


При экспериментах с моделями в стиле ColPali один из наших инженеров создал визуализацию с использованием недавно выпущенной модели jina-clip-v2. Он отобразил схожесть между эмбеддингами токенов и эмбеддингами патчей для заданных пар изображение-текст, создав тепловые карты наложения, которые дали интересные визуальные результаты.

К сожалению, это всего лишь эвристическая визуализация — а не явный или гарантированный механизм. Хотя глобальное контрастное выравнивание в стиле CLIP может (и часто действительно) случайно создавать грубые локальные выравнивания между патчами и токенами, это непреднамеренный побочный эффект, а не целенаправленная задача модели. Позвольте мне объяснить почему.
tagПонимание кода

Давайте разберем, что делает код на высоком уровне. Заметим, что jina-clip-v2 по умолчанию не предоставляет API для доступа к эмбеддингам на уровне токенов или патчей — для этой визуализации потребовалась некоторая последующая доработка.
Вычисление эмбеддингов на уровне слов
Установив model.text_model.output_tokens = True, вызов text_model(x=...,)[1] вернет второй элемент (batch_size, seq_len, embed_dim) для эмбеддингов токенов. Таким образом, он принимает входное предложение, токенизирует его с помощью токенизатора Jina CLIP, а затем группирует подсловные токены обратно в "слова" путем усреднения соответствующих эмбеддингов токенов. Он определяет начало нового слова, проверяя, начинается ли строка токена с символа _ (типично для токенизаторов на основе SentencePiece). В результате получается список эмбеддингов на уровне слов и список слов (так что "Dog" — это один эмбеддинг, "and" — один эмбеддинг и т.д.).
Вычисление эмбеддингов на уровне патчей
Для части обработки изображений vision_model(..., return_all_features=True) вернет (batch_size, n_patches+1, embed_dim), где первый токен — это токен [CLS]. Из этого код извлекает эмбеддинги для каждого патча (то есть токены патчей из vision transformer). Затем он изменяет форму этих эмбеддингов патчей в 2D сетку patch_side × patch_side, которая затем увеличивается до размера исходного изображения.
Визуализация схожести слов и патчей
Расчет схожести и последующая генерация тепловой карты — это стандартные методы интерпретации "после факта": вы берете эмбеддинг текста, вычисляете косинусную схожесть с каждым эмбеддингом патча и затем генерируете тепловую карту, показывающую, какие патчи имеют наибольшую схожесть с этим конкретным эмбеддингом токена. Наконец, код проходит через каждый токен в предложении, выделяет этот токен жирным шрифтом слева и накладывает тепловую карту схожести на исходное изображение справа. Все кадры объединяются в анимированный GIF.
tagЯвляется ли это значимым объяснением?
С чисто программной точки зрения — да, логика согласована и создаст тепловую карту для каждого токена. Вы получите серию кадров, которые показывают схожести патчей, так что скрипт "делает то, что обещает".
