

嵌入(Embeddings)已成为各种人工智能和自然语言处理应用的基石,它提供了一种将文本含义表示为高维向量的方法。然而,随着模型规模的增大和 AI 模型处理数据量的增加,传统嵌入的计算和存储需求也在不断攀升。二进制嵌入作为一种紧凑、高效的替代方案被引入,在大幅减少资源需求的同时仍能保持高性能。
二进制嵌入是一种降低这些资源需求的方法,它可以将嵌入向量的大小减少高达 96%(在 Jina Embeddings 的情况下为 96.875%)。用户可以在其 AI 应用中利用紧凑的二进制嵌入的优势,同时准确性损失最小。
tag什么是二进制嵌入?
二进制嵌入是一种特殊的数据表示形式,它将传统的高维浮点向量转换为二进制向量。这不仅压缩了嵌入,而且还保留了向量几乎所有的完整性和实用性。这种技术的精髓在于即使在转换后也能保持数据点之间的语义和关系距离。
二进制嵌入背后的魔力在于量化,这是一种将高精度数字转换为低精度数字的方法。在 AI 建模中,这通常意味着将嵌入中的 32 位浮点数转换为更少位数的表示形式,比如 8 位整数。

二进制嵌入将这一过程推向极致,将每个值降为 0 或 1。将 32 位浮点数转换为二进制数字可以将嵌入向量的大小减少 32 倍,减少了 96.875%。由此产生的嵌入向量运算速度也大大提高。在某些微芯片上使用硬件加速可以使向量比较的速度提高远超 32 倍。
在这个过程中不可避免会损失一些信息,但当模型性能很好时,这种损失会被最小化。如果不同事物的非量化嵌入差异最大,那么二值化更有可能很好地保持这种差异。否则,正确解释嵌入可能会变得困难。
