向量模型
适用于搜索、RAG、智能体应用程序的性能最佳的多模态多语言长上下文向量模型。
向量模型API
用我们世界一流的向量模型来改进您的搜索和 RAG 系统。从免费试用开始!
chevron_leftchevron_right
示例输入
试试改变它们看看响应如何变化!
Organic skincare for sensitive skin with aloe vera and chamomile: Imagine the soothing embrace of nature with our organic skincare range, crafted specifically for sensitive skin. Infused with the calming properties of aloe vera and chamomile, each product provides gentle nourishment and protection. Say goodbye to irritation and hello to a glowing, healthy complexion. |
Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung unserer Bio-Hautpflege, speziell für empfindliche Haut entwickelt. Mit den beruhigenden Eigenschaften von Aloe Vera und Kamille pflegen und schützen unsere Produkte Ihre Haut auf natürliche Weise. Verabschieden Sie sich von Hautirritationen und genießen Sie einen strahlenden Teint. |
Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder de la naturaleza con nuestra línea de cuidado de la piel orgánico, diseñada especialmente para pieles sensibles. Enriquecidos con aloe vera y manzanilla, estos productos ofrecen una hidratación y protección suave. Despídete de las irritaciones y saluda a una piel radiante y saludable. |
针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,温和滋润,保护您的肌肤不受刺激。让您的肌肤告别不适,迎来健康光彩。 |
新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。ネオンアイライナーからホログラフィックハイライターまで、クリエイティビティを解き放ち、毎回ユニークなルックを演出しましょう。 |
upload
请求
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer " \
-d @- <<EOFEOF
{
"normalized": true,
"embedding_type": "float",
"input": [
"Organic skincare for sensitive skin with aloe vera and chamomile: Imagine the soothing embrace of nature with our organic skincare range, crafted specifically for sensitive skin. Infused with the calming properties of aloe vera and chamomile, each product provides gentle nourishment and protection. Say goodbye to irritation and hello to a glowing, healthy complexion.",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung unserer Bio-Hautpflege, speziell für empfindliche Haut entwickelt. Mit den beruhigenden Eigenschaften von Aloe Vera und Kamille pflegen und schützen unsere Produkte Ihre Haut auf natürliche Weise. Verabschieden Sie sich von Hautirritationen und genießen Sie einen strahlenden Teint.",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder de la naturaleza con nuestra línea de cuidado de la piel orgánico, diseñada especialmente para pieles sensibles. Enriquecidos con aloe vera y manzanilla, estos productos ofrecen una hidratación y protección suave. Despídete de las irritaciones y saluda a una piel radiante y saludable.",
"针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,温和滋润,保护您的肌肤不受刺激。让您的肌肤告别不适,迎来健康光彩。",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。ネオンアイライナーからホログラフィックハイライターまで、クリエイティビティを解き放ち、毎回ユニークなルックを演出しましょう。"
]
}
EOFEOF
v5-omni:一个向量,涵盖所有模态
文本、图像、音频、视频——共享同一个向量空间,两种尺寸。v5-omni-small (16亿) 是参数量为 20 亿时性能最佳的开放权重全向模型。v5-omni-nano (9亿) 在 10 亿以下的参数量下也能提供极具竞争力的检索性能。两者都与 v5-text 完全兼容——无需重新索引。

v5-text:最新最先进的小型多语言向量模型
jina-embeddings-v5-text 以两种高效尺寸(677M 小型模型和 239M 纳米模型)提供第五代向量质量,并具有特定于任务的 LoRA 适配器、Matryoshka 维度、32K 上下文和用于边缘部署的 GGUF/MLX 量化,在 MMTEB、MTEB English 和检索任务中树立了新的基准。

两种购买方式
订阅我们的API或通过云服务提供商购买。
radio_button_unchecked
cloud
与 3 个云服务提供商合作
您的公司是否在使用 AWS 或 Azure?那么请直接在贵公司的这些平台上私有化部署我们的搜索底座模型,这样您的数据就能保持安全且合规。
radio_button_checked