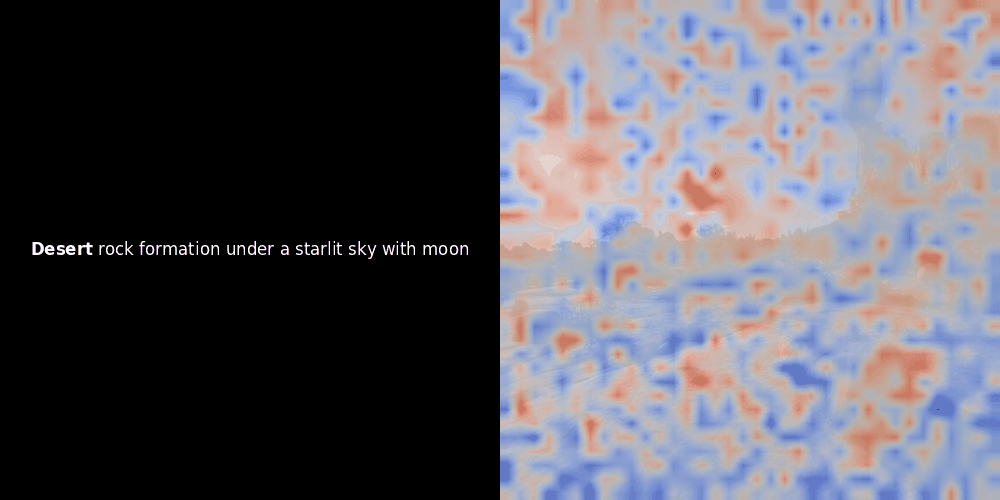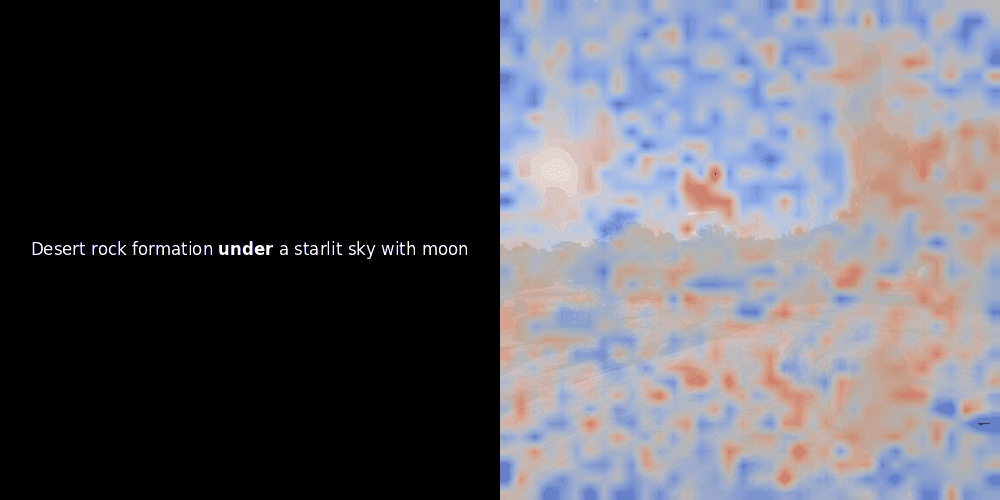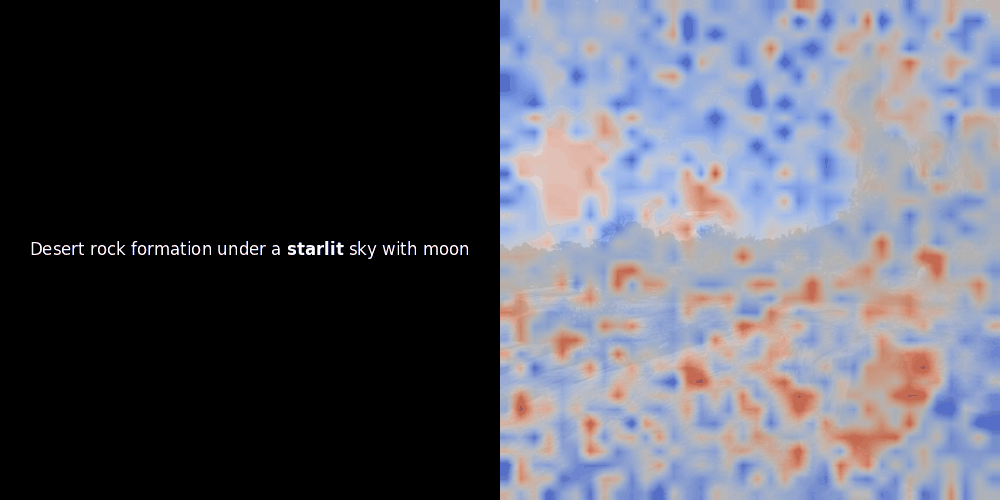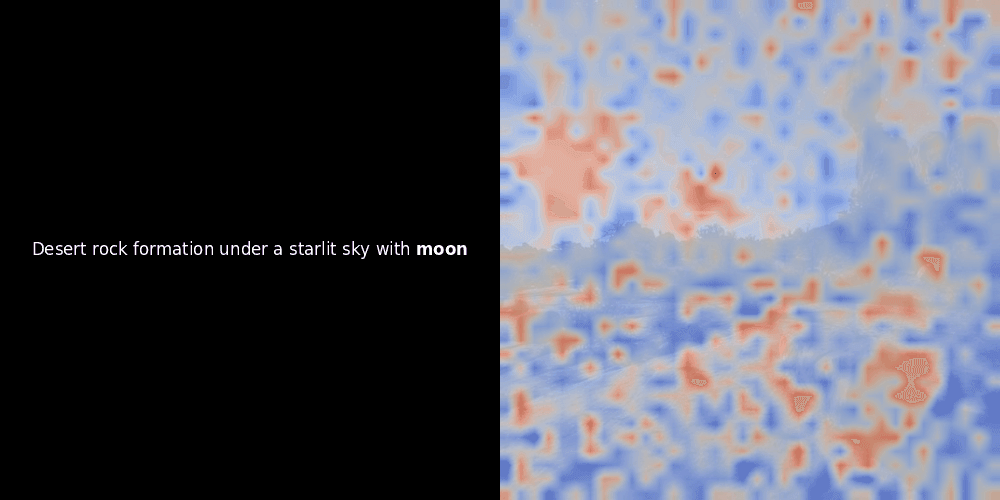

Глядя на примеры выше, мы видим, что слова вроде moon и branches как будто хорошо выравниваются с соответствующими визуальными патчами в исходном изображении. Но вот ключевой вопрос: это значимое выравнивание или мы просто видим удачное совпадение?
Это более глубокий вопрос. Чтобы понять ограничения, вспомним, как тренируется CLIP:

- CLIP использует глобальное контрастное выравнивание между целым изображением и целым текстом. Во время обучения энкодер изображения создает один вектор (объединенное представление), а текстовый энкодер создает другой вектор; CLIP тренируется так, чтобы они совпадали для соответствующих пар текст-изображение и не совпадали для других.
- Нет явного обучения на уровне 'патч X соответствует токену Y'. Модель не обучается напрямую выделять "эта область изображения — собака, та область — кошка" и т.д. Вместо этого она учится, что все представление изображения должно соответствовать всему представлению текста.
