




在多语言模型中,一个关键的挑战是"语言差距"——一种不同语言中具有相同含义的短语之间没有得到理想的紧密对齐或聚类的现象。理想情况下,一种语言的文本及其在另一种语言中的对应文本应具有相似的表示——即非常接近的 embeddings——从而使跨语言应用程序能够以相同的方式处理不同语言的文本。然而,模型往往会微妙地体现文本的语言特征,从而产生导致跨语言性能不理想的"语言差距"。
在本文中,我们将探讨这种语言差距以及它如何影响文本 embedding 模型的性能。我们使用 jina-xlm-roberta 模型和最新的 jina-embeddings-v3 进行了实验,评估了同一语言中的释义以及不同语言对之间的翻译的语义对齐情况。这些实验揭示了在不同训练条件下,具有相似或相同含义的短语如何聚集在一起。

我们还尝试了改进跨语言语义对齐的训练技术,特别是在对比学习过程中引入并行多语言数据。在本文中,我们将分享我们的见解和结果。
tag多语言模型训练既创造又减少语言差距
文本 embedding 模型的训练通常涉及两个主要部分的多阶段过程:
- 掩码语言建模(MLM):预训练通常涉及大量文本,其中一些 token 被随机掩码。模型被训练来预测这些被掩码的 token。这个过程教会模型训练数据中的语言模式,包括可能源自语法、词汇语义和语用现实世界约束的 token 之间的选择依赖关系。
- 对比学习:预训练之后,模型使用精心策划或半策划的数据进行进一步训练,以使语义相似的文本的 embeddings 更加接近,并(可选)将不相似的文本推得更远。这种训练可以使用已知或至少可靠估计其语义相似性的文本对、三元组甚至组。它可能有几个子阶段,这部分过程有多种训练策略,新的研究经常发表,目前尚未就最佳方法达成明确共识。
要理解语言差距是如何产生的以及如何消除它,我们需要了解这两个阶段的作用。
tag掩码语言预训练
文本 embedding 模型的一些跨语言能力是在预训练期间获得的。
同源词和借用词使模型能够从大量文本数据中学习一些跨语言语义对齐。例如,英语单词 banana 和法语单词 banane(以及德语 Banane)在拼写上足够相似且使用频繁,使得 embedding 模型可以学习到跨语言中类似"banan-"的词具有相似的分布模式。它可以利用这些信息在一定程度上学习到其他在不同语言中看起来不同的词也具有相似的含义,甚至可以理解一些语法结构是如何翻译的。
然而,这种学习是在没有明确训练的情况下发生的。
我们测试了 jina-xlm-roberta 模型(jina-embeddings-v3 的预训练主干网络),看它如何从掩码语言预训练中学习跨语言等价性。我们绘制了一组英语句子翻译成德语、荷兰语、简体中文和日语的二维 UMAP 句子表示。结果如下图所示:
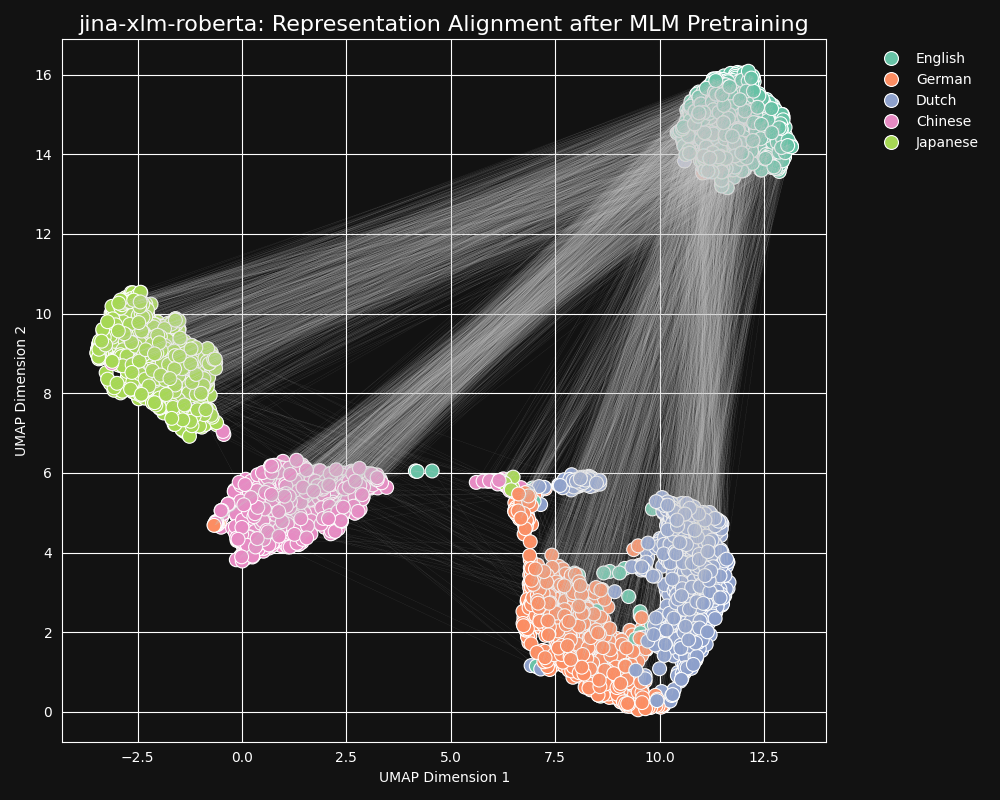
这些句子在
jina-xlm-roberta embedding 空间中强烈倾向于形成特定语言的聚类,尽管在这个投影中可以看到一些离群点,这可能是二维投影的副作用。可以看到,预训练已经将同一语言的句子的 embeddings 聚类得非常紧密。这是一个将高维空间的分布投影到二维空间的结果,所以仍然可能存在,例如,一个德语句子虽然是一个英语句子的好翻译,它的 embedding 可能仍然是最接近其英语源句的 embedding 的德语句子。但它确实表明,一个英语句子的 embedding 可能比起语义完全相同或几乎相同的德语句子,更接近另一个英语句子。
还要注意德语和荷兰语形成的聚类比其他语言对更接近。对于两种相对密切相关的语言来说,这并不令人惊讶。德语和荷兰语足够相似,以至于它们有时可以部分互通。
日语和中文也似乎比其他语言更接近。虽然它们的关系不同,但书面日语通常使用汉字(漢字),即中文的汉字。日语与中文共享大部分这些书写字符,两种语言都有许多使用一个或多个汉字写成的共同词汇。从 MLM 的角度来看,这与荷兰语和德语之间的可见相似性是一样的。
我们可以通过只看两种语言各两个句子的方式更简单地看到这种"语言差距":

