



В октябре 2023 года мы представили jina-embeddings-v2, первое семейство моделей встраивания с открытым исходным кодом, способное обрабатывать входные данные до 8 192 токенов. Развивая этот успех, в этом году мы запустили jina-embeddings-v3, предлагающую такую же обширную поддержку входных данных с дополнительными улучшениями.

В этой статье мы углубимся в встраивания с длинным контекстом и ответим на несколько вопросов: Когда практично объединять такой большой объем текста в единый вектор? Улучшает ли сегментация поиск, и если да, то как? Как мы можем сохранить контекст из разных частей документа при сегментации текста?
Чтобы ответить на эти вопросы, мы сравним несколько методов генерации встраиваний:
- Встраивание длинного контекста (кодирование до 8 192 токенов в документе) против короткого контекста (т.е. усечение до 192 токенов).
- Без разбиения на части vs. наивное разбиение vs. позднее разбиение.
- Различные размеры частей при наивном и позднем разбиении.
tagДействительно ли полезен длинный контекст?
Благодаря возможности кодировать до десяти страниц текста в одном встраивании, модели встраивания с длинным контекстом открывают возможности для крупномасштабного представления текста. Но действительно ли это полезно? По мнению многих людей... нет.




Источники: Цитата Нильса Реймера из подкаста How AI Is Built, твит brainlag, комментарий egorfine на Hacker News, комментарий andy99 на Hacker News
Мы рассмотрим все эти опасения с помощью детального исследования возможностей длинного контекста, когда длинный контекст полезен, и когда его следует (и не следует) использовать. Но сначала давайте выслушаем скептиков и рассмотрим некоторые проблемы, с которыми сталкиваются модели встраивания с длинным контекстом.
tagПроблемы со встраиваниями длинного контекста
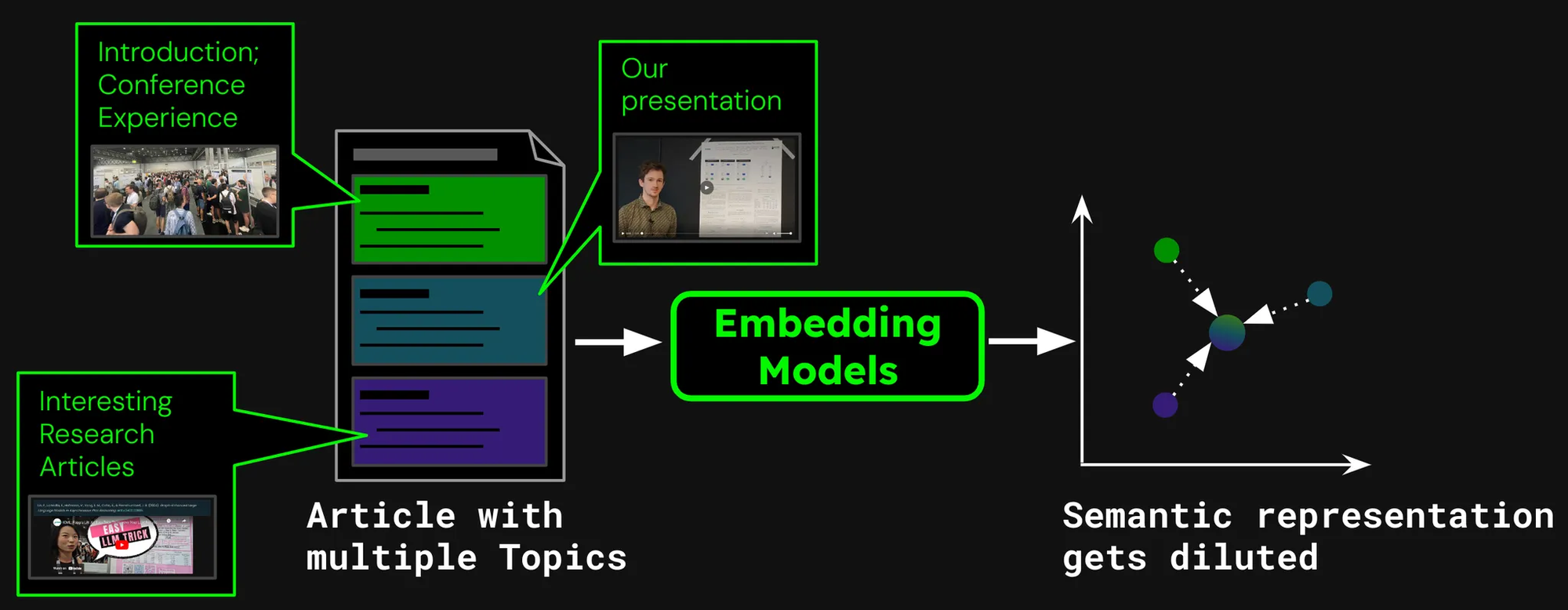
Представьте, что мы создаем систему поиска документов для статей, например, как на нашем блоге Jina AI. Иногда одна статья может охватывать несколько тем, как отчет о нашем посещении конференции ICML 2024, который содержит:
- Введение, содержащее общую информацию об ICML (количество участников, место проведения, охват и т.д.).
