

继上一代 Embeddings V2 的巨大成功之后,我们很高兴地宣布推出最新的中英双语文本嵌入模型:jina-embeddings-v2-base-zh。这个新模型继承了 Jina Embeddings V2 的 8K tokens 长度的卓越特性,现在同时支持中文和英文。
jina-embeddings-v2-base-zh 以其卓越的质量和性能脱颖而出,这得益于使用高质量的双语数据进行严格和平衡的预训练。这种方法有效减少了在使用不平衡的多语言数据训练时常见的偏差。
tag亮点特性
- 双语模型:该模型可以同时编码中英文本,允许使用任一语言作为查询或目标文档。这两种语言中具有相同含义的文本会被映射到相同的嵌入空间,为众多多语言应用奠定基础。
- 扩展至 8K Token 长度:我们的模型能够处理大段文本,这一特性超越了大多数其他开源模型的能力。
- 小巧高效:模型大小为 322MB(1.61 亿参数)且输出维度为 768,设计用于在无 GPU 的标准计算机硬件上实现高性能,提高了其可访问性。
tag在 C-MTEB 上的领先表现
在中文 MTEB 排行榜上,我们支持中英双语的 Jina Embeddings v2 在0.5GB 以下的模型中表现出色。其独特之处在于具备 8K token 长度的能力,这在同类模型中是独一无二的。
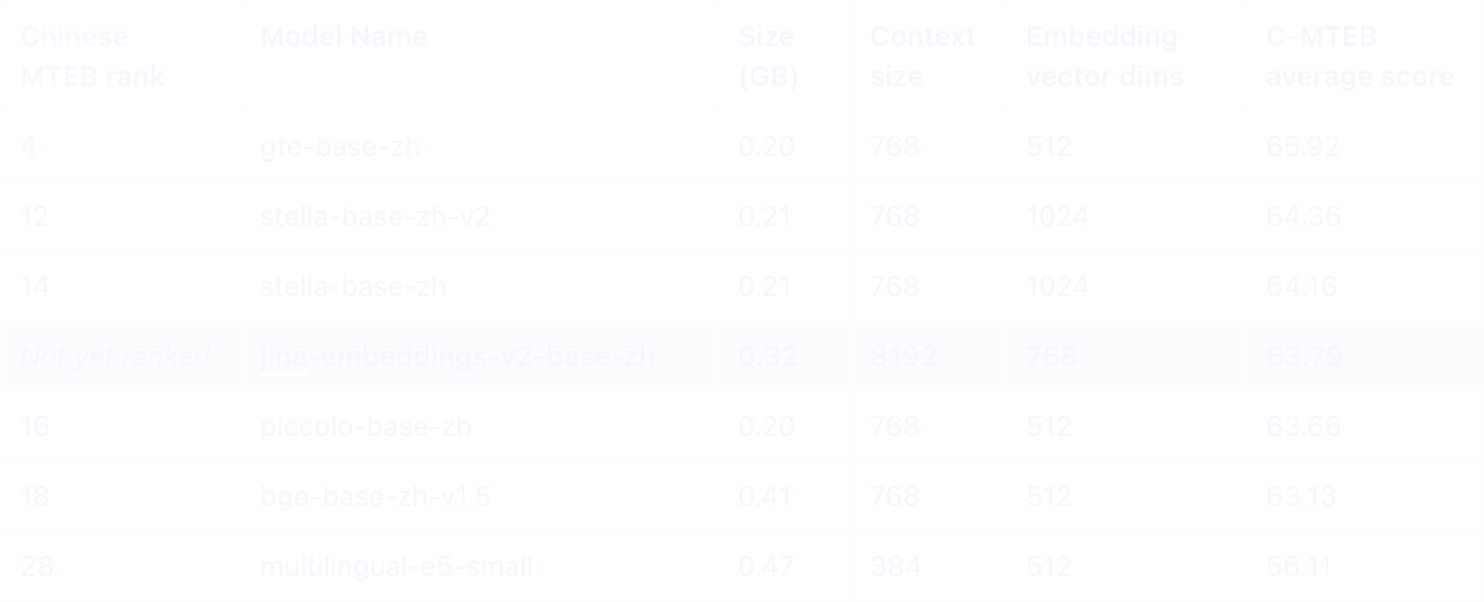
在类似规模的中文模型中,只有 E5 多语言模型和我们的 jina-embeddings-v2-base-zh 提供英语支持,能够实现有效的跨语言应用。值得注意的是,Jina 在所有涉及中文的类别中都表现出明显的优势。

