Читатель
Преобразуйте URL-адрес в формат ввода, удобный для LLM, просто добавив
r.jina.ai в начало.API-интерфейс читателя
Преобразуйте URL-адрес в формат ввода, удобный для LLM, просто добавив
r.jina.ai в начало.chevron_leftchevron_right
globe_book
Используйте
r.jina.ai для чтения URL-адреса и извлечения его содержимого.travel_explore
Используйте
s.jina.ai для поиска в Интернете и получения результатов поиска
Добавьте
mcp.jina.ai в качестве сервера MCP для доступа к нашему API в LLM.upload
Запрос
GET
curl "https://r.jina.ai/https://www.example.com"
Jina VLM: Малая многоязычная модель визуального восприятия и языка
Модель визуально-языкового взаимодействия с 2,4 миллиардами параметров, обеспечивающая передовые возможности многоязычного визуального ответа на вопросы в открытых моделях визуально-языкового взаимодействия масштаба 2 миллиарда.

ReaderLM v2: небольшая языковая модель для преобразования HTML в Markdown и JSON
ReaderLM-v2 — это языковая модель с 1,5 млрд параметров, специализирующаяся на преобразовании HTML в Markdown и извлечении HTML в JSON. Она поддерживает документы размером до 512 тыс. токенов на 29 языках и обеспечивает точность на 20 % выше по сравнению с предыдущей моделью.


Предоставление веб-информации в программы LLM является важным шагом в обучении, однако это может быть непросто. Самый простой метод — очистить веб-страницу и передать ей необработанный HTML-код. Однако парсинг может быть сложным и часто блокируется, а необработанный HTML загроможден посторонними элементами, такими как разметка и скрипты. Reader API решает эти проблемы, извлекая основной контент из URL-адреса и преобразуя его в чистый, удобный для LLM текст, обеспечивая высококачественный ввод для вашего агента и систем RAG.
Необработанный HTML
Вывод считывателя

Reader можно использовать как SERP API. Он позволяет вам снабжать ваш LLM контентом, находящимся за страницей результатов поиска. Просто добавьте
https://s.jina.ai/?q= к вашему запросу, и Reader выполнит поиск в Интернете и вернет пять лучших результатов с их URL-адресами и контентом, каждый в виде чистого, понятного LLM текста. Таким образом, вы всегда сможете поддерживать свой LLM в актуальном состоянии, улучшать его фактологичность и уменьшать галлюцинации.info Обратите внимание: в отличие от демонстрации, показанной выше, на практике вам не нужно искать в Интернете исходный вопрос для обоснования. Люди часто переписывают исходный вопрос или используют вопросы с несколькими переходами. Они считывают полученные результаты, а затем генерируют дополнительные запросы для сбора дополнительной информации по мере необходимости, прежде чем прийти к окончательному ответу.