使用Jina 搜索底座API
访问我们所有产品的最简单方法。随时充值词元。
为此 API 密钥充值
请输入正确的API密钥进行充值
了解速率限制
速率限制是指每个 IP 地址/API 密钥 (RPM) 在一分钟内可以向 API 发出的最大请求数。请在下面详细了解每个产品和层级的速率限制。
keyboard_arrow_down




私有化部署
在 AWS Sagemaker 和 Microsoft Azure 中部署 Jina Embeddings 模型,并很快在 Google Cloud Services 中部署,或者联系我们的销售团队,为您的虚拟私有云和本地服务器获取定制的 Kubernetes 部署。
 AWS SageMaker
AWS SageMaker 向量模型
向量模型 重排器
重排器'%3e%3cpath%20fill='%23ffffff'%20d='M%20198.351562%2044.007812%20L%20112.046875%20118.847656%20L%2038.398438%20251.039062%20L%20104.804688%20251.039062%20Z%20M%20209.832031%2061.519531%20L%20173%20165.332031%20L%20243.621094%20254.0625%20L%20106.613281%20277.605469%20L%20331.15625%20277.605469%20Z%20M%20209.832031%2061.519531%20'%20fill-opacity='1'%20fill-rule='nonzero'/%3e%3c/g%3e%3c/svg%3e) Microsoft Azure向量模型重排器
Microsoft Azure向量模型重排器'%3e%3cpath%20fill='%23ffffff'%20d='M%20246.492188%20109.988281%20L%20274.53125%2081.949219%20L%20276.394531%2070.148438%20C%20225.308594%2023.683594%20144.097656%2028.960938%2098.03125%2081.136719%20C%2085.234375%2095.625%2075.753906%20113.695312%2070.691406%20132.363281%20L%2080.726562%20130.941406%20L%20136.804688%20121.703125%20L%20141.125%20117.28125%20C%20166.0625%2089.882812%20208.246094%2086.199219%20237.039062%20109.503906%20Z%20M%20246.492188%20109.988281%20'%20fill-opacity='1'%20fill-rule='nonzero'/%3e%3c/g%3e%3cg%20clip-path='url(%235696d21d1c)'%3e%3cpath%20fill='%23ffffff'%20d='M%20314.480469%20131.527344%20C%20308.042969%20107.796875%20294.804688%2086.457031%20276.40625%2070.132812%20L%20237.050781%20109.488281%20C%20253.671875%20123.066406%20263.128906%20143.511719%20262.730469%20164.964844%20L%20262.730469%20171.949219%20C%20282.066406%20171.949219%20297.746094%20187.628906%20297.746094%20206.964844%20C%20297.746094%20226.300781%20282.066406%20241.601562%20262.730469%20241.601562%20L%20192.59375%20241.601562%20L%20185.710938%20249.078125%20L%20185.710938%20291.09375%20L%20192.59375%20297.6875%20L%20262.730469%20297.6875%20C%20313.03125%20298.085938%20354.136719%20258.007812%20354.535156%20207.703125%20C%20354.777344%20177.207031%20339.734375%20148.617188%20314.480469%20131.527344%20'%20fill-opacity='1'%20fill-rule='nonzero'/%3e%3c/g%3e%3cg%20clip-path='url(%233d43eedc5d)'%3e%3cpath%20fill='%23ffffff'%20d='M%20122.542969%20297.6875%20L%20192.59375%20297.6875%20L%20192.59375%20241.613281%20L%20122.542969%20241.613281%20C%20117.582031%20241.613281%20112.691406%20240.535156%20108.183594%20238.472656%20L%2098.246094%20241.515625%20L%2070.007812%20269.550781%20L%2067.546875%20279.09375%20C%2083.386719%20291.050781%20102.707031%20297.773438%20122.542969%20297.6875%20'%20fill-opacity='1'%20fill-rule='nonzero'/%3e%3c/g%3e%3cg%20clip-path='url(%237591c6ee7a)'%3e%3cpath%20fill='%23ffffff'%20d='M%20122.542969%20115.789062%20C%2072.226562%20116.085938%2031.691406%20157.117188%2031.988281%20207.433594%20C%2032.160156%20235.527344%2045.285156%20261.972656%2067.546875%20279.105469%20L%20108.183594%20238.472656%20C%2090.554688%20230.511719%2082.71875%20209.765625%2090.679688%20192.136719%20C%2098.644531%20174.507812%20119.386719%20166.671875%20137.015625%20174.632812%20C%20144.777344%20178.144531%20151.007812%20184.359375%20154.519531%20192.136719%20L%20195.152344%20151.503906%20C%20177.863281%20128.894531%20150.992188%20115.6875%20122.542969%20115.789062%20'%20fill-opacity='1'%20fill-rule='nonzero'/%3e%3c/g%3e%3c/svg%3e) Google Cloud向量模型
Google Cloud向量模型
API集成
在流行数据库、向量数据库、RAG 和 LLMOps 框架轻松使用我们的向量模型API。首先,只需将您的 API 密钥复制到以下任意集成中即可快速使用我们的模型。
向量数据库
LLM框架
RAG应用
可观察性

