


多模态搜索将文本和图像整合成无缝的搜索体验,在像 OpenAI 的 CLIP 这样的模型推动下获得了巨大发展。这些模型有效地弥合了视觉和文本数据之间的鸿沟,使我们能够将图像与相关文本相互连接。
虽然 CLIP 和类似模型功能强大,但它们也有明显的局限性,尤其是在处理较长文本或复杂文本关系时。这就是 jina-clip-v1 出场的时机。
jina-clip-v1 专门为解决这些挑战而设计,它在保持强大的文本-图像匹配能力的同时,提供了更好的文本理解能力。它为使用两种模态的应用提供了更简化的解决方案,简化了搜索过程,无需在文本和图像之间来回切换不同的模型。
在这篇文章中,我们将探讨 jina-clip-v1 为多模态搜索应用带来的优势,通过实验展示它如何通过集成的文本和图像嵌入来提高结果的准确性和多样性。
tag什么是 CLIP?
CLIP(对比语言-图像预训练)是由 OpenAI 开发的一种 AI 模型架构,通过学习联合表示来连接文本和图像。CLIP 本质上是一个文本模型和一个图像模型的组合——它将两种类型的输入转换到同一个嵌入空间中,使相似的文本和图像位置相近。CLIP 在海量的图像-文本对数据集上进行训练,使其能够理解视觉和文本内容之间的关系。这使它能够很好地适应不同的领域,在零样本学习场景(如生成图像描述或图像检索)中表现出色。
自 CLIP 发布以来,像 SigLiP、LiT 和 EvaCLIP 这样的模型在其基础上进行了扩展,增强了训练效率、扩展性和多模态理解等方面。这些模型通常利用更大的数据集、改进的架构和更复杂的训练技术来突破文本-图像对齐的边界,进一步推动了图像-语言模型领域的发展。
