

人工智能模型长期存在的一个问题是,神经网络无法解释它们是如何产生输出的。这对人工智能来说到底是不是一个真正的问题并不总是很清楚。当我们要求人类解释他们的推理过程时,他们经常会进行合理化解释,通常完全不知道自己在这样做,给出看似最合理的解释,而没有任何迹象表明他们脑子里真正在想什么。
我们已经知道如何让 AI 模型做出合理的回答。也许在这方面,人工智能比我们愿意承认的更像人类。
五十年前,美国哲学家托马斯·内格尔(Thomas Nagel)写了一篇很有影响力的文章,叫作《做一只蝙蝠是什么感觉?》。他认为,做一只蝙蝠一定有某种感觉:像蝙蝠那样看世界,以蝙蝠的方式感知存在。然而,按照内格尔的说法,即使我们知道关于蝙蝠大脑、蝙蝠感官和蝙蝠身体如何工作的所有可知事实,我们仍然不会知道做一只蝙蝠是什么感觉。
AI 可解释性是同样的问题。我们知道关于特定 AI 模型的所有事实。它不过是一系列矩阵中排列的有限精度数字。我们可以轻松验证每个模型输出都是正确算术运算的结果,但这些信息作为解释是毫无用处的。
对于这个问题,无论是 AI 还是人类都没有普遍的解决方案。然而,ColBERT 架构,特别是当它作为重排模型使用"后期交互"时,能够让你从模型中获得有意义的见解,了解它在特定情况下给出具体结果的原因。
本文将向你展示后期交互如何实现可解释性,使用的是 Jina-ColBERT 模型 jina-colbert-v1-en 和 Matplotlib Python 库。
tagColBERT 简介
ColBERT 由 Khattab & Zaharia (2020) 引入,是对谷歌在 2018 年首次提出的 BERT 模型的扩展。Jina AI 的 Jina-ColBERT 模型借鉴了这项工作以及 Santhanam 等人 (2021) 后来提出的 ColBERT v2 架构。ColBERT 类型的模型可以用来创建嵌入,但当用作重排模型时它们还有一些额外的特性。主要优势是"后期交互",这是一种与标准嵌入模型不同的语义文本相似度问题结构化方法。
tag嵌入模型
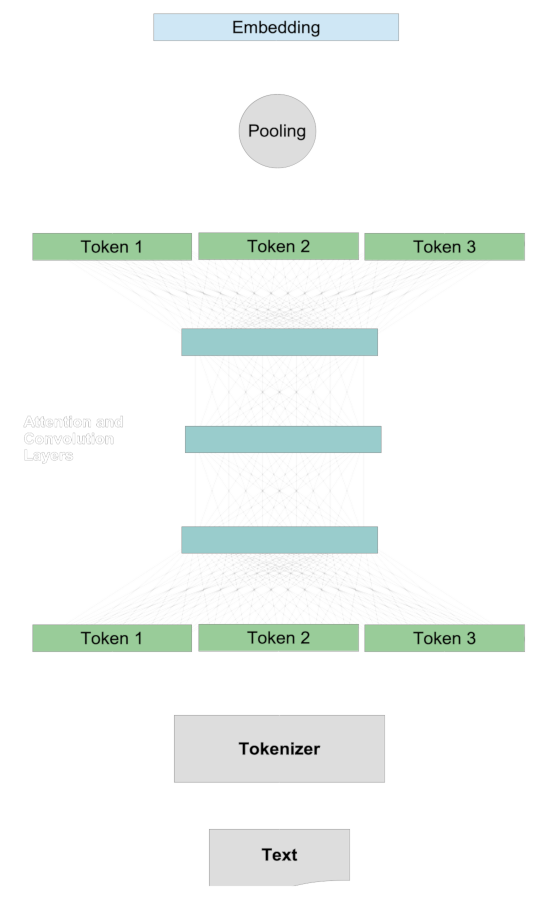
在传统的嵌入模型中,我们通过为两段文本生成称为"嵌入"的代表性向量来比较它们,然后通过余弦或汉明距离等距离度量来比较这些嵌入。量化两段文本的语义相似度通常遵循一个共同的程序。
首先,我们分别为两段文本创建嵌入。对于任何一段文本:
- 分词器将文本分解成大致是词大小的块。
- 每个标记映射到一个向量。
- 标记向量通过注意力系统和卷积层相互作用,为每个标记的表示添加上下文信息。
- 池化层将这些修改后的标记向量转换成单个嵌入向量。
然后,当每个文本都有了嵌入后,我们比较它们,通常使用余弦度量或汉明距离。
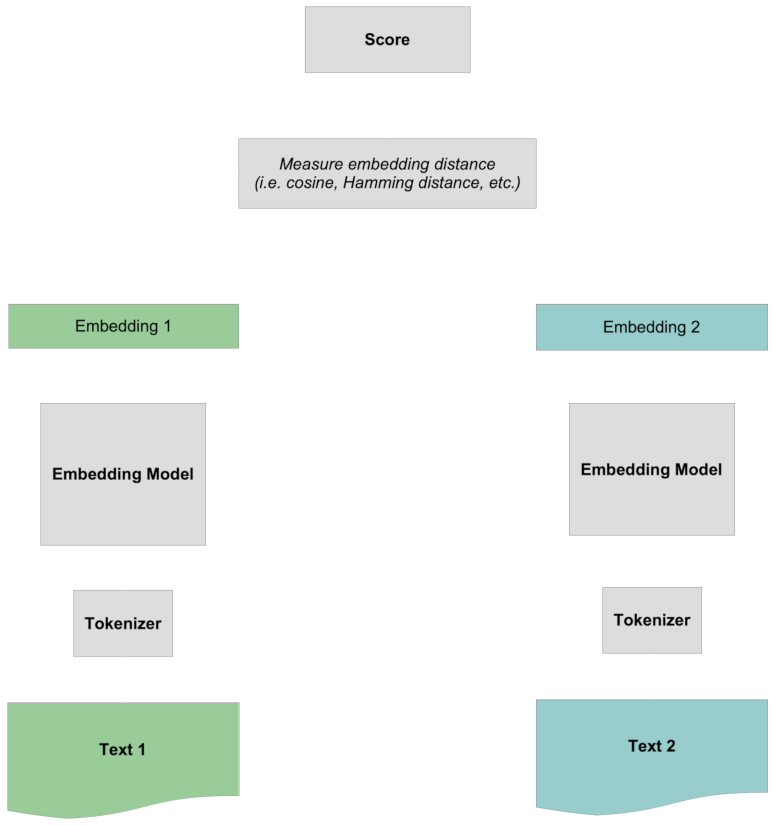
评分是通过比较两个完整的嵌入来进行的,不包含任何关于标记的具体信息。所有标记之间的交互都是"早期的",因为它发生在两段文本相互比较之前。
tag重排模型
重排模型的工作方式不同。
