать, так как задача кажется проще, чем более общая генерация текста.
- Во-вторых, нам нужно приоритизировать поддержку длинного контекста. Современный HTML часто содержит гораздо больше шума, чем простая разметка
<div>. Встроенный CSS и скрипты могут легко раздуть код до сотен тысяч токенов. Чтобы SLM была практичной в этом сценарии, длина контекста должна быть достаточно большой. Длина токенов в 8K или 16K совсем не полезна.
Похоже, что нам нужна неглубокая, но широкая SLM. "Неглубокая" в том смысле, что задача в основном простое "копирование-вставка", поэтому требуется меньше transformer-блоков; и "широкая" в том смысле, что требуется поддержка длинного контекста, чтобы быть практичной, поэтому механизм внимания требует особого ухода. Предыдущие исследования показали, что длина контекста и способность к рассуждению тесно связаны. Для SLM крайне сложно оптимизировать оба измерения, сохраняя при этом малый размер параметров.
Сегодня мы рады анонсировать первую версию этого решения с выпуском reader-lm-0.5b и reader-lm-1.5b, двух SLM, специально обученных генерировать чистый markdown непосредственно из шумного исходного HTML. Обе модели являются многоязычными и поддерживают длину контекста до 256K токенов. Несмотря на компактный размер, эти модели достигают передовой производительности в этой задаче, превосходя более крупные LLM-аналоги, будучи при этом только 1/50 их размера.

Ниже приведены спецификации двух моделей:
| reader-lm-0.5b | reader-lm-1.5b | |
|---|---|---|
| # Parameters | 494M | 1.54B |
| Context length | 256K | 256K |
| Hidden Size | 896 | 1536 |
| # Layers | 24 | 28 |
| # Query Heads | 14 | 12 |
| # KV Heads | 2 | 2 |
| Head Size | 64 | 128 |
| Intermediate Size | 4864 | 8960 |
| Multilingual | Yes | Yes |
| HuggingFace Repo | Link | Link |
tagНачало работы с Reader-LM
tagВ Google Colab
Самый простой способ попробовать reader-lm — запустить наш блокнот Colab, где мы демонстрируем, как использовать reader-lm-1.5b для преобразования веб-сайта Hacker News в markdown. Блокнот оптимизирован для плавной работы на бесплатном уровне GPU T4 Google Colab. Вы также можете загрузить reader-lm-0.5b или изменить URL на любой веб-сайт и изучить результат. Обратите внимание, что входными данными (т.е. промптом) для модели является исходный HTML — никаких инструкций-префиксов не требуется.

Обратите внимание, что бесплатный GPU T4 имеет ограничения, которые могут препятствовать использованию продвинутых оптимизаций при выполнении модели. Функции, такие как bfloat16 и flash attention, недоступны на T4, что может привести к повышенному использованию VRAM и более медленной производительности для длинных входных данных. Для производственных сред мы рекомендуем использовать GPU высокого класса, такой как RTX 3090/4090, для значительно лучшей производительности.
tagВ производстве: Скоро доступно на Azure и AWS
Reader-LM доступен на Azure Marketplace и AWS SageMaker. Если вам нужно использовать эти модели за пределами этих платформ или локально в вашей компании, обратите внимание, что обе модели лицензированы под CC BY-NC 4.0. По вопросам коммерческого использования, пожалуйста, свяжитесь с нами.


tagТестирование производительности
Для количественной оценки производительности Reader-LM мы сравнили его с несколькими большими языковыми моделями, включая: GPT-4o, Gemini-1.5-Flash, Gemini-1.5-Pro, LLaMA-3.1-70B, Qwen2-7B-Instruct.
Модели оценивались по следующим метрикам:
- ROUGE-L (чем выше, тем лучше): Эта метрика, широко используемая для задач суммаризации и ответов на вопросы, измеряет перекрытие между предсказанным выводом и эталоном на уровне n-грамм.
- Token Error Rate (TER, чем ниже, тем лучше): Эта метрика вычисляет долю сгенерированных markdown-токенов, которые не встречаются в исходном HTML-контенте. Мы разработали эту метрику для оценки уровня галлюцинаций модели, помогая нам выявлять случаи, когда модель производит контент, не обоснованный в HTML. Дальнейшие улучшения будут внесены на основе анализа конкретных случаев.
