



Семантические эмбеддинги являются основой современных моделей ИИ, включая чат-боты и модели генерации изображений. Иногда они скрыты от пользователей, но они всегда присутствуют, таясь прямо под поверхностью.
Теория эмбеддингов состоит всего из двух частей:
- Объекты — вещи вне модели ИИ, такие как тексты и изображения — представлены векторами, созданными моделями ИИ на основе данных об этих объектах.
- Отношения между объектами вне модели ИИ представлены пространственными отношениями между этими векторами. Мы специально обучаем модели ИИ создавать векторы, которые работают таким образом.
Когда мы создаем мультимодальную модель для работы с изображениями и текстом, мы обучаем модель так, чтобы эмбеддинги изображений и эмбеддинги текстов, описывающих или связанных с этими изображениями, находились относительно близко друг к другу. Семантические сходства между объектами, которые представляют эти два вектора — изображение и текст — отражаются в пространственном отношении между двумя векторами.
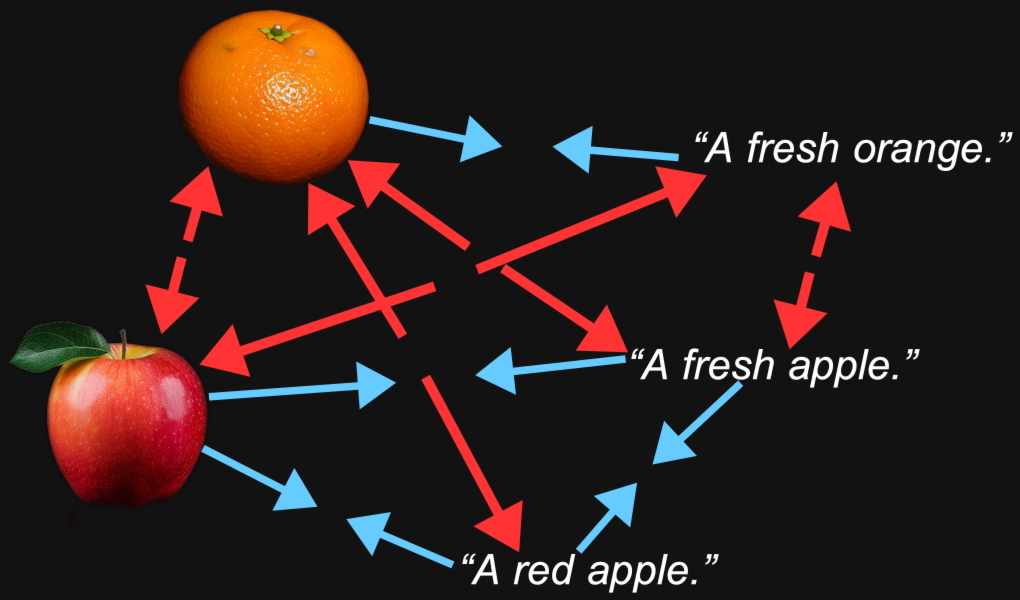
Например, мы можем разумно ожидать, что векторы эмбеддингов для изображения апельсина и текста "свежий апельсин" будут ближе друг к другу, чем то же изображение и текст "свежее яблоко".
Это и есть цель модели эмбеддингов: генерировать представления, где характеристики, которые нас интересуют — например, какой вид фрукта изображен на картинке или назван в тексте — сохраняются в расстоянии между ними.
Но мультимодальность привносит нечто еще. Мы можем обнаружить, что изображение апельсина находится ближе к изображению яблока, чем к тексту "свежий апельсин", и что текст "свежее яблоко" находится ближе к другому тексту, чем к изображению яблока.
Оказывается, именно это и происходит с мультимодальными моделями, включая собственную модель Jina AI — Jina CLIP (jina-clip-v1).
Чтобы проверить это, мы отобрали 1000 пар текст-изображение из тестового набора Flickr8k. Каждая пара содержит пять текстов-подписей (так что технически это не пара) и одно изображение, причем все пять текстов описывают одно и то же изображение.
Например, следующее изображение (1245022983_fb329886dd.jpg в наборе данных Flickr8k):

Его пять подписей:
A child in all pink is posing nearby a stroller with buildings in the distance.
A little girl in pink dances with her hands on her hips.
A small girl wearing pink dances on the sidewalk.
The girl in a bright pink skirt dances near a stroller.
The little girl in pink has her hands on her hips.
Мы использовали Jina CLIP для создания эмбеддингов изображений и текстов, а затем:
- Сравнили косинусное сходство эмбеддингов изображений с эмбеддингами их текстовых подписей.
- Взяли эмбеддинги всех пяти текстовых подписей, описывающих одно и то же изображение, и сравнили их косинусное сходство друг с другом.