- Презентацию нашей работы (jina-clip-v1).
- Обзоры других интересных исследовательских работ, представленных на ICML.
Если мы создаем только одно встраивание для этой статьи, это встраивание представляет собой смесь трех разных тем:
Это приводит к нескольким проблемам:
- Размывание представления: Хотя все темы в данном тексте могут быть связаны, только одна может быть релевантна поисковому запросу пользователя. Однако одно встраивание (в данном случае, всего поста в блоге) – это всего лишь одна точка в векторном пространстве. По мере добавления текста во входные данные модели, встраивание смещается, чтобы охватить общую тему статьи, становясь менее эффективным в представлении содержания конкретных параграфов.
- Ограниченная емкость: Модели встраивания производят векторы фиксированного размера, независимо от длины входных данных. По мере добавления контента на вход, модели становится сложнее представить всю эту информацию в векторе. Представьте это как уменьшение изображения до 16×16 пикселей — если вы уменьшаете изображение чего-то простого, например яблока, вы все еще можете извлечь смысл из уменьшенного изображения. Уменьшение карты улиц Берлина? Не совсем то же самое.
- Потеря информации: В некоторых случаях даже модели встраивания с длинным контекстом достигают своих пределов; Многие модели поддерживают кодирование текста до 8 192 токенов. Более длинные документы необходимо обрезать перед встраиванием, что приводит к потере информации. Если информация, релевантная для пользователя, находится в конце документа, она вообще не будет захвачена встраиванием.
- Возможно, вам нужна сегментация текста: Некоторым приложениям требуются встраивания для определенных сегментов текста, а не для всего документа, например, для определения релевантного отрывка в тексте.
tagДлинный контекст vs. усечение
Чтобы понять, действительно ли длинный контекст полезен, давайте рассмотрим производительность двух сценариев поиска:
- Кодирование документов до 8 192 токенов (около 10 страниц текста).
- Усечение документов до 192 токенов и кодирование до этого предела.
Мы сравним результаты, используяjina-embeddings-v3 с метрикой поиска nDCG@10. Мы протестировали следующие наборы данных:
| Dataset | Описание | Пример запроса | Пример документа | Средняя длина документа (символов) |
|---|---|---|---|---|
| NFCorpus | Полнотекстовый медицинский набор данных для поиска с 3244 запросами и документами в основном из PubMed. | "Using Diet to Treat Asthma and Eczema" | "Statin Use and Breast Cancer Survival: A Nationwide Cohort Study from Finland Recent studies have suggested that [...]" | 326753 |
| QMSum | Набор данных для суммаризации встреч на основе запросов, требующий обобщения релевантных сегментов встреч. | "The professor was the one to raise the issue and suggested that a knowledge engineering trick [...]" | "Project Manager: Is that alright now ? {vocalsound} Okay . Sorry ? Okay , everybody all set to start the meeting ? [...]" | 37445 |
| NarrativeQA | Набор данных вопросов и ответов, содержащий длинные истории и соответствующие вопросы о конкретном содержании. | "What kind of business Sophia owned in Paris?" | "The Project Gutenberg EBook of The Old Wives' Tale, by Arnold Bennett\n\nThis eBook is for the use of anyone anywhere [...]" | 53336 |