- Word Error Rate (WER, чем ниже, тем лучше): Обычно используемый в задачах OCR и ASR, WER учитывает последовательность слов и подсчитывает ошибки, такие как вставки (ADD), замены (SUB) и удаления (DEL). Эта метрика обеспечивает детальную оценку несоответствий между сгенерированным markdown и ожидаемым выводом.
Для использования LLM для этой задачи мы использовали следующую единообразную инструкцию в качестве префикса промпта:
Your task is to convert the content of the provided HTML file into the corresponding markdown file. You need to convert the structure, elements, and attributes of the HTML into equivalent representations in markdown format, ensuring that no important information is lost. The output should strictly be in markdown format, without any additional explanations.Результаты можно найти в таблице ниже.
| ROUGE-L | WER | TER | |
|---|---|---|---|
| reader-lm-0.5b | 0.56 | 3.28 | 0.34 |
| reader-lm-1.5b | 0.72 | 1.87 | 0.19 |
| gpt-4o | 0.43 | 5.88 | 0.50 |
| gemini-1.5-flash | 0.40 | 21.70 | 0.55 |
| gemini-1.5-pro | 0.42 | 3.16 | 0.48 |
| llama-3.1-70b | 0.40 | 9.87 | 0.50 |
| Qwen2-7B-Instruct | 0.23 | 2.45 | 0.70 |
tagКачественное исследование
Мы провели качественное исследование путем визуальной проверки выходного markdown. Мы отобрали 22 HTML-источника, включая новостные статьи, блог-посты, целевые страницы, страницы электронной коммерции и форумные посты на нескольких языках: английском, немецком, японском и китайском. Мы также включили Jina Reader API в качестве базового уровня, который опирается на регулярные выражения, эвристику и предопределенные правила.
Оценка фокусировалась на четырех ключевых аспектах вывода, каждая модель оценивалась по шкале от 1 (низший) до 5 (высший):
- Извлечение заголовков: Оценка того, насколько хорошо каждая модель идентифицирует и форматирует заголовки документа h1,h2,..., h6, используя правильный синтаксис markdown.
- Извлечение основного содержания: Оценка способности моделей точно конвертировать основной текст, сохраняя параграфы, форматирование списков и поддерживая согласованность представления.
- Сохранение богатой структуры: Анализ того, насколько эффективно каждая модель сохраняет общую структуру документа, включая заголовки, подзаголовки, маркированные списки и нумерованные списки.
- Использование синтаксиса Markdown: Оценка способности каждой модели правильно конвертировать HTML-элементы, такие как
<a>(ссылки),<strong>(жирный текст) и<em>(курсив) в их соответствующие эквиваленты markdown.
Результаты можно найти ниже.

Reader-LM-1.5B стабильно показывает хорошие результаты по всем параметрам, особенно выделяясь в сохранении структуры и использовании синтаксиса markdown. Хотя он не всегда превосходит Jina Reader API, его производительность конкурентоспособна с более крупными моделями, такими как Gemini 1.5 Pro, что делает его высокоэффективной альтернативой более крупным LLM. Reader-LM-0.5B, хотя и меньше, все еще обеспечивает солидную производительность, особенно в сохранении структуры.
tagКак мы обучали Reader-LM
tagПодготовка данных
Мы использовали Jina Reader API для генерации обучающих пар исходного HTML и соответствующего markdown. В ходе эксперимента мы обнаружили, что SLM особенно чувствительны к качеству обучающих данных. Поэтому мы создали конвейер данных, который обеспечивает включение в обучающий набор только высококачественных markdown-записей.
Кроме того, мы добавили некоторые синтетические HTML и их markdown-аналоги, сгенерированные с помощью GPT-4o. По сравнению с реальным HTML, синтетические данные, как правило, намного короче, с более простыми и предсказуемыми структурами, и значительно более низким уровнем шума.