Результат показал удивительно большой разрыв, что видно на Рисунке 1:
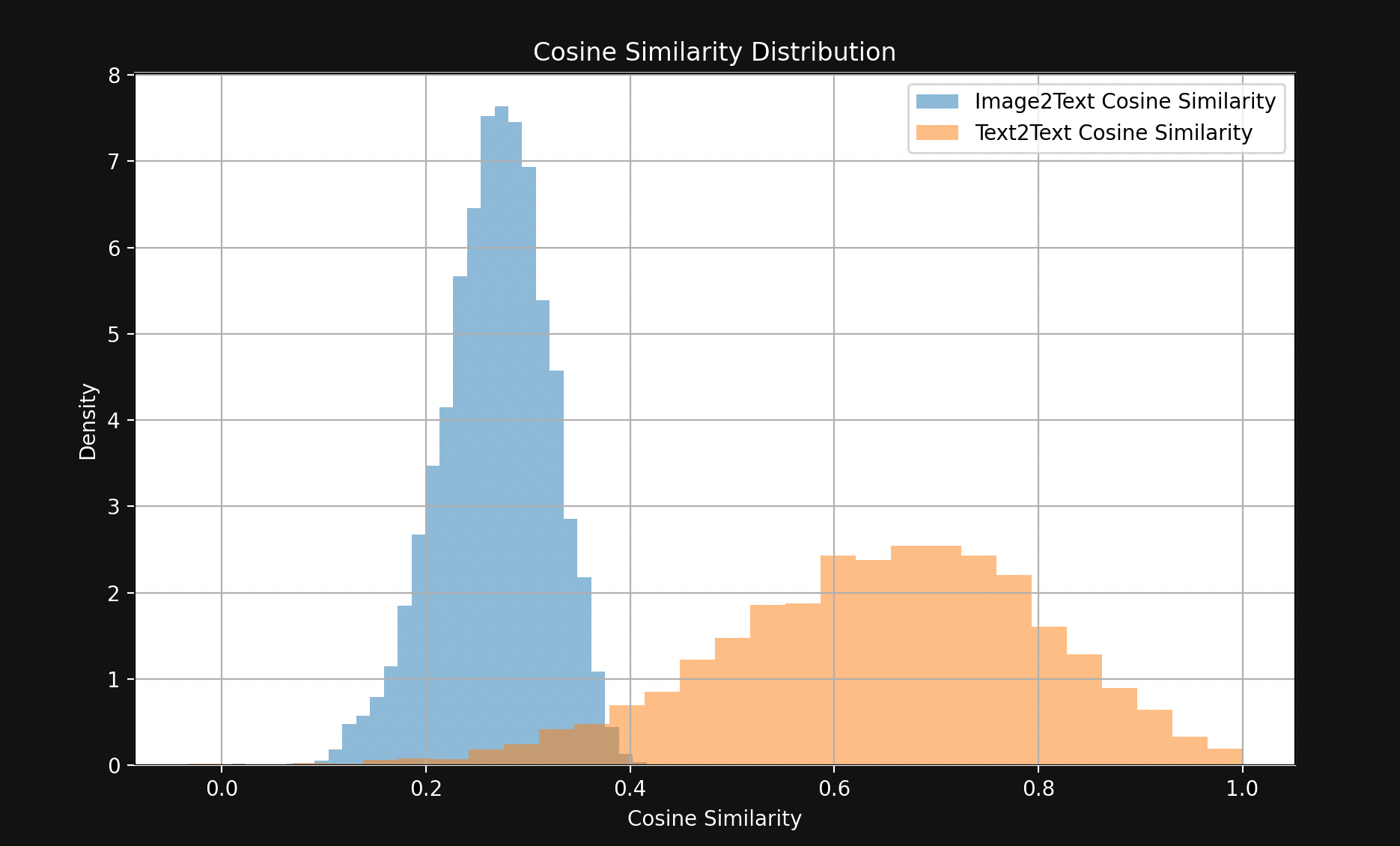
За редким исключением, соответствующие текстовые пары находятся гораздо ближе друг к другу, чем соответствующие пары изображение-текст. Это убедительно указывает на то, что Jina CLIP кодирует тексты в одной части пространства эмбеддингов, а изображения — в другой, в значительной степени непересекающейся части, относительно далеко от нее. Это пространство между текстами и изображениями называется мультимодальным разрывом.

Мультимодальные модели эмбеддингов кодируют не только семантическую информацию, которая нас интересует: они кодируют тип носителя их входных данных. Согласно Jina CLIP, изображение не стоит тысячи слов, как гласит поговорка. Оно содержит информацию, которую никакое количество слов никогда не сможет по-настоящему передать. Модель кодирует тип носителя входных данных в семантику своих эмбеддингов, хотя никто никогда не обучал ее этому.
Это явление было исследовано в статье Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning [Liang et al., 2022], где оно называется "модальным разрывом". Модальный разрыв — это пространственное разделение в пространстве эмбеддингов между входными данными одного типа носителя и входными данными другого. Хотя модели намеренно не обучаются иметь такой разрыв, он широко распространен в мультимодальных моделях.
Наши исследования модального разрыва в Jina CLIP во многом основаны на работе Liang et al. [2022].
tagОткуда берется модальный разрыв?
Liang et al. [2022] выделяют три основных источника модального разрыва:
- Смещение при инициализации, которое они называют "эффектом конуса".
- Снижение температуры (случайности) во время обучения, которое делает очень сложным "разучиться" этому смещению.
- Процедуры контрастного обучения, которые широко используются в мультимодальных моделях и непреднамеренно усиливают разрыв.
Рассмотрим каждый из них по очереди.
tagЭффект конуса
Модель, построенная с использованием архитектуры CLIP или CLIP-подобной архитектуры, фактически представляет собой две отдельные модели встраивания, соединенные вместе. Для мультимодальных моделей изображение-текст это означает одну модель для кодирования текстов и совершенно отдельную для кодирования изображений, как показано на схеме ниже.
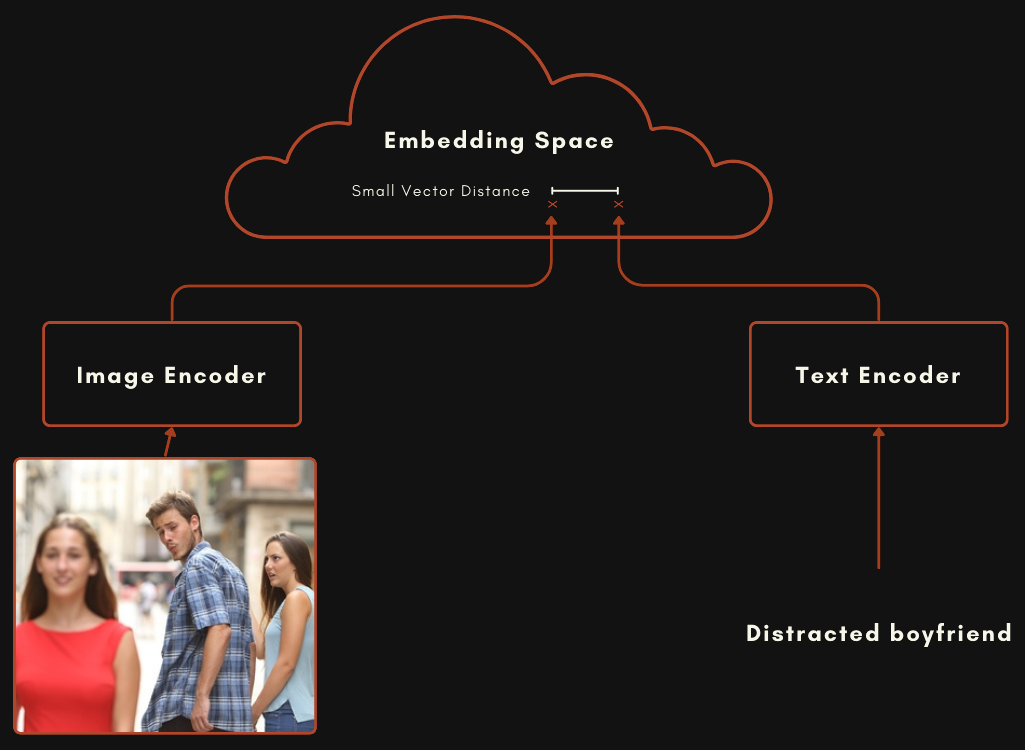
Эти две модели обучаются таким образом, что встраивание изображения и встраивание текста оказываются относительно близко друг к другу, когда текст хорошо описывает изображение.