Изображения на веб-странице автоматически снабжаются подписями с использованием языковой модели видения в программе чтения и форматируются в виде тегов alt изображения на выходе. Это дает вашему последующему LLM достаточно подсказок, чтобы включить эти изображения в процессы рассуждения и обобщения. Это означает, что вы можете задавать вопросы об изображениях, выбирать конкретные изображения или даже пересылать их URL-адреса более мощному VLM для более глубокого анализа!
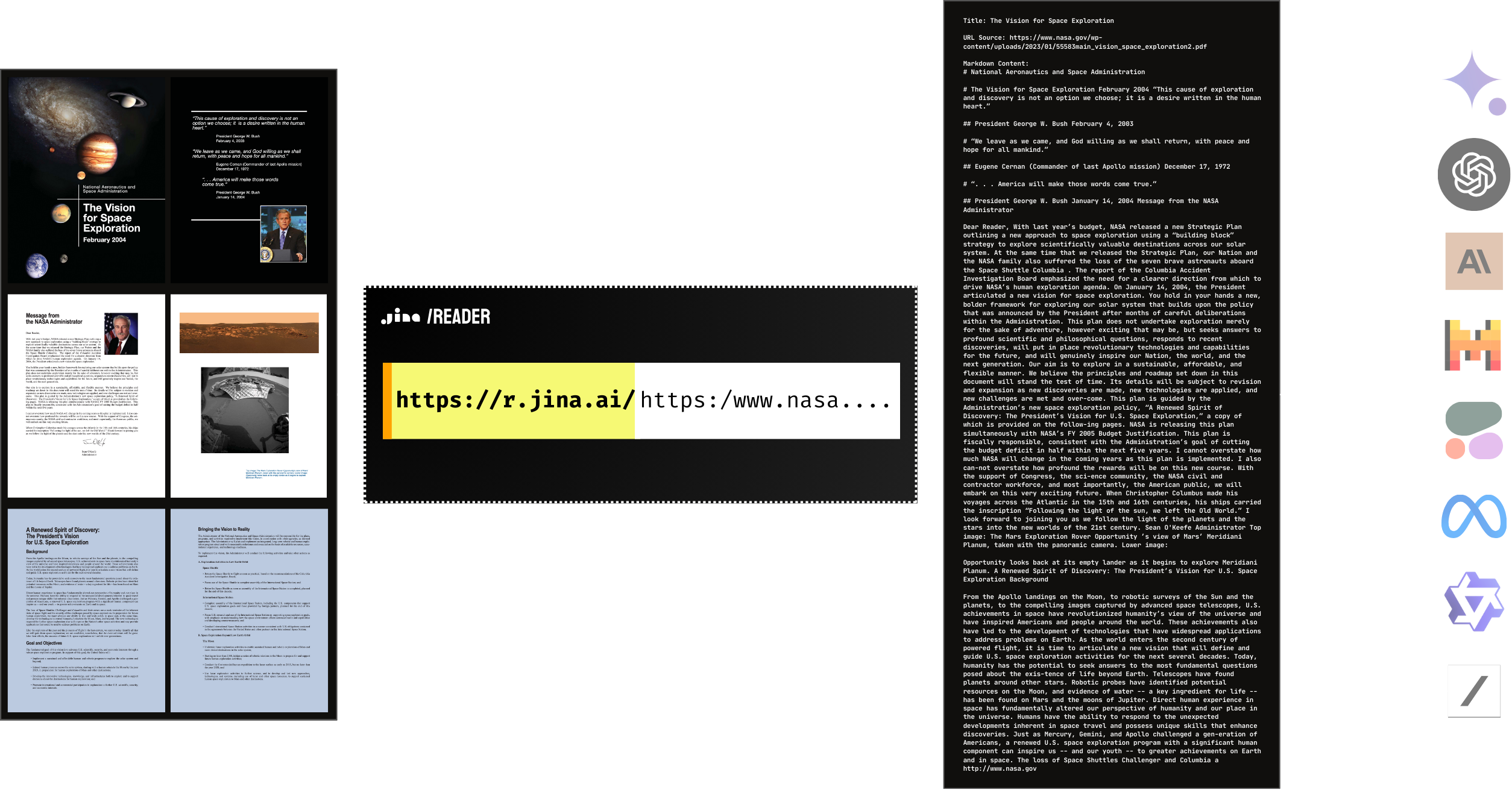
Да, Reader изначально поддерживает чтение PDF-файлов. Он совместим с большинством PDF-файлов, в том числе с большим количеством изображений, и работает молниеносно! В сочетании с LLM вы можете легко создать ChatPDF или ИИ для анализа документов в кратчайшие сроки.
Лучшая часть? Это бесплатно!
Reader API доступен бесплатно и предлагает гибкие ограничения по скорости и ценам. Построенный на основе масштабируемой инфраструктуры, он обеспечивает высокую доступность, параллелизм и надежность. Мы стремимся быть вашим предпочтительным решением по заземлению для ваших студентов LLM.
Ограничение скорости
Ограничения скорости отслеживаются тремя способами: RPM (запросы в минуту) и TPM (токены в минуту). Ограничения применяются для каждого IP/API-ключа и срабатывают при достижении порогового значения RPM или TPM. Когда вы указываете ключ API в заголовке запроса, мы отслеживаем ограничения скорости по ключу, а не по IP-адресу.
| Продукт | Конечная точка API | Описаниеarrow_upward | без API-ключаkey_off | с бесплатным API-ключомkey | с платным API-ключомkey | с премиум-ключом APIkey | Средняя задержка | Подсчет использования токенов | Разрешенный запрос | |
|---|---|---|---|---|---|---|---|---|---|---|
| API-интерфейс читателя | https://r.jina.ai | Преобразовать URL в текст, понятный LLM | 20 RPM | 500 RPM | 500 RPM | trending_up5000 RPM | 7.9s | Подсчитайте количество токенов в выходном ответе. | GET/POST | |