虽然两个模型都具有 8K token 上下文大小,但 jina-embeddings-v2-base-zh 显著优于 OpenAI 的 text-embedding-ada-002,特别是在涉及中文的任务中。

tag助力中国企业全球化发展
我们的中英嵌入模型是中国企业"出海"的强大工具。它可以无缝处理中文文本,提供高质量的嵌入,轻松集成到领先的向量数据库、搜索系统和 RAG 应用中。
jina-embeddings-v2-base-zh 特别适合开发针对中英文场景的 AI 应用,这对拓展国际业务的企业至关重要。以下是一些具体用例:
- 文档分析与管理:可以分析和管理大量文档,助力国际法律和商业交易。
- AI 驱动的搜索应用:在多语言环境中增强搜索功能,使全球用户更容易找到中英文相关信息。
- 检索增强型聊天机器人和问答系统:构建高效的双语客户服务机器人,改善与全球客户的互动。
- 自然语言处理应用:包括用于理解全球市场趋势的情感分析、国际营销策略的主题建模,以及管理全球沟通的文本分类。
- 推荐系统:利用中英文数据的见解,为全球多元化受众定制产品和内容推荐。
通过利用这个模型,中国企业可以有效地跨越 AI 应用中的语言障碍,提升全球竞争力和市场覆盖。
tag通过 API 开始使用 jina-embeddings-v2-base-zh
立即通过 Embeddings API 将我们的模型集成到您的工作流程中。只需访问我们的 Embeddings 门户,获取免费访问密钥或充值现有密钥,然后从下拉菜单中选择 jina-embeddings-v2-base-zh。就这么简单!

tag未来展望:扩展语言支持和 AWS Sagemaker 集成
jina-embeddings-v2-base-zh 即将在 AWS Sagemaker 和 Hugging Face 上线。