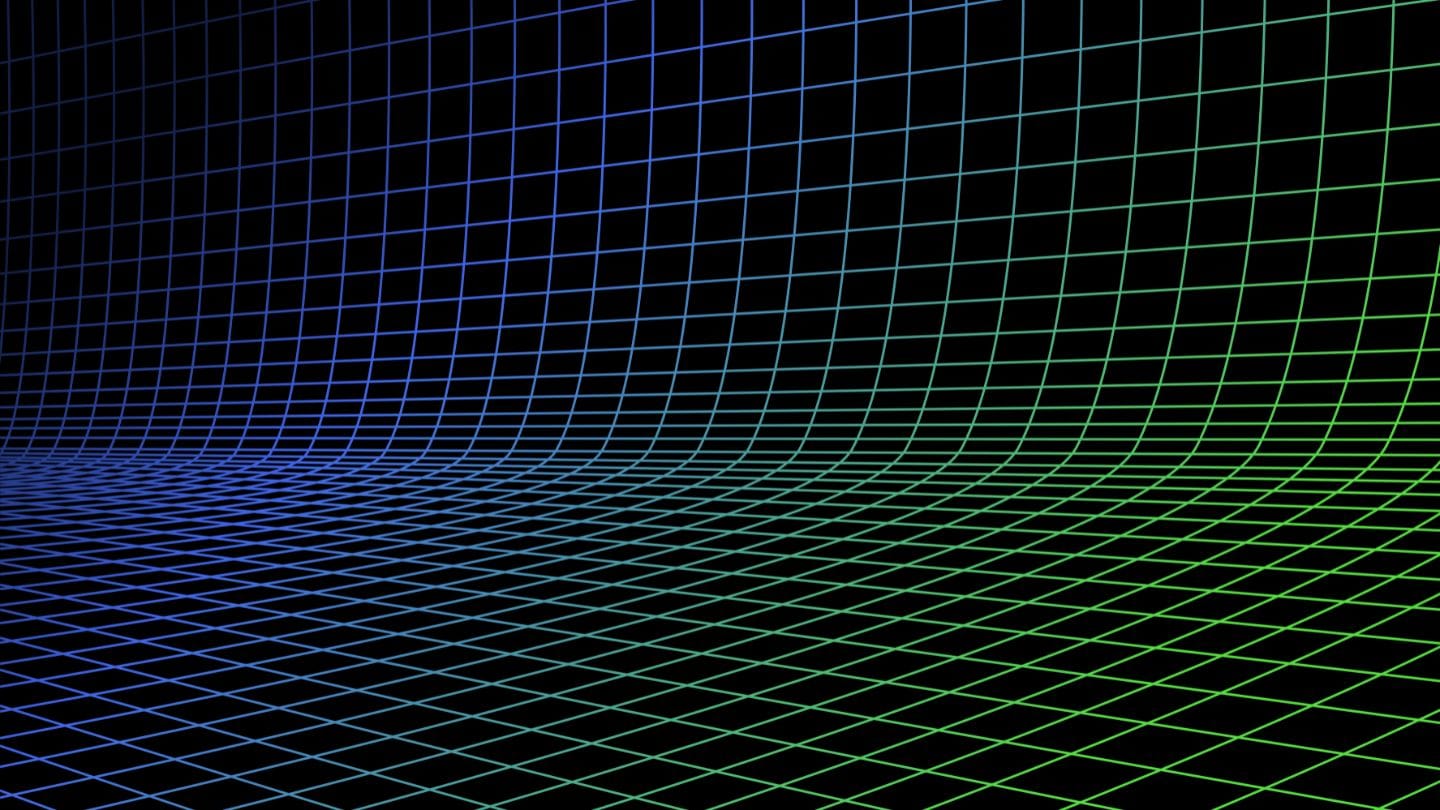
虽然 CLIP 可以单独处理文本,但它有明显的局限性。首先,它只在短文本描述上训练,不能处理长文本,最多只能处理约 77 个单词。其次,CLIP 擅长连接文本和图像,但在比较文本与文本时表现欠佳,比如难以识别 a crimson fruit 和 a red apple 这样的字符串可能指代相同的事物。这正是像 jina-embeddings-v3 这样的专门文本模型发挥作用的地方。
这些局限性使涉及文本和图像的搜索任务变得复杂,例如,在一个用户可以使用文本字符串或图像搜索时装产品的"购物造型"在线商店中。在为产品建立索引时,你需要多次处理每个产品——一次处理图像,一次处理文本,再用一个专门的文本模型处理一次。同样,当用户搜索产品时,你的系统需要至少搜索两次才能找到文本和图像目标:
如何使用 jina-clip-v1 解决 CLIP 的缺陷
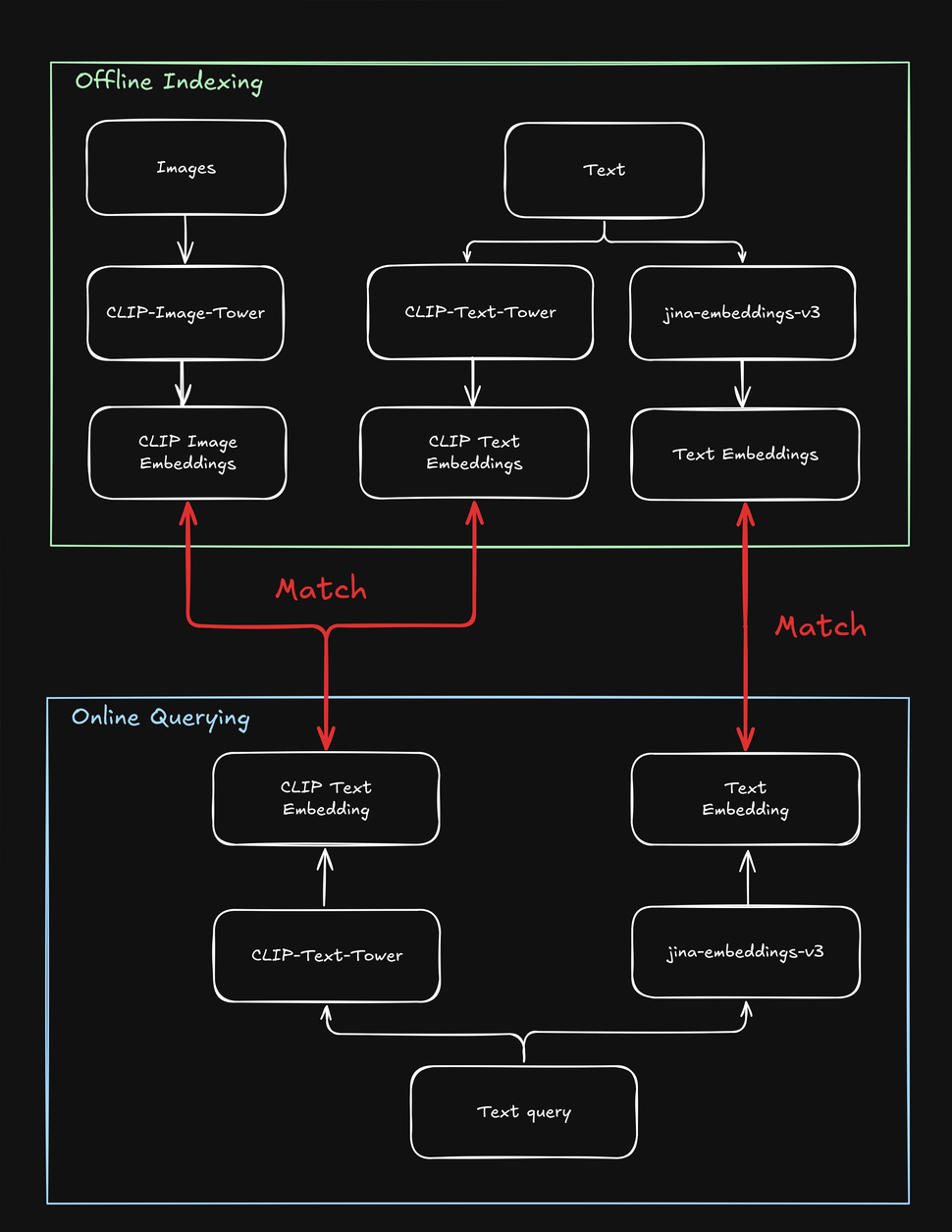
为了克服 CLIP 的局限性,我们创建了 jina-clip-v1,使其能够理解更长的文本,并更有效地将文本查询与文本和图像匹配。是什么让 jina-clip-v1 如此特别?首先,它使用了更智能的文本理解模型(JinaBERT),帮助它理解更长、更复杂的文本(如产品描述),而不仅仅是短标题(如产品名称)。其次,我们训练 jina-clip-v1 同时擅长两件事:既能匹配文本和图像,又能匹配文本和其他文本。