| 2WikiMultihopQA | Набор данных для многошагового поиска ответов с до 5 шагами рассуждений, разработанный с шаблонами для избежания коротких путей. | "What is the award that the composer of song The Seeker (The Who Song) earned?" | "Passage 1:\nMargaret, Countess of Brienne\nMarguerite d'Enghien (born 1365 - d. after 1394), was the ruling suo jure [...]" | 30854 |
| SummScreenFD | Набор данных для суммаризации сценариев с транскриптами телесериалов и обзорами, требующими интеграции рассредоточенного сюжета. | "Penny gets a new chair, which Sheldon enjoys until he finds out that she picked it up from [...]" | "[EXT. LAS VEGAS CITY (STOCK) - NIGHT]\n[EXT. ABERNATHY RESIDENCE - DRIVEWAY -- NIGHT]\n(The lamp post light over the [...]" | 1613 |
Как мы видим, кодирование более 192 токенов может дать заметные улучшения производительности:
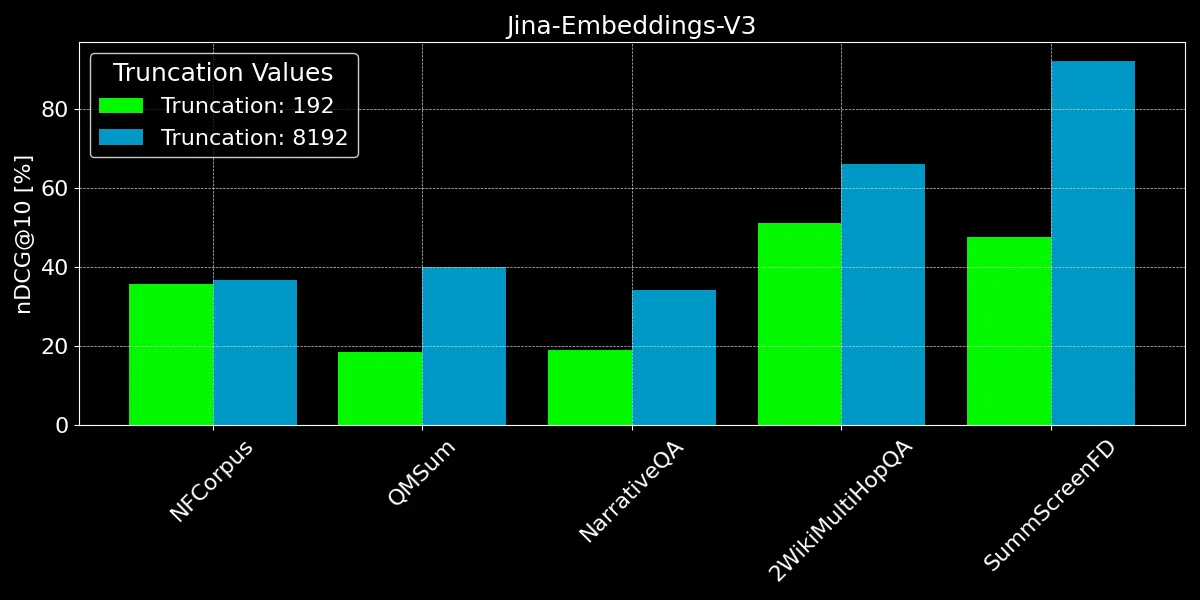
Однако на некоторых наборах данных мы видим большие улучшения, чем на других:
- Для NFCorpus усечение едва имеет значение. Это потому, что заголовки и аннотации находятся прямо в начале документов, и они весьма релевантны типичным поисковым запросам пользователей. Независимо от того, усечен текст или нет, наиболее важные данные остаются в пределах лимита токенов.
- QMSum и NarrativeQA считаются задачами "понимания прочитанного", где пользователи обычно ищут конкретные факты в тексте. Эти факты часто встречаются в деталях, разбросанных по всему документу, и могут выходить за пределы усеченного лимита в 192 токена. Например, в документе NarrativeQA Percival Keene, ответ на вопрос "Кто тот хулиган, который крадет обед Персиваля?" находится далеко за этим лимитом. Аналогично, в 2WikiMultiHopQA релевантная информация распределена по всему документу, требуя от моделей навигации и синтеза знаний из нескольких разделов для эффективного ответа на запросы.
- SummScreenFD - это задача, направленная на определение сценария, соответствующего данному резюме. Поскольку резюме включает информацию, распределенную по всему сценарию, кодирование большего объема текста улучшает точность сопоставления резюме с правильным сценарием.
tagСегментация текста для улучшения производительности поиска
• Сегментация: Обнаружение границ в входном тексте, например, предложений или фиксированного количества токенов.
• Наивное разбиение: Разделение текста на фрагменты на основе сегментационных меток перед его кодированием.
• Позднее разбиение: Сначала кодирование документа, а затем его сегментация (с сохранением контекста между фрагментами).
Вместо встраивания всего документа в один вектор, мы можем использовать различные методы для первоначальной сегментации документа путем назначения граничных меток:

Некоторые распространенные методы включают:
- Сегментация по фиксированному размеру: Документ делится на сегменты фиксированного количества токенов, определяемого токенизатором модели встраивания. Это обеспечивает соответствие токенизации сегментов токенизации всего документа (сегментация по определенному количеству символов могла бы привести к другой токенизации).
- Сегментация по предложениям: Документ сегментируется на предложения, и каждый фрагмент состоит из n количества предложений.
- Сегментация по семантике: Каждый сегмент соответствует нескольким предложениям, и модель встраивания определяет сходство последовательных предложений. Предложения с высоким сходством встраиваний назначаются в один фрагмент.