Вы можете обучить такую модель, рандомизировав веса в обеих моделях, а затем представляя ей пары изображение-текст вместе, обучая её с нуля для минимизации расстояния между двумя выходами. Оригинальная модель OpenAI CLIP была обучена именно таким образом. Однако это требует большого количества пар изображение-текст и вычислительно затратного обучения. Для первой модели CLIP, OpenAI собрала 400 миллионов пар изображение-текст из подписанных материалов в Интернете.
Более новые CLIP-подобные модели используют предварительно обученные компоненты. Это означает отдельное обучение каждого компонента как хорошей одномодальной модели встраивания, одной для текстов и одной для изображений. Затем эти две модели дополнительно обучаются вместе с использованием пар изображение-текст, процесс, называемый контрастной настройкой. Согласованные пары изображение-текст используются для медленного "подталкивания" весов к тому, чтобы сделать соответствующие текстовые и изображенческие встраивания ближе друг к другу, а несоответствующие - дальше друг от друга.
Этот подход обычно требует меньше данных пар изображение-текст, которые сложно и дорого получить, и большого количества простых текстов и изображений без подписей, которые гораздо легче получить. Jina CLIP (jina-clip-v1) была обучена с использованием этого последнего метода. Мы предварительно обучили модель JinaBERT v2 для кодирования текста, используя общие текстовые данные, и использовали предварительно обученный кодировщик изображений EVA-02, затем дополнительно обучили их с использованием различных методик контрастного обучения, как описано в работе Koukounas et al. [2024]
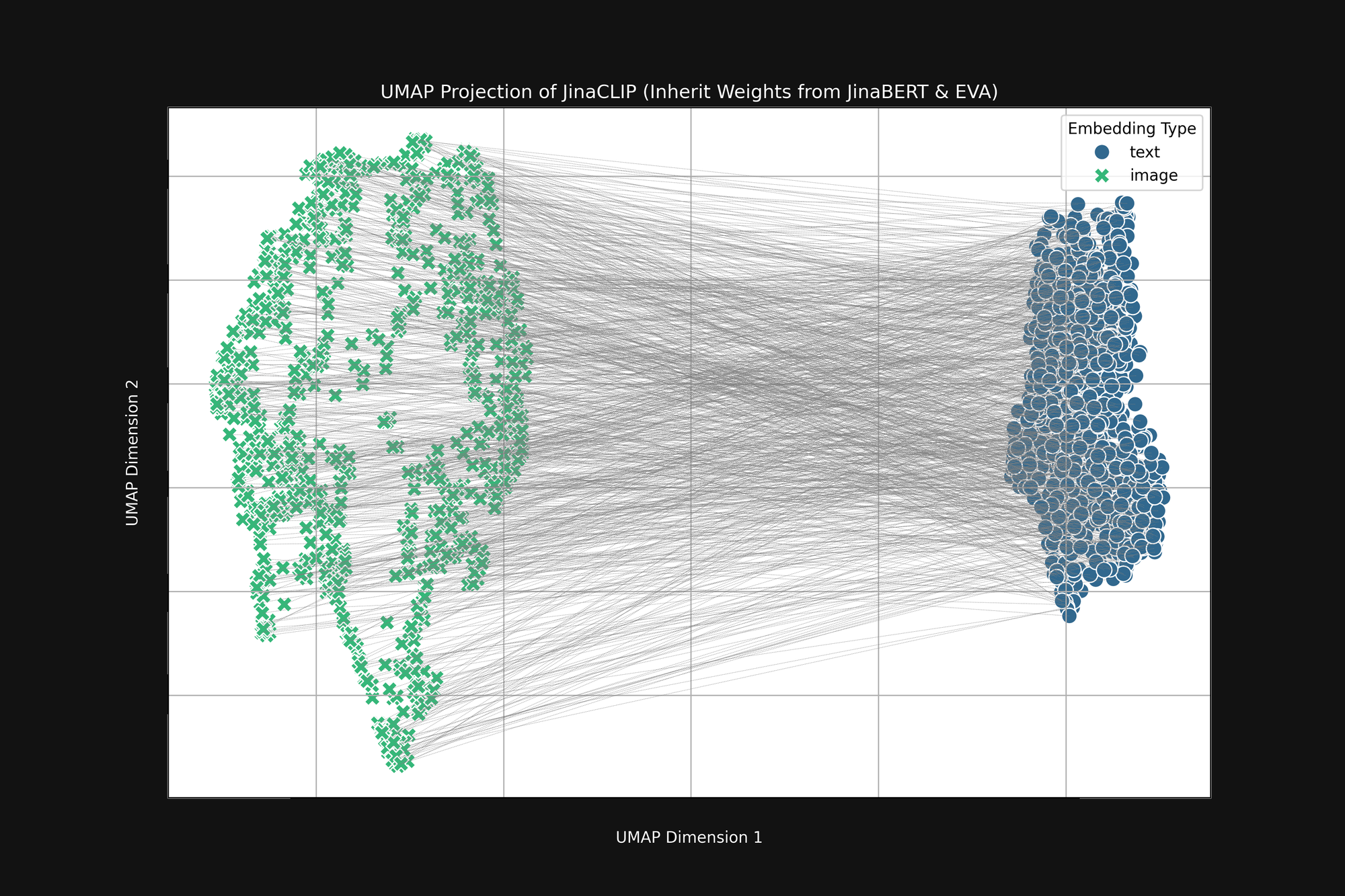
Если мы возьмем эти две предварительно обученные модели и посмотрим на их выход до обучения их с парами изображение-текст, мы заметим нечто важное. Рисунок 2 (выше) - это UMAP проекция в два измерения встраиваний изображений, созданных предварительно обученным кодировщиком EVA-02, и текстовых встраиваний, созданных предварительно обученным JinaBERT v2, где серые линии указывают на сопоставленные пары изображение-текст. Это до какого-либо кросс-модального обучения.
