
После выпуска компанией OpenAI модели O1, одной из самых обсуждаемых тем в сообществе ИИ стало масштабирование вычислений во время тестирования. Это относится к выделению дополнительных вычислительных ресурсов во время вывода — фазы, когда модель ИИ генерирует ответы на входные данные — а не во время предварительного обучения. Хорошо известным примером является многошаговое рассуждение по "цепочке мыслей", которое позволяет моделям выполнять более обширные внутренние размышления, такие как оценка нескольких потенциальных ответов, более глубокое планирование, самоанализ перед формированием окончательного ответа. Эта стратегия улучшает качество ответов, особенно в сложных задачах рассуждения. Недавно выпущенная компанией Alibaba модель QwQ-32B-Preview следует этой тенденции улучшения рассуждений ИИ через увеличение вычислений во время тестирования.
При использовании модели O1 от OpenAI пользователи могут явно заметить, что многошаговый вывод требует дополнительного времени, поскольку модель выстраивает цепочки рассуждений для решения проблем.
В Jina AI мы больше фокусируемся на эмбеддингах и ранжировщиках, чем на LLM, поэтому для нас естественно рассматривать масштабирование вычислений во время тестирования в этом контексте: Как можно применить "цепочку мыслей" к моделям эмбеддингов? Хотя на первый взгляд это может показаться неочевидным, эта статья исследует новый подход и демонстрирует, как масштабирование вычислений во время тестирования может быть применено к jina-clip для классификации изображений вне распределения (OOD) — решая задачи, которые иначе были бы невозможны.

tagПрактический пример

Наш эксперимент был сосредоточен на классификации покемонов с использованием набора данных TheFusion21/PokemonCards, который содержит тысячи изображений карточек покемонов. Задача состоит в классификации изображений, где входными данными является обрезанное изображение покемона с карточки (с удаленным текстом/описаниями), а выходными данными — правильное имя покемона из предопределенного набора имен. Эта задача представляет особенно интересный вызов для моделей эмбеддингов CLIP, потому что:
- Имена и визуальные образы покемонов представляют собой узкоспециализированные концепции вне распределения для модели, что затрудняет прямую классификацию
- Каждый покемон имеет четкие визуальные характеристики, которые можно разложить на базовые элементы (формы, цвета, позы), которые CLIP может лучше понять
- Оформление карточек обеспечивает последовательный визуальный формат, добавляя сложность через различные фоны, позы и художественные стили
- Задача требует интеграции нескольких визуальных характеристик одновременно, подобно сложным цепочкам рассуждений в языковых моделях

Absol G, Aerodactyl, Weedle, Caterpie, Azumarill, Bulbasaur, Venusaur, Absol, Aggron, Beedrill δ, Alakazam, Ampharos, Dratini, Ampharos, Ampharos, Arcanine, Blaine's Moltres, Aerodactyl, Celebi & Venusaur-GX, Caterpie]
tagБазовый подход
Базовый подход использует простое прямое сравнение между изображениями карт покемонов и их именами. Сначала мы обрезаем каждое изображение карты покемона, чтобы удалить всю текстовую информацию (заголовок, нижний колонтитул, описание) для предотвращения тривиальных догадок модели CLIP из-за появления имен покемонов в этих текстах. Затем мы кодируем как обрезанные изображения, так и имена покемонов с помощью моделей jina-clip-v1 и jina-clip-v2, чтобы получить их соответствующие эмбеддинги. Классификация производится путем вычисления косинусного сходства между этими эмбеддингами изображений и текста — каждое изображение сопоставляется с именем, имеющим наивысший показатель сходства. Это создает прямое соответствие один к одному между визуальным оформлением карты и именами покемонов, без какого-либо дополнительного контекста или информации об атрибутах. Псевдокод ниже обобщает базовый метод.