Для простоты в этой статье мы используем сегментацию фиксированного размера.
tagПоиск документов с использованием наивного разбиения
После выполнения сегментации фиксированного размера мы можем наивно разбить документ в соответствии с этими сегментами:
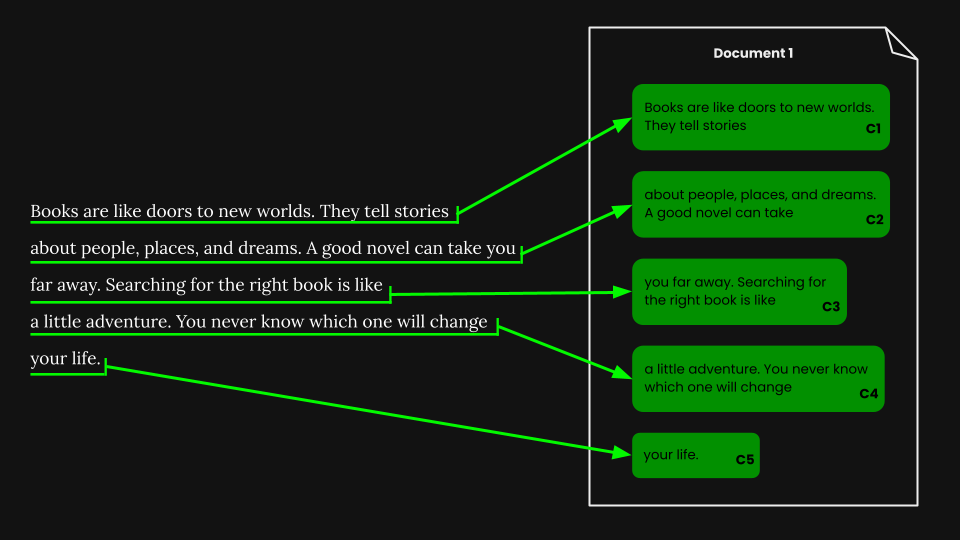
Используя jina-embeddings-v3, мы кодируем каждый фрагмент в вектор встраивания, который точно отражает его семантику, затем сохраняем эти встраивания в векторной базе данных.
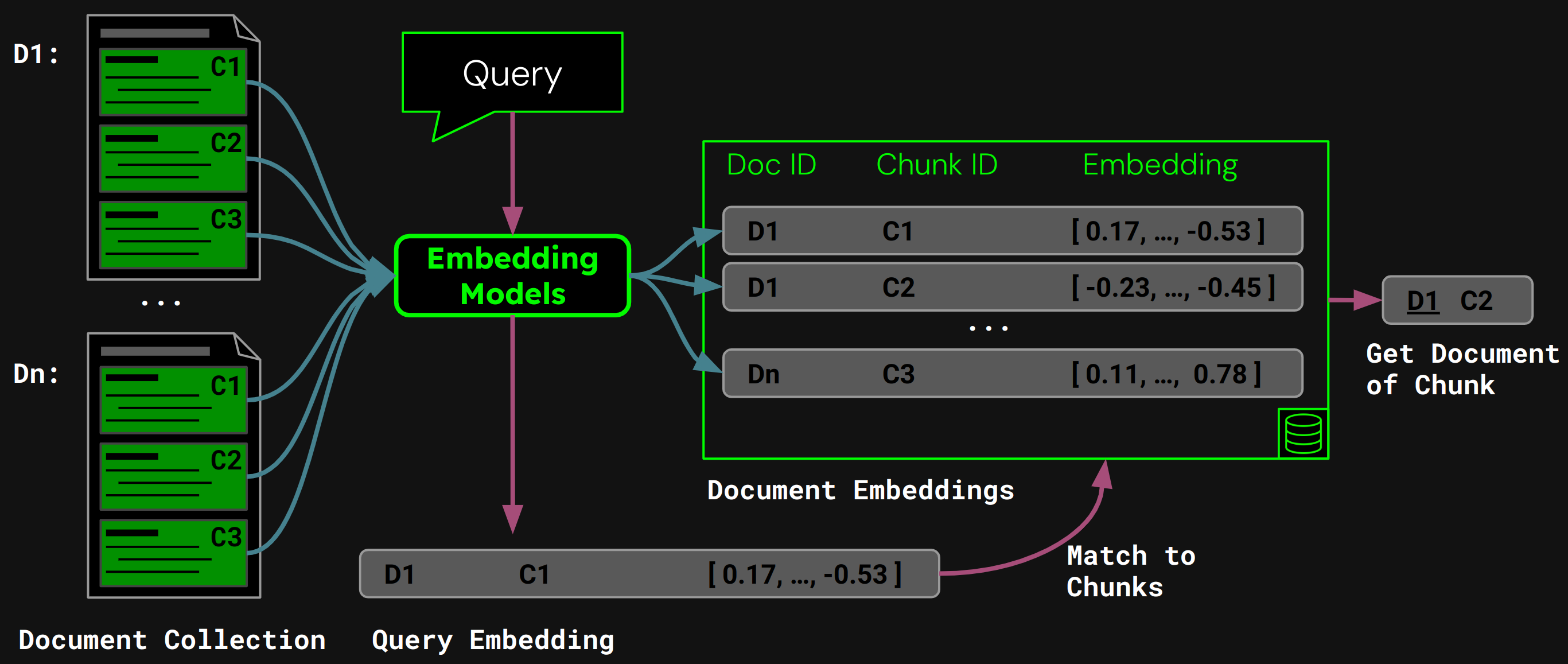
Во время выполнения модель кодирует запрос пользователя в вектор запроса. Мы сравниваем его с нашей векторной базой данных встраиваний фрагментов, чтобы найти фрагмент с наибольшим косинусным сходством, а затем возвращаем соответствующий документ пользователю:
tagПроблемы наивного разбиения

Хотя наивное разбиение решает некоторые ограничения моделей эмбеддингов с длинным контекстом, у него есть свои недостатки:
- Потеря общей картины: Когда дело доходит до поиска документов, множественные эмбеддинги небольших фрагментов могут не уловить общую тему документа. Это похоже на ситуацию, когда за деревьями не видно леса.