Jina Embeddings 模型经过专门训练,在这方面非常稳健,使其非常适合二值化。
这种紧凑的嵌入使新的 AI 应用成为可能,特别是在资源受限的场景中,如移动设备和对时间敏感的使用场景。
如下图所示,这些成本和计算时间的优势仅带来相对较小的性能损失。

对于 jina-embeddings-v2-base-en,二进制量化将检索准确率从 47.13% 降低到 42.05%,损失约 10%。对于 jina-embeddings-v2-base-de,这种损失仅为 4%,从 44.39% 降低到 42.65%。
Jina Embeddings 模型在生成二进制向量时表现如此出色,是因为它们经过训练可以创建更均匀的嵌入分布。这意味着与其他模型的嵌入相比,两个不同的嵌入在更多维度上的距离可能更远。这一特性确保了这些距离能更好地通过二进制形式表示。
tag二进制嵌入是如何工作的?
让我们看看它是如何工作的,考虑三个嵌入:A、B 和 C。这三个都是完整的浮点向量,而不是二值化的向量。现在,假设从 A 到 B 的距离大于从 B 到 C 的距离。对于嵌入,我们通常使用余弦距离,所以:
如果我们对 A、B 和 C 进行二值化,我们可以使用汉明距离更有效地测量距离。
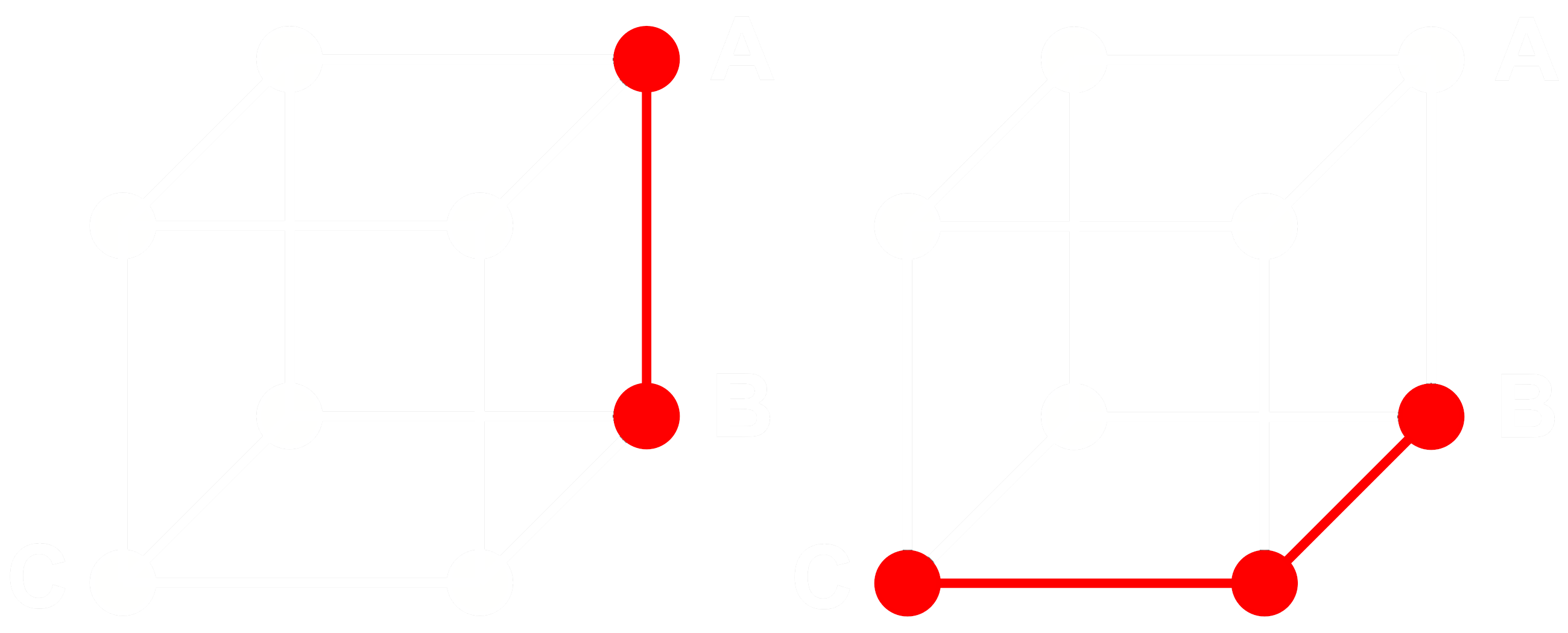
让我们将 A、B 和 C 的二值化版本分别称为 Abin、Bbin 和 Cbin。
