

Разбиение длинного документа имеет две проблемы: первая — определение точек разбиения, то есть как сегментировать документ. Можно рассмотреть фиксированную длину токенов, фиксированное количество предложений или более продвинутые техники, такие как регулярные выражения или модели семантической сегментации. Точные границы чанков не только улучшают читаемость результатов поиска, но и гарантируют, что чанки, подаваемые в LLM в системе RAG, являются точными и достаточными — не больше и не меньше.
Вторая проблема — это потеря контекста внутри каждого чанка. После сегментации документа следующим логичным шагом для большинства людей является встраивание каждого чанка отдельно в пакетном процессе. Однако это приводит к потере глобального контекста из исходного документа. Многие предыдущие работы сначала решали первую проблему, утверждая, что лучшее обнаружение границ улучшает семантическое представление. Например, "семантическая разбивка" группирует предложения с высокой косинусной схожестью в пространстве эмбеддингов, чтобы минимизировать нарушение семантических единиц.
С нашей точки зрения, эти две проблемы почти ортогональны и могут решаться отдельно. Если бы нам пришлось расставить приоритеты, мы бы сказали, что 2-я проблема более критична.
| Проблема 2: Контекстная информация | |||
|---|---|---|---|
| Сохранена | Потеряна | ||
| Проблема 1: Точки разбиения | Хорошие | Идеальный сценарий | Плохие результаты поиска |
| Плохие | Хорошие результаты поиска, но результаты могут быть нечитаемыми или неподходящими для рассуждений LLM | Наихудший сценарий |
tagПоздняя разбивка для решения проблемы потери контекста
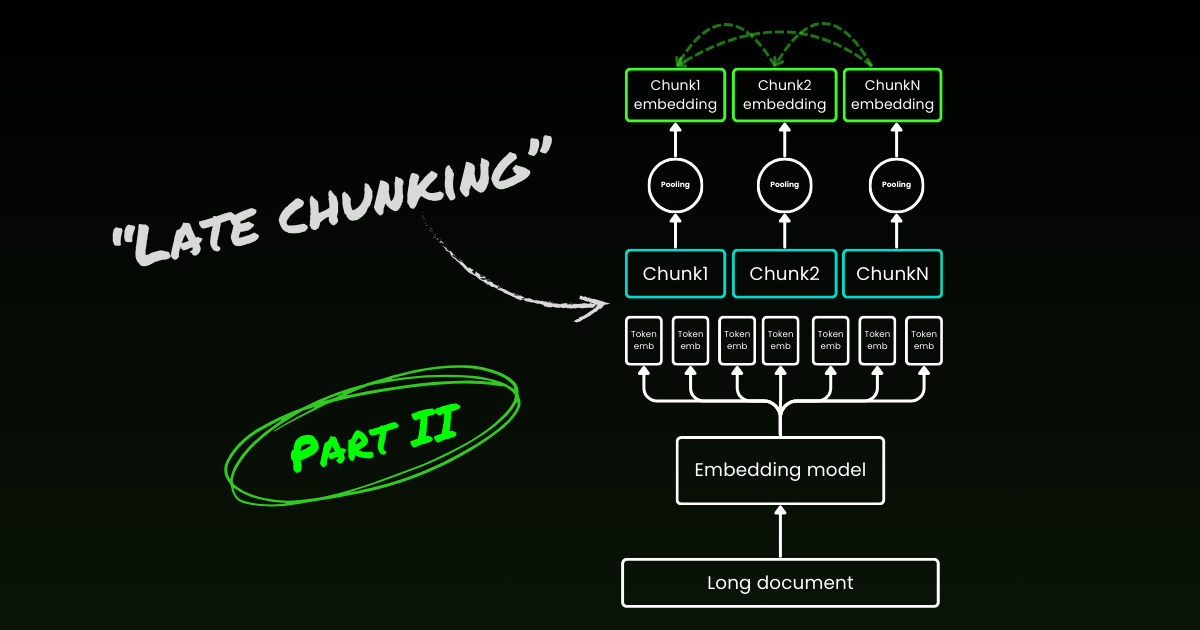
Поздняя разбивка начинается с решения второй проблемы: потери контекста. Речь идет не о поиске идеальных точек разбиения или семантических границ. Вам по-прежнему нужно использовать регулярные выражения, эвристики или другие техники для разделения длинного документа на маленькие чанки. Но вместо того, чтобы встраивать каждый чанк сразу после сегментации, поздняя разбивка сначала кодирует весь документ в одном контекстном окне (для jina-embeddings-v3 это 8192 токена). Затем она следует указаниям о границах для применения усреднения для каждого чанка — отсюда термин "поздняя" в поздней разбивке.