- Проблема отсутствия контекста: Фрагменты нельзя точно интерпретировать, так как отсутствует контекстная информация, как показано на Рисунке 6.
- Эффективность: Большее количество фрагментов требует больше места для хранения и увеличивает время поиска.
tagПозднее разбиение решает проблему контекста
Позднее разбиение работает в два основных этапа:
- Сначала оно использует возможности модели по работе с длинным контекстом для кодирования всего документа в токенные эмбеддинги. Это сохраняет полный контекст документа.
- Затем оно создает эмбеддинги фрагментов путем применения усреднения к определенным последовательностям токенных эмбеддингов, соответствующих границам, определенным при сегментации.
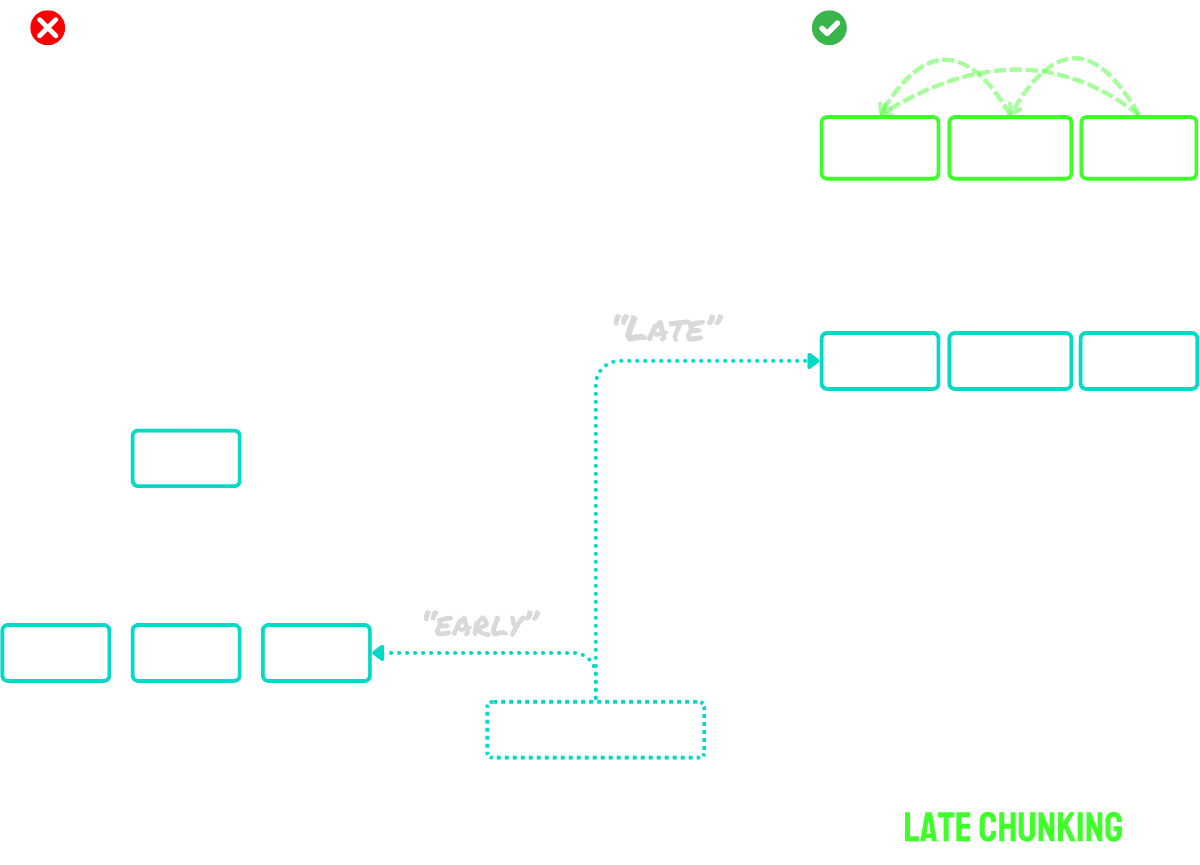
Ключевое преимущество этого подхода в том, что токенные эмбеддинги контекстуализированы - то есть они естественным образом фиксируют ссылки и связи с другими частями документа. Поскольку процесс создания эмбеддингов происходит до разбиения, каждый фрагмент сохраняет осведомленность о более широком контексте документа, решая проблему отсутствия контекста, которая преследует подходы с наивным разбиением.