Наконец, мы объединили HTML и markdown, используя шаблон чата. Окончательные обучающие данные форматированы следующим образом:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{{RAW_HTML}}<|im_end|>
<|im_start|>assistant
{{MARKDOWN}}<|im_end|>
Полный объем обучающих данных составляет 2,5 миллиарда токенов.
tagДвухэтапное обучение
Мы провели эксперименты с моделями различных размеров, начиная от 65M и 135M параметров и до 3B параметров. Спецификации для каждой модели можно найти в таблице ниже.
| reader-lm-65m | reader-lm-135m | reader-lm-360m | reader-lm-0.5b | reader-lm-1.5b | reader-lm-1.7b | reader-lm-3b | |
|---|---|---|---|---|---|---|---|
| Hidden Size | 512 | 576 | 960 | 896 | 1536 | 2048 | 3072 |
| # Layers | 8 | 30 | 32 | 24 | 28 | 24 | 32 |
| # Query Heads | 16 | 9 | 15 | 14 | 12 | 32 | 32 |
| # KV Heads | 8 | 3 | 5 | 2 | 2 | 32 | 32 |
| Head Size | 32 | 64 | 64 | 64 | 128 | 64 | 96 |
| Intermediate Size | 2048 | 1536 | 2560 | 4864 | 8960 | 8192 | 8192 |
| Attention Bias | False | False | False | True | True | False | False |
| Embedding Tying | False | True | True | True | True | True | False |
| Vocabulary Size | 32768 | 49152 | 49152 | 151646 | 151646 | 49152 | 32064 |
| Base Model | Lite-Oute-1-65M-Instruct | SmolLM-135M | SmolLM-360M-Instruct | Qwen2-0.5B-Instruct | Qwen2-1.5B-Instruct | SmolLM-1.7B | Phi-3-mini-128k-instruct |
Обучение модели проводилось в два этапа:
- Короткий и простой HTML: На этом этапе максимальная длина последовательности (HTML + markdown) была установлена на 32K токенов, с общим количеством 1,5 миллиарда обучающих токенов.
- Длинный и сложный HTML: длина последовательности была увеличена до 128K токенов, с 1,2 миллиардами обучающих токенов. Для этого этапа мы реализовали механизм zigzag-ring-attention из работы Zilin Zhu "Ring Flash Attention" (2024).
Поскольку обучающие данные включали последовательности длиной до 128K токенов, мы полагаем, что модель может без проблем поддерживать до 256K токенов. Однако обработка 512K токенов может быть проблематичной, так как расширение позиционных вложений RoPE в четыре раза относительно длины обучающей последовательности может привести к ухудшению производительности.
Для моделей с 65M и 135M параметров мы наблюдали, что они могли достичь разумного поведения "копирования", но только с короткими последовательностями (менее 1K токенов). С увеличением длины входных данных эти модели испытывали трудности с генерацией разумного вывода. Учитывая, что современный исходный код HTML легко может превышать 100K токенов, лимит в 1K токенов далеко не достаточен.
tagДегенерация и монотонные циклы
Одной из основных проблем, с которыми мы столкнулись, была дегенерация, особенно в форме повторений и зацикливания. После генерации некоторых токенов модель начинала многократно генерировать один и тот же токен или застревала в цикле, непрерывно повторяя короткую последовательность токенов до достижения максимально допустимой длины вывода.

Для решения этой проблемы:
- Мы применили контрастный поиск как метод декодирования и включили контрастные потери во время обучения. По нашим экспериментам, этот метод эффективно снизил повторяющуюся генерацию на практике.
- Мы реализовали простой критерий остановки повторений в конвейере transformer. Этот критерий автоматически определяет, когда модель начинает повторять токены, и останавливает декодирование на раннем этапе, чтобы избежать монотонных циклов. Эта идея была вдохновлена этим обсуждением.
tagЭффективность обучения на длинных входных данных
Чтобы снизить риск ошибок нехватки памяти (OOM) при обработке длинных входных данных, мы реализовали поблочную передачу модели. Этот подход кодирует длинный ввод меньшими фрагментами, уменьшая использование VRAM.