而 OpenAI CLIP 则不然:无论是建立索引还是查询,你都需要调用两个模型(CLIP 用于图像和短文本如标题,另一个文本嵌入模型用于较长的文本如描述)。这不仅增加了开销,还会降低搜索速度,而搜索本应是一个非常快速的操作。jina-clip-v1 用一个模型就完成了所有这些工作,而且不会牺牲速度:

这种统一的方法开启了早期模型难以实现的新可能性,有潜力重塑我们对搜索的方法。在这篇文章中,我们进行了两个实验:
- 通过结合文本和图像搜索来改进搜索结果:我们能否将 jina-clip-v1 对文本的理解与对图像的理解结合起来?当我们混合这两种类型的理解时会发生什么?添加视觉信息会改变我们的搜索结果吗?简而言之,同时使用文本和图像搜索能否获得更好的结果?
- 使用图像来使搜索结果多样化:大多数搜索引擎都在最大化文本匹配。但我们能否使用 jina-clip-v1 的图像理解作为"视觉洗牌"?与其仅显示最相关的结果,我们可以包含视觉上多样化的结果。这不是为了找到更多相关结果——而是为了展示更广泛的视角,即使它们的相关性较低。通过这种方式,我们可能会发现之前没有考虑到的主题方面。例如,在时尚搜索的背景下,如果用户搜索"彩色鸡尾酒裙",他们是希望看到所有相似的结果(即非常接近的匹配),还是通过视觉洗牌看到更多样化的选择?