Для документов, превышающих максимальный размер входных данных модели, мы можем использовать "длинное позднее разбиение":
- Сначала мы разбиваем документ на перекрывающиеся "макро-фрагменты". Размер каждого макро-фрагмента подобран так, чтобы уместиться в максимальную длину контекста модели (например, 8 192 токена).
- Модель обрабатывает эти макро-фрагменты для создания токенных эмбеддингов.
- После получения токенных эмбеддингов мы переходим к стандартному позднему разбиению - применяем усреднение для создания финальных эмбеддингов фрагментов.
Этот подход позволяет нам обрабатывать документы любой длины, сохраняя при этом преимущества позднего разбиения. Представьте это как двухэтапный процесс: сначала делаем документ "удобоваримым" для модели, затем применяем обычную процедуру позднего разбиения.
Вкратце:
- Наивное разбиение: Разделить документ на маленькие фрагменты, затем закодировать каждый фрагмент отдельно.
- Позднее разбиение: Закодировать весь документ сразу для создания токенных эмбеддингов, затем создать эмбеддинги фрагментов путем объединения токенных эмбеддингов на основе границ сегментов.
- Длинное позднее разбиение: Разделить большие документы на перекрывающиеся макро-фрагменты, которые помещаются в контекстное окно модели, закодировать их для получения токенных эмбеддингов, затем применить позднее разбиение как обычно.
Для более подробного описания идеи ознакомьтесь с нашей статьей или блог-постами, упомянутыми выше.
tagРазбивать или не разбивать?
Мы уже видели, что эмбеддинги с длинным контекстом в целом превосходят эмбеддинги коротких текстов, и получили обзор стратегий как наивного, так и позднего разбиения. Теперь возникает вопрос: Является ли разбиение лучше, чем эмбеддинг с длинным контекстом?
Для проведения честного сравнения мы обрезаем текстовые значения до максимальной длины последовательности модели (8 192 токена) перед началом их сегментации. Мы используем сегментацию фиксированного размера с 64 токенами на сегмент (как для наивной сегментации, так и для позднего разбиения). Давайте сравним три сценария:
- Без сегментации: Мы кодируем каждый текст в один эмбеддинг. Это приводит к тем же оценкам, что и в предыдущем эксперименте (см. Рисунок 2), но мы включаем их здесь для лучшего сравнения.
- Наивное разбиение: Мы сегментируем тексты, затем применяем наивное разбиение на основе границ.
- Позднее разбиение: Мы сегментируем тексты, затем используем позднее разбиение для определения эмбеддингов.
Как для позднего разбиения, так и для наивной сегментации мы используем поиск по фрагментам для определения релевантного документа (как показано на Рисунке 5 ранее в этом посте).
