



Недавно Кристоф Шуман, основатель LAION AI, поделился интересным наблюдением о моделях текстовых эмбеддингов:
Когда слова в предложении случайно перемешаны, косинусное сходство между их текстовыми эмбеддингами остается удивительно высоким по сравнению с исходным предложением.
Например, рассмотрим два предложения: Berlin is the capital of Germany и the Germany Berlin is capital of. Хотя второе предложение не имеет смысла, модели текстовых эмбеддингов практически не могут их различить. При использовании jina-embeddings-v3 эти два предложения имеют показатель косинусного сходства 0,9295.
Порядок слов — не единственное, к чему эмбеддинги, похоже, не очень чувствительны. Грамматические преобразования могут кардинально изменить смысл предложения, но практически не влияют на расстояние между эмбеддингами. Например, She ate dinner before watching the movie и She watched the movie before eating dinner имеют косинусное сходство 0,9833, несмотря на противоположный порядок действий.
Отрицание также известно как сложное явление для последовательного встраивания без специального обучения — This is a useful model и This is not a useful model выглядят практически одинаково в пространстве эмбеддингов. Часто замена слов в тексте на другие того же класса, например, изменение "today" на "yesterday", или изменение времени глагола, не меняет эмбеддинги настолько сильно, как можно было бы ожидать.
Это имеет серьезные последствия. Рассмотрим два поисковых запроса: Flight from Berlin to Amsterdam и Flight from Amsterdam to Berlin. Они имеют почти идентичные эмбеддинги — jina-embeddings-v3 присваивает им косинусное сходство 0,9884. Для реального приложения, такого как поиск авиабилетов или логистика, этот недостаток является фатальным.
В этой статье мы рассмотрим проблемы, с которыми сталкиваются модели эмбеддингов, изучая их постоянные трудности с порядком и выбором слов. Мы проанализируем основные режимы отказа в различных лингвистических категориях — включая направленные, временные, причинно-следственные, сравнительные и отрицательные контексты — исследуя при этом стратегии улучшения производительности модели.
tagПочему перемешанные предложения имеют удивительно близкие косинусные оценки?
Сначала мы думали, что это может быть связано с тем, как модель комбинирует значения слов — она создает эмбеддинг для каждого слова (6-7 слов в каждом из наших примеров предложений выше) и затем усредняет эти эмбеддинги с помощью среднего объединения. Это означает, что очень мало информации о порядке слов доступно для финального эмбеддинга. Среднее значение одинаково независимо от порядка значений.
Однако даже модели, использующие CLS-объединение (которое рассматривает специальное первое слово для понимания всего предложения и должно быть более чувствительным к порядку слов), имеют ту же проблему. Например, bge-1.5-base-en все равно дает оценку косинусного сходства 0,9304 для предложений Berlin is the capital of Germany и the Germany Berlin is capital of.
Это указывает на ограничение в том, как обучаются модели эмбеддингов. Хотя языковые модели изначально изучают структуру предложений во время предварительного обучения, они, похоже, теряют часть этого понимания во время контрастивного обучения — процесса, который мы используем для создания моделей эмбеддингов.
tagКак длина текста и порядок слов влияют на сходство эмбеддингов?
Почему у моделей возникают проблемы с порядком слов? Первое, что приходит на ум, — это длина текста (в токенах). Когда текст отправляется в функцию кодирования, модель сначала генерирует список эмбеддингов токенов (то есть каждое токенизированное слово имеет выделенный вектор, представляющий его значение), а затем усредняет их.