- Поскольку архитектура CLIP включает Vision Transformer для изображений и текстовый трансформер для текста — оба формируют отдельные энкодеры — в ней нет модуля кросс-внимания, который бы естественным образом выравнивал патчи с токенами. Вместо этого вы получаете только self-attention в каждой башне, плюс финальную проекцию для глобальных эмбеддингов изображения или текста.
Короче говоря, это эвристическая визуализация. То, что определенный эмбеддинг патча может быть близок или далек от конкретного эмбеддинга токена, является в некотором роде эмергентным свойством. Это скорее трюк интерпретации после факта, чем надежное или официальное "внимание" модели.
tagПочему может возникать локальное выравнивание?
Так почему же мы иногда замечаем локальные выравнивания на уровне слов-патчей? Вот в чем дело: даже несмотря на то, что CLIP тренируется на глобальной контрастной задаче изображение-текст, он все равно использует self-attention (в энкодерах изображений на основе ViT) и слои трансформера (для текста). Внутри этих слоев self-attention различные части представлений изображений могут взаимодействовать друг с другом, так же как это делают слова в текстовых представлениях. Через обучение на массивных наборах данных изображение-текст модель естественным образом развивает внутренние латентные структуры, которые помогают ей сопоставлять целые изображения с их соответствующими текстовыми описаниями.