首先,它不是为任何文本创建嵌入,而是取一段文本(称为"查询")和一组其他文本(我们称之为"目标文档"),然后根据查询文本对每个目标文档进行评分。这些数字没有归一化,也不像比较嵌入,但它们是可排序的。根据模型,相对于查询得分最高的目标文档是与查询语义最相关的文本。
让我们使用 Jina Reranker API 和 Python,具体看看这在 jina-colbert-v1-en 重排模型中是如何工作的。
以下代码也在一个笔记本中,你可以下载或在 Google Colab 中运行。
首先,你应该在你的 Python 环境中安装最新版本的 requests 库。你可以使用以下命令:
pip install requests -U
接下来,访问 Jina Reranker API 页面并获取一个免费的 API token,可用于处理最多一百万个文本标记。如下图所示,从页面底部复制 API token:
我们将使用以下查询文本:
- "Elephants eat 150 kg of food per day."
并将这个查询与三段文本进行比较:
- "Elephants eat 150 kg of food per day."
- "Every day, the average elephant consumes roughly 150 kg of plants."
- "The rain in Spain falls mainly on the plain."
第一个文档与查询完全相同,第二个是第一个的改写,最后一个文本则完全无关。
使用以下 Python 代码获取分数,将你的 Jina Reranker API token 赋值给变量 jina_api_key:
import requests
url = "<https://api.jina.ai/v1/rerank>"
jina_api_key = "<YOUR JINA RERANKER API TOKEN HERE>"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {jina_api_key}"
}
data = {
"model": "jina-colbert-v1-en",
"query": "Elephants eat 150 kg of food per day.",
"documents": [
"Elephants eat 150 kg of food per day.",
"Every day, the average elephant consumes roughly 150 kg of food.",
"The rain in Spain falls mainly on the plain.",
],
"top_n": 3
}
response = requests.post(url, headers=headers, json=data)
for item in response.json()['results']:
print(f"{item['relevance_score']} : {item['document']['text']}")
在 Python 文件或笔记本中运行这段代码应该产生以下结果:
11.15625 : Elephants eat 150 kg of food per day.