这两种方法在各种用例中都很有价值,特别是在用户可能使用文本或图像进行搜索的场景中,如电子商务、媒体、艺术设计、医学影像等领域。
平均文本和图像嵌入以获得超出平均水平的性能
当用户提交查询(通常是文本字符串)时,我们可以使用 jina-clip-v1 的文本塔将查询编码为文本嵌入。jina-clip-v1 的优势在于它能够通过在同一语义空间中对齐文本到文本和文本到图像的信号来理解文本和图像。
如果我们通过平均预先索引的文本和图像嵌入来组合每个产品的表示,是否能改进检索结果?
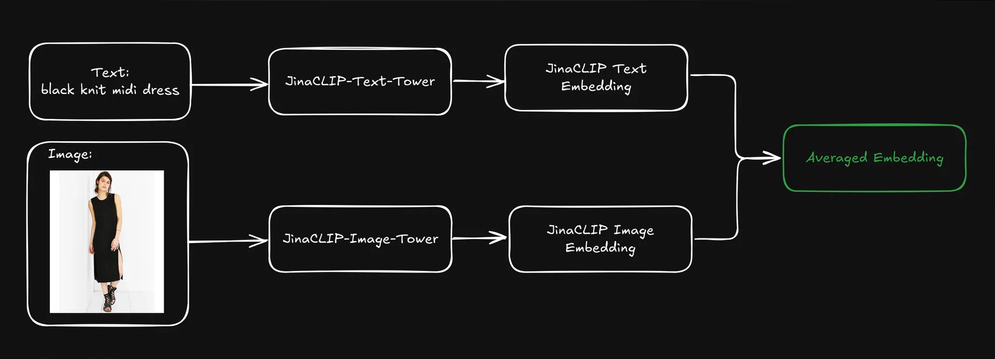
这创建了一个包含文本信息(如产品描述)和视觉信息(如产品图片)的单一表示。然后我们可以使用文本查询嵌入来搜索这些混合表示。这对我们的搜索结果有什么影响?
为了找到答案,我们使用了 Fashion200k 数据集,这是一个专门为时尚图像检索和跨模态理解任务创建的大规模数据集。它包含超过 200,000 张时尚商品图片,包括服装、鞋子和配饰,以及相应的产品描述和元数据。
 xthan
xthan我们进一步将每个商品分类为一个广泛类别(例如,dress)和一个细粒度类别(如 knit midi dress)。
分析三种检索方法
为了了解对文本和图像嵌入进行平均是否会产生更好的检索结果,我们用三种类型的搜索进行了实验,每种搜索都使用文本字符串(例如 red dress)作为查询:
- 使用文本嵌入的查询到描述:基于文本嵌入搜索产品描述。
- 使用跨模态搜索的查询到图像:基于图像嵌入搜索产品图片。
- 查询到平均嵌入:搜索产品描述和产品图片的平均嵌入。
我们首先对整个数据集建立索引,然后随机生成 1,000 个查询来评估性能。我们将每个查询编码为文本嵌入,并根据上述方法分别进行匹配。我们通过返回产品的类别与输入查询的匹配程度来衡量准确性。
当我们使用查询 multicolor henley t-shirt dress 时,查询到描述搜索获得了最高的 top-5 准确率,但排名前三的连衣裙在视觉上是相同的。这并不理想,因为有效的搜索应该在相关性和多样性之间取得平衡,以更好地吸引用户的注意力。

查询到图像的跨模态搜索使用相同的查询并采取相反的方法,呈现了高度多样化的连衣裙集合。虽然它在五个结果中有两个匹配了正确的大类别,但没有一个匹配细粒度类别。

平均文本和图像嵌入搜索产生了最好的结果:五个结果全部匹配大类别,其中两个匹配了细粒度类别。此外,视觉重复的项目被消除,提供了更多样化的选择。使用文本嵌入来搜索平均的文本和图像嵌入似乎在保持搜索质量的同时融入了视觉线索,导致更多样化和全面的结果。

扩大规模:使用更多查询进行评估
为了看看这在更大规模上是否有效,我们继续对更多的大类别和细粒度类别进行实验。我们进行了多次迭代,每次检索不同数量的结果("k 值")。
在大类别和细粒度类别中,查询到平均嵌入在所有 k 值(10、20、50、100)上始终达到最高的准确率。这表明,无论类别是宽泛还是具体,结合文本和图像嵌入都能提供最准确的相关项目检索结果:

| k | Search Type | Broad Category Precision (cosine similarity) | Fine-grained Category Precision (cosine similarity) |
|---|---|---|---|
| 10 | Query to Description | 0.9026 | 0.2314 |
| 10 | Query to Image | 0.7614 | 0.2037 |
| 10 | Query to Avg Embedding | 0.9230 | 0.2711 |
| 20 | Query to Description | 0.9150 | 0.2316 |
| 20 | Query to Image | 0.7523 | 0.1964 |
| 20 | Query to Avg Embedding | 0.9229 | 0.2631 |
| 50 | Query to Description | 0.9134 | 0.2254 |
| 50 | Query to Image | 0.7418 | 0.1750 |
| 50 | Query to Avg Embedding | 0.9226 | 0.2390 |
| 100 | Query to Description | 0.9092 | 0.2139 |
| 100 | Query to Image | 0.7258 | 0.1675 |
| 100 | Query to Avg Embedding | 0.9150 | 0.2286 |
- 使用文本嵌入的查询到描述在两个类别中都表现良好,但略落后于平均嵌入方法。这表明仅文本描述就能提供有价值的信息,特别是对于像"连衣裙"这样的更宽泛的类别,但可能缺乏精确细粒度分类所需的细微差别(例如区分不同类型的连衣裙)。
- 使用跨模态搜索的查询到图像在两个类别中的准确率始终最低。这表明虽然视觉特征可以帮助识别大类别,但在捕捉特定时尚商品的细粒度区别方面效果较差。仅从视觉特征区分细粒度类别的挑战尤其明显,因为视觉差异可能很微妙,需要文本提供的额外上下文。
- 总的来说,结合文本和视觉信息(通过平均嵌入)在宽泛和细粒度时尚检索任务中都达到了高准确率。文本描述发挥着重要作用,特别是在识别大类别方面,而单独使用图像在两种情况下都效果较差。
总体而言,大类别的准确率比细粒度类别高得多,主要是因为数据集中大类别项目(如 dress)的表示比细粒度类别(如 henley dress)更多,这很自然,因为后者是前者的子集。从本质上讲,大类别比细粒度类别更容易概括。在时尚例子之外,识别某物总体上是一只鸟很简单。但要识别它是一只 火烈鸟乐园极乐鸟就难得多。
另一个需要注意的是,文本查询中的信息更容易与其他文本(如产品名称或描述)匹配,而不是视觉特征。因此,如果使用文本作为输入,文本比图像更可能成为输出。通过在索引中结合图像和文本(通过平均嵌入),我们获得了最佳结果。
使用文本检索结果;用图像使其多样化
