


После интеграции Jina Embeddings в Deepset's Haystack 2.0 и выпуска Jina Reranker, мы рады сообщить, что Jina Reranker теперь также доступен через расширение Jina Haystack.


Haystack — это комплексный фреймворк, который сопровождает вас на каждом этапе жизненного цикла проекта GenAI. Независимо от того, хотите ли вы выполнять поиск документов, retrieval-augmented generation (RAG), ответы на вопросы или генерацию ответов, Haystack может объединять современные модели встраивания и LLM в пайплайны для создания комплексных NLP-приложений и решения ваших задач.
В этой статье мы покажем, как использовать их для создания собственной поисковой системы для тикетов Jira, чтобы оптимизировать рабочие процессы и больше никогда не тратить время на создание дубликатов задач.
Для этого руководства вам понадобится API-ключ Jina Reranker. Вы можете получить его с бесплатной пробной квотой в миллион токенов на сайте Jina Reranker.
tagПолучение тикетов поддержки Jira
Любая команда, работающая со сложным проектом, сталкивалась с разочарованием, когда нужно создать тикет, но неизвестно, существует ли уже тикет для этой проблемы.
В следующем руководстве мы покажем, как можно легко создать инструмент, используя Jina Reranker и пайплайны Haystack, который будет предлагать возможные дубликаты тикетов при создании нового.
- При вводе тикета, который нужно проверить на наличие дубликатов среди существующих тикетов, пайплайн сначала извлечет из базы данных все связанные проблемы.
- Затем он удалит исходный тикет из списка (если он уже существовал в базе данных) и любые дочерние тикеты (то есть тикеты, чей родительский ID соответствует исходному тикету).
- Окончательная выборка теперь включает только проблемы, которые могут охватывать ту же тему, что и исходный тикет, но не были отмечены как таковые в базе данных через их ID. Эти тикеты переранжируются для обеспечения максимальной релевантности и позволяют идентифицировать дубликаты записей в базе данных.
tagПолучение набора данных
Для реализации нашего решения мы выбрали все тикеты Jira со статусом "In-progress" для проекта Apache Zookeeper. Это сервис с открытым исходным кодом для координации процессов распределенных приложений.
Мы разместили тикеты в JSON-файле для удобства. Пожалуйста, скачайте файл в свое рабочее пространство.
tagНастройка предварительных требований
Для установки требований выполните:
pip install --q chromadb haystack-ai jina-haystack chroma-haystack
Чтобы ввести API-ключ, установите его как переменную окружения:
import os
import getpass
os.environ["JINA_API_KEY"] = getpass.getpass()
getpass.getpass() предложит вам ввести API-ключ под соответствующим блоком кода. Вы можете ввести ключ там и нажать enter, чтобы продолжить руководство. Если хотите, вы также можете заменить getpass.getpass() самим API-ключом.tagСоздание пайплайна индексации
Пайплайн индексации будет предварительно обрабатывать тикеты, преобразовывать их в векторы и сохранять. Мы будем использовать Chroma DocumentStore как нашу векторную базу данных для хранения векторных представлений через интеграцию Chroma Document Store Haystack.