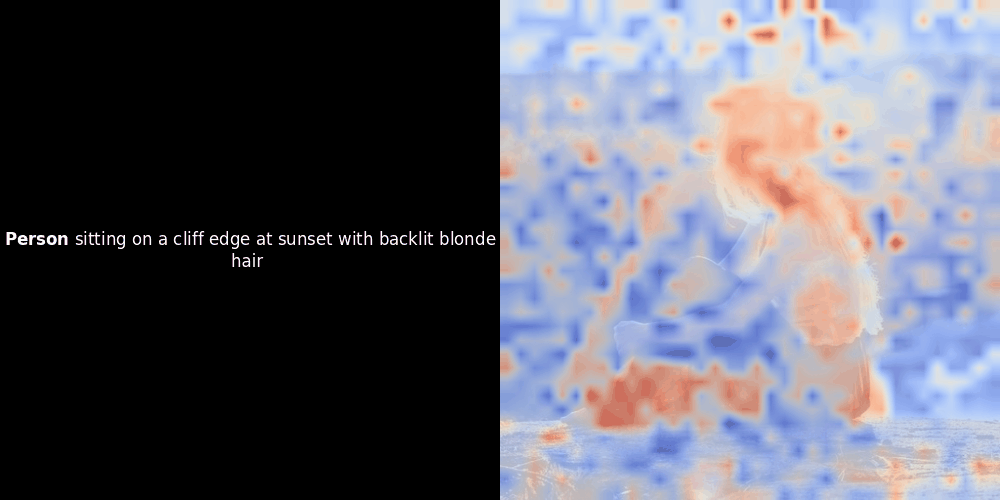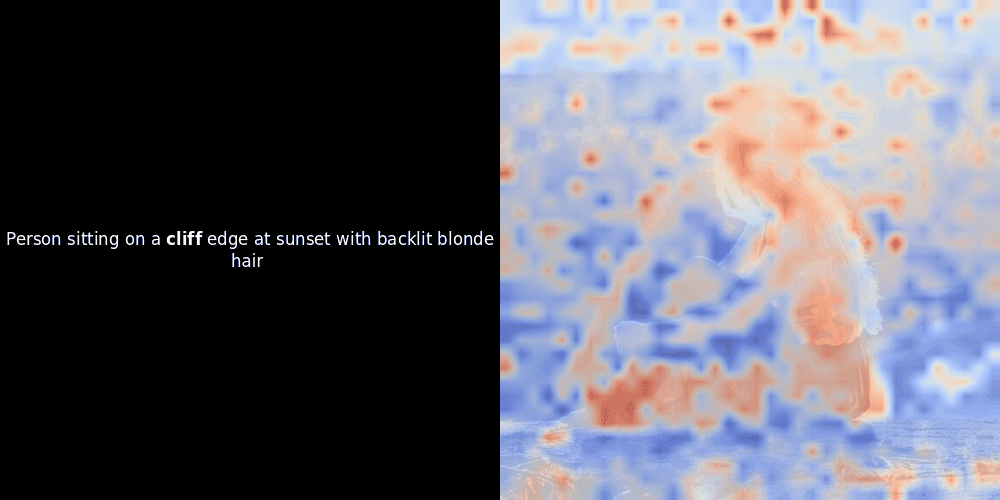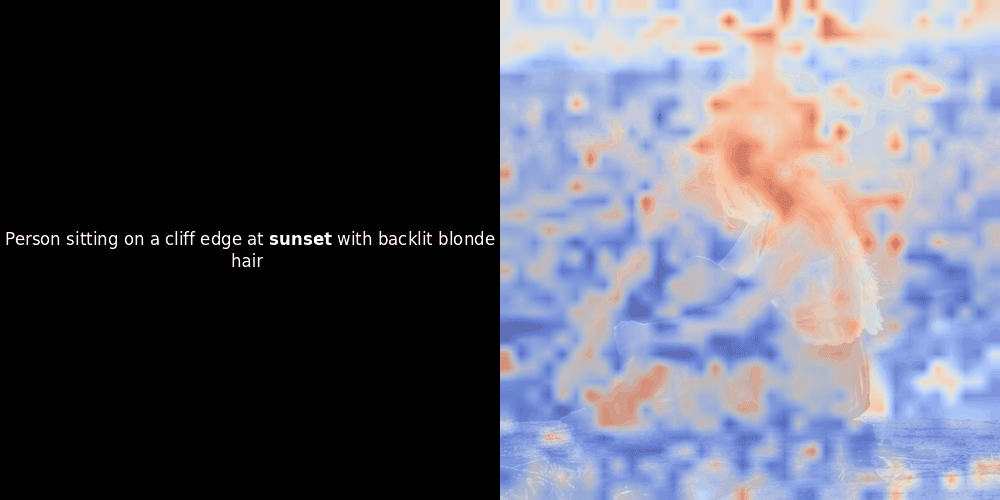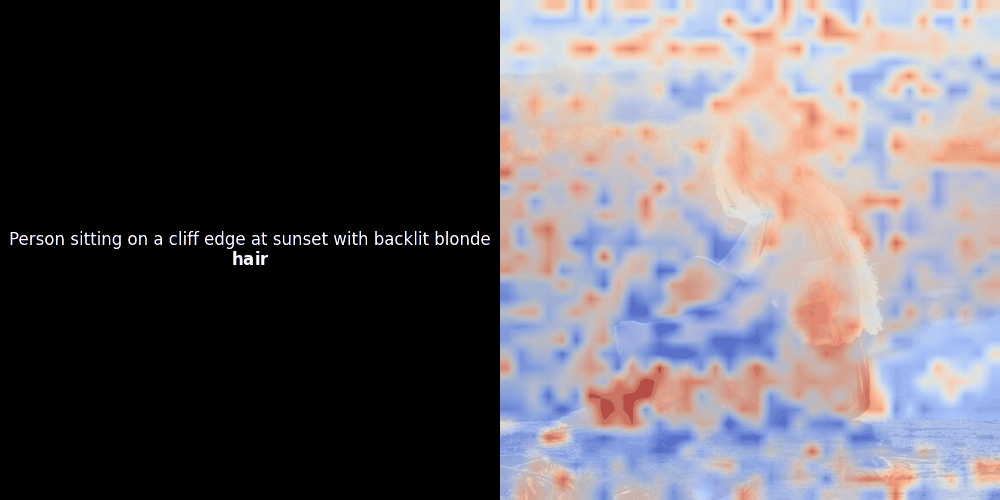
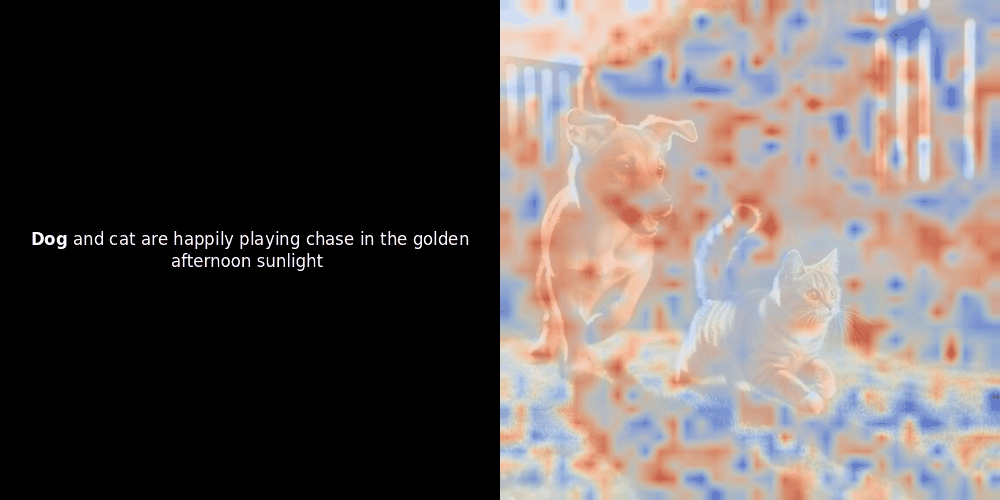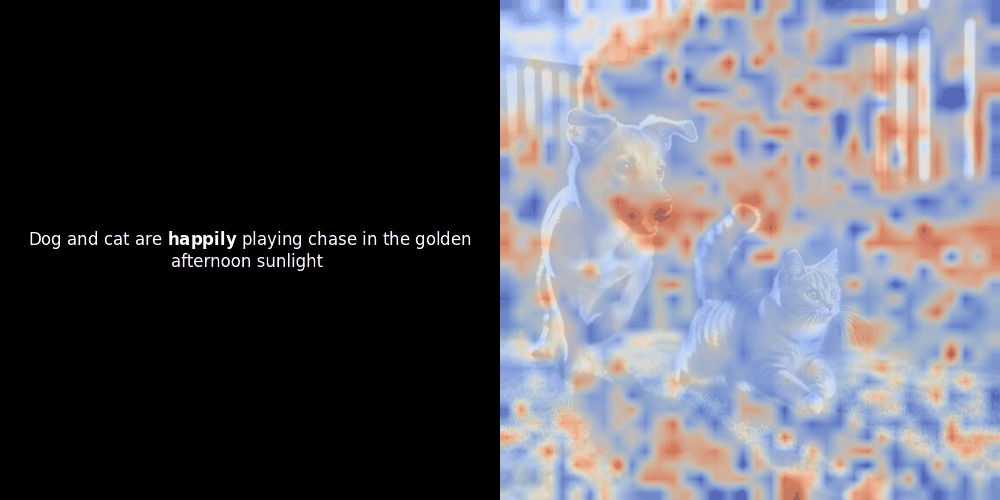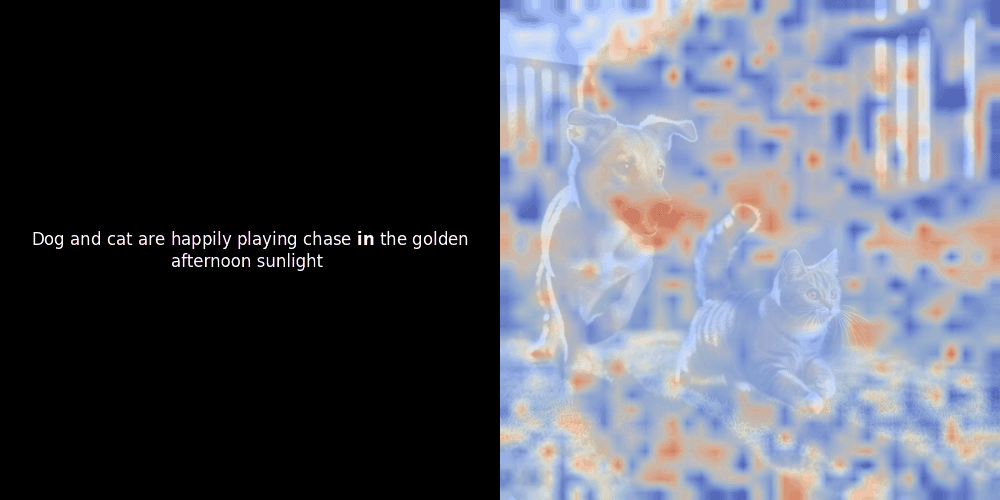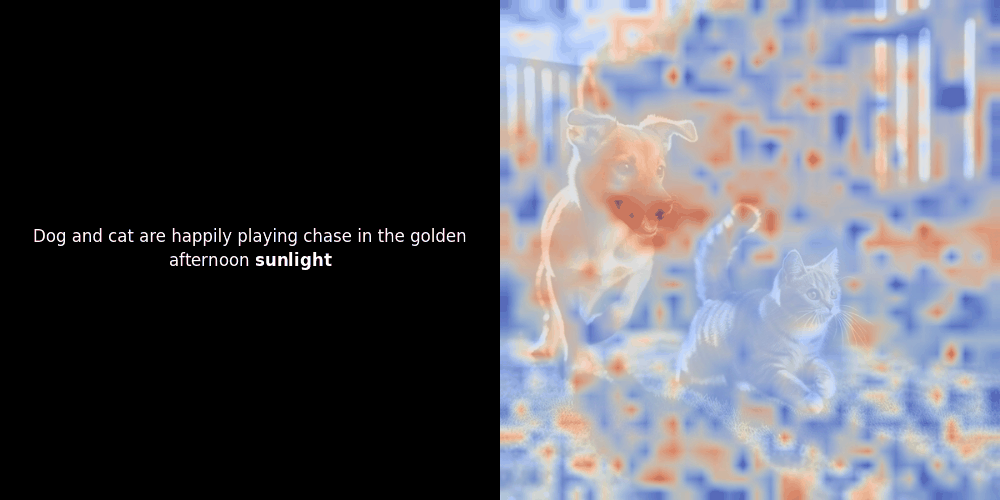
Локальное выравнивание может появляться в этих латентных представлениях по крайней мере по двум причинам:
- Паттерны совместной встречаемости: Если модель видит много изображений "собак" рядом со многими изображениями "кошек" (часто помеченных или описанных этими словами), она может изучить латентные признаки, которые примерно соответствуют этим концепциям. Таким образом, эмбеддинг для "собаки" может стать близким к локальным патчам, которые