Результаты не показывают явного победителя:
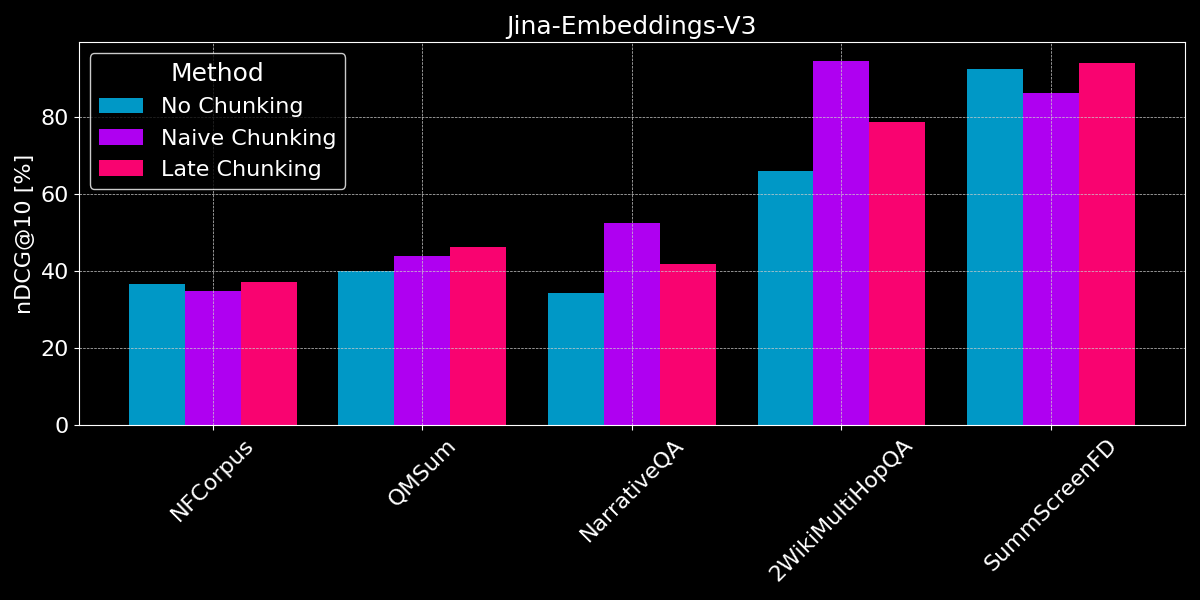
- Для поиска фактов лучше работает наивное разбиение: Для наборов данных QMSum, NarrativeQA и 2WikiMultiHopQA модель должна определить релевантные отрывки в документе. Здесь наивное разбиение явно лучше, чем кодирование всего в единый эмбеддинг, поскольку, вероятно, только несколько фрагментов содержат релевантную информацию, и эти фрагменты захватывают ее гораздо лучше, чем единый эмбеддинг всего документа.
- Позднее разделение лучше работает с содержательными документами и релевантным контекстом: Для документов, охватывающих связную тему, где пользователи ищут общие темы, а не конкретные факты (как в NFCorpus), позднее разделение немного превосходит отсутствие разделения, так как оно балансирует контекст всего документа с локальными деталями. Однако, хотя позднее разделение обычно работает лучше, чем наивное разделение, сохраняя контекст, это преимущество может стать недостатком при поиске отдельных фактов в документах, содержащих в основном нерелевантную информацию — как видно по снижению производительности для NarrativeQA и 2WikiMultiHopQA, где добавленный контекст становится скорее отвлекающим, чем полезным.
tagИмеет ли значение размер чанка?
Эффективность методов разделения действительно зависит от набора данных, что подчеркивает важную роль структуры контента:
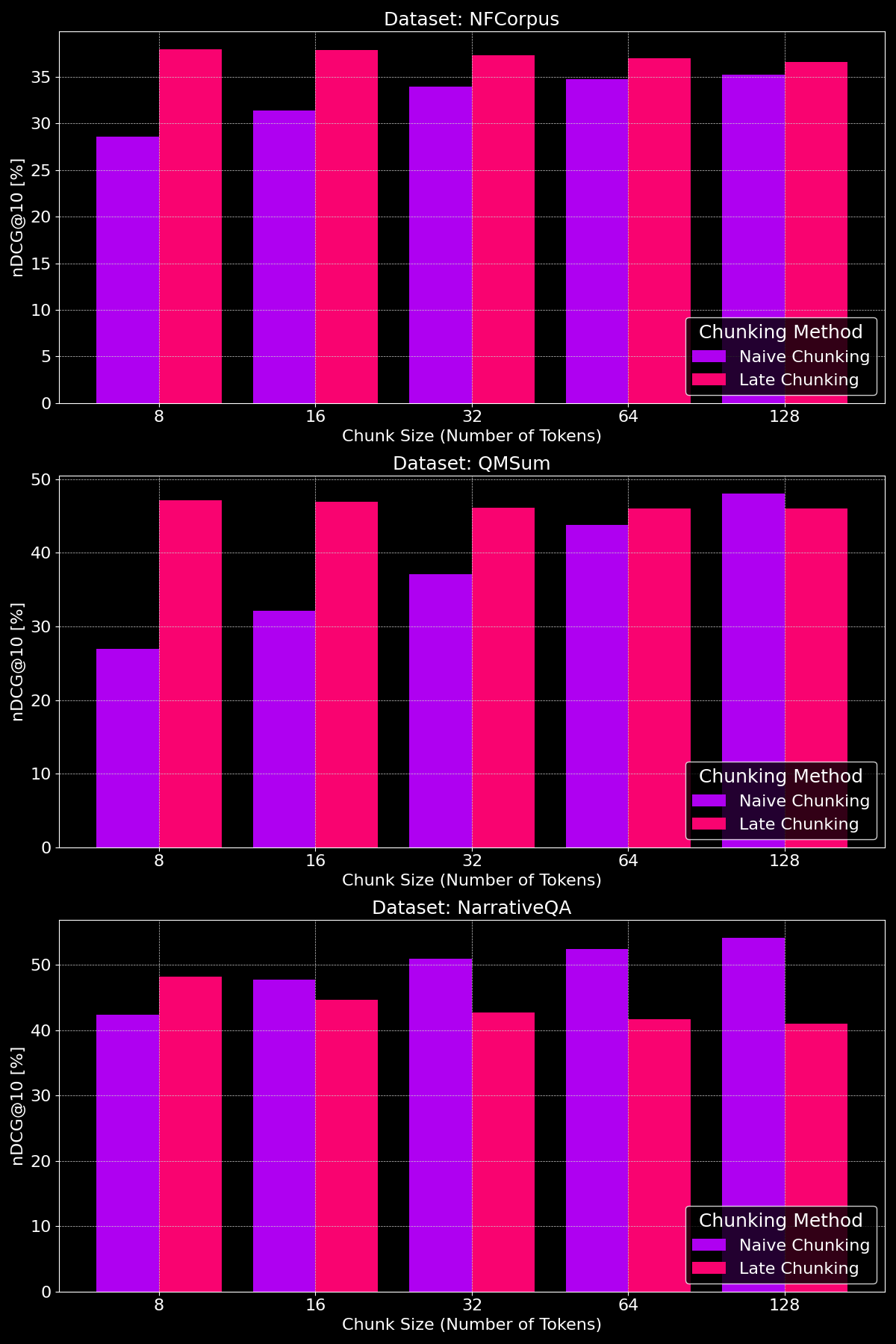
Как мы видим, позднее разделение обычно превосходит наивное разделение при меньших размерах чанков, поскольку меньшие наивные чанки слишком малы, чтобы содержать много контекста, в то время как меньшие поздние чанки сохраняют контекст всего документа, что делает их более семантически значимыми. Исключением является набор данных NarrativeQA, где просто слишком много нерелевантного контекста, из-за чего позднее разделение отстает. При больших размерах чанков наивное разделение показывает заметное улучшение (иногда превосходя позднее разделение) благодаря увеличенному контексту, в то время как производительность позднего разделения постепенно снижается.
tagВыводы: Когда что использовать?
В этой статье мы рассмотрели различные типы задач поиска документов, чтобы лучше понять, когда использовать сегментацию и когда помогает позднее разделение. Итак, что мы узнали?
tagКогда следует использовать встраивание с длинным контекстом?