Чтобы увидеть, как длина текста и порядок слов влияют на сходство эмбеддингов, мы создали набор данных из 180 синтетических предложений различной длины: 3, 5, 10, 15, 20 и 30 токенов. Мы также случайным образом перемешали токены, чтобы сформировать вариации каждого предложения:

Вот несколько примеров:
| Длина (токены) | Исходное предложение | Перемешанное предложение |
|---|---|---|
| 3 | The cat sleeps | cat The sleeps |
| 5 | He drives his car carefully | drives car his carefully He |
| 15 | The talented musicians performed beautiful classical music at the grand concert hall yesterday | in talented now grand classical yesterday The performed musicians at hall concert the music |
| 30 | The passionate group of educational experts collaboratively designed and implemented innovative teaching methodologies to improve learning outcomes in diverse classroom environments worldwide | group teaching through implemented collaboratively outcomes of methodologies across worldwide diverse with passionate and in experts educational classroom for environments now by learning to at improve from innovative The designed |
Мы закодируем набор данных, используя нашу собственную модель jina-embeddings-v3 и модель с открытым исходным кодом bge-base-en-v1.5, затем вычислим косинусное сходство между исходным и перемешанным предложениями:
| Длина (токены) | Среднее косинусное сходство | Стандартное отклонение косинусного сходства |
|---|---|---|
| 3 | 0,947 | 0,053 |
| 5 | 0,909 | 0,052 |
| 10 | 0,924 | 0,031 |
| 15 | 0,918 | 0,019 |
| 20 | 0,899 | 0,021 |
| 30 | 0,874 | 0,025 |
Теперь мы можем создать диаграмму размаха, которая делает тенденцию в косинусном сходстве более очевидной:
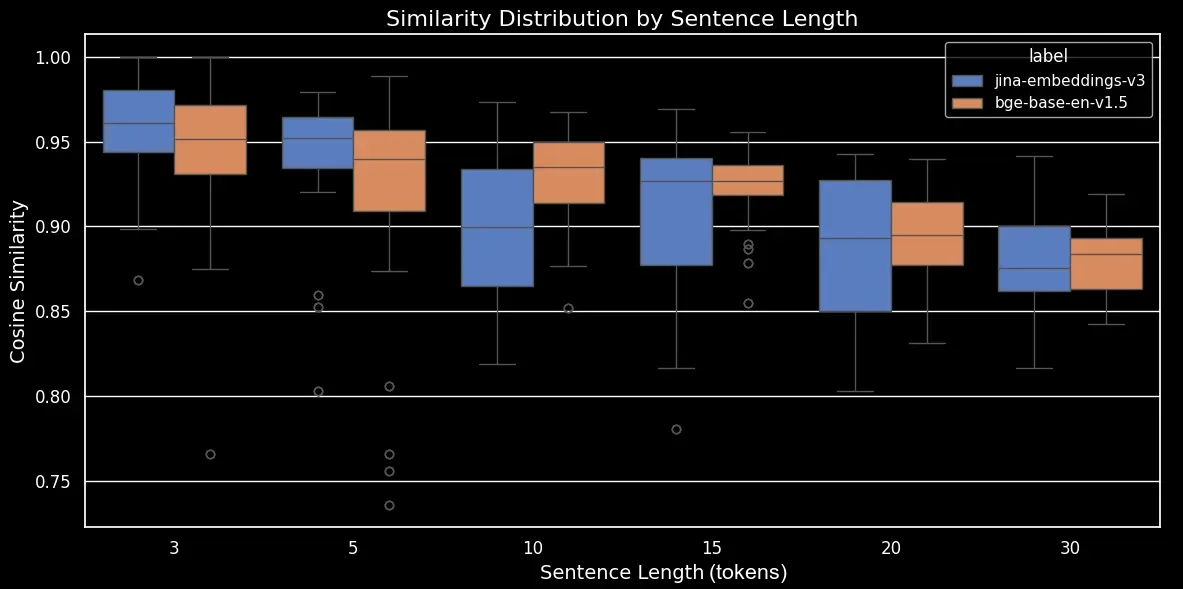
bge-base-en-1.5 (без дополнительной настройки)Как мы видим, существует четкая линейная зависимость в среднем косинусном сходстве эмбеддингов. Чем длиннее текст, тем ниже средний показатель косинусного сходства между исходными и случайно перемешанными предложениями. Это, вероятно, происходит из-за "смещения слов", а именно того, насколько далеко слова переместились от своих исходных позиций после случайного перемешивания. В более коротком тексте просто меньше "слотов" для перемещения токена, поэтому он не может переместиться так далеко, в то время как более длинный текст имеет большее количество потенциальных перестановок, и слова могут перемещаться на большее расстояние.