изображают собакоподобную форму или текстуру. Это не обучается явно на уровне патчей, но возникает из повторяющихся ассоциаций между парами изображений/текстов с собаками.
- Self-attention: В Vision Transformers патчи взаимодействуют друг с другом. Отличительные патчи (например, морда собаки) могут получить устойчивую латентную "подпись", поскольку модель пытается создать единое глобально точное представление всей сцены. Если это помогает минимизировать общую контрастивную потерю, это будет усиливаться.
tagТеоретический анализ
Контрастивная целевая функция CLIP направлена на максимизацию косинусного сходства между соответствующими парами изображение-текст при минимизации его для несоответствующих пар. Предположим, что текстовый и визуальный энкодеры создают токены и эмбеддинги патчей соответственно:
Глобальное сходство можно представить как совокупность локальных сходств:
Когда определенные пары токен-патч часто встречаются вместе в обучающих данных, модель усиливает их сходство через накопительные обновления градиента:
, где - количество совместных появлений. Это приводит к значительному увеличению , способствуя более сильному локальному выравниванию для этих пар. Однако контрастивная потеря распределяет обновления градиента по всем парам токен-патч, ограничивая силу обновлений для любой конкретной пары:
Это предотвращает значительное усиление индивидуальных сходств токен-патч.
tagЗаключение
Визуализация токен-патч в CLIP основывается на случайном, возникающем выравнивании между текстовыми и визуальными представлениями. Это выравнивание, хотя и интригующее, происходит из глобального контрастивного обучения CLIP и не обладает структурной надежностью, необходимой для точной и достоверной интерпретируемости. Получаемые визуализации часто демонстрируют шум и несогласованность, ограничивая их полезность для глубокого интерпретационного анализа.

Модели с поздним взаимодействием, такие как ColBERT и ColPali, решают эти ограничения путем архитектурного встраивания явных, детальных выравниваний между текстовыми токенами и патчами изображений. Обрабатывая модальности независимо и выполняя целенаправленные вычисления сходства на более поздней стадии, эти модели обеспечивают значимую связь каждого текстового токена с соответствующими областями изображения.