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
document_store = ChromaDocumentStore()
Начнем с определения нашего пользовательского препроцессора данных, который будет учитывать только релевантные поля документа и удалять все пустые записи:
import json
from typing import List
from haystack import Document, component
relevant_keys = ['Summary', 'Issue key', 'Issue id', 'Parent id', 'Issue type', 'Status', 'Project lead', 'Priority', 'Assignee', 'Reporter', 'Creator', 'Created', 'Updated', 'Last Viewed', 'Due Date', 'Labels',
'Description', 'Comment', 'Comment__1', 'Comment__2', 'Comment__3', 'Comment__4', 'Comment__5', 'Comment__6', 'Comment__7', 'Comment__8', 'Comment__9', 'Comment__10', 'Comment__11', 'Comment__12',
'Comment__13', 'Comment__14', 'Comment__15']
@component
class RemoveKeys:
@component.output_types(documents=List[Document])
def run(self, file_name: str):
with open(file_name, 'r') as file:
tickets = json.load(file)
cleaned_tickets = []
for t in tickets:
t = {k: v for k, v in t.items() if k in relevant_keys and v}
cleaned_tickets.append(t)
return {'documents': cleaned_tickets}
Затем нам нужно создать пользовательский JSON конвертер для преобразования тикетов в объекты Document, которые может понимать Haystack:
@component
class JsonConverter:
@component.output_types(documents=List[Document])
def run(self, tickets: List[Document]):
tickets_documents = []
for t in tickets:
if 'Parent id' in t:
t = Document(content=json.dumps(t), meta={'Issue key': t['Issue key'], 'Issue id': t['Issue id'], 'Parent id': t['Parent id']})
else:
t = Document(content=json.dumps(t), meta={'Issue key': t['Issue key'], 'Issue id': t['Issue id'], 'Parent id': ''})
tickets_documents.append(t)
return {'documents': tickets_documents}
Наконец, мы встраиваем Documents и записываем эти представления в ChromaDocumentStore:
from haystack import Pipeline
from haystack.components.writers import DocumentWriter
from haystack_integrations.components.retrievers.chroma import ChromaEmbeddingRetriever
from haystack.document_stores.types import DuplicatePolicy
from haystack_integrations.components.embedders.jina import JinaDocumentEmbedder
retriever = ChromaEmbeddingRetriever(document_store=document_store)
retriever_reranker = ChromaEmbeddingRetriever(document_store=document_store)
indexing_pipeline = Pipeline()
indexing_pipeline.add_component('cleaner', RemoveKeys())
indexing_pipeline.add_component('converter', JsonConverter())
indexing_pipeline.add_component('embedder', JinaDocumentEmbedder(model='jina-embeddings-v2-base-en'))
indexing_pipeline.add_component('writer', DocumentWriter(document_store=document_store, policy=DuplicatePolicy.SKIP))
indexing_pipeline.connect('cleaner', 'converter')
indexing_pipeline.connect('converter', 'embedder')
indexing_pipeline.connect('embedder', 'writer')
indexing_pipeline.run({'cleaner': {'file_name': 'tickets.json'}})
Это должно создать индикатор прогресса и вывести краткий JSON, содержащий информацию о том, что было сохранено:
Calculating embeddings: 100%|██████████| 1/1 [00:01<00:00, 1.21s/it]
{'embedder': {'meta': {'model': 'jina-embeddings-v2-base-en',
'usage': {'total_tokens': 20067, 'prompt_tokens': 20067}}},
'writer': {'documents_written': 31}}tagСоздание конвейера запросов
Давайте создадим конвейер запросов, чтобы начать сравнивать тикеты. В Haystack 2.0 компоненты извлечения тесно связаны с DocumentStores. Если мы передадим хранилище документов в инициализированный ранее retriever, этот конвейер сможет получить доступ к созданным нами документам и передать их в компонент переранжирования. Затем компонент переранжирования сравнивает эти документы непосредственно с вопросом и ранжирует их по релевантности.
Сначала определим пользовательский очиститель для удаления тикетов, содержащих либо тот же ID проблемы, либо родительский ID, что и проблема, переданная в качестве запроса:
from typing import Optional
@component
class RemoveRelated:
@component.output_types(documents=List[Document])
def run(self, tickets: List[Document], query_id: Optional[str]):
retrieved_tickets = []
for t in tickets:
if not t.meta['Issue id'] == query_id and not t.meta['Parent id'] == query_id:
retrieved_tickets.append(t)
return {'documents': retrieved_tickets}
Затем мы встраиваем запрос, извлекаем релевантные документы, очищаем выборку и, наконец, выполняем переранжирование:
from haystack_integrations.components.embedders.jina import JinaTextEmbedder
from haystack_integrations.components.rankers.jina import JinaRanker
query_pipeline_reranker = Pipeline()
query_pipeline_reranker.add_component('query_embedder_reranker', JinaTextEmbedder(model='jina-embeddings-v2-base-en'))
query_pipeline_reranker.add_component('query_retriever_reranker', retriever_reranker)
query_pipeline_reranker.add_component('query_cleaner_reranker', RemoveRelated())
query_pipeline_reranker.add_component('query_ranker_reranker', JinaRanker())
query_pipeline_reranker.connect('query_embedder_reranker.embedding', 'query_retriever_reranker.query_embedding')
query_pipeline_reranker.connect('query_retriever_reranker', 'query_cleaner_reranker')
query_pipeline_reranker.connect('query_cleaner_reranker', 'query_ranker_reranker')
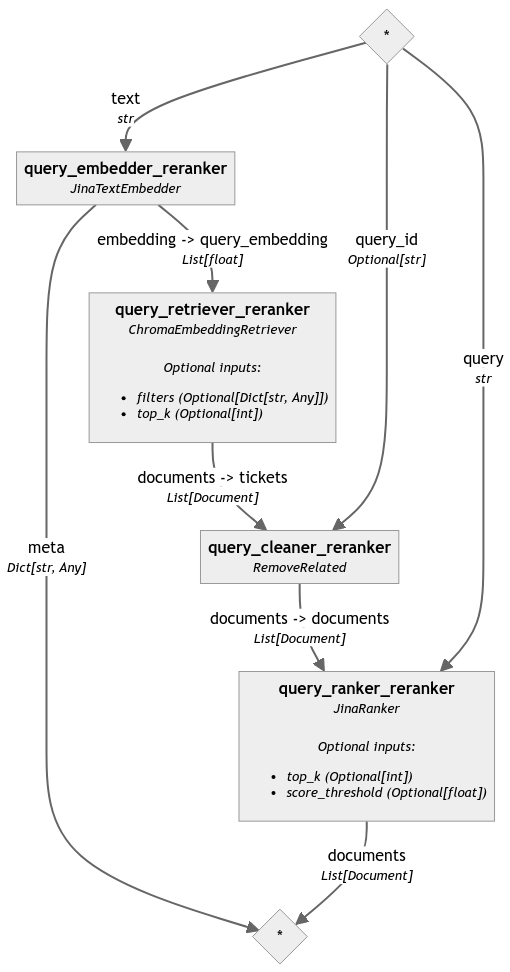
Чтобы подчеркнуть разницу, вызванную компонентом переранжирования, мы проанализировали тот же конвейер без финального шага переранжирования (соответствующий код был опущен в этом посте для удобства чтения, но его можно найти в блокноте):
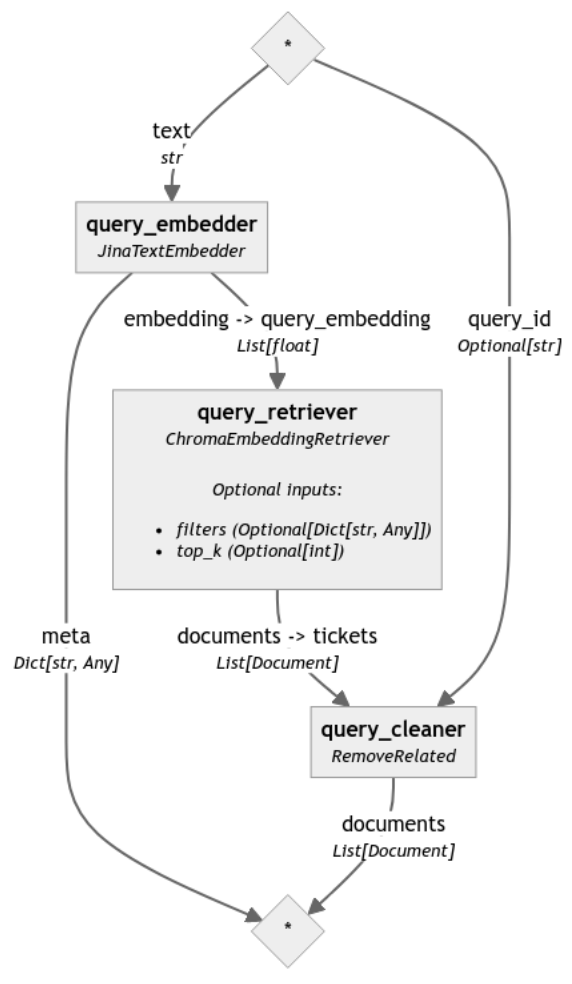
Чтобы сравнить результаты этих двух конвейеров, мы определяем наш запрос в виде существующего тикета, в данном случае "ZOOKEEPER-3282":
query_ticket_key = 'ZOOKEEPER-3282'
with open('tickets.json', 'r') as file:
tickets = json.load(file)
for ticket in tickets:
if ticket['Issue key'] == query_ticket_key:
query = str(ticket)
query_ticket_id = ticket['Issue id']
Он касается "большой переработки документации" [sic]. Вы увидите, что, несмотря на опечатку, Jina Reranker правильно извлечет похожие тикеты.