tagПоздняя разбивка устойчива к плохим указаниям о границах
Что действительно интересно, эксперименты показывают, что поздняя разбивка устраняет необходимость в идеальных семантических границах, что частично решает первую упомянутую выше проблему. Фактически, поздняя разбивка, применённая к границам фиксированных токенов, превосходит наивную разбивку с семантическими указаниями о границах. Простые модели сегментации, такие как использующие границы фиксированной длины, работают наравне с продвинутыми алгоритмами обнаружения границ при использовании с поздней разбивкой. Мы протестировали три разных размера моделей эмбеддинга, и результаты показывают, что все они последовательно получают преимущества от поздней разбивки на всех тестовых наборах данных. При этом сама модель эмбеддинга остается наиболее значимым фактором производительности — нет ни одного случая, когда более слабая модель с поздней разбивкой превосходила бы более сильную модель без нее.

jina-embeddings-v2-small с указаниями о границах фиксированной длины токенов и наивной разбивкой). В рамках аблационного исследования мы протестировали позднюю разбивку с различными указаниями о границах (фиксированная длина токенов, границы предложений и семантические границы) и разными моделями (jina-embeddings-v2-small, nomic-v1 и jina-embeddings-v3). На основе их производительности на MTEB, рейтинг этих трех моделей эмбеддинга: jina-embeddings-v2-small < nomic-v1 < jina-embeddings-v3. Однако, основное внимание в этом эксперименте уделяется не оценке производительности самих моделей эмбеддингов, а пониманию того, как более качественная модель эмбеддингов взаимодействует с поздним чанкингом и граничными маркерами. Подробности эксперимента можно найти в нашей исследовательской работе.| Combo | SciFact | NFCorpus | FiQA | TRECCOVID |
|---|---|---|---|---|
| Baseline | 64.2 | 23.5 | 33.3 | 63.4 |
| Late | 66.1 | 30.0 | 33.8 | 64.7 |
| Nomic | 70.7 | 35.3 | 37.0 | 72.9 |
| Jv3 | 71.8 | 35.6 | 46.3 | 73.0 |
| Late + Nomic | 70.6 | 35.3 | 38.3 | 75.0 |
| Late + Jv3 | 73.2 | 36.7 | 47.6 | 77.2 |
| SentBound | 64.7 | 28.3 | 30.4 | 66.5 |
| Late + SentBound | 65.2 | 30.0 | 33.9 | 66.6 |
| Nomic + SentBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SentBound | 71.4 | 35.8 | 43.7 | 72.4 |
| Late + Nomic + SentBound | 70.5 | 35.3 | 36.9 | 76.1 |
| Late + Jv3 + SentBound | 72.4 | 36.6 | 47.6 | 76.2 |
| SemanticBound | 64.3 | 27.4 | 30.3 | 66.2 |
| Late + SemanticBound | 65.0 | 29.3 | 33.7 | 66.3 |
| Nomic + SemanticBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SemanticBound | 71.2 | 36.1 | 44.0 | 74.7 |
| Late + Nomic + SemanticBound | 70.5 | 36.9 | 36.9 | 76.1 |
| Late + Jv3 + SemanticBound | 72.4 | 36.6 | 47.6 | 76.2 |
Обратите внимание, что устойчивость к плохим границам не означает, что мы можем игнорировать их — они по-прежнему важны как для человеческой читабельности, так и для LLM. Вот как мы это видим: при оптимизации сегментации, то есть упомянутой выше первой проблемы, мы можем полностью сосредоточиться на читабельности, не беспокоясь о потере семантики/контекста. Поздний чанкинг справляется как с хорошими, так и с плохими точками разрыва, поэтому вам нужно заботиться только о читабельности.
tagПоздний чанкинг является двунаправленным
Другое распространенное заблуждение о позднем чанкинге заключается в том, что его условные эмбеддинги чанков опираются только на предыдущие чанки, не "заглядывая вперед". Это неверно. На самом деле условная зависимость в позднем чанкинге является двунаправленной, а не однонаправленной. Это происходит потому, что матрица внимания в модели эмбеддингов — энкодере-трансформере — полностью связана, в отличие от маскированной треугольной матрицы, используемой в авторегрессивных моделях. Формально, эмбеддинг чанка , , а не , где обозначает факторизацию языковой модели. Это также объясняет, почему поздний чанкинг не зависит от точного расположения границ.

tagПоздний чанкинг можно обучать
Поздний чанкинг не требует дополнительного обучения для моделей эмбеддингов. Его можно применять к любым моделям эмбеддингов с длинным контекстом, использующим усреднение (mean pooling), что делает его очень привлекательным для практиков. Тем не менее, если вы работаете над такими задачами, как вопросно-ответные системы или поиск документов по запросу, производительность можно дополнительно улучшить с помощью тонкой настройки. В частности, обучающие данные состоят из кортежей, содержащих:
- Запрос (например, вопрос или поисковый термин)
- Документ, содержащий релевантную информацию для ответа на запрос
- Релевантный фрагмент внутри документа, который является конкретным куском текста, напрямую отвечающим на запрос
Модель обучается путем сопоставления запросов с их релевантными фрагментами, используя контрастивную функцию потерь, такую как InfoNCE. Это обеспечивает тесное выравнивание релевантных фрагментов с запросом в пространстве эмбеддингов, в то время как несвязанные фрагменты отодвигаются дальше. В результате модель учится фокусироваться на наиболее релевантных частях документа при генерации эмбеддингов чанков. Более подробную информацию можно найти в нашей исследовательской работе.