对于二进制向量,如果 Abin 和 Bbin 之间的余弦距离大于 Bbin 和 Cbin 之间的距离,那么 Abin 和 Bbin 之间的汉明距离大于或等于 Bbin 和 Cbin 之间的汉明距离。
所以如果:
那么对于汉明距离:
理想情况下,当我们对嵌入进行二值化时,我们希望完整嵌入的相同关系在二进制嵌入中也成立。这意味着如果一个距离在浮点余弦中大于另一个距离,那么它们二值化等价的汉明距离也应该更大:
我们不能使这对所有嵌入三元组都成立,但我们可以使它对几乎所有的三元组都成立。
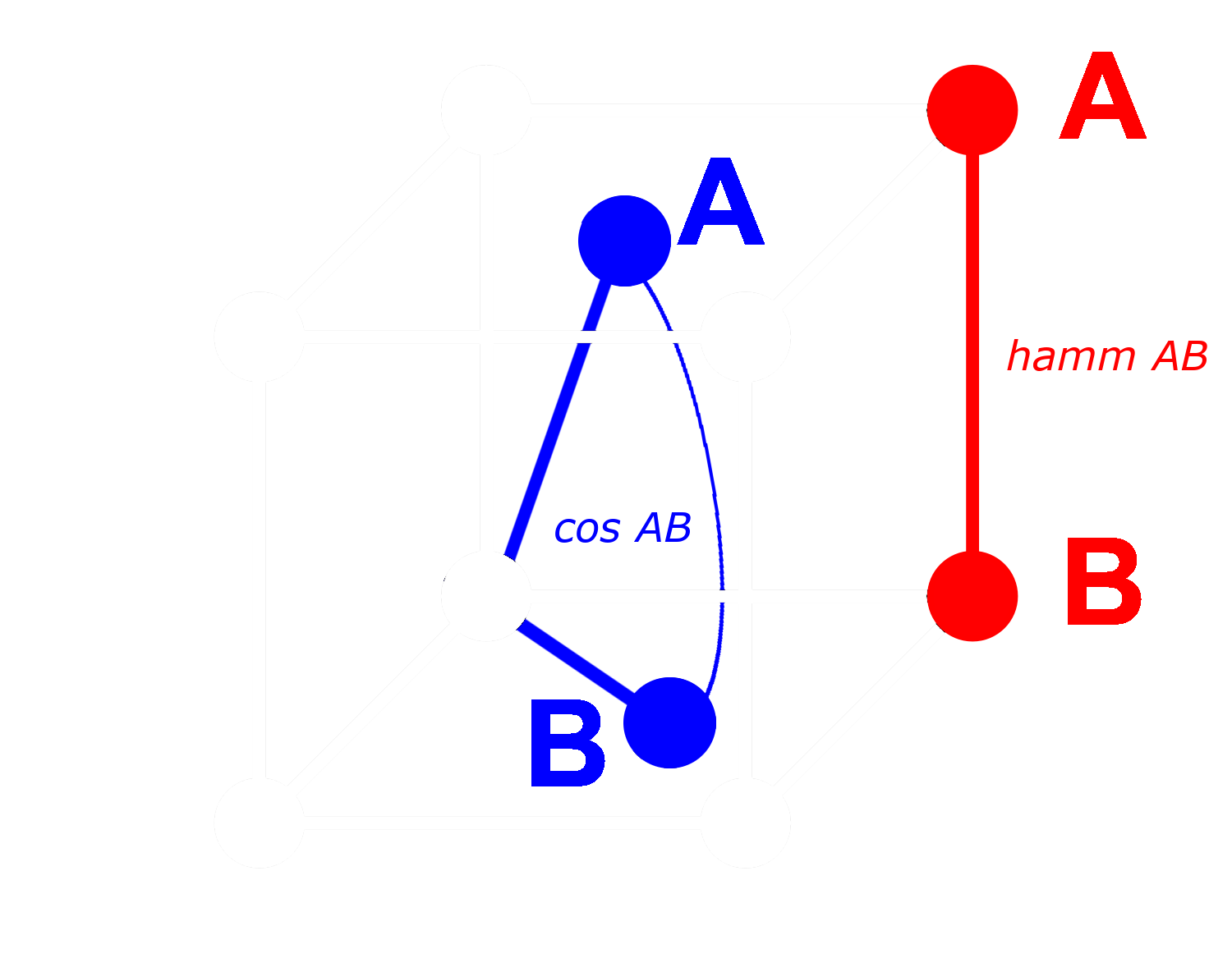
对于二进制向量,我们可以将每个维度视为存在(1)或不存在(0)。两个向量在非二进制形式中的距离越远,在任何一个维度上,一个具有正值而另一个具有负值的概率就越高。这意味着在二进制形式中,很可能会有更多的维度其中一个为零而另一个为一。这使它们在汉明距离上更远。
相反的情况适用于更接近的向量:非二进制向量越接近,在任何维度上两者都为零或都为一的概率就越高。这使它们在汉明距离上更近。
Jina Embeddings 模型之所以特别适合二值化,是因为我们使用负例挖掘和其他微调实践来训练它们,特别是增加不相似事物之间的距离并减少相似事物之间的距离。这使得嵌入更加稳健,对相似性和差异性更敏感,并使二进制嵌入之间的汉明距离与非二进制嵌入之间的余弦距离更加成比例。
tag使用 Jina AI 的二进制嵌入可以节省多少?