在 Jina AI,我们坚持致力于成为全球受众可负担且易访问的嵌入技术领导者。我们正在积极开发更多多语言产品,重点关注主要欧洲语言和其他国际语言,以扩大我们的覆盖范围。敬请期待这些令人兴奋的更新,包括与 AWS SageMaker 的集成,我们将继续扩展我们的能力。
tag特别感谢早期测试用户
我们衷心感谢中国用户社区中测试预览版(jina-embeddings-v2-base-zh-preview)的精选成员。他们富有洞察力的反馈对提升正式版本的性能起到了关键作用。如果您对我们模型的质量有任何观察或建议,我们热诚邀请您加入我们的 Discord 服务器并与我们分享您的想法。您的意见对我们持续改进的过程非常宝贵。


相比 jina-embeddings-v2-base-zh-preview 的分数分布改进
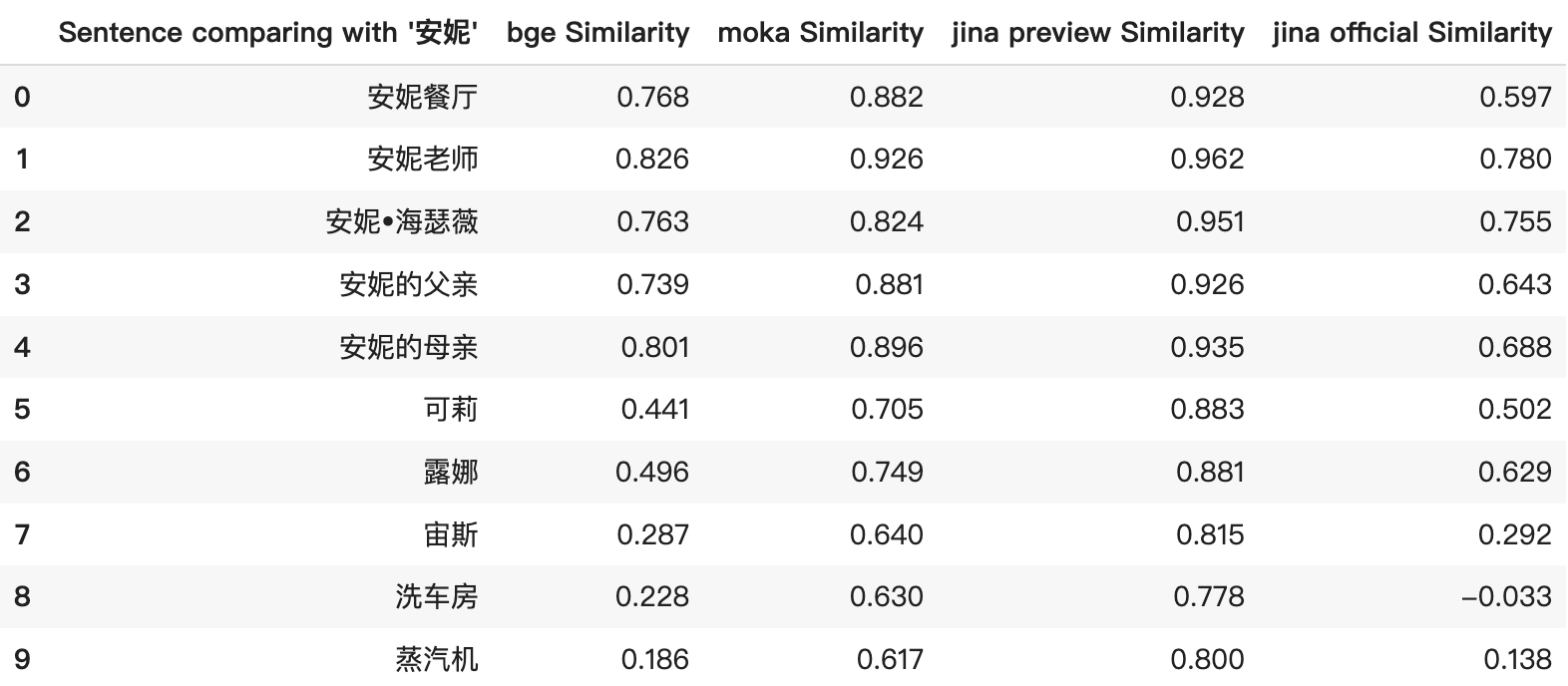
jina-embeddings-v2-base-zh-preview 存在相似度分数膨胀的问题,即使是不相关的条目也会获得高余弦相似度分数。这一点在下面截图中的前 5 个结果中特别明显。相似度分数始终很高,并且无法准确反映条目之间的真实关系。比如,"安妮"和"蒸汽机"之间的比较获得了误导性的高相似度分数。
在正式版本中,我们已经对模型进行了微调,使其产生更加明显和合理的相似度分数,确保更准确地表示条目之间的关系。例如,修订后的评分现在呈现更广的范围,能更清晰地反映条目间的相对相似度。
此外,Jina Embeddings 现在独特地成为唯一支持 8192 个词元的开源嵌入模型。这一特性凸显了其处理各种数据类型的能力,从长篇文档到简短短语,甚至是单个词语/名称,如"安妮"对比"露娜"。
tag中英双语 8K 向量大模型新鲜出炉,企业出海必备!
