


一天深夜,一名警察发现一个醉汉在路灯下爬来爬去。醉汉告诉警察他在找钱包。当警察问他是否确定钱包是在这里丢的时候,醉汉回答说他觉得更可能是在马路对面丢的。困惑的警察问道:那你为什么要在这里找呢?醉汉解释说:因为这里的光线比较好。
David H. Friedman,为什么科学研究经常出错:路灯效应,《发现》杂志,2010 年 12 月
基准测试是现代机器学习实践的核心组成部分,并且已经持续了很长时间,但它们存在一个非常严重的问题:我们无法判断我们的基准测试是否测量了任何有用的东西。
这是一个大问题,本文将介绍解决方案的一部分:AIR-Bench。这个与北京智源人工智能研究院的联合项目是一种新颖的 AI 评估方法,旨在提高我们基准测试的质量和实用性。


tag路灯效应
科学和运营研究非常强调测量,但测量并非一件简单的事情。在健康研究中,你可能想知道某种药物或治疗是否使接受者更健康、寿命更长,或者以某种方式改善了他们的状况。但健康和生活质量的提高是很难直接测量的,而且可能需要几十年才能知道某种治疗是否延长了某人的寿命。
因此研究人员使用代理指标。在健康研究中,这可能是体力、减轻疼痛、降低血压或其他你可以轻松测量的变量。健康研究的问题之一是,代理指标可能并不能真正反映你希望药物或治疗带来的更好的健康结果。
测量是对你关心的有用事物的代理。你可能无法测量那个事物,所以你测量其他东西,你能测量的东西,而你有理由相信这些测量与你真正关心的有用事物相关。
关注测量是 20 世纪运营研究的一个重要发展,它产生了一些深远而积极的影响。全面质量管理是一套被认为促成了日本在 1980 年代经济主导地位的理论,几乎完全是关于持续测量代理变量并在此基础上优化实践。
但是关注测量存在一些已知的重大问题:
- 当你基于测量结果做决策时,这个测量可能就不再是一个好的代理指标。
- 通常有一些方法可以夸大测量结果而不会带来任何改进,这可能导致作弊或者认为你在做一些实际上并没有帮助的事情而取得了进步。
有些人认为大多数医学研究可能都是错误的,部分原因就在于此。你可以测量的事物与实际目标之间的脱节是美国在越南战争中遭遇灾难的原因之一。
这有时被称为"路灯效应",就像本文开头的故事一样,醉汉不是在他丢失物品的地方寻找,而是在光线较好的地方寻找。代理测量就像在有光的地方寻找,因为我们想看的东西那里没有光。
在更专业的文献中,"路灯效应"通常与古德哈特定律联系在一起,这源于英国经济学家查尔斯·古德哈特对撒切尔政府的批评,该政府非常强调繁荣的代理指标。古德哈特定律有几种表述,但下面这个是最广为人知的:
一旦一个指标成为目标,它就不再是一个好的指标[...]
Keith Hoskins,1996 年《"可怕的问责观念":将人们纳入对象的测量》
在 AI 领域,一个著名的例子是机器翻译研究中使用的 BLEU 指标。BLEU 是 2001 年在 IBM 开发的一种自动评估机器翻译系统的方法,它是 00 年代机器翻译繁荣的关键因素。一旦可以轻松地为你的系统打分,你就可以努力改进它。而 BLEU 分数也在持续提高。到 2010 年,如果一篇关于机器翻译的研究论文没有超越最先进的 BLEU 分数,就几乎不可能发表在期刊或会议上,无论这篇论文有多创新,或者它在处理其他系统难以处理的特定问题方面表现得多么好。
进入会议最简单的方法就是找到一些微小的方法来调整模型参数,获得比 Google Translate 略高的 BLEU 分数,然后提交。这些结果实际上毫无用处。只要用一些新的文本来测试翻译,就会发现它们很少比最先进的系统更好,而且经常更差。
与其用 BLEU 来评估机器翻译的进展,获得更好的 BLEU 分数反而成了目标。一旦发生这种情况,它就不再是评估进展的有效方式。
tag我们的 AI 基准测试是好的代理指标吗?