采用 Jina AI 的二进制嵌入模型不仅可以降低时间敏感应用中的延迟,还能带来显著的成本效益,如下表所示:
| 模型 | 2.5 亿个 嵌入的内存 |
检索基准 平均值 |
AWS 估计价格 (使用 x2gb 实例, 每 GB/月 $3.8) |
|---|---|---|---|
| 32 位浮点嵌入 | 715 GB | 47.13 | $35,021 |
| 二进制嵌入 | 22.3 GB | 42.05 | $1,095 |
这种 95% 以上的节省仅伴随着约 10% 的检索精度降低。
相比使用 OpenAI 的 Ada 2 模型或 Cohere 的 Embed v3 产生的二值化向量,这种节省更为显著,这两个模型产生的输出嵌入维度都在 1024 或更高。Jina AI 的嵌入仅有 768 维,即使在量化之前也比其他模型更小,但仍保持着相当的精度。
这些节省也体现在环境方面,使用更少的稀有材料和能源。
tag开始使用
要使用 Jina Embeddings API 获取二值嵌入,只需在你的 API 调用中添加 encoding_type 参数,将值设为 binary 可获取编码为有符号整数的二值化嵌入,或设为 ubinary 获取无符号整数。
tag直接访问 Jina Embedding API
使用 curl:
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR API KEY>" \
-d '{
"input": ["Your text string goes here", "You can send multiple texts"],
"model": "jina-embeddings-v2-base-en",
"encoding_type": "binary"
}'
或通过 Python requests API:
import requests
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <YOUR API KEY>"
}
data = {
"input": ["Your text string goes here", "You can send multiple texts"],
"model": "jina-embeddings-v2-base-en",
"encoding_type": "binary",
}
response = requests.post(
"https://api.jina.ai/v1/embeddings",
headers=headers,
json=data,
)
通过上述 Python request,检查 response.json() 将得到以下响应:
{
"model": "jina-embeddings-v2-base-en",
"object": "list",
"usage": {
"total_tokens": 14,
"prompt_tokens": 14
},
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.14528547,
-1.0152762,
...
]
},
{
"object": "embedding",
"index": 1,
"embedding": [
-0.109809875,
-0.76077706,
...
]
}
]
}
这是两个以 96 个 8 位有符号整数存储的二值嵌入向量。要将它们解包成 768 个 0 和 1,你需要使用 numpy 库:
import numpy as np
# assign the first vector to embedding0
embedding0 = response.json()['data'][0]['embedding']
# convert embedding0 to a numpy array of unsigned 8-bit ints
uint8_embedding = np.array(embedding0).astype(numpy.uint8)
# unpack to binary
np.unpackbits(uint8_embedding)
结果是一个只包含 0 和 1 的 768 维向量:
array([0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0,
0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 1, 0, 1,
0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 1,
0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1,
1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0,
0, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0,
1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1,
1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1,
1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1,
0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1,
1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0,
1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1,
0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1,
1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0,
0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1,
1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1,
1, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1,
0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 0,
1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0,
0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0,
0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1,
0, 1, 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0,
0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0,
1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 0,
0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0,
0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 1,
1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0,
1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0,
1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1,
1, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0,
1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1,
1, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0,
1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1,
0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0],
dtype=uint8)
tag在 Qdrant 中使用二值量化
你也可以使用 Qdrant 的集成库将二值嵌入直接存入你的 Qdrant 向量存储。由于 Qdrant 内部已实现了 BinaryQuantization,你可以将其作为整个向量集合的预设配置,使其在不改变代码的情况下就能检索和存储二值向量。
具体示例代码如下:
import qdrant_client
import requests
from qdrant_client.models import Distance, VectorParams, Batch, BinaryQuantization, BinaryQuantizationConfig