Как показано на рисунке ниже (Косинусное сходство vs Среднее смещение слов), чем длиннее текст, тем больше смещение слов:
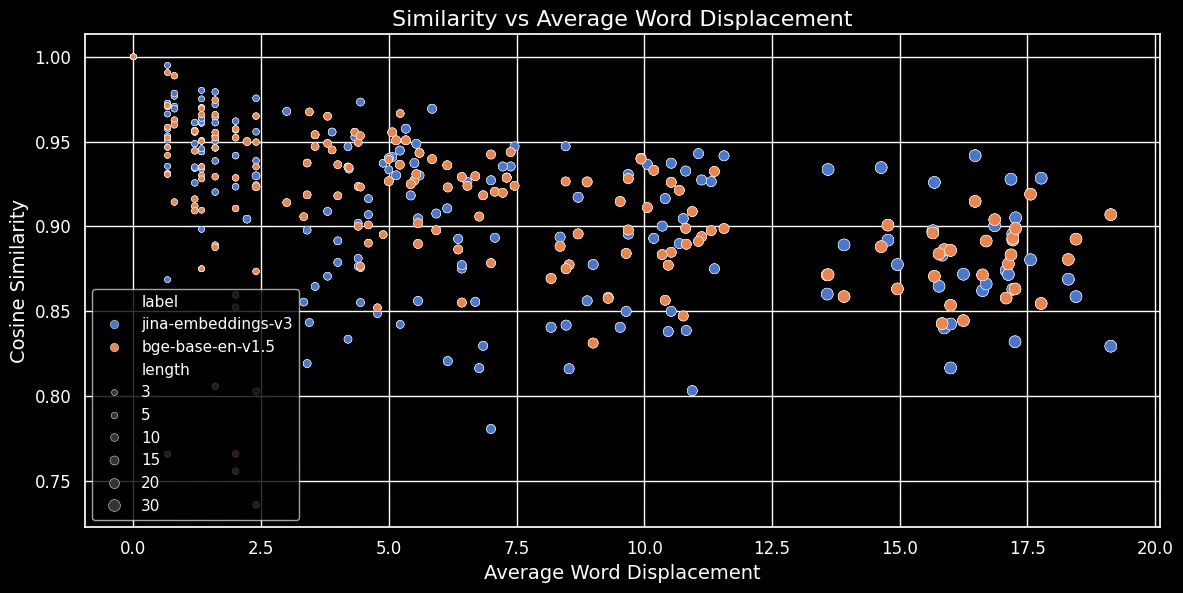
Вложения токенов зависят от локального контекста, то есть от слов, находящихся ближе всего к ним. В коротком тексте перестановка слов не может сильно изменить этот контекст. Однако в более длинном тексте слово может быть перемещено очень далеко от своего исходного контекста, что может значительно изменить его токенное вложение. В результате перемешивание слов в более длинном тексте создает более отдаленное вложение, чем в коротком. На рисунке выше показано, что как для jina-embeddings-v3 с использованием усреднения, так и для bge-base-en-v1.5 с использованием CLS-пулинга, действует одна и та же закономерность: перемешивание более длинных текстов и большее смещение слов приводят к меньшим показателям сходства.
tagРешают ли проблему большие модели?
Обычно, когда мы сталкиваемся с такого рода проблемой, распространенной тактикой является использование более крупной модели. Но может ли большая модель вложения текста действительно эффективнее захватывать информацию о порядке слов? Согласно закону масштабирования моделей текстовых вложений (упомянутому в нашем посте о релизе jina-embeddings-v3), более крупные модели обычно обеспечивают лучшую производительность:
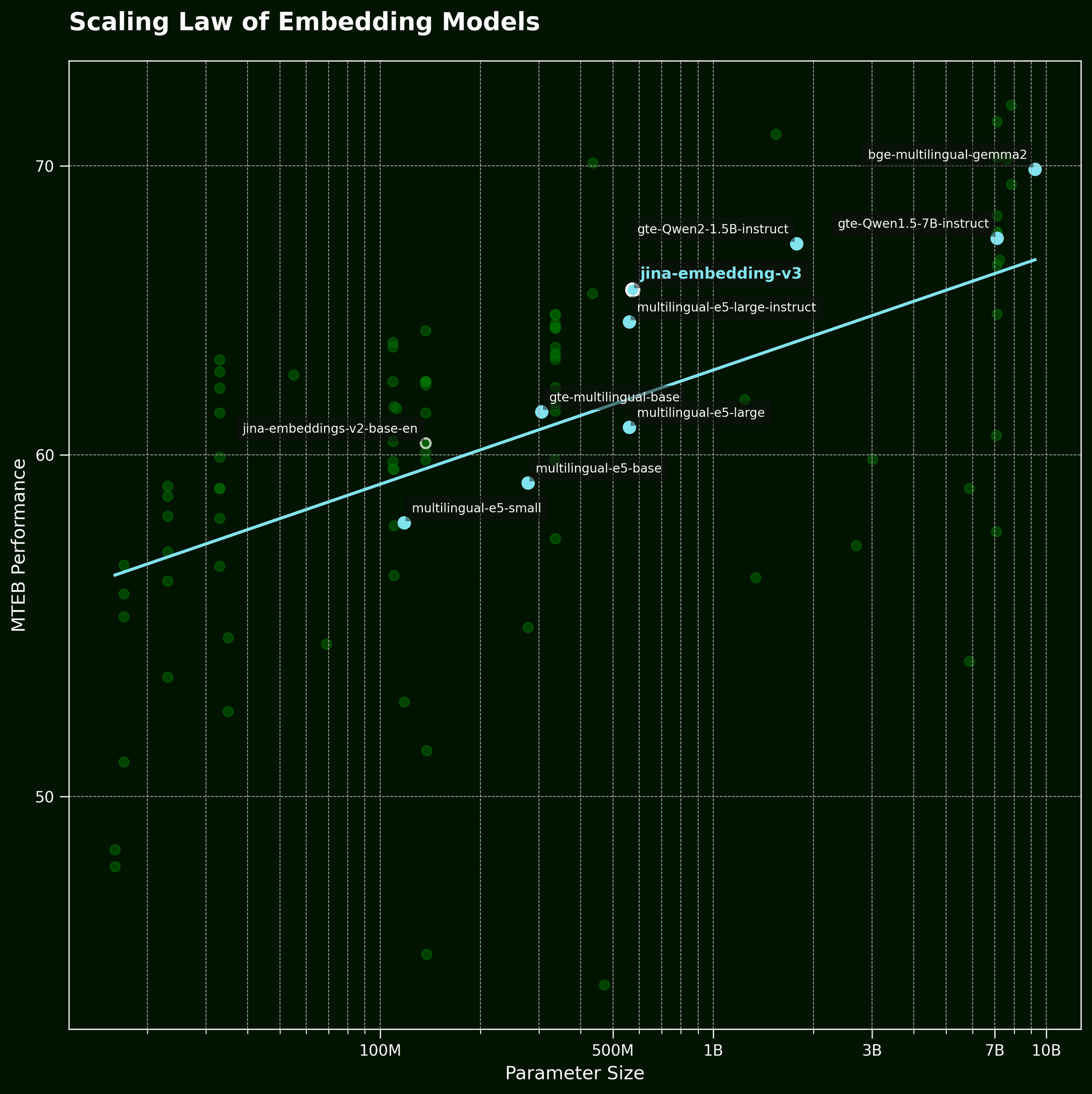
Но может ли более крупная модель эффективнее захватывать информацию о порядке слов? Мы протестировали три варианта модели BGE: bge-small-en-v1.5, bge-base-en-v1.5 и bge-large-en-v1.5, с размерами параметров 33 миллиона, 110 миллионов и 335 миллионов соответственно.
Мы будем использовать те же 180 предложений, что и раньше, но без учета информации о длине. Мы закодируем как исходные предложения, так и их случайные перестановки, используя три варианта модели, и построим график среднего косинусного сходства:
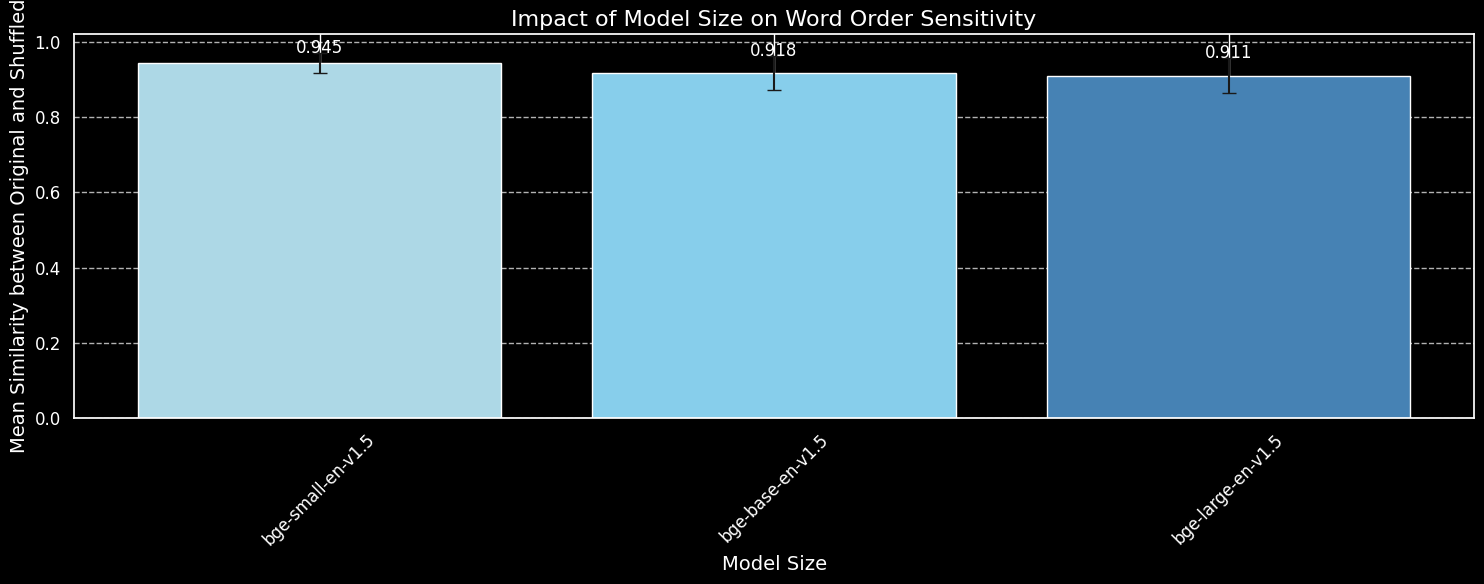
bge-small-en-v1.5, bge-base-en-v1.5 и bge-large-en-v1.5.Хотя мы видим, что более крупные модели более чувствительны к вариациям порядка слов, разница небольшая. Даже значительно более крупная bge-large-en-v1.5 лишь немного лучше различает перемешанные предложения от неперемешанных. Другие факторы играют роль в определении того, насколько чувствительна модель вложений к перестановкам слов, особенно различия в режиме обучения. Более того, косинусное сходство - это очень ограниченный инструмент для измерения способности модели проводить различия. Однако мы видим, что размер модели не является основным фактором. Мы не можем просто увеличить нашу модель и решить эту проблему.