最广泛使用的 embedding 模型基准测试是 MTEB 测试集,它包含 56 个具体测试。这些测试按类别进行平均,并全部合并产生特定类别的分数。在撰写本文时,MTEB 排行榜的顶部如下所示:
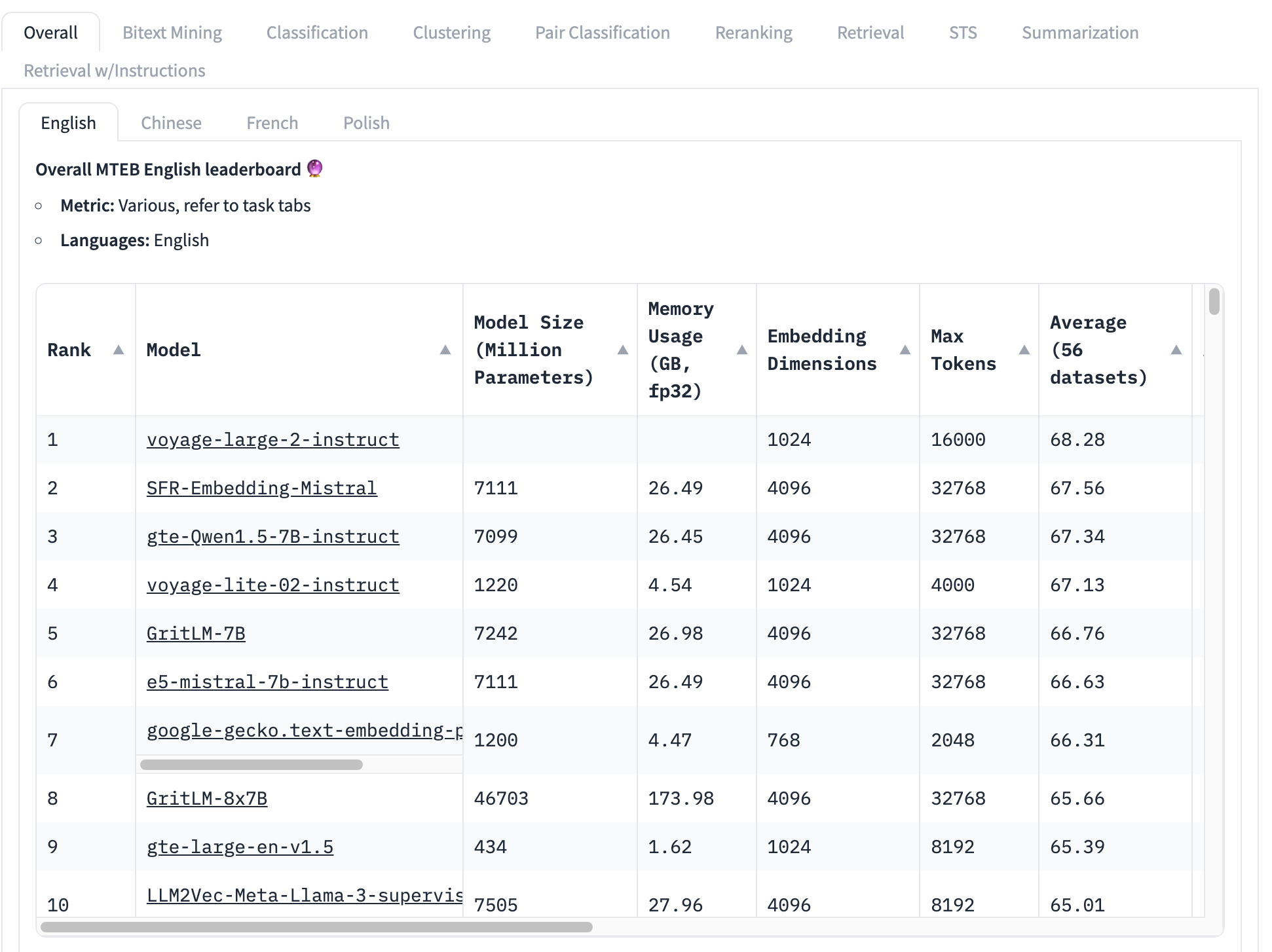
排名最高的 embedding 模型总平均分为 68.28,第二高的是 67.56。看这个表格很难知道这是否是一个显著的差异。如果这是一个小差异,那么其他因素可能比哪个模型得分最高更重要:
- 模型大小:模型有不同的大小,反映了不同的计算资源需求。小模型运行更快,占用内存更少,需要的硬件也更便宜。在这个前 10 名的列表中,我们看到模型大小从 4.34 亿参数到超过 460 亿参数不等 —— 相差 100 倍!