MongoDB

DataStax

Qdrant

Pinecone

Chroma
Weaviate
Milvus
Epsilla
'%3e%3cg%20clip-path='url(%23clip1_1855_4873)'%3e%3cpath%20d='M24%2048C37.2548%2048%2048%2037.2548%2048%2024C48%2010.7452%2037.2548%200%2024%200C10.7452%200%200%2010.7452%200%2024C0%2037.2548%2010.7452%2048%2024%2048Z'%20fill='%239995F7'/%3e%3cpath%20d='M34.7344%2013.2656V34.7364H30.1118V21.866L25.8771%2034.7364H22.1563L17.8863%2021.8434V34.7364H13.2637V13.2656H18.7126L24.0406%2028.1337L29.3107%2013.2656H34.7344Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1855_4873'%3e%3crect%20width='48'%20height='48'%20fill='white'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_1855_4873'%3e%3crect%20width='48'%20height='48'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
MyScale
LlamaIndex

Haystack
Langchain
Dify
'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M47.0411%2016.7178V0.0339975H19.9095C12.6477%200.0339975%206.69079%206.0208%206.54804%2013.3944H6.54423V20.9514H9.80254V13.3944H9.80629C9.9491%207.8547%2014.4463%203.35742%2019.9095%203.35742H43.7804V13.3944H23.6055C21.6685%2013.3944%2019.8837%2014.4534%2019.8837%2016.7178H47.0411ZM0%2031.2822V47.9666H27.1292C34.391%2047.9666%2040.3478%2041.9799%2040.4906%2034.6062H40.4944V27.0486H37.2361V34.6056H37.2304C37.0902%2040.1453%2032.5923%2044.6458%2027.1292%2044.6458H3.25829V34.6056H23.4332C25.3701%2034.6056%2027.155%2033.5466%2027.155%2031.2822H0ZM6.51656%2037.9297H26.76C29.6453%2037.9297%2030.6811%2036.1285%2030.6811%2033.3516V20.1285H47.0411V34.9045C47.0411%2041.0933%2042.9446%2046.3521%2037.3807%2048C41.0988%2044.9774%2043.7829%2040.3769%2043.7829%2034.9045V23.4519H33.9395V33.3516C33.9395%2037.8418%2031.4062%2041.3192%2026.76%2041.3192H6.51656V37.9297ZM40.5221%2010.071H20.2786C17.3933%2010.071%2016.3575%2011.8722%2016.3575%2014.6484V27.8722H0V13.0955C0%206.90725%204.09661%201.64856%209.6604%200C5.9424%203.02257%203.25829%207.62312%203.25829%2013.0955V24.5481H13.0992V14.6484C13.0992%2010.1582%2015.6324%206.68085%2020.2786%206.68085H40.5221V10.071Z'%20fill='%237628F8'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_1822_544'%3e%3crect%20width='48'%20height='48'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
SuperDuperDB
%20rotate(-89.93)'/%3e%3crect%20class='cls-1'%20x='30.52'%20y='10.19'%20width='3'%20height='47.42'%20transform='translate(-13.3%2044.91)%20rotate(-60.3)'/%3e%3ccircle%20id='_椭圆形'%20class='cls-1'%20cx='28.91'%20cy='31.28'%20r='5'/%3e%3cpolygon%20class='cls-1'%20points='42.43%2030.75%2035.08%2029.1%2036.37%2021.5%2039.33%2022.01%2038.51%2026.8%2043.09%2027.82%2042.43%2030.75'/%3e%3cpolygon%20class='cls-1'%20points='16.75%2045.55%209.43%2043.77%2010.86%2036.19%2013.8%2036.75%2012.9%2041.53%2017.46%2042.63%2016.75%2045.55'/%3e%3cpolygon%20class='cls-1'%20points='11.02%2028.19%209.54%2020.8%2017.01%2018.89%2017.75%2021.8%2013.04%2023%2013.96%2027.6%2011.02%2028.19'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
DashVector
Portkey