Мы улучшили реализацию упаковки данных в нашей обучающей структуре, которая основана на Transformers Trainer. Для оптимизации эффективности обучения несколько коротких текстов (например, 2K токенов) объединяются в одну длинную последовательность (например, 30K токенов), что позволяет проводить обучение без заполнения. Однако в исходной реализации некоторые короткие примеры разделялись на два подтекста и включались в разные длинные обучающие последовательности. В таких случаях второй подтекст терял свой контекст (например, исходное содержание HTML в нашем случае), что приводило к искажению обучающих данных. Это заставляет модель полагаться на свои параметры, а не на входной контекст, что, по нашему мнению, является основным источником галлюцинаций.
В итоге мы выбрали модели 0.5B и 1.5B для публикации. Модель 0.5B является наименьшей моделью, способной достичь желаемого поведения "выборочного копирования" на входных данных с длинным контекстом, в то время как модель 1.5B является наименьшей более крупной моделью, которая значительно улучшает производительность без достижения уменьшения отдачи по отношению к размеру параметров.
tagАльтернативная архитектура: модель только с энкодером
На ранних этапах этого проекта мы также исследовали использование архитектуры только с энкодером для решения этой задачи. Как упоминалось ранее, задача конвертации HTML в Markdown представляется в основном задачей "выборочного копирования". Учитывая обучающую пару (исходный HTML и markdown), мы можем пометить токены, существующие как во входных, так и в выходных данных, как 1, а остальные как 0. Это преобразует проблему в задачу классификации токенов, аналогичную той, что используется в распознавании именованных сущностей (NER).
Хотя этот подход казался логичным, он представлял значительные трудности на практике. Во-первых, исходный HTML из реальных источников крайне зашумлен и длинен, что делает метки 1 крайне разреженными и, следовательно, трудными для обучения модели. Во-вторых, кодирование специального синтаксиса markdown в схеме 0-1 оказалось проблематичным, поскольку символы вроде ## title, *bold* и | table | не существуют во входных данных исходного HTML. В-третьих, выходные токены не всегда строго следуют порядку входных данных. Часто происходит небольшое изменение порядка, особенно с таблицами и ссылками, что затрудняет представление такого поведения переупорядочивания в простой схеме 0-1. Переупорядочивание на короткие расстояния потенциально можно было бы обрабатывать с помощью динамического программирования или алгоритмов выравнивания-искажения, введя метки вроде -1, -2, +1, +2 для представления смещений расстояния, преобразуя задачу бинарной классификации в задачу многоклассовой классификации токенов.
Подводя итог, решение проблемы с архитектурой только с энкодером и рассмотрение её как задачи классификации токенов имеет свою привлекательность, особенно поскольку обучающие последовательности намного короче по сравнению с моделью только с декодером, что делает её более дружественной к VRAM. Однако основная проблема заключается в подготовке качественных обучающих данных. Когда мы осознали, что время и усилия, затраченные на предварительную обработку данных — использование динамического программирования и эвристик для создания идеальных последовательностей меток на уровне токенов — были чрезмерными, мы решили прекратить этот подход.
tagЗаключение
Reader-LM - это новая малая языковая модель (SLM), разработанная для извлечения и очистки данных в открытом интернете. Вдохновленные Jina Reader, мы стремились создать комплексное решение на основе языковой модели, способное преобразовывать необработанный, зашумленный HTML в чистый markdown. При этом мы сосредоточились на экономической эффективности, сохраняя небольшой размер модели, чтобы Reader-LM оставалась практичной и удобной в использовании. Это также первая декодер-only модель с длинным контекстом, обученная в Jina AI.
Хотя изначально задача может показаться простой проблемой "выборочного копирования", преобразование и очистка HTML в markdown далеко не просты. В частности, модель должна отлично справляться с позиционно-зависимыми рассуждениями на основе контекста, что требует большего размера параметров, особенно в скрытых слоях. Для сравнения, изучение синтаксиса markdown относительно просто.
В ходе наших экспериментов мы также обнаружили, что обучение SLM с нуля особенно сложно. Начало с предварительно обученной модели и продолжение обучения для конкретной задачи значительно повысило эффективность обучения. Все еще остается много возможностей для улучшения как эффективности, так и качества: расширение длины контекста, ускорение декодирования и добавление поддержки инструкций во входных данных, что позволило бы Reader-LM извлекать определенные части веб-страницы в markdown.