- Embedding 维度:Embedding 维度各不相同。较小的维度使得 embedding 向量占用更少的内存和存储空间,并使向量比较(embeddings 的核心用途)更快。在这个列表中,我们看到 embedding 维度从 768 到 4096 不等 —— 虽然只相差 5 倍,但在构建商业应用时仍然很重要。
- 上下文输入窗口大小:上下文窗口的大小和质量各不相同,从 2048 个 token 到 32768 个不等。此外,不同的模型使用不同的位置编码和输入管理方法,这可能会导致对输入的特定部分产生偏好。
简而言之,总平均分是一种非常不完整的方式来确定哪个 embedding 模型最好。
即使我们查看下面这些特定任务的分数,比如检索任务的分数,我们仍然面临着同样的问题。无论模型在这组测试中的得分如何,都无法知道哪个模型在你特定的独特用例中表现最好。
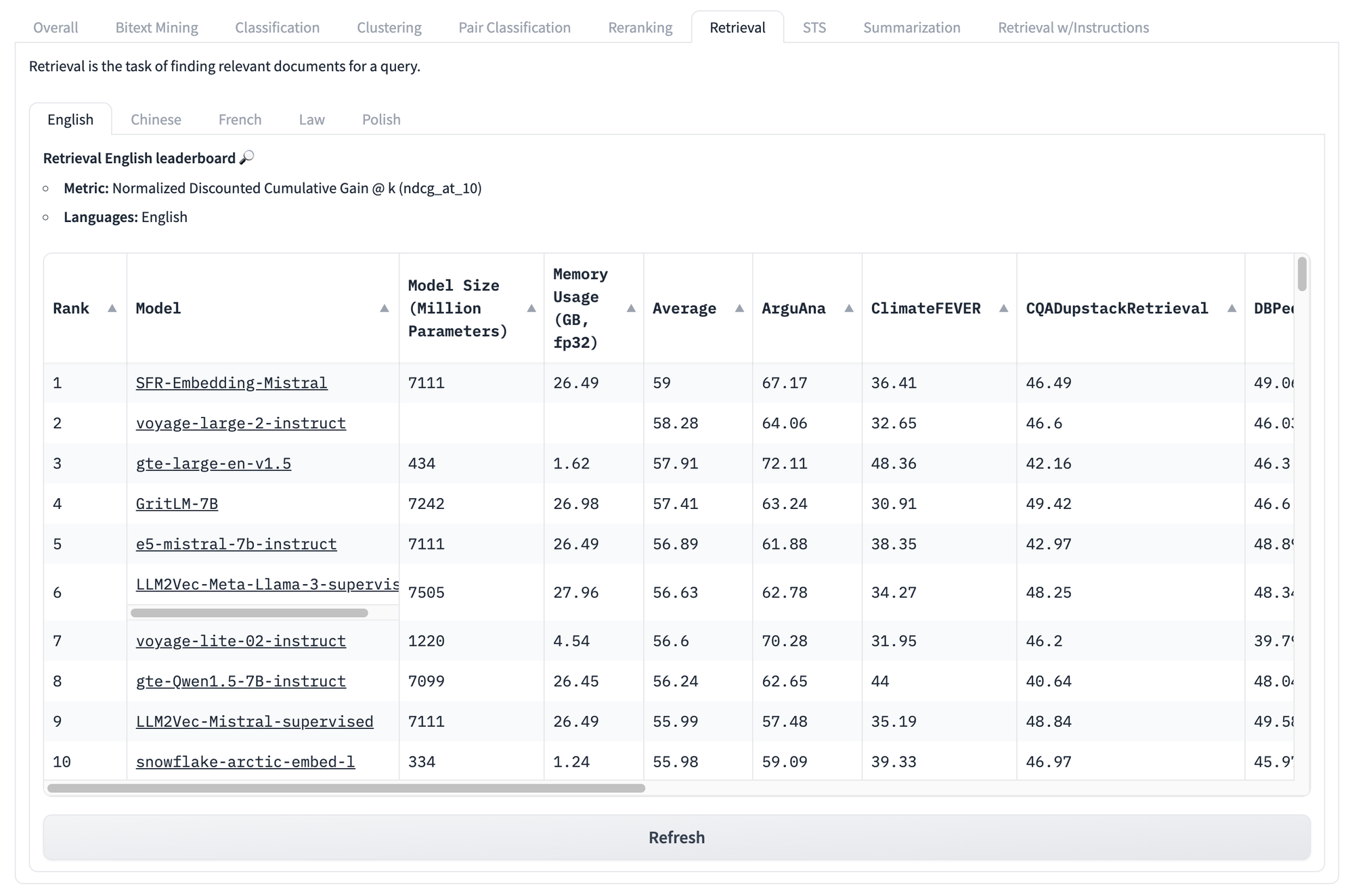
但这些类型的基准测试问题并不止于此。
古德哈特定律的主要洞察是,任何指标都可能被操纵,这往往是无意为之的。例如,MTEB 基准测试包含来自公开来源的数据,这些数据很可能已经包含在你的训练数据中。除非你特意努力从训练中移除基准测试数据,否则你的基准测试分数在统计上将是不可靠的。
这个问题没有简单而全面的解决方案。基准测试是一个代理指标,我们永远无法确定它是否真实反映了我们想要了解但无法直接衡量的内容。