# Preprocessing
cropped_images = [crop_artwork(img) for img in pokemon_cards] # Remove text, keep only art
pokemon_names = ["Absol", "Aerodactyl", ...] # Raw Pokemon names
# Get embeddings using jina-clip-v1
image_embeddings = model.encode_image(cropped_images)
text_embeddings = model.encode_text(pokemon_names)
# Classification by cosine similarity
similarities = cosine_similarity(image_embeddings, text_embeddings)
predicted_names = [pokemon_names[argmax(sim)] for sim in similarities]
# Evaluate
accuracy = mean(predicted_names == ground_truth_names)tag"Цепочка мыслей" для классификации
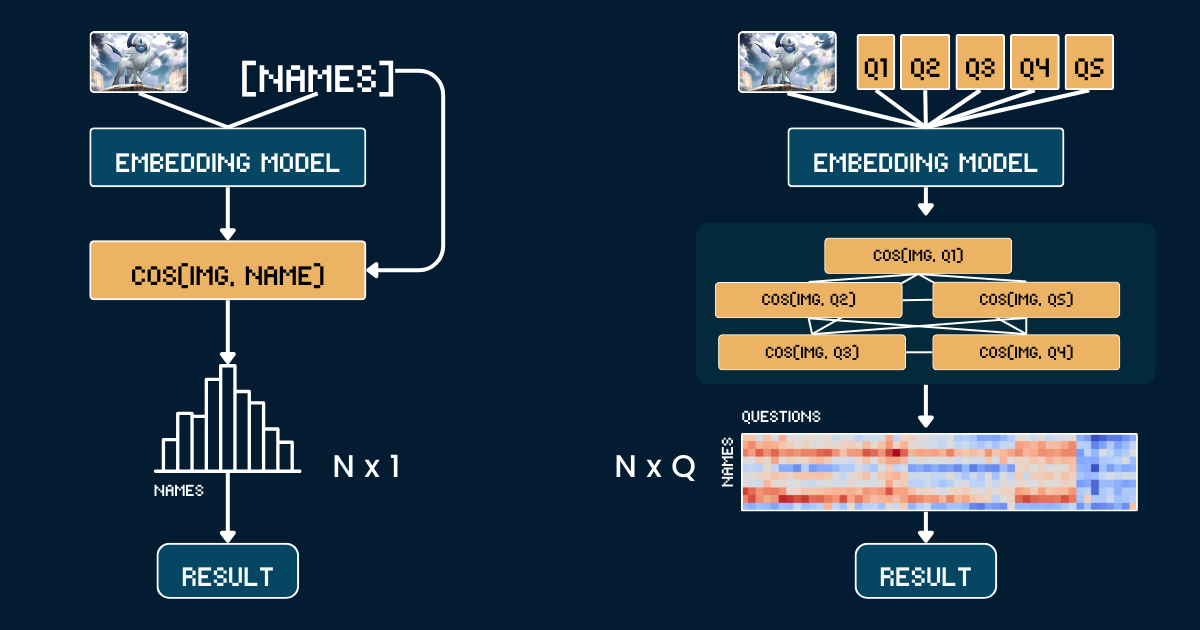
Вместо прямого сопоставления изображений с именами, мы разбиваем распознавание покемонов на структурированную систему визуальных атрибутов. Мы определяем пять ключевых групп атрибутов: доминирующий цвет (например, "белый", "синий"), основная форма (например, "волк", "крылатая рептилия"), ключевая особенность (например, "один белый рог", "большие крылья"), форма тела (например, "волкоподобный на четырех лапах", "крылатый и стройный") и фоновая сцена (например, "космос", "зеленый лес").
Для каждой группы атрибутов мы создаем специальные текстовые подсказки (например, "Тело этого покемона в основном {} цвета") в паре с соответствующими вариантами. Затем мы используем модель для вычисления оценок сходства между изображением и каждым вариантом атрибута. Эти оценки преобразуются в вероятности с помощью softmax для получения более калиброванной меры уверенности.