{
"Summary": "a big refactor for the documetations"
"Issue key": "ZOOKEEPER-3282"
"Issue id:: 13216608
"Parent id": ""
"Issue Type": "Task"
"Status": "In Progress"
"Project lead": "phunt"
"Priority": "Major"
"Assignee": "maoling"
"Reporter": "maoling"
"Creator": "maoling"
"Created": "19/Feb/19 11:50"
"Updated": "04/Aug/19 12:48"
"Last Viewed": "12/Mar/24 11:56"
"Description": "Hi guys: I'am working on doing a big refactor for the documetations.it aims to - 1.make a better reading experiences and help users know more about zookeeper quickly,as good as other projects' doc(e.g redis,hbase). - 2.have less changes to diff with the original docs as far as possible. - 3.solve the problem when we have some new features or improvements,but cannot find a good place to doc it. The new catalog may looks kile this: * is new one added. ** is the one to keep unchanged as far as possible. *** is the one modified. -------------------------------------------------------------- |---Overview |---Welcome ** [1.1] |---Overview ** [1.2] |---Getting Started ** [1.3] |---Release Notes ** [1.4] |---Developer |---API *** [2.1] |---Programmer's Guide ** [2.2] |---Recipes *** [2.3] |---Clients * [2.4] |---Use Cases * [2.5] |---Admin & Ops |---Administrator's Guide ** [3.1] |---Quota Guide ** [3.2] |---JMX ** [3.3] |---Observers Guide ** [3.4] |---Dynamic Reconfiguration ** [3.5] |---Zookeeper CLI * [3.6] |---Shell * [3.7] |---Configuration flags * [3.8] |---Troubleshooting & Tuning * [3.9] |---Contributor Guidelines |---General Guidelines * [4.1] |---ZooKeeper Internals ** [4.2] |---Miscellaneous |---Wiki ** [5.1] |---Mailing Lists ** [5.2] -------------------------------------------------------------- The Roadmap is: 1.(I pick up it : D) 1.1 write API[2.1], which includes the: 1.1.1 original API Docs which is a Auto-generated java doc,just give a link. 1.1.2. Restful-api (the apis under the /zookeeper-contrib-rest/src/main/java/org/apache/zookeeper/server/jersey/resources) 1.2 write Clients[2.4], which includes the: 1.2.1 C client 1.2.2 zk-python, kazoo 1.2.3 Curator etc....... look at an example from: https://redis.io/clients # write Recipes[2.3], which includes the: - integrate "Java Example" and "Barrier and Queue Tutorial"(Since some bugs in the examples and they are obsolete,we may delete something) into it. - suggest users to use the recipes implements of Curator and link to the Curator's recipes doc. # write Zookeeper CLI[3.6], which includes the: - about how to use the zk command line interface [./zkCli.sh] e.g ls /; get ; rmr;create -e -p etc....... - look at an example from redis: https://redis.io/topics/rediscli # write shell[3.7], which includes the: - list all usages of the shells under the zookeeper/bin. (e.g zkTxnLogToolkit.sh,zkCleanup.sh) # write Configuration flags[3.8], which includes the: - list all usages of configurations properties(e.g zookeeper.snapCount): - move the original Advanced Configuration part of zookeeperAdmin.md into it. look at an example from:https://coreos.com/etcd/docs/latest/op-guide/configuration.html # write Troubleshooting & Tuning[3.9], which includes the: - move the original "Gotchas: Common Problems and Troubleshooting" part of Administrator's Guide.md into it. - move the original "FAQ" into into it. - add some new contents (e.g https://www.yumpu.com/en/document/read/29574266/building-an-impenetrable-zookeeper-pdf-github). look at an example from:https://redis.io/topics/problems https://coreos.com/etcd/docs/latest/tuning.html # write General Guidelines[4.1], which includes the: - move the original "Logging" part of ZooKeeper Internals into it as the logger specification. - write specifications about code, git commit messages,github PR etc ... look at an example from: http://hbase.apache.org/book.html#hbase.commit.msg.format # write Use Cases[2.5], which includes the: - just move the context from: https://cwiki.apache.org/confluence/display/ZOOKEEPER/PoweredBy into it. - add some new contents.(e.g Apache Projects:Spark;Companies:twitter,fb) -------------------------------------------------------------- BTW: - Any insights or suggestions are very welcomed.After the dicussions,I will create a series of tickets(An umbrella) - Since these works can be done parallelly, if you are interested in them, please don't hesitate,just assign to yourself, pick it up. (Notice: give me a ping to avoid the duplicated work)."
}
Наконец, мы запускаем конвейер запросов. В данном случае он извлекает 20 тикетов, удаляет записи, связанные по ID, выполняет переранжирование и выводит окончательную выборку из 10 наиболее релевантных проблем.