Baseten
TiDB
LanceDB
Carbon
我们的论文
了解我们的前沿搜索模型是如何从头开始训练的,查看我们的最新论文。在 EMNLP、SIGIR、ICLR、NeurIPS 和 ICML 与我们的团队见面!
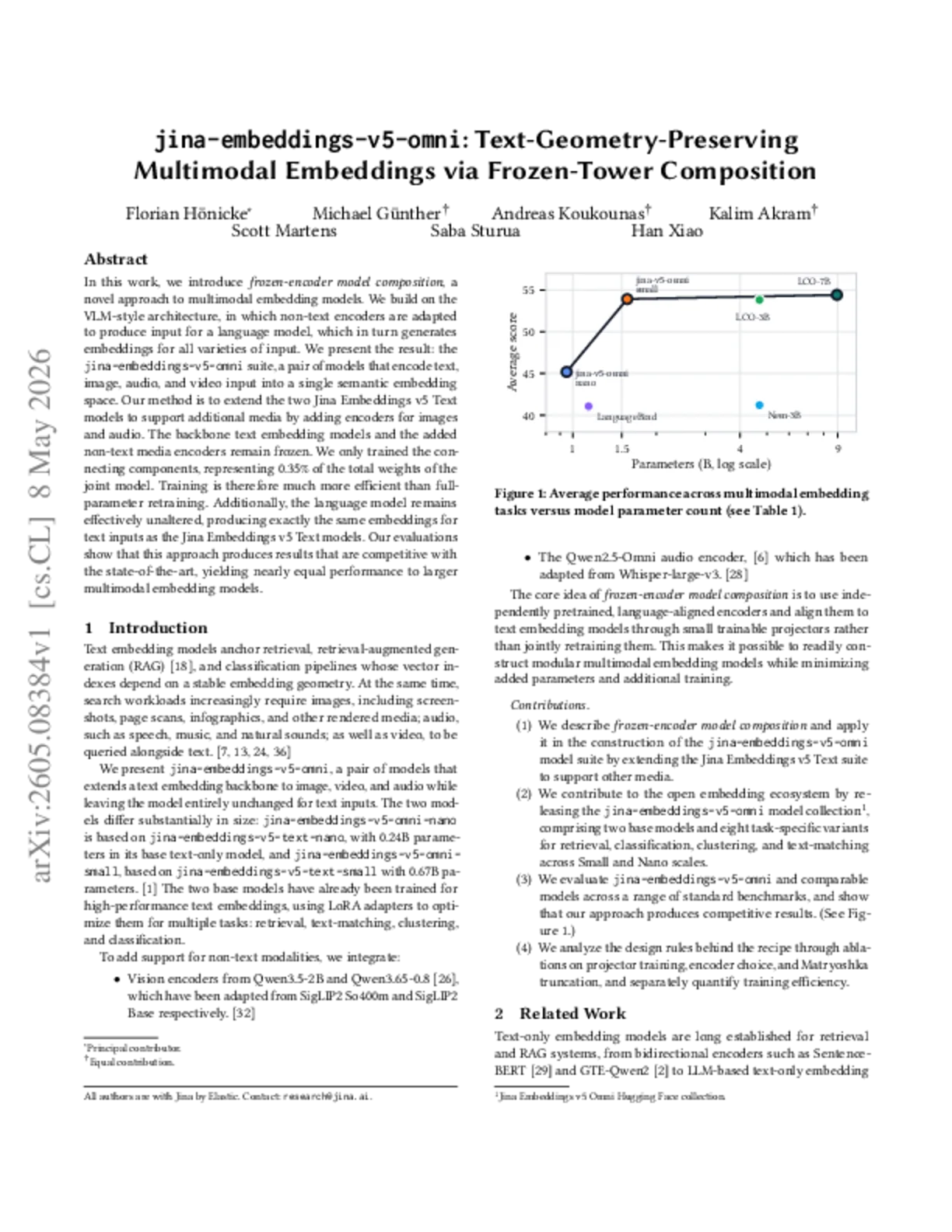
五月 11, 2026