Полная структура цепочки мыслей (CoT) состоит из двух частей: classification_groups, которая описывает группы подсказок, и pokemon_rules, которая определяет, каким вариантам атрибутов должен соответствовать каждый покемон. Например, Absol должен соответствовать "белому" цвету и "волкоподобной" форме. Полная CoT показана ниже (мы объясним, как она построена, позже):
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
Финальная классификация объединяет эти вероятности атрибутов — вместо единичного сравнения сходства, мы теперь делаем множественные структурированные сравнения и агрегируем их вероятности для принятия более информированного решения.
# Classification process
def classify_pokemon(image):
# Generate all text prompts
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# Get embeddings and similarities
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# Convert to probabilities per attribute group
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# Score each Pokemon based on matching attributes
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get)tagАнализ сложности
Предположим, мы хотим классифицировать изображение среди N имен покемонов. Базовый подход требует вычисления N текстовых эмбеддингов (по одному для каждого имени покемона). В отличие от этого, наш масштабированный подход во время тестирования требует вычисления Q текстовых эмбеддингов, где
Q — это общее количество комбинаций вопрос-вариант для всех вопросов. Оба метода требуют вычисления одного векторного представления изображения и выполнения финального шага классификации, поэтому мы исключаем эти общие операции из нашего сравнения. В данном исследовании наши N=13 и Q=52.В крайнем случае, когда Q = N, наш подход фактически сводится к базовому. Однако ключ к эффективному масштабированию вычислений во время тестирования заключается в том, чтобы:
- Составлять тщательно подобранные вопросы, увеличивающие
Q - Убедиться, что каждый вопрос предоставляет отдельные, информативные подсказки о конечном ответе
- Разрабатывать вопросы максимально ортогональными друг другу для максимизации их совместного информационного прироста.
Этот подход аналогичен игре "Двадцать вопросов", где каждый вопрос стратегически выбирается для эффективного сужения круга возможных ответов.
tagОценка
Наша оценка проводилась на 117 тестовых изображениях, охватывающих 13 различных классов покемонов. Результаты следующие:
| Approach | jina-clip-v1 | jina-clip-v2 |
|---|---|---|
| Baseline | 31.36% | 16.10% |
| CoT | 46.61% | 38.14% |
| Improvement | +15.25% | +22.04% |
Можно видеть, что одна и та же классификация CoT дает значительные улучшения для обеих моделей (+15.25% и +22.04% соответственно) на этой нестандартной или OOD-задаче. Это также говорит о том, что после создания pokemon_system, одна и та же система CoT может эффективно переноситься между разными моделями без необходимости в тонкой настройке или пост-тренировке.
Примечательна относительно высокая базовая производительность v1 (31.36%) в классификации покемонов. Эта модель была обучена на LAION-400M, который включал контент, связанный с покемонами. В отличие от этого, v2 была обучена на DFN-2B (подвыборка из 400M экземпляров) — наборе данных более высокого качества, но с более строгой фильтрацией, который мог исключить контент, связанный с покемонами, что объясняет более низкую базовую производительность V2 (16.10%) на этой конкретной задаче.
tagЭффективное создание pokemon_system
Эффективность нашего подхода с масштабированием вычислений во время тестирования сильно зависит от того, насколько хорошо мы построим pokemon_system. Существуют различные подходы к созданию этой системы, от ручного до полностью автоматизированного.
Ручное создание
Самый прямой подход — это ручной анализ набора данных покемонов и создание групп атрибутов, промптов и правил. Эксперту в предметной области необходимо определить ключевые визуальные атрибуты, такие как цвет, форма и отличительные особенности. Затем написать естественно-языковые промпты для каждого атрибута, перечислить возможные варианты для каждой группы атрибутов и сопоставить каждого покемона с правильными вариантами атрибутов. Хотя это обеспечивает высококачественные правила, процесс требует много времени и плохо масштабируется при большом N.