До этапа переранжирования вывод включает 17 тикетов:
| Rank | Issue ID | Issue Key | Summary |
|---|---|---|---|
| 1 | 13191544 | ZOOKEEPER-3170 | Umbrella for eliminating ZooKeeper flaky tests |
| 2 | 13400622 | ZOOKEEPER-4375 | Quota cannot limit the specify value when multiply clients create/set znodes |
| 3 | 13249579 | ZOOKEEPER-3499 | [admin server way] Add a complete backup mechanism for zookeeper internal |
| 4 | 13295073 | ZOOKEEPER-3775 | Wrong message in IOException |
| 5 | 13268474 | ZOOKEEPER-3617 | ZK digest ACL permissions gets overridden |
| 6 | 13296971 | ZOOKEEPER-3787 | Apply modernizer-maven-plugin to build |
| 7 | 13265507 | ZOOKEEPER-3600 | support the complete linearizable read and multiply read consistency level |
| 8 | 13222060 | ZOOKEEPER-3318 | [CLI way]Add a complete backup mechanism for zookeeper internal |
| 9 | 13262989 | ZOOKEEPER-3587 | Add a documentation about docker |
| 10 | 13262130 | ZOOKEEPER-3578 | Add a new CLI: multi |
| 11 | 13262828 | ZOOKEEPER-3585 | Add a documentation about RequestProcessors |
| 12 | 13262494 | ZOOKEEPER-3583 | Add new apis to get node type and ttl time info |
| 13 | 12998876 | ZOOKEEPER-2519 | zh->state should not be 0 while handle is active |
| 14 | 13536435 | ZOOKEEPER-4696 | Update for Zookeeper latest version |
| 15 | 13297249 | ZOOKEEPER-3789 | fix the build warnings about @see,@link,@return found by IDEA |
| 16 | 12728973 | ZOOKEEPER-1983 | Append to zookeeper.out (not overwrite) to support logrotation |
| 17 | 12478629 | ZOOKEEPER-915 | Errors that happen during sync() processing at the leader do not get propagated back to the client. |
После включения переранжировщика мы запускаем конвейер запросов:
result = query_pipeline_reranker.run(data={'query_embedder_reranker':{'text': query},
'query_retriever_reranker': {'top_k': 20},
'query_cleaner_reranker': {'query_id': query_ticket_id},
'query_ranker_reranker': {'query': query, 'top_k': 10}
}
)
for idx, res in enumerate(result['query_ranker_reranker']['documents']):
print('Doc {}:'.format(idx + 1), res)
Окончательный результат - 10 наиболее релевантных тикетов:
| Rank | Issue ID | Issue Key | Summary |
|---|---|---|---|
| 1 | 13262989 | ZOOKEEPER-3587 | Add a documentation about docker |
| 2 | 13265507 | ZOOKEEPER-3600 | support the complete linearizable read and multiply read consistency level |
| 3 | 13249579 | ZOOKEEPER-3499 | [admin server way] Add a complete backup mechanism for zookeeper internal |
| 4 | 12478629 | ZOOKEEPER-915 | Errors that happen during sync() processing at the leader do not get propagated back to the client. |
| 5 | 13262828 | ZOOKEEPER-3585 | Add a documentation about RequestProcessors |
| 6 | 13297249 | ZOOKEEPER-3789 | fix the build warnings about @see,@link,@return found by IDEA |
| 7 | 12998876 | ZOOKEEPER-2519 | zh->state should not be 0 while handle is active |
| 8 | 13536435 | ZOOKEEPER-4696 | Update for Zookeeper latest version |
| 9 | 12728973 | ZOOKEEPER-1983 | Append to zookeeper.out (not overwrite) to support logrotation |
| 10 | 13222060 | ZOOKEEPER-3318 | [CLI way]Add a complete backup mechanism for zookeeper internal |
tagПреимущества Jina Embeddings и Reranker
Подводя итоги этого руководства, мы создали инструмент идентификации дубликатов тикетов на основе Jina Embeddings, Jina Reranker и Haystack 2.0. Результаты выше ясно показывают необходимость как Jina Embeddings для поиска релевантных документов через векторный поиск, так и Jina Reranker для получения наиболее релевантного контента.
Если взять, например, два тикета, касающихся добавления документации, т.е. "ZOOKEEPER-3585" и "ZOOKEEPER-3587", мы видим, что после этапа поиска они правильно включены на позиции 11 и 9 соответственно. После переранжирования документов они теперь оба находятся в топ-5 наиболее релевантных документов на позициях 5 и 1 соответственно, что показывает значительное улучшение.
Интегрируя обе модели в конвейеры Haystack, весь инструмент готов к использованию. Эта комбинация делает расширение Jina Haystack идеальным решением для вашего приложения.