9.6328125 : Every day, the average elephant consumes roughly 150 kg of food.
1.568359375 : The rain in Spain falls mainly on the plain.
正如我们所期望的,完全匹配的文本得分最高,改写版本得分第二高,而完全无关的文本得分要低得多。
tag使用 ColBERT 进行评分
ColBERT 重排与基于嵌入的评分的不同之处在于,两段文本的标记在评分过程中会相互比较。两段文本永远不会有自己的嵌入。
首先,我们使用与嵌入模型相同的架构,为每个标记创建包含文本上下文信息的新表示。然后,我们比较查询中的每个标记与文档中的每个标记。
对于查询中的每个标记,我们识别出文档中与之交互最强的标记,并对这些交互分数求和以计算最终的数值。
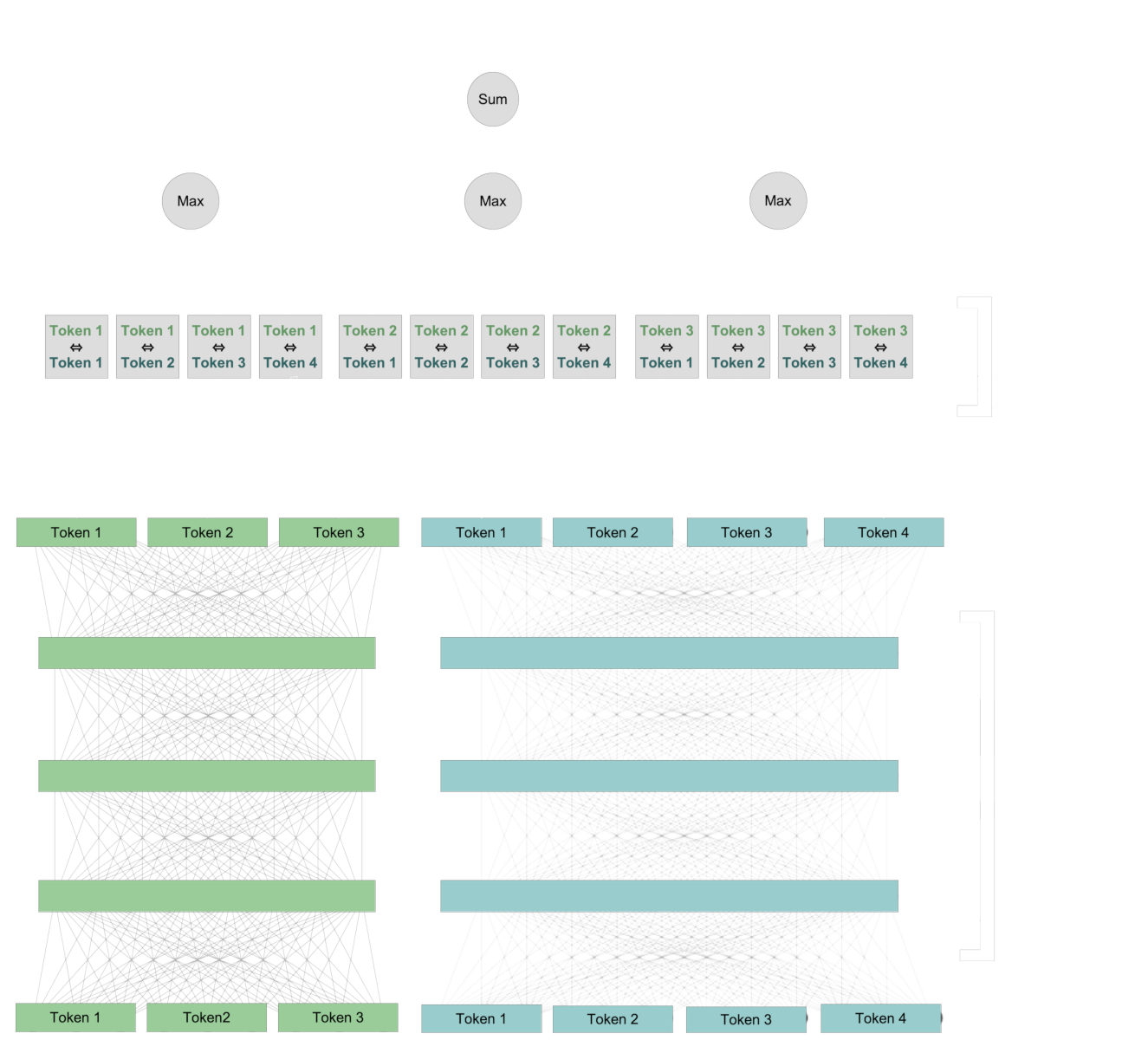
这种交互是"后期"的:当我们比较两个文本时,词元之间会相互交互。但请记住,"后期"交互并不排除"早期"交互。被比较的词元向量对已经包含了它们各自上下文的信息。
这种后期交互方案保留了词元级别的信息,即使这些信息是上下文相关的。这使我们能够部分看到 ColBERT 模型是如何计算得分的,因为我们可以识别出哪些上下文化词元对对最终得分有贡献。
tag使用热力图解释排名
热力图是一种可视化技术,用于查看 Jina-ColBERT 创建评分时的内部运作。在本节中,我们将使用 seaborn 和 matplotlib 库从 jina-colbert-v1-en 的后期交互层创建热力图,展示查询词元如何与目标文本词元交互。
tag设置
我们创建了一个 Python 库文件,其中包含用于访问 jina-colbert-v1-en 模型并使用 seaborn、matplotlib 和 Pillow 创建热力图的代码。你可以直接从 GitHub 下载这个库,或者在你自己的系统上使用提供的 notebook,或者在 Google Colab 上使用。