Создание с помощью LLM
Мы можем использовать LLM для ускорения этого процесса, предлагая им генерировать систему классификации. Хорошо структурированный промпт должен запрашивать группы атрибутов на основе визуальных характеристик, шаблоны естественно-языковых промптов, всеобъемлющие и взаимоисключающие варианты, и правила сопоставления для каждого покемона. LLM может быстро создать первый черновик, хотя его вывод может потребовать проверки.
I need help creating a structured system for Pokemon classification. For each Pokemon in this list: [Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...], create a classification system with:
1. Classification groups that cover these visual attributes:
- Dominant color of the Pokemon
- What type of creature it appears to be (primary form)
- Its most distinctive visual feature
- Overall body shape
- What kind of background/environment it's typically shown in
2. For each group:
- Create a natural language prompt template using "{}" for the option
- List all possible options that could apply to these Pokemon
- Make sure options are mutually exclusive and comprehensive
3. Create rules that map each Pokemon to exactly one option per attribute group, using indices to reference the options
Please output this as a Python dictionary with two main components:
- "classification_groups": containing prompts and options for each attribute
- "pokemon_rules": mapping each Pokemon to its correct attribute indices
Example format:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # index for "white"
...
},
...
}
}Более надежный подход сочетает генерацию LLM с человеческой валидацией. Сначала LLM генерирует исходную систему. Затем эксперты проверяют и корректируют группировку атрибутов, полноту вариантов и точность правил. LLM улучшает систему на основе этой обратной связи, и процесс повторяется до достижения удовлетворительного качества. Этот подход обеспечивает баланс между эффективностью и точностью.
Автоматизированное создание с помощью DSPy
Для полностью автоматизированного подхода мы можем использовать DSPy для итеративной оптимизации pokemon_system. Процесс начинается с простой pokemon_system, написанной вручную или с помощью LLM в качестве исходного промпта. Каждая версия оценивается на отложенном наборе, используя точность как сигнал обратной связи для DSPy. На основе этой производительности генерируются оптимизированные промпты (т.е. новые версии pokemon_system). Этот цикл повторяется до сходимости, и в течение всего процесса модель векторных представлений остается полностью фиксированной.
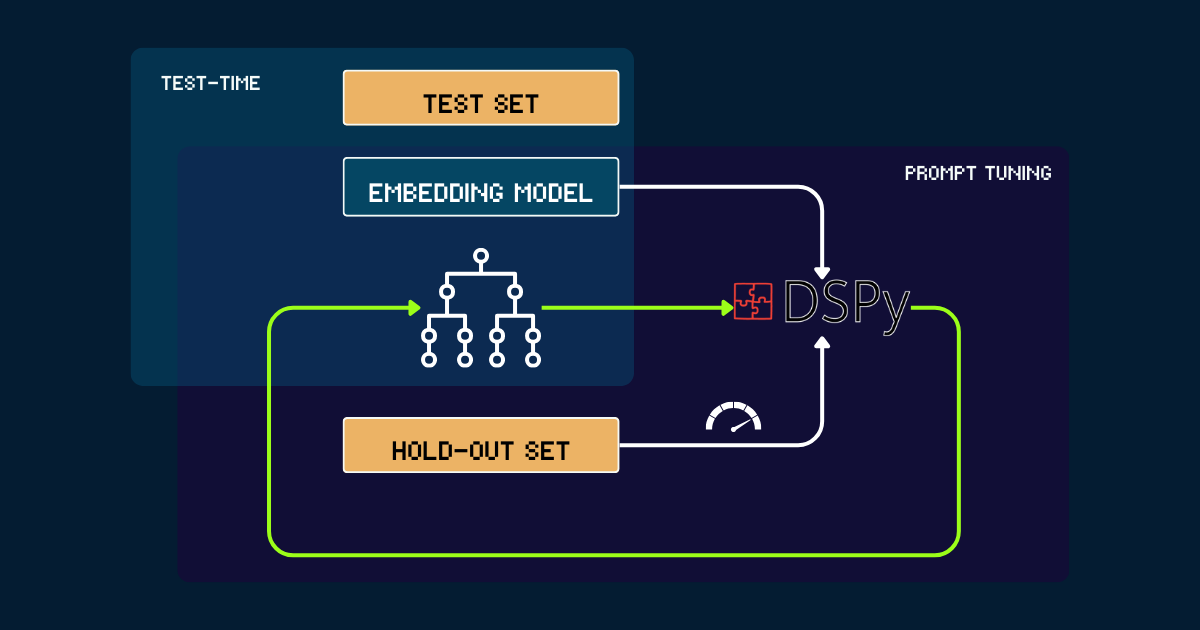
pokemon_system CoT; настройку необходимо выполнить только один раз для каждой задачи.tagПочему стоит масштабировать вычисления во время тестирования для моделей векторных представлений?