在上一节中,我们触及了搜索结果视觉重复的问题。在搜索中,单靠准确率并不总是足够的。在许多情况下,维护一个简洁但高度相关和多样化的排序列表更有效,特别是当用户的查询模糊时(例如,如果用户搜索 black jacket — 他们是指黑色机车夹克、飞行夹克、西装外套还是其他类型?)。
现在,我们不使用 jina-clip-v1 的跨模态能力,而是使用其文本模型塔的文本嵌入进行初始文本搜索,然后应用图像模型塔的图像嵌入作为"视觉重排序器"来使搜索结果多样化。下图说明了这一点:
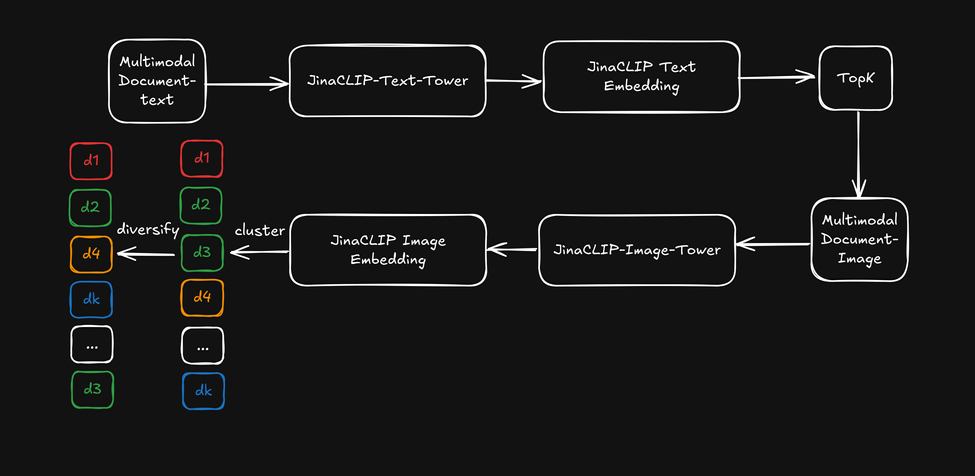
- 首先,基于文本嵌入检索 top-k 搜索结果。
- 对于每个靠前的搜索结果,提取视觉特征并使用图像嵌入进行聚类。
- 通过从每个聚类中选择一个项目来重新排序搜索结果,并向用户呈现多样化的列表。
在检索前五十个结果后,我们对图像嵌入应用了轻量级的 k-means 聚类(k=5),然后从每个聚类中选择项目。由于我们使用查询到产品类别作为衡量指标,类别精确度与查询到描述的性能保持一致。然而,通过基于图像的多样化,排序结果开始覆盖更多不同的方面(如面料、剪裁和图案)。以下是之前多色亨利 T 恤连衣裙的示例:

现在让我们看看使用文本嵌入搜索结合图像嵌入作为多样化重排序器如何影响搜索结果:

排序结果源自基于文本的搜索,但在前五个示例中开始涵盖更多不同的"方面"。这实现了类似于平均嵌入的效果,而无需实际进行平均。
然而,这确实需要付出代价:我们必须在检索 top-k 结果后应用额外的聚类步骤,这会增加几毫秒的时间,具体取决于初始排名的大小。此外,确定 k-means 聚类的 k 值需要一些启发式猜测。这就是我们为改善结果多样化所付出的代价!
结论
jina-clip-v1 通过在单个高效模型中统一两种模态,有效地弥合了文本和图像搜索之间的差距。我们的实验表明,与传统的 CLIP 模型相比,它处理更长、更复杂的文本输入和图像的能力可以提供更优越的搜索性能。
我们的测试涵盖了各种方法,包括将文本与描述、图像和平均嵌入进行匹配。结果一致表明,结合文本和图像嵌入产生了最佳效果,提高了准确性和搜索结果的多样性。我们还发现,使用图像嵌入作为"视觉重排序器"可以在保持相关性的同时增强结果的多样性。
这些进展对用户使用文本描述和图像进行搜索的实际应用具有重要意义。通过同时理解这两种类型的数据,jina-clip-v1 简化了搜索流程,提供更相关的结果,并实现更多样化的产品推荐。这种统一的搜索功能不仅限于电子商务,还可以惠及媒体资产管理、数字图书馆和视觉内容策划,使跨不同格式发现相关内容变得更加容易。
虽然 jina-clip-v1 目前仅支持英语,但我们正在开发 jina-clip-v2。继承 jina-embeddings-v3 和 jina-colbert-v2 的脚步,这个新版本将是支持 89 种语言的最先进多语言多模态检索器。这一升级将为跨不同市场和行业的搜索和检索任务开启新的可能性,使其成为电子商务、媒体等全球应用中更强大的嵌入模型。