SIGIR 2026
二月 17, 2026

ICLR 2026
一月 22, 2026

十二月 29, 2025

ICLR 2026
十二月 04, 2025

AAAI 2026
十月 01, 2025

NeurIPS 2025
八月 31, 2025

EMNLP 2025
六月 24, 2025

ICLR 2025
三月 04, 2025

ACL 2025
十二月 17, 2024

ICLR 2025
十二月 12, 2024

ECIR 2025
九月 18, 2024

SIGIR 2025
九月 07, 2024

EMNLP 2024
八月 30, 2024

WWW 2025
六月 21, 2024

ICML 2024
五月 30, 2024

二月 26, 2024

十月 30, 2023

EMNLP 2023
七月 20, 2023
共计 19 篇论文。
学习向量模型
什么是向量,为什么要向量化?我们已经为您提供了一些入门文章。通过我们的综合指南从头开始了解向量模型。




重排器、向量搜索和 BM25 的比较
下表提供了 重排器、向量搜索和 BM25 的全面比较,突出显示了它们在各个类别中的优缺点。
| 重排器 | 向量搜索 | BM25 | |
|---|---|---|---|
| 最适合场景 | 增强的搜索精度和相关性 | 初始、快速过滤 | 跨广泛查询的一般文本检索 |
| 粒度 | 详细:子文档和查询段 | 广泛:整个文档 | 中级:各种文本片段 |
| 查询时间复杂度 | 高的 | 中等的 | 低的 |
| 索引时间复杂度 | 不需要 | 高的 | 低,利用预建索引 |
| 训练时间复杂度 | 高的 | 高的 | 不需要 |
| 搜索质量 | 更适合细致入微的查询 | 效率与准确性之间的平衡 | 对于广泛的查询来说一致且可靠 |
| 优势 | 高度准确,具有深入的上下文理解 | 快速高效,准确度适中 | 高度可扩展,具有既定的功效 |
| 免费试用重排器 API | 免费使用向量模型 API |