Потому что масштабирование предварительного обучения в конечном итоге становится экономически неосуществимым.
С момента выпуска набора векторных представлений Jina — включая jina-embeddings-v1, v2, v3, jina-clip-v1, v2 и jina-ColBERT-v1, v2 — каждое обновление модели через масштабированное предварительное обучение сопровождалось увеличением затрат. Например, наша первая модель, jina-embeddings-v1, выпущенная в июне 2023 года со 110M параметров, стоила в обучении от 10,000, в зависимости от способа подсчета. С jina-embeddings-v3 улучшения значительны, но они в основном происходят из-за увеличенных вложенных ресурсов. Траектория затрат для передовых моделей выросла с тысяч до десятков тысяч долларов, а для более крупных AI-компаний даже до сотен миллионов сегодня. Хотя вложение большего количества денег, ресурсов и данных в предварительное обучение дает лучшие модели, предельная отдача в конечном итоге делает дальнейшее масштабирование экономически неустойчивым.

С другой стороны, современные модели векторных представлений становятся все более мощными: многоязычными, многозадачными, мультимодальными и способными к сильной производительности в режиме zero-shot и следованию инструкциям. Эта универсальность оставляет большое пространство для алгоритмических улучшений и масштабирования вычислений во время тестирования.
Вопрос тогда становится: какие затраты пользователи готовы нести за запрос, который им действительно важен? Если допущение более длительного времени вывода для фиксированных предварительно обученных моделей значительно улучшает качество результатов, многие сочли бы это оправданным. С нашей точки зрения, существует значительный неиспользованный потенциал в масштабировании вычислений во время тестирования для моделей векторных представлений. Это представляет собой сдвиг от простого увеличения размера модели во время обучения к усилению вычислительных усилий во время фазы вывода для достижения лучшей производительности.
tagЗаключение
Наше исследование вычислений во время тестирования для jina-clip-v1/v2 показывает несколько ключевых выводов:
- Мы достигли лучшей производительности на нестандартных или внедистрибутивных (OOD) данных без какой-либо тонкой настройки или пост-тренировки векторных представлений.
- Система делала более тонкие различия путем итеративного уточнения поиска сходства и критериев классификации.
- Включая динамические корректировки промптов и итеративные рассуждения, мы превратили процесс вывода модели векторных представлений из единичного запроса в более сложную цепочку размышлений.
Это исследование лишь слегка затрагивает поверхность того, что возможно с вычислениями во время тестирования. Остается значительное пространство для алгоритмического масштабирования. Например, мы могли бы разработать методы для итеративного выбора вопросов, которые наиболее эффективно сужают пространство ответов, аналогично оптимальной стратегии в игре "Двадцать вопросов". Масштабируя вычисления во время тестирования, мы можем продвинуть модели векторных представлений за пределы их текущих ограничений и позволить им решать более сложные, нюансированные задачи, которые раньше казались недостижимыми.