| API-интерфейс читателя | https://s.jina.ai | Поиск в Интернете и преобразование результатов в текст, понятный LLM | block | 100 RPM | 100 RPM | trending_up1000 RPM | 2.5s | Каждый запрос стоит фиксированное количество токенов, начиная с 10000 токенов. | GET/POST | |
| API реранкера | https://api.jina.ai/v1/rerank | Ранжировать документы по запросу | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart зависит от размера входных данных help | Подсчитайте количество токенов во входном запросе. | POST | |
| Встраивание API | https://api.jina.ai/v1/embeddings | Преобразование текста/изображений в векторы фиксированной длины | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart зависит от размера входных данных help | Подсчитайте количество токенов во входном запросе. | POST | |
| API классификатора | https://api.jina.ai/v1/train | Обучить классификатор с использованием маркированных примеров | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart зависит от размера входных данных | Токены подсчитываются как: input_tokens × num_iters | POST | |
| API классификатора (Несколько выстрелов) | https://api.jina.ai/v1/classify | Классифицируйте входные данные с помощью обученного классификатора с несколькими попытками | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart зависит от размера входных данных | Токены учитываются как: input_tokens | POST | |
| API классификатора (Нулевой выстрел) | https://api.jina.ai/v1/classify | Классифицируйте входные данные, используя классификацию с нулевым результатом | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart зависит от размера входных данных | Токены считаются как: input_tokens + label_tokens | POST | |
| API сегментатора | https://api.jina.ai/v1/segment | Токенизация и сегментация длинного текста | 20 RPM | 200 RPM | 200 RPM | 1,000 RPM | 0.3s | Токен не считается использованием. | GET/POST | |
| Глубокий поиск | https://deepsearch.jina.ai/v1/chat/completions | Рассуждайте, ищите и повторяйте, чтобы найти лучший ответ. | block | 50 RPM | 50 RPM | 500 RPM | 56.7s | Подсчитайте общее количество токенов за весь процесс. | POST |