首先,安装所需依赖。你需要在 Python 环境中安装最新版本的 requests 库。如果你还没有安装,请运行:
pip install requests -U
然后,安装核心库:
pip install matplotlib seaborn torch Pillow
接下来,从 GitHub 下载 jina_colbert_heatmaps.py。你可以通过网页浏览器下载,或者如果安装了 wget,可以在命令行中下载:
wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/heatmaps/jina_colbert_heatmaps.py
准备好库文件后,我们只需要为本文的其余部分声明一个函数:
from jina_colbert_heatmaps import JinaColbertHeatmapMaker
def create_heatmap(query, document, figsize=None):
heat_map_maker = JinaColbertHeatmapMaker(jina_api_key=jina_api_key)
# get token embeddings for the query
query_emb = heat_map_maker.embed(query, is_query=True)
# get token embeddings for the target document
document_emb = heat_map_maker.embed(document, is_query=False)
return heat_map_maker.compute_heatmap(document_emb[0], query_emb[0], figsize)
tag结果
现在我们可以创建热力图了,让我们制作一些热力图并看看它们告诉我们什么。
在 Python 中运行以下命令:
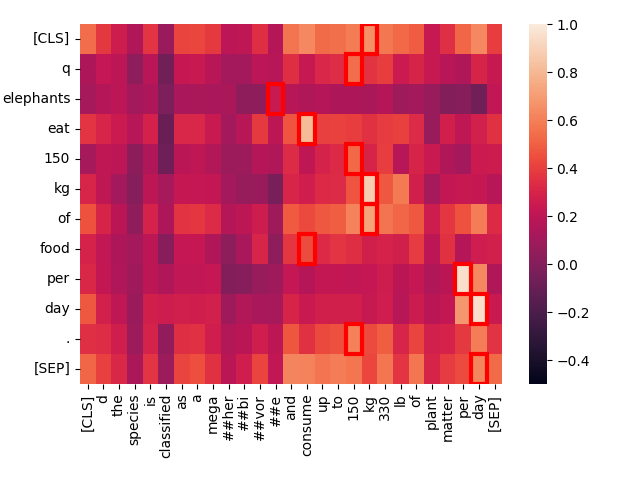