Результат представляет собой своего рода усеченный "конус", с встраиваниями изображений на одном конце и текстовыми встраиваниями на другом. Эта коническая форма плохо переводится в двумерные проекции, но вы можете в целом видеть её на изображении выше. Все тексты группируются в одной части пространства встраиваний, а все изображения - в другой. Если после обучения тексты все еще более похожи на другие тексты, чем на соответствующие изображения, это начальное состояние является главной причиной. Цель наилучшего сопоставления изображений с текстами, текстов с текстами и изображений с изображениями полностью совместима с этой конической формой.
Модель предвзята с рождения, и то, что она учит, не меняет этого. Рисунок 3 (ниже) - тот же анализ модели Jina CLIP после выпуска, после полного обучения с использованием пар изображение-текст. Если что, мультимодальный разрыв становится еще более выраженным.
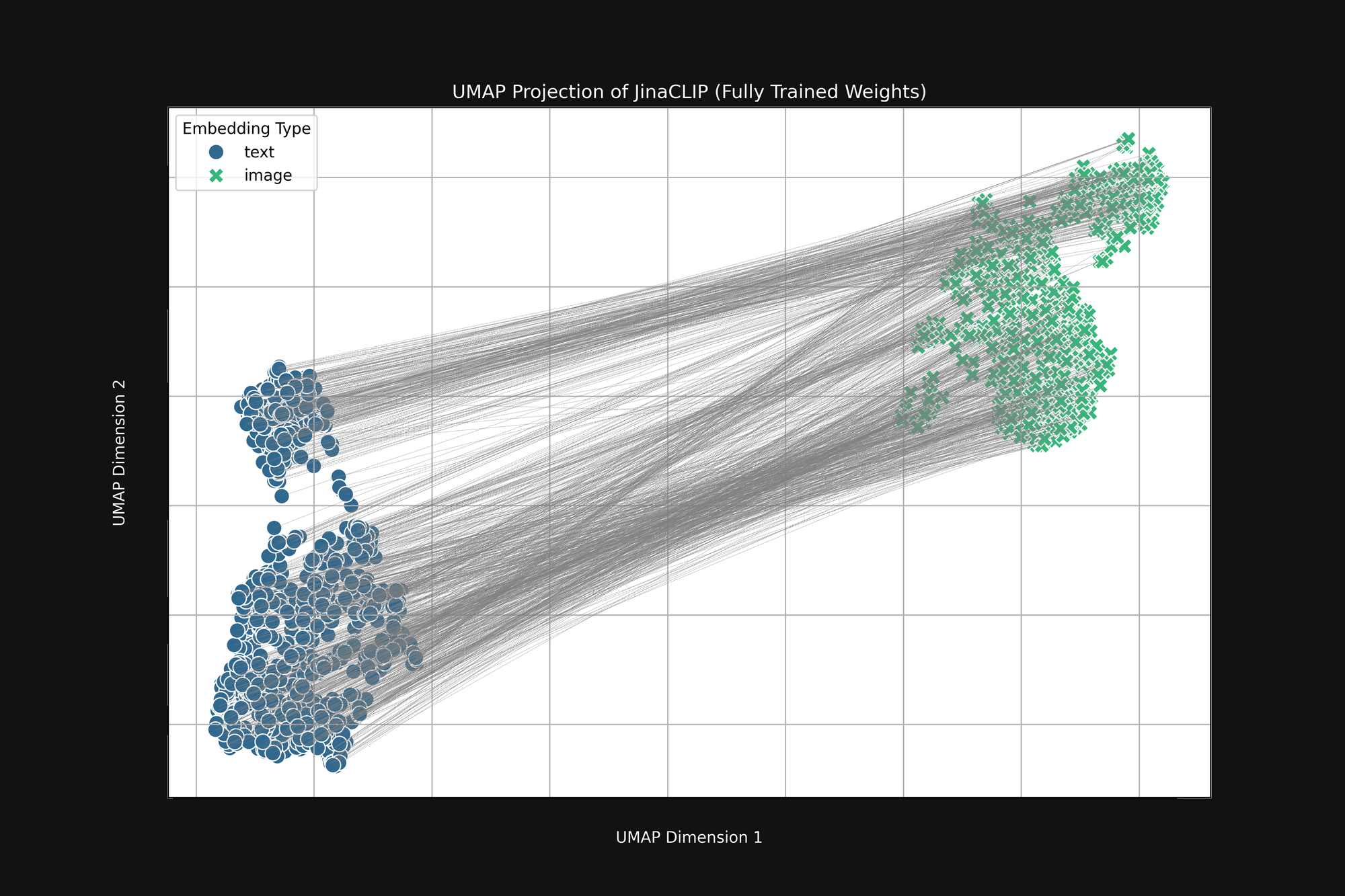
Даже после обширного обучения Jina CLIP все еще кодирует носитель как часть сообщения.