自从我们的 Embeddings V2 获得各界好评后,今日,我们推出了全新的中英双语文本向量大模型:jina-embeddings-v2-base-zh。此模型不仅继承了 V2 的全部优势,能够处理长达八千词元的文本,更能流畅应对中英文双语内容,为跨语种的应用插上了翅膀。
jina-embeddings-v2-base-zh 之所以表现卓越,全赖优质的双语数据集,经过我们严格且平衡的 预训练、一阶微调和二阶微调。这种三步走的训练范式不仅泛化了模型的双语能力,更有效的降低了模型偏见,解决了多语言模型时常遭遇到的"不患寡而患不均"的问题。
tag模型特色一览
特色 1:双语无缝对接
jina-embeddings-v2-base-zh 模型能够流畅处理中英文本,无论是作为搜索查询还是目标文档。中英文本中意义相近的内容都会被映射到相同的向量空间,为多语言应用奠定了坚实基础。
特色 2:8k Token 超长文本支持
我们的模型支持长达 8K Token 的文本处理,这在开源向量模型中独树一帜,在处理更长的文本段落上提供了显著优势。
特色 3:高效紧凑的模型结构
jina-embeddings-v2-base-zh 模型以 322MB 的轻巧体积(包含 1.61 亿参数),输出维度为 768,能够在普通计算机硬件上高效运行,无需依赖 GPU,极大地提升了其实用性和便捷性。
tag模型性能卓越
在 CMTEB 排行榜的激烈竞争中,我们的 Jina Embeddings v2 模型在 0.5GB 以下模型类别中脱颖而出,它不仅支持中英文本,而且能够处理高达 8K Token 的文本,这一能力在同类模型中实属罕见。
在同等体积的支持中文的模型中,Multilingual E5 和我们的 jina-embeddings-v2-base-zh 是唯二能够处理英文的模型,这使得跨语言应用成为可能。
目前,全球范围内,仅有 OpenAI 的闭源模型 text-embedding-ada-002 和 Jina Embeddings 能够支持 8k Token 的长文本输入。而在处理中文任务方面,Jina Embeddings 显示出了显著的性能优势。
tag助力中国企业拓展全球业务
我们的中英双语向量模型 jina-embeddings-v2-base-zh 是中国企业进军国际市场的强大伙伴。它能够无缝处理中英双语文本,并提供高质量的文本向量表示,还能轻松集成到先进的向量数据库、搜索系统以及 RAG 应用里。
这款模型特别适合打造适应中英双语场景的 AI 应用,对于追求全球化发展的企业来说,其价值不可估量。以下是几个实际应用案例:
- 文档分析与管理:分析和管理海量文档,助力国际法律和商务交易的顺利进行。
- AI-driven search applications: Improve search performance in multilingual environments, helping global users easily find information in both Chinese and English.
- Enhanced retrieval chatbots and QA systems: Create efficient bilingual customer service bots, optimizing communication experiences with global customers.
- Natural Language Processing applications: Cover global market trend analysis, international market strategy topic modeling, and text classification for global communications management.
- Recommendation systems: Leverage Chinese and English data insights to provide personalized product and content recommendations for diverse global audiences.
With this model, Chinese enterprises can bridge the language gap in AI applications and gain an early advantage in global market competition.
tagGetting Started with jina-embeddings-v2-base-zh
Want to quickly integrate our bilingual embedding model into your workflow? Just follow these simple steps: visit https://jina.ai/embeddings, get your free API key or update your existing one, then select jina-embeddings-v2-base-zh from the dropdown menu, and your model is instantly ready for exploration and use!
tagLooking Forward: Multilingual Support and Deep Integration with AWS SageMaker
jina-embeddings-v2-base-zh will soon be available on AWS SageMaker and HuggingFace, providing users with more convenient service options.
We are actively advancing our multilingual embedding models, particularly focusing on support for European and other international languages, to meet the diverse needs of global users. Stay tuned for our exciting upcoming updates, including deep integration with AWS SageMaker, as we continue to deepen and broaden our service scope.
tagAcknowledgments: Thanks to Early Testers for Their Valuable Contributions
We sincerely thank our Chinese community friends who participated in testing jina-embeddings-v2-base-zh-preview. Your valuable feedback played a crucial role in optimizing our model. If you have any suggestions or ideas during use, please feel free to share them with us. Every piece of feedback drives our continuous improvement.
Official Version Resolves Score Inflation Issues from Preview Version
Compared to the preview version, the official model provides more distributed and reasonable similarity scores. During preview testing, our model showed similarity score inflation, where even completely unrelated words like 'Annie' and 'steam engine' would receive high cosine similarity scores. In the official version, we've optimized the model to ensure more reasonable similarity scores that more accurately reflect relationships between content.
Additionally, Jina Embeddings now supports text processing up to 8192 tokens, demonstrating its powerful capability to handle various types of data, whether long articles, short phrases, or single words or names (such as comparing "Annie" with "Luna"). This improvement not only enhances the model's accuracy but also increases its flexibility and practicality in handling diverse data.