tagПорядок слов и выбор слов в реальном мире
jina-embeddings-v2 (не нашу самую последнюю модель, jina-embeddings-v3), поскольку v2 намного меньше и, следовательно, быстрее для экспериментов на наших локальных GPU, имея 137 млн параметров против 580 млн у v3.Как мы упоминали во введении, порядок слов - не единственная проблема для моделей вложений. Более реалистичная проблема в реальном мире связана с выбором слов. Существует много способов поменять слова в предложении - способов, которые плохо отражаются во вложениях. Мы можем взять "Она летела из Парижа в Токио" и изменить его на "Она ехала из Токио в Париж", и вложения остаются похожими. Мы отобразили это по нескольким категориям изменений:
| Категория | Пример - Слева | Пример - Справа | Косинусное сходство (jina) |
|---|---|---|---|
| Направление | Она летела из Парижа в Токио | Она ехала из Токио в Париж | 0.9439 |
| Временная | Она поужинала перед просмотром фильма | Она посмотрела фильм перед ужином | 0.9833 |
| Причинная | Повышение температуры растопило снег | Тающий снег охладил температуру | 0.8998 |
| Сравнительная | Кофе вкуснее чая | Чай вкуснее кофе | 0.9457 |
| Отрицание | Он стоит возле стола | Он стоит далеко от стола | 0.9116 |
Таблица выше показывает список "проблемных случаев", когда модель текстовых эмбеддингов не справляется с тонкими изменениями слов. Это соответствует нашим ожиданиям: модели текстовых эмбеддингов не обладают способностью к рассуждению. Например, модель не понимает отношений между "из" и "в". Модели текстовых эмбеддингов выполняют семантическое сопоставление, где семантика обычно захватывается на уровне токенов и затем сжимается в единый плотный вектор после объединения. В отличие от этого, LLM (авторегрессивные модели), обученные на больших наборах данных триллионного масштаба, начинают демонстрировать возникающие способности к рассуждению.
Это заставило нас задуматься: можем ли мы дообучить модель эмбеддингов с помощью контрастивного обучения, используя триплеты, чтобы приблизить запрос и положительный пример, одновременно отдаляя запрос от отрицательного примера?

Например, "Рейс из Амстердама в Берлин" можно рассматривать как отрицательную пару для "Рейс из Берлина в Амстердам". Фактически, в техническом отчете jina-embeddings-v1 (Michael Guenther и др.), мы кратко рассмотрели этот вопрос в небольшом масштабе: мы дообучили модель jina-embeddings-v1 на наборе данных с отрицаниями, содержащем 10 000 примеров, сгенерированных большими языковыми моделями.

Результаты, представленные в отчете по ссылке выше, были многообещающими:
Мы наблюдаем, что для всех размеров моделей дообучение на данных с триплетами (включая наш набор данных с отрицаниями) значительно улучшает производительность, особенно в задаче HardNegation.