Jina嵌入模型是如何训练的?
keyboard_arrow_down
你们的多模态向量模型是什么?
keyboard_arrow_down
你们的模型支持哪些语言?
keyboard_arrow_down
单个句子输入的最大长度是多少?
keyboard_arrow_down
单个请求中最多可以包含多少个句子?
keyboard_arrow_down
如何将图像发送到多模态向量模型?
keyboard_arrow_down
Jina Embeddings 模型与 OpenAI 和 Cohere 的最新向量模型相比如何?
keyboard_arrow_down
如何从 OpenAI 的 text-embedding-3-large 迁移到 Jina Embeddings 模型?
keyboard_arrow_down
使用 jina-clip 模型时如何计算 token?
keyboard_arrow_down
你们提供向量模型图片或音频的模型吗?
keyboard_arrow_down
Jina 向量模型模型可以使用私人或公司数据进行微调吗?
keyboard_arrow_down
您的服务可以在 AWS、Azure 或 GCP 上私有化部署吗?
keyboard_arrow_down
“task”参数是什么?我应该在什么情况下使用它?
keyboard_arrow_down
什么是延迟交互检索?哪些模型支持这种检索方式?
keyboard_arrow_down
什么是延迟分块?我应该在什么情况下使用它?
keyboard_arrow_down
为什么 API 支持的上下文长度与模型的最大容量不同?
keyboard_arrow_down
为什么jina-embeddings-v4是免费的,但速度却很慢?
keyboard_arrow_down
Embeddings API 的速率限制是多少?
keyboard_arrow_down
每个嵌入模型的上下文长度限制是多少?
keyboard_arrow_down
图片和PDF文件的大小限制是多少?
keyboard_arrow_down
速率限制
速率限制通过三种方式跟踪:RPM(每分钟请求数)和TPM(每分钟词元数)。限制按 IP/API 密钥强制执行,当首先达到 RPM 或 TPM 阈值时,将触发限制。当您在请求标头中提供 API 密钥时,我们会按密钥而不是 IP 地址跟踪速率限制。
| 产品 | API端口 | 描述arrow_upward | 无 API 密钥key_off | 免费 API 密钥key | 使用付费 API 密钥key | 带有高级 API 密钥key | 平均延迟 | 词元使用计数 | 请求类型 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 读取器 API | https://r.jina.ai | 将 URL 转换为大模型友好文本 | 20 RPM | 500 RPM | 500 RPM | trending_up5000 RPM | 7.9s | 以输出响应中的词元数量为准。 | GET/POST | |
| 读取器 API | https://s.jina.ai | 搜索网络并将结果转换为大模型友好文本 | block | 100 RPM | 100 RPM | trending_up1000 RPM | 2.5s | 每个请求都需要固定数量的词元,从 10000 个词元开始 | GET/POST | |
| 向量模型API | https://api.jina.ai/v1/embeddings | 将文本/图片转为定长向量 | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart 取决于输入大小 help | 以输入请求中的词元数量为准。 | POST | |
| 重排器 API | https://api.jina.ai/v1/rerank | 按查询对文档进行精排 | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart 取决于输入大小 help | 以输入请求中的词元数量为准。 | POST | |
| 分类器 API | https://api.jina.ai/v1/train | 使用训练样本训练分类器 | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart 取决于输入大小 | 词元计数为:输入词元 × 迭代次数 | POST | |
| 分类器 API (少量样本) | https://api.jina.ai/v1/classify | 使用经过训练的少样本分类器对输入进行分类 | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart 取决于输入大小 | 词元计数为:输入词元 | POST | |
| 分类器 API (零样本) | https://api.jina.ai/v1/classify | 使用零样本分类对输入进行分类 | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart 取决于输入大小 | 词元计数为:输入词元 加 标签词元 | POST | |
| 切分器 API | https://api.jina.ai/v1/segment | 对长文本进行分词分句 | 20 RPM | 200 RPM | 200 RPM | 1,000 RPM | 0.3s | 词元不计算使用量。 | GET/POST | |
| 深度搜索 | https://deepsearch.jina.ai/v1/chat/completions | 推理、搜索和迭代以找到最佳答案 | block | 50 RPM | 50 RPM | 500 RPM | 56.7s | 统计整个过程中词元的总数。 | POST |
CC BY-NC 许可证自检
play_arrow
您使用的是我们在 Azure、AWS 还是 GCP 上的官方 API 或官方镜像?
play_arrow
是的
play_arrow
不
API相关常见问题
code
我可以对读取器、向量模型、重排器、分类器和微调模型 API 使用相同的 API 密钥吗?
keyboard_arrow_down
code
我可以查看 API 密钥的词元使用情况吗?
keyboard_arrow_down
code
如果我忘记了 API 密钥,该怎么办?
keyboard_arrow_down
code
API 密钥会过期吗?
keyboard_arrow_down
code
我可以在 API 密钥之间转移额度吗?
keyboard_arrow_down
code
我可以销毁我的 API 密钥吗?
keyboard_arrow_down
code
为什么有些机型第一次请求比较慢?
keyboard_arrow_down
code
我的API数据是否用于训练你们的模型?
keyboard_arrow_down
code
Jina API 的速率限制是多少?
keyboard_arrow_down
code
API是否有批量大小限制?
keyboard_arrow_down
与计费相关的常见问题
attach_money
API是根据句子的数量或请求的数量计费吗?
keyboard_arrow_down
attach_money
新用户可以免费试用吗?
keyboard_arrow_down
attach_money
失败的请求是否会扣除词元?
keyboard_arrow_down
attach_money
接受哪些付款方式?
keyboard_arrow_down
attach_money
充值后可以开具发票吗?
keyboard_arrow_down