Использование более дорогостоящего подхода OpenAI с чисто случайной инициализацией не устраняет этого смещения. Мы взяли оригинальную архитектуру OpenAI CLIP и полностью рандомизировали все веса, затем провели тот же анализ, что и выше. Результат все равно имеет форму усеченного конуса, как показано на Рисунке 4:
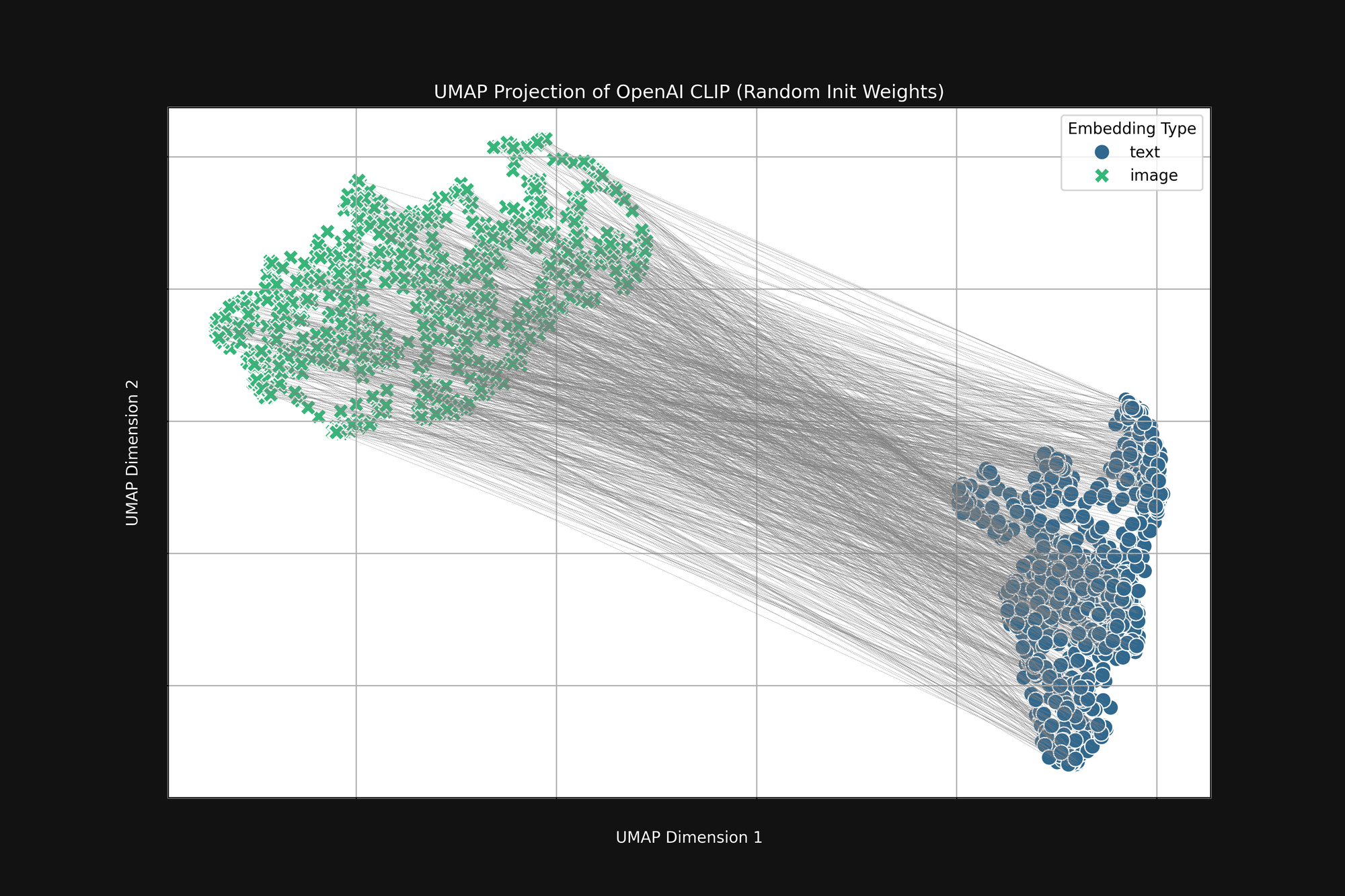
Это смещение является структурной проблемой и может не иметь решения. Если это так, мы можем только искать способы корректировки или смягчения его во время обучения.
tagТемпература обучения
Во время обучения моделей ИИ мы обычно добавляем некоторую случайность в процесс. Мы рассчитываем, насколько пакет обучающих образцов должен изменить веса в модели, затем добавляем небольшой случайный фактор к этим изменениям перед фактическим изменением весов. Мы называем количество случайности температурой, по аналогии с тем, как мы используем случайность в термодинамике.
Высокие температуры создают большие изменения в моделях очень быстро, в то время как низкие температуры уменьшают количество изменений, которые модель может сделать каждый раз, когда она видит некоторые обучающие данные. В результате при высоких температурах мы можем ожидать, что отдельные встраивания будут много перемещаться в пространстве встраиваний во время обучения, а при низких температурах они будут перемещаться гораздо медленнее.
Лучшей практикой для обучения моделей ИИ является начало с высокой температуры с последующим её постепенным снижением. Это помогает модели делать большие скачки в обучении в начале, когда веса либо случайны, либо далеки от того, где они должны быть, а затем позволяет ей более стабильно изучать детали.