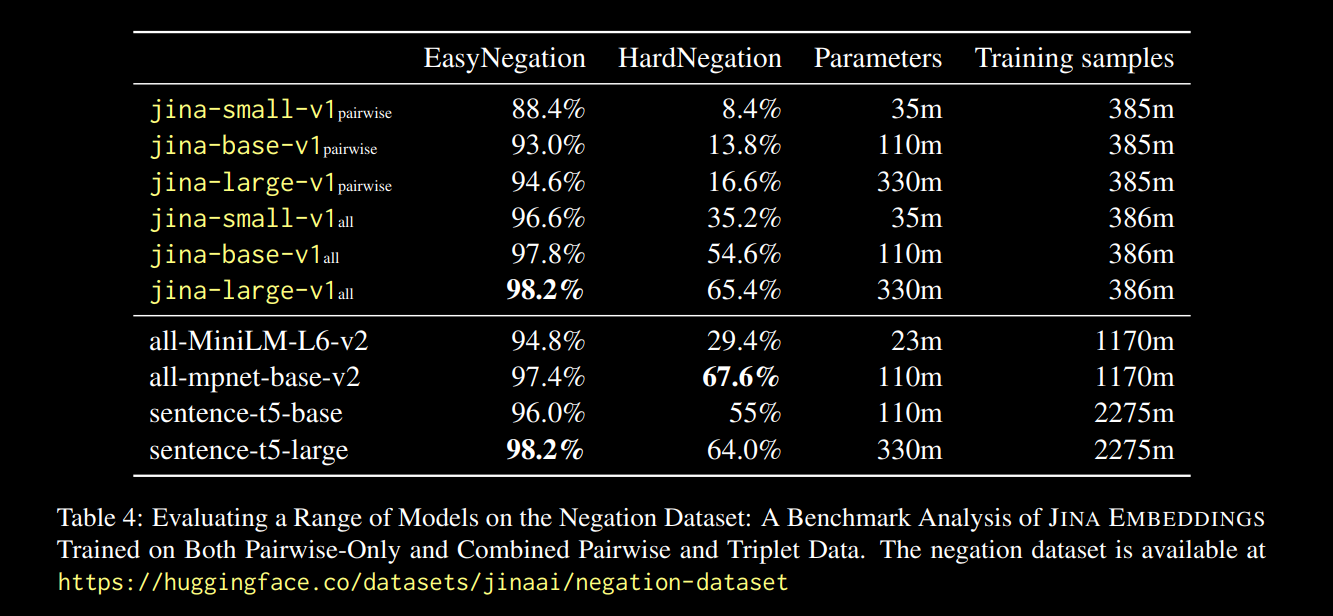
jina-embeddings с попарным и комбинированным триплетным/попарным обучением.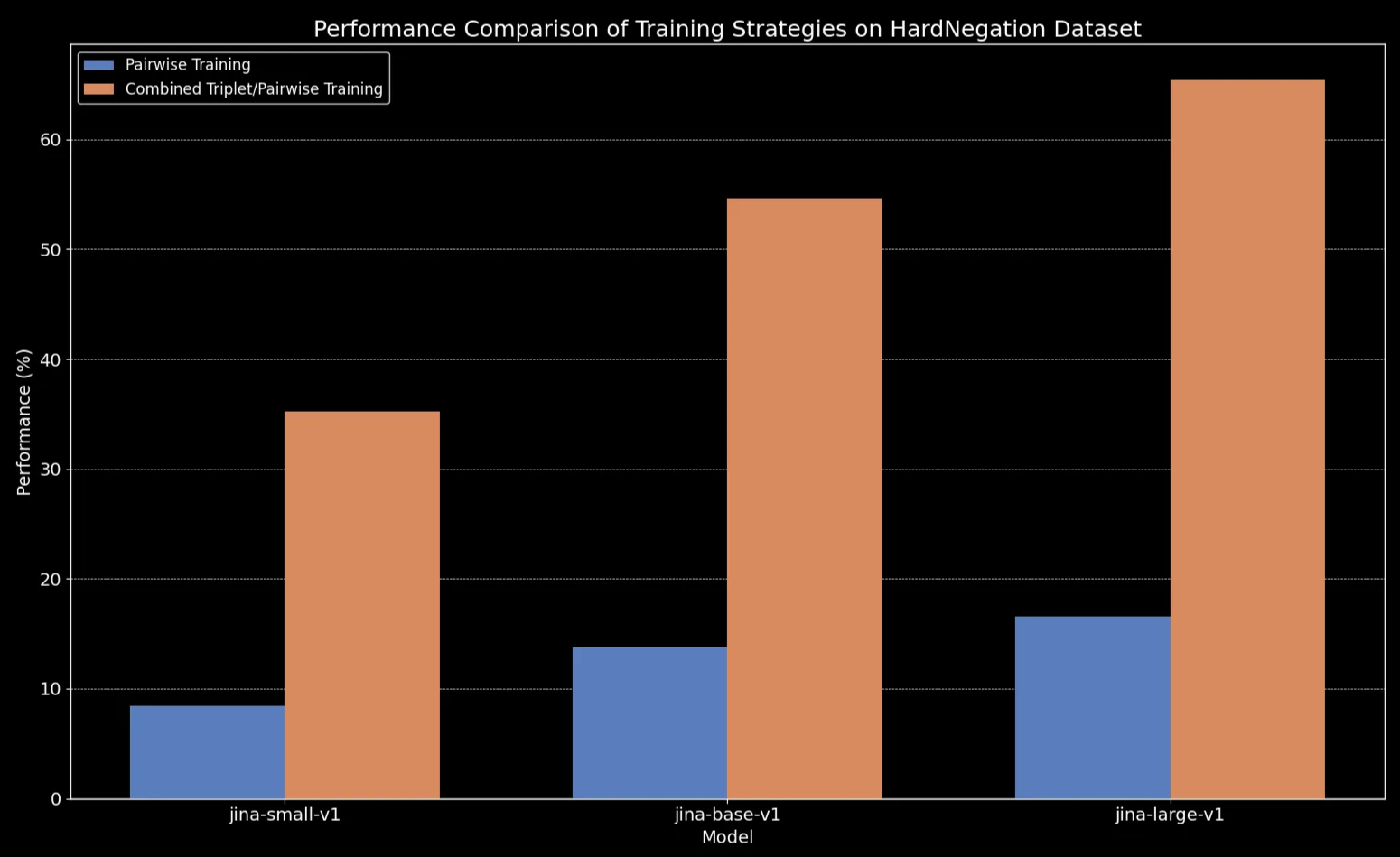
jina-embeddings.tagДообучение моделей текстовых эмбеддингов на курированных наборах данных
В предыдущих разделах мы изучили несколько ключевых наблюдений относительно текстовых эмбеддингов:
- Короткие тексты более подвержены ошибкам в захвате порядка слов.
- Увеличение размера модели текстовых эмбеддингов не обязательно улучшает понимание порядка слов.
- Контрастивное обучение может предложить потенциальное решение этих проблем.
Учитывая это, мы дообучили jina-embeddings-v2-base-en и bge-base-en-1.5 на наших наборах данных с отрицаниями и порядком слов (всего около 11 000 обучающих примеров):


Чтобы помочь оценить дообучение, мы создали набор данных из 1 000 триплетов, состоящих из query, positive (pos) и negative (neg) случаев:

Вот пример строки:
| Anchor | The river flows from the mountains to the sea |
| Positive | Water travels from mountain peaks to ocean |
| Negative | The river flows from the sea to the mountains |
Эти триплеты разработаны для охвата различных проблемных случаев, включая изменения смысла из-за порядка слов в направлении, времени и причинно-следственных связях.
Теперь мы можем оценить модели на трех разных наборах для оценки:
- Набор из 180 синтетических предложений (из предыдущей части этого поста), случайно перемешанных.
- Пять вручную проверенных примеров (из таблицы направлений/причинно-следственных связей и т.д. выше).