# Provide Jina API key and choose one of the available models.
# You can get a free trial key here: https://jina.ai/embeddings/
JINA_API_KEY = "jina_xxx"
MODEL = "jina-embeddings-v2-base-en" # or "jina-embeddings-v2-base-en"
EMBEDDING_SIZE = 768 # 512 for small variant
# Get embeddings from the API
url = "https://api.jina.ai/v1/embeddings"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {JINA_API_KEY}",
}
text_to_encode = ["Your text string goes here", "You can send multiple texts"]
data = {
"input": text_to_encode,
"model": MODEL,
}
response = requests.post(url, headers=headers, json=data)
embeddings = [d["embedding"] for d in response.json()["data"]]
# Index the embeddings into Qdrant
client = qdrant_client.QdrantClient(":memory:")
client.create_collection(
collection_name="MyCollection",
vectors_config=VectorParams(size=EMBEDDING_SIZE, distance=Distance.DOT, on_disk=True),
quantization_config=BinaryQuantization(binary=BinaryQuantizationConfig(always_ram=True)),
)
client.upload_collection(
collection_name="MyCollection",
ids=list(range(len(embeddings))),
vectors=embeddings,
payload=[
{"text": x} for x in text_to_encode
],
)要配置搜索,你应该使用 oversampling 和 rescore 参数:
from qdrant_client.models import SearchParams, QuantizationSearchParams
results = client.search(
collection_name="MyCollection",
query_vector=embeddings[0],
search_params=SearchParams(
quantization=QuantizationSearchParams(
ignore=False,
rescore=True,
oversampling=2.0,
)
)
)tag使用 LlamaIndex
要在 LlamaIndex 中使用 Jina 二进制嵌入,在实例化 JinaEmbedding 对象时将 encoding_queries 参数设置为 binary:
from llama_index.embeddings.jinaai import JinaEmbedding
# You can get a free trial key from https://jina.ai/embeddings/
JINA_API_KEY = "<YOUR API KEY>"
jina_embedding_model = JinaEmbedding(
api_key=jina_ai_api_key,
model="jina-embeddings-v2-base-en",
encoding_queries='binary',
encoding_documents='float'
)
jina_embedding_model.get_query_embedding('Query text here')
jina_embedding_model.get_text_embedding_batch(['X', 'Y', 'Z'])
tag支持二进制嵌入的其他向量数据库
以下向量数据库原生支持二进制向量:
tag示例
为了展示二进制嵌入的实际应用,我们从 arXiv.org 选取了一些摘要,并使用 jina-embeddings-v2-base-en 获取了它们的 32 位浮点和二进制向量。然后我们将它们与示例查询"3D segmentation"的嵌入进行了比较。
从下表可以看出,前三个答案是相同的,前五个中有四个匹配。使用二进制向量产生了几乎相同的顶部匹配结果。
| Binary | 32-bit Float | |||
|---|---|---|---|---|
| Rank | Hamming dist. |
Matching Text | Cosine | Matching text |
| 1 | 0.1862 | SEGMENT3D: A Web-based Application for Collaboration... |
0.2340 | SEGMENT3D: A Web-based Application for Collaboration... |
| 2 | 0.2148 | Segmentation-by-Detection: A Cascade Network for... |
0.2857 | Segmentation-by-Detection: A Cascade Network for... |
| 3 | 0.2174 | Vox2Vox: 3D-GAN for Brain Tumour Segmentation... |
0.2973 | Vox2Vox: 3D-GAN for Brain Tumour Segmentation... |
| 4 | 0.2318 | DiNTS: Differentiable Neural Network Topology Search... |
0.2983 | Anisotropic Mesh Adaptation for Image Segmentation... |
| 5 | 0.2331 | Data-Driven Segmentation of Post-mortem Iris Image... |
0.3019 | DiNTS: Differentiable Neural Network Topology... |