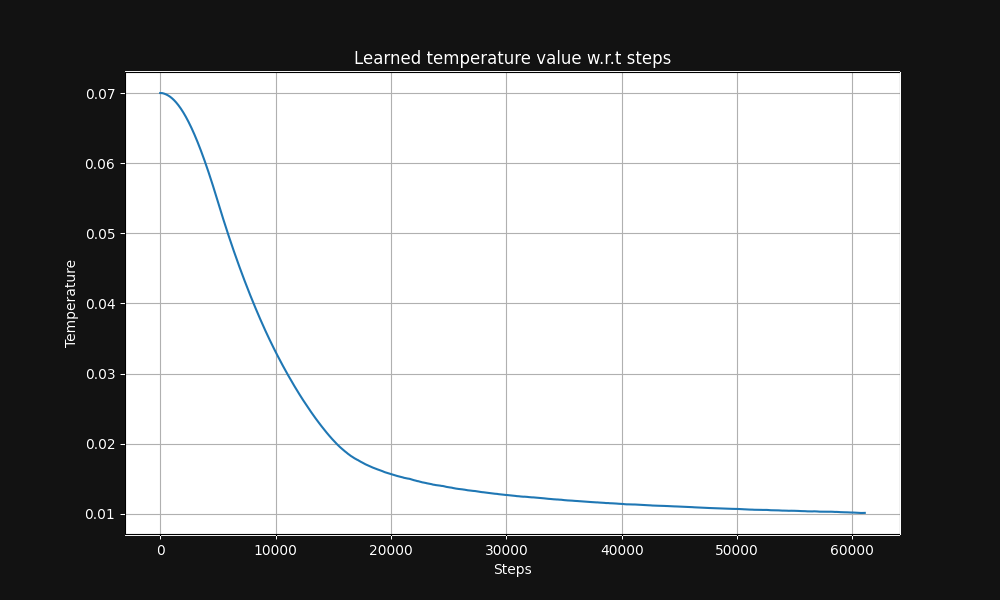
Парное обучение изображение-текст Jina CLIP начинается с температуры 0.07 (это относительно высокая температура) и экспоненциально снижает её в процессе обучения до 0.01, как показано на Рисунке 5 ниже, графике температуры относительно шагов обучения:
Мы хотели узнать, уменьшит ли повышение температуры — добавление случайности — конический эффект и приблизит ли встраивания изображений и текстовые встраивания в целом. Поэтому мы переобучили Jina CLIP с фиксированной температурой 0.1 (очень высокое значение). После каждой эпохи обучения мы проверяли распределение расстояний между парами изображение-текст и текст-текст, как на Рисунке 1. Результаты показаны ниже на Рисунке 6:
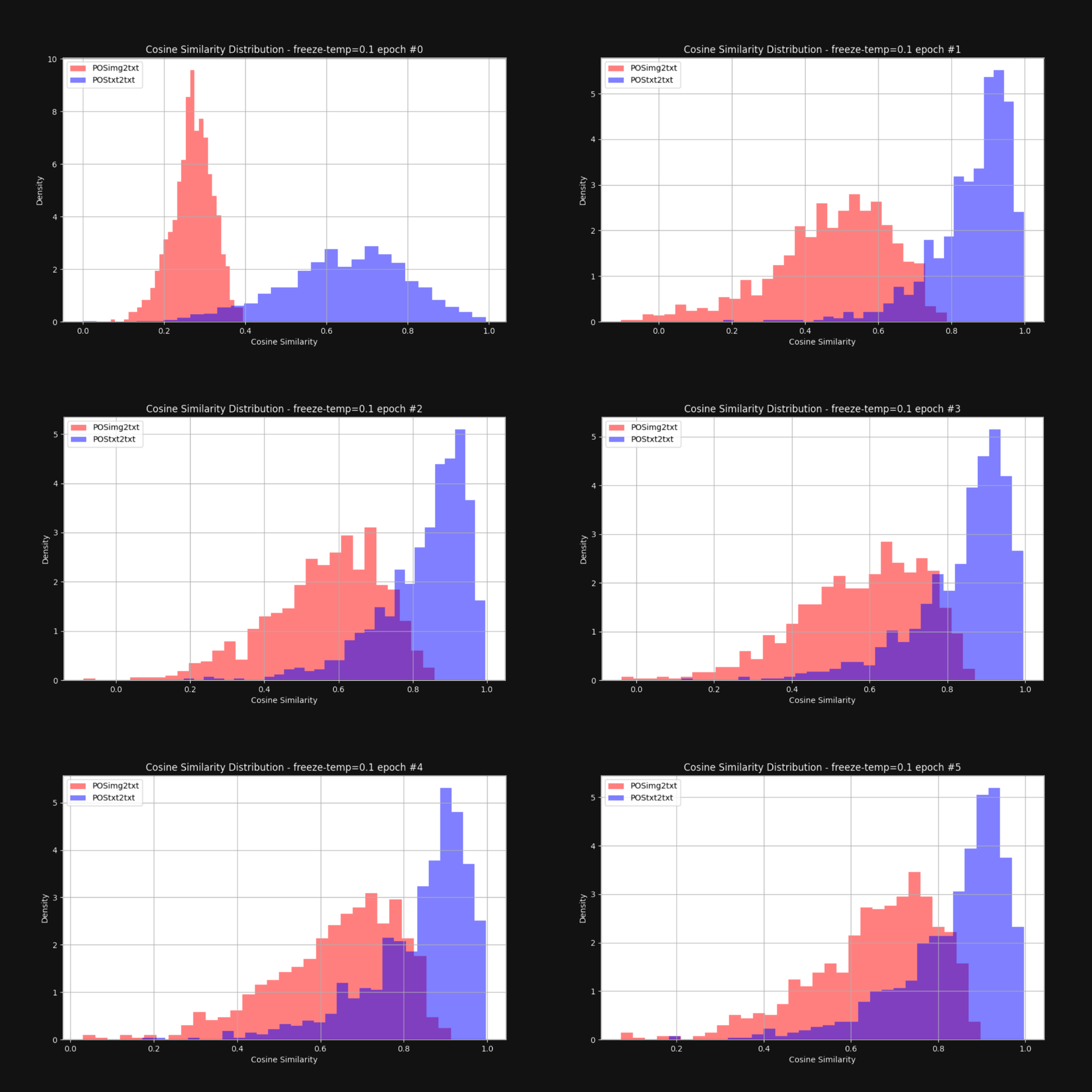
Как видите, поддержание высокой температуры действительно существенно сокращает мультимодальный разрыв. Возможность значительного перемещения эмбеддингов во время обучения во многом помогает преодолеть начальное смещение в их распределении.