Не паникуйте! Каждый новый ключ API содержит десять миллионов бесплатных токенов!
Цены на API
Цены на API основаны на использовании токена. Один ключ API дает вам доступ ко всем продуктам Search Foundation.

С API Jina Search Foundation
Самый простой способ получить доступ ко всем нашим продуктам. Пополняйте токены по мере использования.
Пополните этот ключ API дополнительными токенами
Пожалуйста, введите правильный ключ API для пополнения счета.
Понять ограничение скорости
Ограничения скорости — это максимальное количество запросов, которые можно сделать к API в течение минуты на IP-адрес/ключ API (RPM). Узнайте больше об ограничениях скорости для каждого продукта и уровня ниже.
keyboard_arrow_down

Каковы затраты, связанные с использованием Reader API?
keyboard_arrow_down
Как работает API Reader?
keyboard_arrow_down
Является ли Reader API открытым исходным кодом?
keyboard_arrow_down
Какова типичная задержка для Reader API?
keyboard_arrow_down
Почему мне следует использовать Reader API вместо того, чтобы самостоятельно очищать страницу?
keyboard_arrow_down
Поддерживает ли Reader API несколько языков?
keyboard_arrow_down
Что делать, если веб-сайт блокирует Reader API?
keyboard_arrow_down
Может ли Reader API извлекать контент из PDF-файлов?
keyboard_arrow_down
Может ли Reader API обрабатывать медиаконтент с веб-страниц?
keyboard_arrow_down
Можно ли использовать Reader API для локальных файлов HTML?
keyboard_arrow_down
Кэширует ли Reader API контент?
keyboard_arrow_down
Могу ли я использовать API Reader для доступа к контенту после входа в систему?
keyboard_arrow_down
Могу ли я использовать Reader API для доступа к PDF-файлам на arXiv?
keyboard_arrow_down
Как работает подпись к изображению в Reader?
keyboard_arrow_down
Какова масштабируемость Reader? Могу ли я использовать его в производстве?
keyboard_arrow_down
Каков предел скорости API Reader?
keyboard_arrow_down
Что такое Reader-LM? Как им пользоваться?
keyboard_arrow_down
Как извлечь структурированные данные с веб-страниц?
keyboard_arrow_down
Действительно ли Reader активно обходит защиту веб-сайтов от ботов?
keyboard_arrow_down
Позволит ли переход с бесплатного на платный API-ключ получить доступ к большему количеству веб-сайтов?
keyboard_arrow_down
Ограничение скорости
Ограничения скорости отслеживаются тремя способами: RPM (запросы в минуту) и TPM (токены в минуту). Ограничения применяются для каждого IP/API-ключа и срабатывают при достижении порогового значения RPM или TPM. Когда вы указываете ключ API в заголовке запроса, мы отслеживаем ограничения скорости по ключу, а не по IP-адресу.
| Продукт | Конечная точка API | Описаниеarrow_upward | без API-ключаkey_off | с бесплатным API-ключомkey | с платным API-ключомkey | с премиум-ключом APIkey | Средняя задержка | Подсчет использования токенов | Разрешенный запрос | |
|---|---|---|---|---|---|---|---|---|---|---|
| API-интерфейс читателя | https://r.jina.ai | Преобразовать URL в текст, понятный LLM | 20 RPM | 500 RPM | 500 RPM | trending_up5000 RPM | 7.9s | Подсчитайте количество токенов в выходном ответе. | GET/POST | |
| API-интерфейс читателя | https://s.jina.ai | Поиск в Интернете и преобразование результатов в текст, понятный LLM | block | 100 RPM | 100 RPM | trending_up1000 RPM | 2.5s | Каждый запрос стоит фиксированное количество токенов, начиная с 10000 токенов. | GET/POST | |
| API реранкера | https://api.jina.ai/v1/rerank | Ранжировать документы по запросу | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart зависит от размера входных данных help | Подсчитайте количество токенов во входном запросе. | POST | |
| Встраивание API | https://api.jina.ai/v1/embeddings | Преобразование текста/изображений в векторы фиксированной длины | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart зависит от размера входных данных help | Подсчитайте количество токенов во входном запросе. | POST | |
| API классификатора | https://api.jina.ai/v1/train | Обучить классификатор с использованием маркированных примеров | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart зависит от размера входных данных | Токены подсчитываются как: input_tokens × num_iters | POST | |
| API классификатора (Несколько выстрелов) | https://api.jina.ai/v1/classify | Классифицируйте входные данные с помощью обученного классификатора с несколькими попытками | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart зависит от размера входных данных | Токены учитываются как: input_tokens | POST | |
| API классификатора (Нулевой выстрел) | https://api.jina.ai/v1/classify | Классифицируйте входные данные, используя классификацию с нулевым результатом | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart зависит от размера входных данных | Токены считаются как: input_tokens + label_tokens | POST | |
| API сегментатора | https://api.jina.ai/v1/segment | Токенизация и сегментация длинного текста | 20 RPM | 200 RPM | 200 RPM | 1,000 RPM | 0.3s | Токен не считается использованием. | GET/POST | |
| Глубокий поиск | https://deepsearch.jina.ai/v1/chat/completions | Рассуждайте, ищите и повторяйте, чтобы найти лучший ответ. | block | 50 RPM | 50 RPM | 500 RPM | 56.7s | Подсчитайте общее количество токенов за весь процесс. | POST |
Общие вопросы, связанные с API
code
Могу ли я использовать один и тот же ключ API для чтения, встраивания, переранжирования, классификации и тонкой настройки API?
keyboard_arrow_down
code
Могу ли я отслеживать использование токена моего ключа API?
keyboard_arrow_down
code
Что мне делать, если я забуду свой ключ API?
keyboard_arrow_down
code
Срок действия ключей API истекает?
keyboard_arrow_down
code
Могу ли я передавать токены между ключами API?
keyboard_arrow_down
code
Могу ли я отозвать свой ключ API?
keyboard_arrow_down
code
Почему первый запрос для некоторых моделей выполняется медленно?
keyboard_arrow_down
code
Используются ли данные из моего API для обучения ваших моделей?
keyboard_arrow_down
code
Каковы ограничения скорости запросов к API Jina?
keyboard_arrow_down
code
Существуют ли ограничения на размер пакета для API?
keyboard_arrow_down
Общие вопросы, связанные с выставлением счетов
attach_money
Выставление счетов зависит от количества предложений или запросов?
keyboard_arrow_down
attach_money
Доступна ли бесплатная пробная версия для новых пользователей?
keyboard_arrow_down
attach_money
Взимаются ли токены за неудачные запросы?
keyboard_arrow_down
attach_money
Какие способы оплаты принимаются?
keyboard_arrow_down
attach_money
Доступно ли выставление счетов за покупку токенов?
keyboard_arrow_down