create_heatmap("Elephants eat 150 kg of food per day.", "Elephants eat 150 kg of food per day.")结果将是一个如下所示的热力图:
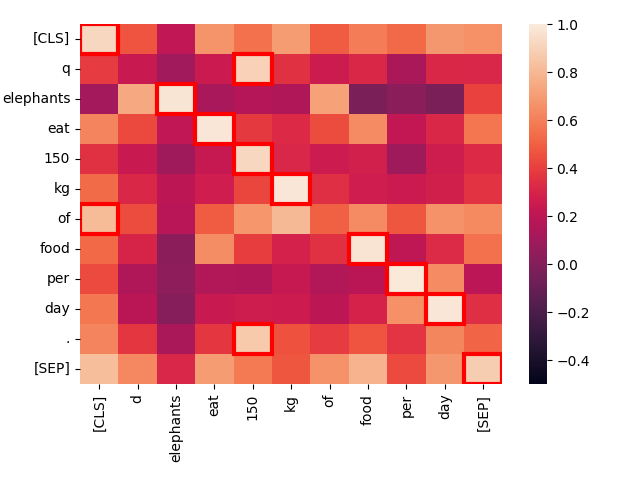
这是比较两个相同文本时词元对之间激活水平的热力图。每个方格显示来自两个文本的一对词元之间的交互。额外的词元 [CLS] 和 [SEP] 分别表示文本的开始和结束,而 q 和 d 分别在查询和目标文档的 [CLS] 词元之后插入。这不仅允许模型考虑词元与文本开始和结束之间的交互,还允许词元表示对它们是在查询中还是在目标文档中保持敏感。
方格越亮,两个词元之间的交互越强,表明它们在语义上相关。每对词元的交互分数范围是 -1.0 到 1.0。红框突出显示的方格是对最终得分有贡献的:对于查询中的每个词元,它与任何文档词元的最高交互水平就是计入的值。
最佳匹配——最亮的点——和红框标记的最大值几乎都恰好在对角线上,并且它们有很强的交互。唯一的例外是"技术性"词元 [CLS]、q 和 d,以及英语中高频的"停用词" "of",这些词携带的独立信息很少。
让我们看一个结构相似的句子——"Cats eat 50 g of food per day."——看看它的词元如何交互:
create_heatmap("Elephants eat 150 kg of food per day.", "Cats eat 50 g of food per day.")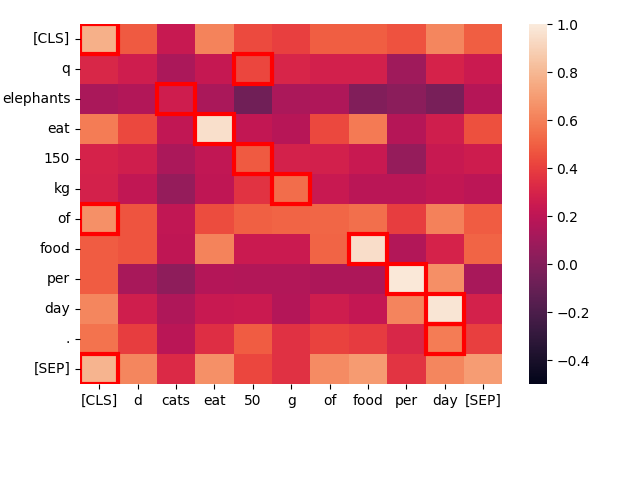
再一次,最佳匹配主要在对角线上,因为大多数词是相同的,且句子结构几乎相同。即使是"cats"和"elephants"也因为它们的共同上下文而匹配,尽管匹配程度不是很高。
上下文越不相似,匹配程度就越差。考虑文本"Employees eat at the company canteen."