Однако это имеет свою цену. Мы также протестировали производительность модели с помощью шести различных тестов поиска: трех тестов поиска текст-текст и трех тестов поиска текст-изображение, используя наборы данных MS-COCO, Flickr8k и Flickr30k. Во всех тестах мы наблюдаем резкое падение производительности в начале обучения и затем очень медленный рост, как показано на Рисунке 7:
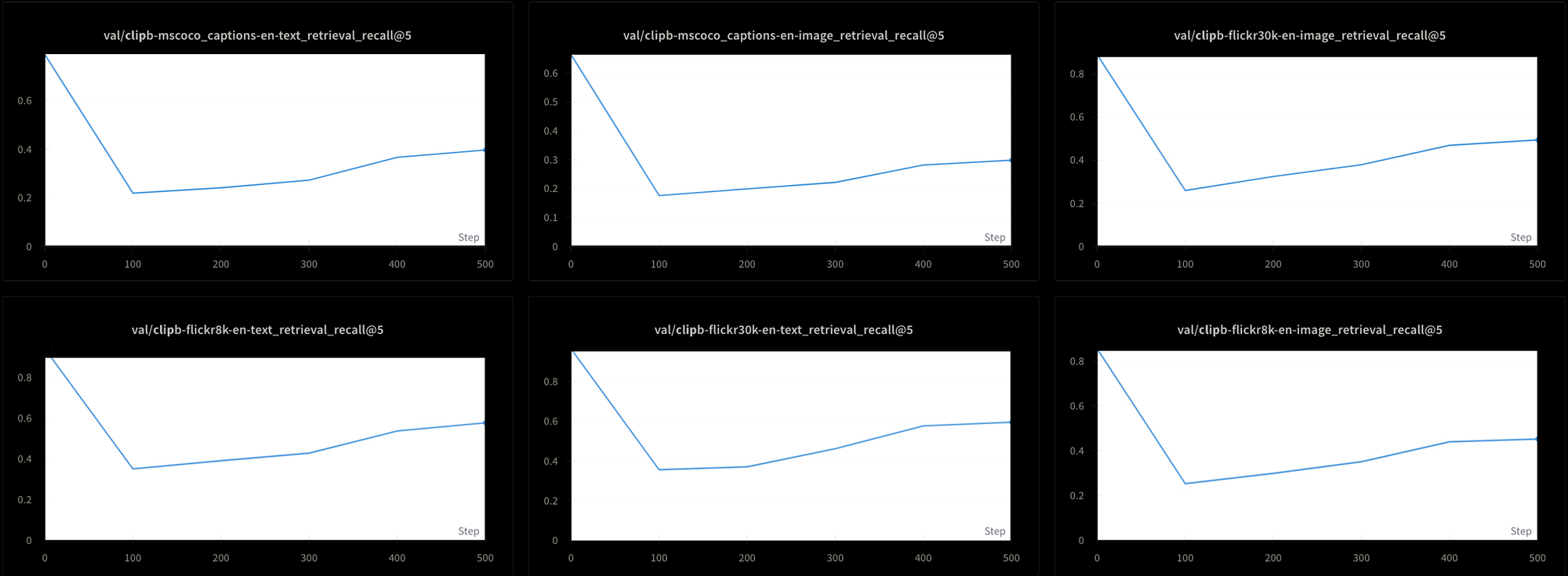
Обучение модели типа Jina CLIP с использованием такой постоянной высокой температуры, вероятно, было бы крайне затратным по времени и ресурсам. Хотя теоретически это возможно, это не является практичным решением.
tagКонтрастивное обучение и проблема ложных отрицательных примеров
Liang и др. [2022] также обнаружили, что стандартные практики контрастивного обучения — механизм, который мы используем для обучения мультимодальных моделей в стиле CLIP — имеют тенденцию усиливать мультимодальный разрыв.
Контрастивное обучение — это по сути простая концепция. У нас есть эмбеддинг изображения и эмбеддинг текста, и мы знаем, что они должны быть ближе друг к другу, поэтому во время обучения мы корректируем веса в модели для достижения этого. Мы двигаемся медленно, изменяя веса на небольшую величину, и корректируем их пропорционально тому, насколько далеко друг от друга находятся два эмбеддинга: чем ближе они друг к другу, тем меньше изменение.
Эта техника работает гораздо лучше, если мы не только сближаем эмбеддинги, когда они соответствуют друг другу, но также отдаляем их, когда они не соответствуют. Нам нужны не только пары изображение-текст, которые должны быть вместе, но и пары, которые мы знаем, должны быть раздельно.
Это создает несколько проблем:
- Наши источники данных состоят исключительно из соответствующих пар. Никто не будет создавать базу данных текстов и изображений, которые человек проверил как несвязанные, и их нельзя легко создать путем скрапинга веб-страниц или другими методами без присмотра или с частичным присмотром.
- Даже пары изображение-текст, которые поверхностно кажутся совершенно несвязанными, не обязательно таковыми являются. У нас нет теории семантики, которая позволила бы нам объективно делать такие отрицательные суждения. Например, изображение кошки, лежащей на крыльце, не является полностью отрицательным соответствием для текста "мужчина спит на диване". Оба включают лежание на чем-то.
В идеале мы хотели бы обучать на парах изображение-текст, о которых мы точно знаем, что они связаны и не связаны, но нет очевидного способа получить заведомо несвязанные пары. Можно спросить людей "Описывает ли это предложение эту картинку?" и ожидать согласованных ответов. Гораздо сложнее получить согласованные ответы, спрашивая "Не имеет ли это предложение ничего общего с этой картинкой?"
Вместо этого мы получаем несвязанные пары изображение-текст путем случайного выбора картинок и текстов из наших обучающих данных, ожидая, что они практически всегда будут плохими совпадениями. На практике это работает так, что мы разделяем наши обучающие данные на батчи. Для обучения Jina CLIP мы использовали батчи, содержащие 32 000 соответствующих пар изображение-текст, но для этого эксперимента размеры батчей были только 16.