但我们确实发现了 AI 基准测试存在的三个核心问题,这些问题是可以缓解的:
- 基准测试本质上是固定的:使用相同的任务和相同的文本。
- 基准测试是通用的:对实际场景的信息价值有限。
- 基准测试缺乏灵活性:无法应对多样化的使用场景。
AI 虽然会带来这样的问题,但有时也会提供解决方案。我们相信我们可以使用 AI 模型来解决这些问题,至少在 AI 基准测试方面。
tag使用 AI 来评估 AI:AIR-Bench
AIR-Bench 是开源的,基于 MIT 许可证。你可以在其 GitHub 仓库查看或下载代码。
 AIR-Bench
AIR-Benchtag它能做什么?
AIR-Bench 为 AI 基准测试带来了一些重要特性:
- 针对检索和 RAG 应用的专业化
这个基准测试面向实际的信息检索应用和检索增强生成管道。 - 领域和语言的灵活性
AIR 使得从特定领域数据或其他语言,甚至是你自己的特定任务数据创建基准测试变得更加容易。 - 自动化数据生成
AIR-Bench 生成测试数据,并且数据集会定期更新,降低数据泄漏的风险。
tag在 HuggingFace 上的 AIR-Bench 排行榜
我们运营着一个排行榜,类似于 MTEB 的排行榜,用于当前发布的 AIR-Bench 生成的任务。我们将定期重新生成基准测试,添加新的基准测试,并扩展对更多 AI 模型的覆盖范围。

tag它是如何工作的?