create_heatmap("Elephants eat 150 kg of food per day.", "Employees eat at the company canteen.")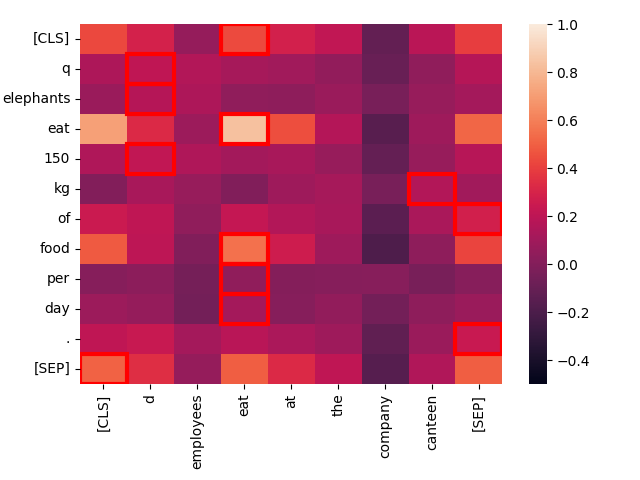
尽管结构相似,这里唯一的强匹配是两个"eat"之间。主题上,这些句子非常不同,即使它们的结构高度平行。
通过查看红框中方格的颜色深浅,我们可以看出模型会如何将它们作为"Elephants eat 150 kg of food per day"的匹配进行排名,jina-colbert-v1-en 证实了这种直觉:
| Score | Text |
|---|---|
| 11.15625 | Elephants eat 150 kg of food per day. |
| 8.3671875 | Cats eat 50 g of food per day. |
| 3.734375 | Employees eat at the company canteen. |
现在,让我们将"Elephants eat 150 kg of food per day."与一个本质上含义相同但表述不同的句子进行比较:"Every day, the average elephant consumes roughly 150 kg of food."
create_heatmap("Elephants eat 150 kg of food per day.", "Every day, the average elephant consumes roughly 150 kg of food.")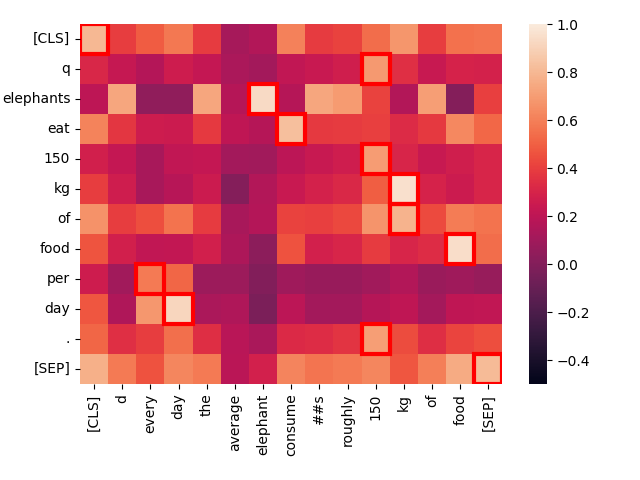
请注意第一句中的"eat"和第二句中的"consume"之间的强关联。尽管词汇不同,Jina-ColBERT 仍能识别出它们的共同含义。
另外,"every day"与"per day"有很强的匹配度,尽管它们在句子中的位置完全不同。只有低值词"of"显示出异常的不匹配。
现在,让我们将相同的查询与一个完全无关的文本进行比较:"The rain in Spain falls mainly on the plain."
create_heatmap("Elephants eat 150 kg of food per day.", "The rain in Spain falls mainly on the plain.")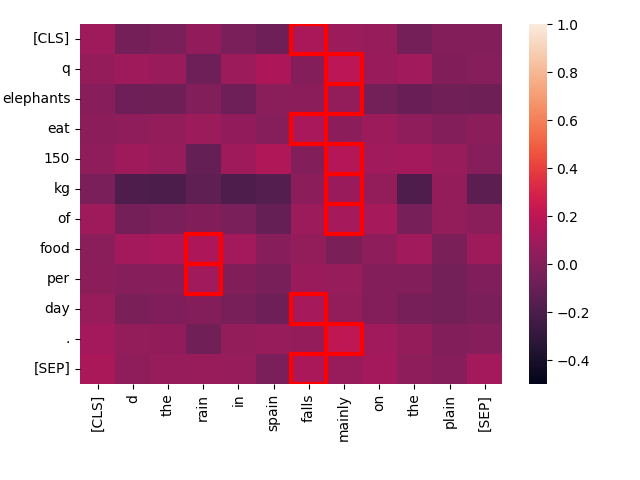
你可以看到,这对文本的"最佳匹配"互动得分要低得多,两段文本中的任何词之间几乎都没有互动。从直观上来说,与"Every day, the average elephant consumes roughly 150 kg of food"相比,我们预期它的得分会很低,而 jina-colbert-v1-en 也证实了这一点:
| Score | Text |
|---|---|
| 9.6328125 | Every day, the average elephant consumes roughly 150 kg of food. |
| 1.568359375 | The rain in Spain falls mainly on the plain. |
tag长文本
这些是用来演示 ColBERT 式重排序模型工作原理的简单示例。在信息检索场景中,如检索增强生成,查询通常是短文本,而匹配的候选文档往往更长,通常与模型的输入上下文窗口一样长。
Jina-ColBERT 模型都支持 8192 个 token 的输入上下文,相当于大约 16 页标准单倍行距的文本。
我们也可以为这些不对称的情况生成热图。例如,让我们看看印度象维基百科页面的第一部分:
要查看传递给 jina-colbert-v1-en 的纯文本,请点击此链接。
这段文本有 364 个词,所以我们的热图看起来不会很方正:
create_heatmap("Elephants eat 150 kg of food per day.", wikipedia_elephants, figsize=(50,7))
我们可以看到"elephants"在文本中多处匹配。在一篇关于大象的文章中,这并不令人意外。但我们也可以看到一个互动强度特别高的区域:
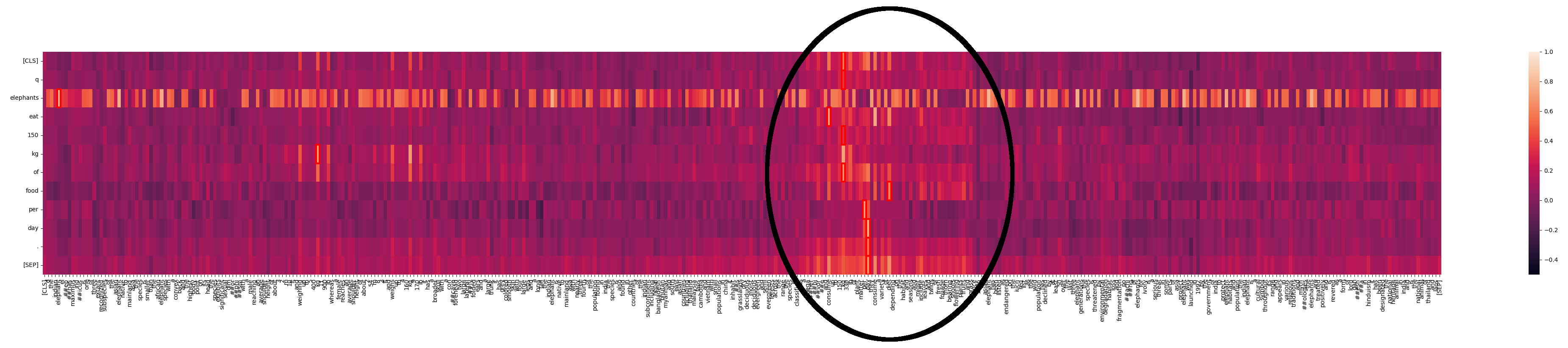
这里发生了什么?通过 Jina-ColBERT,我们可以找到长文本中对应的部分。原来是第二段的第四句话:
该物种被归类为巨型食草动物,每天能消耗高达 150 kg (330 lb) 的植物。
这重述了查询文本中的相同信息。如果我们只看这句话的热图,就能看到强匹配:
Jina-ColBERT 让你能够准确看到长文本中哪些部分导致了它与查询的匹配。这不仅有助于调试,还能提供更好的可解释性。查看匹配是如何形成的并不需要太多技术含量。
tag用 Jina-ColBERT 解释 AI 输出结果
嵌入是现代 AI 中的核心技术。我们所做的几乎一切都基于这样一个理念:输入数据中的复杂、可学习的关系可以在高维空间的几何中表达。然而,对于普通人来说,理解数千到数百万维度的空间关系非常困难。
ColBERT 是从这种抽象层次退后了一步。它不是解释 AI 模型行为问题的完整答案,但它直接指向了我们的结果中哪些数据部分起到了作用。
有时候,AI 必须是一个黑盒子。完成所有重要工作的巨型矩阵太大,任何人都无法完全理解。但 ColBERT 架构为这个黑盒子投射了一点光明,展示了更多可能性。
Jina-ColBERT 模型目前仅支持英语(jina-colbert-v1-en),但更多语言和使用场景正在开发中。这一系列模型不仅能执行最先进的信息检索,还能告诉你为什么会产生匹配,这体现了 Jina AI 致力于使 AI 技术既易于使用又实用的承诺。