tagПоздний чанкинг vs. Контекстуальный поиск
Вскоре после появления позднего чанкинга Anthropic представила отдельную стратегию под названием Contextual Retrieval. Метод Anthropic — это подход "в лоб" для решения проблемы потери контекста, который работает следующим образом:
- Каждый чанк отправляется в LLM вместе с полным документом
- LLM добавляет релевантный контекст к каждому чанку
- Это приводит к более богатым и информативным эмбеддингам
На наш взгляд, это по сути обогащение контекста, где глобальный контекст явно жестко закодирован в каждый чанк с помощью LLM, что дорого с точки зрения стоимости, времени и хранения. Кроме того, неясно, устойчив ли этот подход к границам чанков, так как LLM полагается на точные и читабельные чанки для эффективного обогащения контекста. В противоположность этому, поздний чанкинг очень устойчив к граничным маркерам, как показано выше. Он не требует дополнительного хранения, так как размер эмбеддинга остается прежним. Несмотря на использование полной длины контекста модели эмбеддингов, он все еще значительно быстрее, чем использование LLM для генерации обогащения. В качественном исследовании нашей научной работы мы показываем, что контекстуальный поиск Anthropic работает аналогично позднему чанкингу. Однако поздний чанкинг предоставляет более низкоуровневое, универсальное и естественное решение, используя внутренние механизмы энкодера-трансформера.
tagКакие модели эмбеддингов поддерживают поздний чанкинг?
Поздний чанкинг не является эксклюзивным для jina-embeddings-v3 или v2. Это довольно универсальный подход, который можно применять к любой модели эмбеддингов с длинным контекстом, использующей усреднение (mean pooling). Например, в этом посте мы показываем, что nomic-v1 тоже его поддерживает. Мы тепло приветствуем всех провайдеров эмбеддингов в реализации поддержки позднего чанкинга в их решениях.
Как пользователь модели, при оценке новой модели эмбеддингов или API вы можете следовать этим шагам, чтобы проверить, может ли она поддерживать поздний чанкинг:
- Единственный выход: Выдает ли модель/API только одно финальное эмбеддинг на предложение вместо эмбеддингов на уровне токенов? Если да, то она, вероятно, не может поддерживать позднюю фрагментацию (особенно для веб-API).
- Поддержка длинного контекста: Обрабатывает ли модель/API контексты не менее 8192 токенов? Если нет, то поздняя фрагментация будет неприменима — точнее говоря, нет смысла адаптировать позднюю фрагментацию для модели с коротким контекстом. Если да, убедитесь, что она действительно хорошо работает с длинными контекстами, а не просто заявляет об их поддержке. Обычно эту информацию можно найти в техническом отчете модели, например, в оценках на LongMTEB или других бенчмарках для длинного контекста.
- Mean Pooling: Для самостоятельно размещаемых моделей или API, которые предоставляют эмбеддинги на уровне токенов до пулинга, проверьте, является ли mean pooling методом пулинга по умолчанию. Модели, использующие CLS или max pooling, несовместимы с поздней фрагментацией.
Подводя итог, если модель эмбеддингов поддерживает длинный контекст и использует mean pooling по умолчанию, она может легко поддерживать позднюю фрагментацию. Ознакомьтесь с нашим репозиторием GitHub для деталей реализации и дальнейшего обсуждения.
tagЗаключение
Итак, что такое поздняя фрагментация? Поздняя фрагментация — это простой метод генерации эмбеддингов фрагментов с использованием моделей эмбеддингов для длинного контекста. Он быстрый, устойчивый к граничным сигналам и высокоэффективный. Это не эвристика или переусложнение — это продуманный дизайн, основанный на глубоком понимании механизма трансформера.
Сегодня ажиотаж вокруг LLM неоспорим. Во многих случаях проблемы, которые могли бы эффективно решаться меньшими моделями вроде BERT, вместо этого передаются LLM, движимые привлекательностью более крупных и сложных решений. Неудивительно, что крупные провайдеры LLM продвигают более широкое использование своих моделей, а провайдеры эмбеддингов выступают за эмбеддинги — оба играют на своих коммерческих преимуществах. Но в конечном счете дело не в шумихе, а в действии, в том, что действительно работает. Пусть сообщество, индустрия и, что наиболее важно, время покажут, какой подход действительно является более экономичным, эффективным и долговечным.
Обязательно прочитайте нашу исследовательскую статью, и мы призываем вас протестировать позднюю фрагментацию в различных сценариях и поделиться с нами своими отзывами.