- 94 курированных триплета из нашего набора данных с триплетами, который мы только что создали.
Вот разница для перемешанных предложений до и после дообучения:
| Длина предложения (токены) | Среднее косинусное сходство (jina) |
Среднее косинусное сходство (jina-ft) |
Среднее косинусное сходство (bge) |
Среднее косинусное сходство (bge-ft) |
|---|---|---|---|---|
| 3 | 0.970 | 0.927 | 0.929 | 0.899 |
| 5 | 0.958 | 0.910 | 0.940 | 0.916 |
| 10 | 0.953 | 0.890 | 0.934 | 0.910 |
| 15 | 0.930 | 0.830 | 0.912 | 0.875 |
| 20 | 0.916 | 0.815 | 0.901 | 0.879 |
| 30 | 0.927 | 0.819 | 0.877 | 0.852 |
Результат кажется очевидным: несмотря на то, что процесс дообучения занял всего пять минут, мы видим значительное улучшение производительности на наборе данных со случайно перемешанными предложениями:
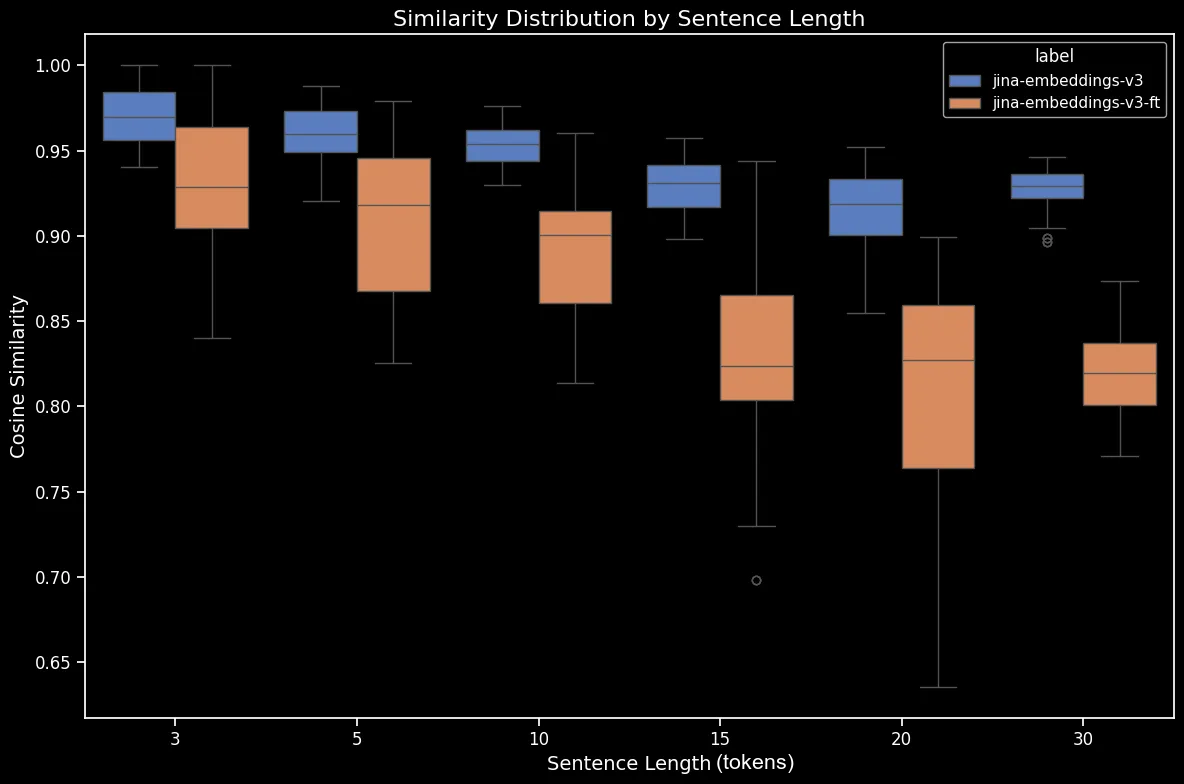
bge-base-en-1.5 (после дообучения).Мы также наблюдаем улучшения в случаях с направлением, временем, причинно-следственными связями и сравнениями. Модель показывает существенное улучшение производительности, что отражается в снижении усредненного косинусного сходства. Наибольший прирост производительности наблюдается в случае отрицания, благодаря тому, что наш набор данных для дообучения содержал 10 000 примеров с отрицанием.
| Категория | Пример - Левый | Пример - Правый | Среднее косинусное сходство (jina) |
Среднее косинусное сходство (jina-ft) |
Среднее косинусное сходство (bge) |
Среднее косинусное сходство (bge-ft) |