AIR 方法的核心洞察是我们可以使用大型语言模型(LLM)来生成新的文本和新的任务,这些内容不可能存在于任何训练集中。
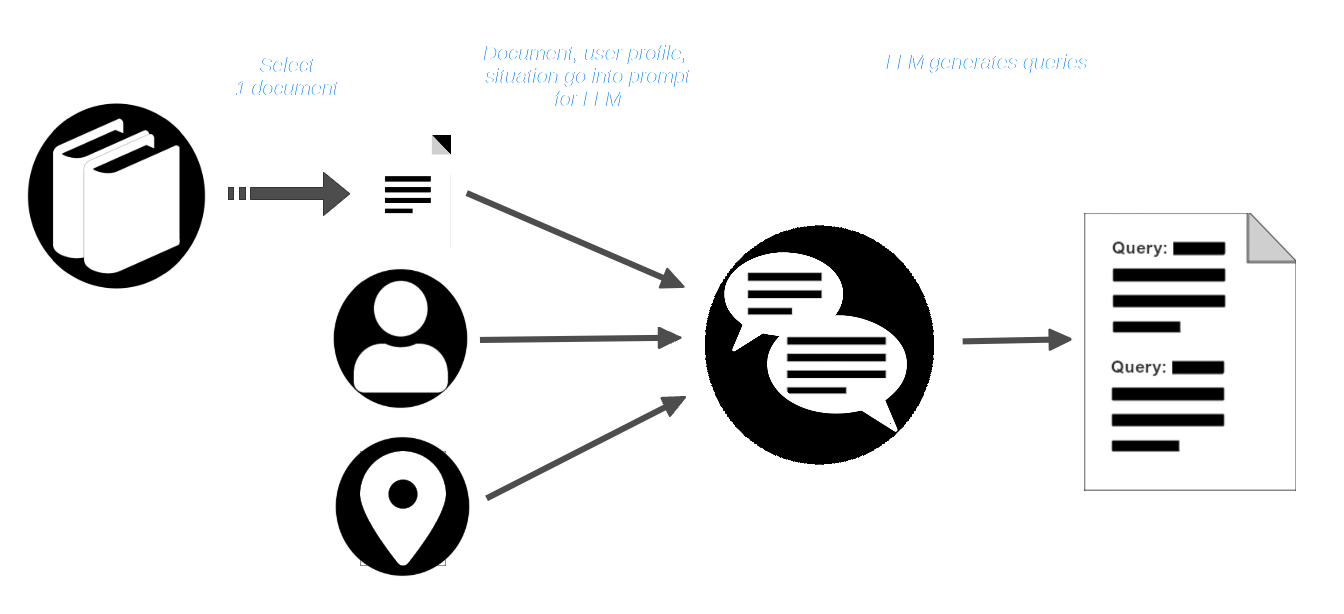
AIR-Bench 利用 LLM 的创造能力来模拟场景。用户选择一个文档集合——可能是某些模型训练数据的一部分的真实文档集合——然后设想一个具有特定角色的用户,以及他们需要使用该文档集合的情景。

然后,用户从语料库中选择一个文档,并将其与用户配置文件和情景描述一起传递给 LLM。LLM 会被提示创建适合该用户和情景的查询,这些查询应该能找到该文档。
AIR-Bench 管道接着会用文档和查询来提示 LLM,生成与提供的文档相似但不应该匹配查询的合成文档。
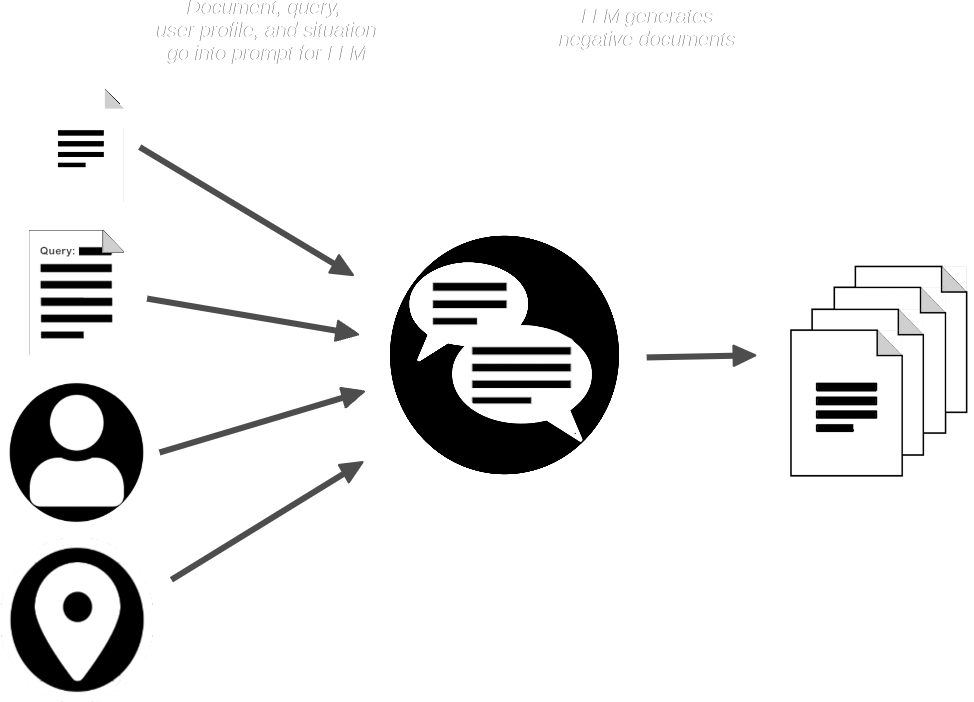
现在我们有了:
- 一组查询
- 每个查询对应的真实匹配文档
- 一小组预期不匹配的合成文档
AIR-Bench 将合成文档与真实文档集合合并,然后使用一个或多个 embedding 和 reranker 模型来验证查询是否应该能够检索到匹配的文档。它还使用 LLM 来验证每个查询是否与它应该检索的文档相关。
关于这个以 AI 为中心的生成和质量控制过程的更多细节,请阅读 GitHub 上 AIR-Bench 仓库中的数据生成文档。
AIR-Bench这为我们提供了一组高质量的查询-匹配对以及用于运行它们的半合成数据集。即使原始真实文档集确实构成了其训练的一部分,添加的合成文档和查询本身都是全新的、从未见过的数据,这是它之前无法学习到的。
tag特定领域基准测试和基于现实的测试
合成查询和文档不仅可以防止基准数据泄露到训练中,还在很大程度上解决了通用基准测试的问题。