В целом, включение как можно большего объема текста ваших документов во входные данные модели встраивания не вредит точности поиска. Однако модели встраивания с длинным контекстом часто фокусируются на начале документов, так как они содержат контент вроде заголовков и введения, которые важнее для оценки релевантности, но модели могут пропустить контент в середине документа.
tagКогда следует использовать наивное разделение?
Когда документы охватывают несколько аспектов или пользовательские запросы нацелены на конкретную информацию внутри документа, разделение обычно улучшает производительность поиска.
В конечном счете, решения о сегментации зависят от таких факторов, как необходимость отображения частичного текста пользователям (например, как Google представляет релевантные отрывки в предпросмотрах результатов поиска), что делает сегментацию необходимой, или ограничения по вычислительным ресурсам и памяти, где сегментация может быть менее предпочтительной из-за увеличенных накладных расходов на поиск и использования ресурсов.
tagКогда следует использовать позднее разделение?
Кодируя полный документ перед созданием чанков, позднее разделение решает проблему потери смысла текстовых сегментов из-за отсутствия контекста. Это особенно хорошо работает с содержательными документами, где каждая часть связана с целым. Наши эксперименты показывают, что позднее разделение особенно эффективно при разделении текста на меньшие чанки, как продемонстрировано в нашей статье. Однако есть одно предостережение: если части документа не связаны друг с другом, включение этого более широкого контекста может фактически ухудшить производительность поиска, так как добавляет шум во встраивания.
tagЗаключение
Выбор между встраиванием с длинным контекстом, наивным разделением и поздним разделением зависит от конкретных требований вашей задачи поиска. Встраивания с длинным контекстом ценны для содержательных документов с общими запросами, в то время как разделение превосходит в случаях, когда пользователи ищут конкретные факты или информацию внутри документа. Позднее разделение дополнительно улучшает поиск, сохраняя контекстную согласованность внутри меньших сегментов. В конечном счете, понимание ваших данных и целей поиска будет направлять оптимальный подход, балансируя точность, эффективность и контекстную релевантность.
Если вы исследуете эти стратегии, рассмотрите возможность использования jina-embeddings-v3 — его продвинутые возможности работы с длинным контекстом, позднее разделение и гибкость делают его отличным выбором для различных сценариев поиска.