|---|---|---|---|---|---|---|
| Направление | She flew from Paris to Tokyo. | She drove from Tokyo to Paris | 0.9439 | 0.8650 | 0.9319 | 0.8674 |
| Время | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 | 0.9263 | 0.9683 | 0.9331 |
| Причина | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 | 0.7937 | 0.8874 | 0.8371 |
| Сравнение | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 | 0.8759 | 0.9723 | 0.9030 |
| Отрицание | He is standing by the table | He is standing far from the table | 0.9116 | 0.4478 | 0.8329 | 0.4329 |
tagЗаключение
В этой статье мы углубились в проблемы, с которыми сталкиваются модели текстовых эмбеддингов, особенно в их трудностях с эффективной обработкой порядка слов. Если разбить по категориям, мы выделили пять основных типов ошибок: Направление, Время, Причина, Сравнение и Отрицание. Это те типы запросов, где порядок слов действительно важен, и если ваш случай использования включает любой из них, стоит знать об ограничениях этих моделей.
Мы также провели быстрый эксперимент, расширив набор данных, ориентированный на отрицание, чтобы охватить все пять категорий ошибок. Результаты оказались многообещающими: дообучение с тщательно подобранными "сложными негативными примерами" улучшило способность модели распознавать, какие элементы связаны между собой, а какие нет. Тем не менее, предстоит еще много работы. Будущие шаги включают более глубокое изучение того, как размер и качество набора данных влияют на производительность.