В таблице ниже представлены 16 случайно выбранных пар изображение-текст из Flickr8k:
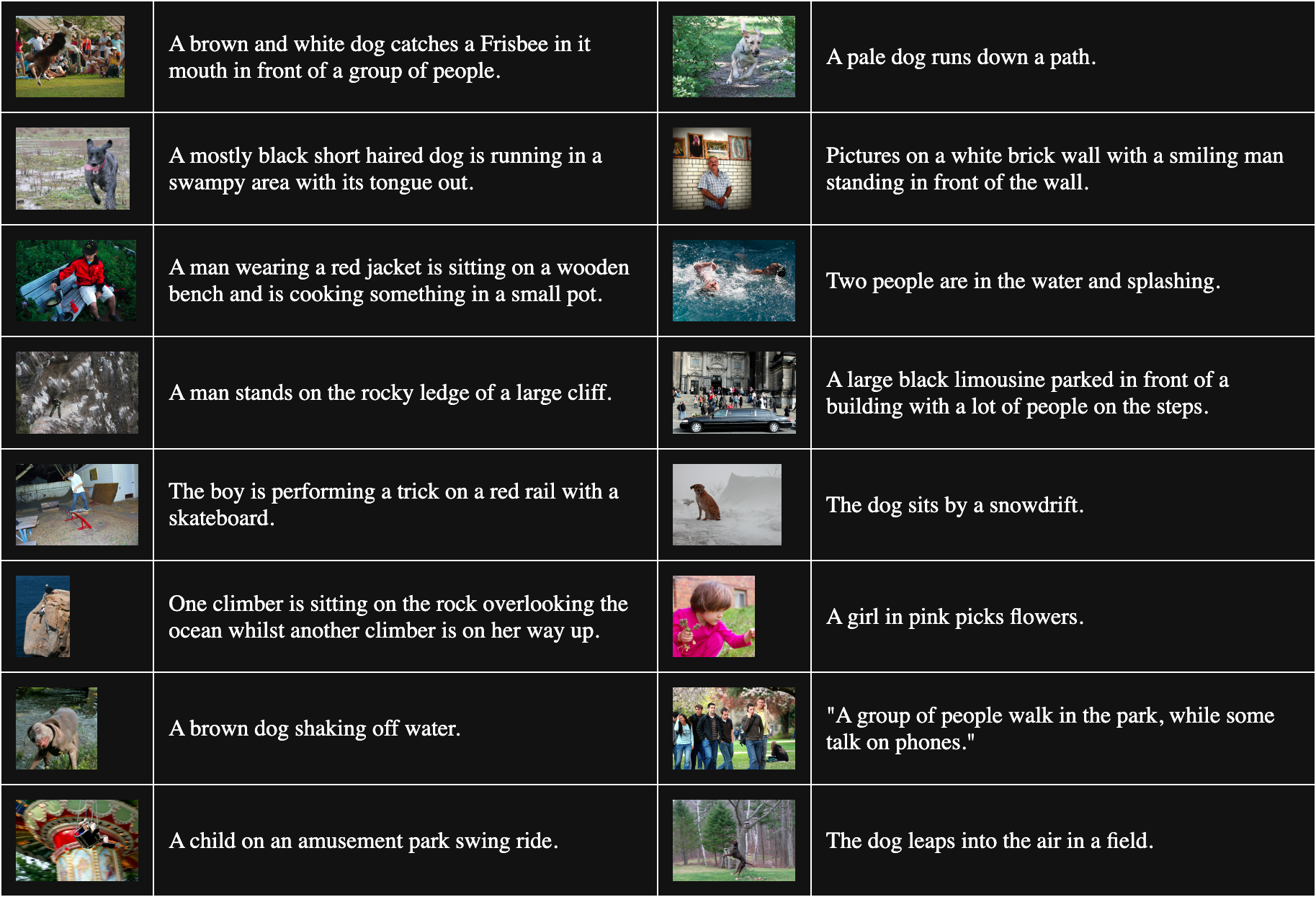
Чтобы получить несоответствующие пары, мы комбинируем каждое изображение в батче с каждым текстом, кроме того, с которым оно совпадает. Например, следующая пара является несоответствующим изображением и текстом:

Подпись: Девочка в розовом собирает цветы.
Но эта процедура предполагает, что все тексты, соответствующие другим изображениям, одинаково плохо подходят. Это не всегда верно. Например:

Подпись: Собака сидит у сугроба.
Хотя текст не описывает это изображение, у них есть общее — собака. Обработка этой пары как несоответствующей будет стремиться оттолкнуть слово "собака" от любого изображения собаки.
Liang и др. [2022] показывают, что эти несовершенные несоответствующие пары отталкивают все изображения и тексты друг от друга.
Мы решили проверить их утверждение с полностью случайно инициализированной моделью изображений vit-b-32 и аналогично случайно инициализированной текстовой моделью JinaBERT v2, с температурой обучения, установленной на постоянное значение 0.02 (умеренно низкая температура). Мы создали два набора обучающих данных:
- Один со случайными батчами из Flickr8k, с несоответствующими парами, созданными как описано выше.
- Другой, где батчи намеренно составлены с несколькими копиями одного и того же изображения с разными текстами в каждом батче. Это гарантирует, что значительное число "несоответствующих" пар на самом деле являются правильными совпадениями друг для друга.
Затем мы обучили две модели в течение одной эпохи, каждую на своем наборе данных, и измерили среднее косинусное расстояние между 1 000 парами текст-изображение из набора данных Flickr8k для каждой модели. Модель, обученная на случайных батчах, имела среднее косинусное расстояние 0.7521, в то время как модель, обученная с большим количеством намеренно совпадающих "несоответствующих" пар, имела среднее косинусное расстояние 0.7840. Эффект от неправильных "несоответствующих" пар весьма значителен. Учитывая, что реальное обучение модели длится гораздо дольше и использует гораздо больше данных, мы можем видеть, как этот эффект может расти и увеличивать разрыв между изображениями и текстами в целом.
tagСредство передачи является сообщением
Канадский теоретик коммуникации Маршалл Маклюэн ввел фразу "Средство передачи является сообщением" в своей книге 1964 года Понимание медиа: Внешние расширения человека, чтобы подчеркнуть, что сообщения не являются автономными. Они приходят к нам в контексте, который сильно влияет на их значение, и он знаменито утверждал, что одной из важнейших частей этого контекста является природа средства коммуникации.
Мультимодальный разрыв дает нам уникальную возможность изучить класс возникающих семантических явлений в AI-моделях. Никто не учил Jina CLIP кодировать тип данных, на которых она обучалась — она просто сделала это сама. Даже если мы еще не решили эту проблему для мультимодальных моделей, у нас по крайней мере есть хорошее теоретическое понимание того, откуда она возникает.
Мы должны предположить, что наши модели кодируют и другие вещи, которые мы еще не искали, из-за того же типа смещения. Например, вероятно, у нас та же проблема в мультиязычных моделях встраивания. Совместное обучение на двух или более языках, вероятно, приводит к такому же разрыву между языками, особенно учитывая, что широко используются похожие методы обучения. Решения проблемы разрыва могут иметь очень широкие последствия.
Исследование смещения при инициализации в более широком спектре моделей, вероятно, также приведет к новым открытиям. Если среда является сообщением для модели встраивания, кто знает, что еще кодируется в наших моделях без нашего ведома?