通过向 LLM 提供选定的数据、用户画像和场景,AIR-Bench 可以非常轻松地为特定用例构建基准测试。此外,通过为特定类型的用户和使用场景构建查询,AIR-Bench 可以生成比传统基准测试更接近真实世界使用情况的测试查询。LLM 有限的创造力和想象力可能无法完全匹配实际场景,但它比使用研究人员可获得数据制作的静态测试数据集要更好。
作为这种灵活性的副产品,AIR-Bench 支持 GPT-4 支持的所有语言。
此外,AIR-Bench 专注于现实的基于 AI 的信息检索,这是嵌入模型最广泛的应用。它不为其他类型的任务(如聚类或分类)提供评分。
tagAIR-Bench 发行版
AIR-Bench 可以通过其 GitHub 仓库下载、使用和修改。
AIR-BenchAIR-Bench 支持两种基准测试:
- 基于评估与特定查询相关文档的正确检索的信息检索任务。
- 模拟检索增强生成管道中信息检索部分的"长文档"任务。
我们还预生成了一组基准测试,包括英文和中文,以及生成它们的脚本,作为如何使用 AIR-Bench 的实际示例。这些使用了一系列容易获得的数据。
例如,对于6,738,498 个英文维基百科页面的选集,我们生成了 1,727 个查询,匹配 4,260 个文档,以及额外的 7,882 个合成的不匹配但相似的文档。我们为八个英语数据集和六个中文数据集提供传统的信息检索基准测试。对于"长文档"任务,我们提供了十五个基准测试,全部为英文。
要查看完整列表和更多详细信息,请访问 GitHub 上 AIR-Bench 仓库中的可用任务页面。
AIR-Benchtag参与其中
AIR-Benchmark 被设计为 Search Foundations 社区的工具,以便参与的用户可以创建更适合其需求的基准测试。当您的测试能够反映您的使用场景时,它们也会为我们提供信息,这样我们就能构建更好地满足您需求的产品。