由于 MLM 自然地按语言聚类文本,"my dog is blue" 和 "my cat is red" 被聚在一起,远离它们的德语对应句。与之前博文中讨论的"模态差距"不同,我们认为这源于语言之间的表面相似性和差异性:相似的拼写、印刷中相同字符序列的使用,以及可能存在的形态和句法结构的相似性——常见的词序和构词方式。
简而言之,无论模型在 MLM 预训练中学习跨语言等价性的程度如何,这都不足以克服按语言聚类的强烈倾向。这留下了一个很大的语言差距。
tag对比学习
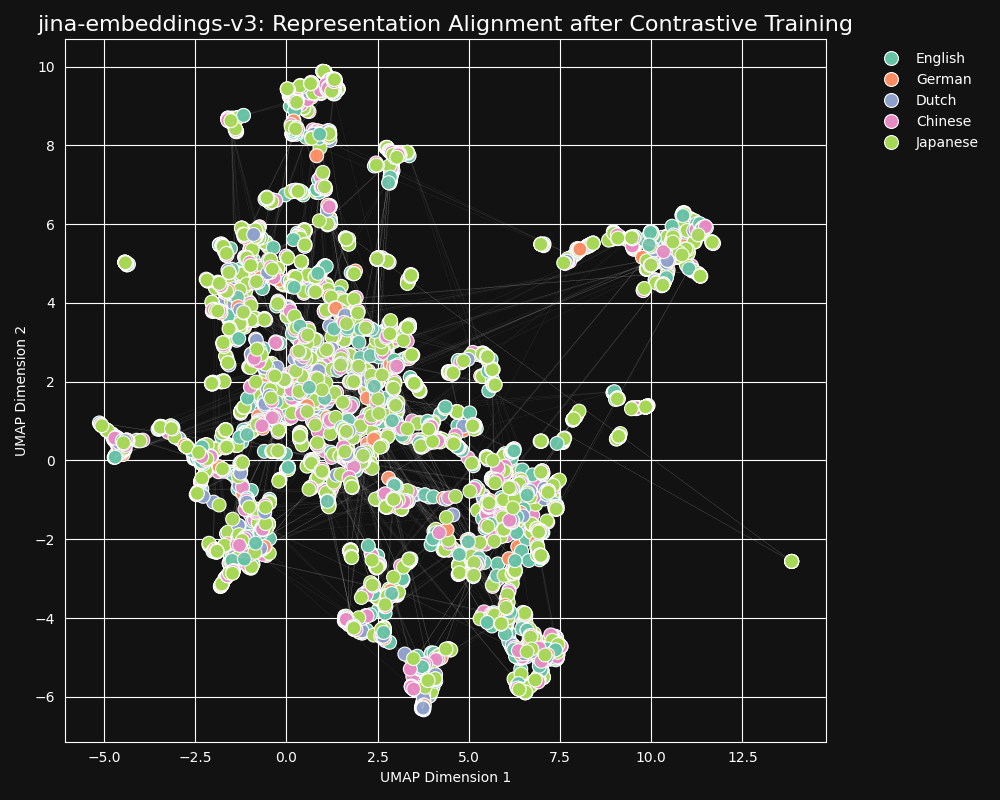
理想情况下,我们希望 embedding 模型对语言无感,在其 embeddings 中只编码一般含义。在这样的模型中,我们将看不到按语言聚类,也不会有语言差距。一种语言中的句子应该非常接近其良好的翻译,而远离表达其他含义的句子,即使是同一语言中的句子,如下图所示:

MLM 预训练无法实现这一点,因此我们使用额外的对比学习技术来改进 embeddings 中的语义表示。
对比学习涉及使用已知在含义上相似或不同的文本对,以及已知一对比另一对更相似的三元组。在训练过程中,权重会被调整以反映文本对和三元组之间的这种已知关系。
我们的对比学习数据集中包含 30 种语言,但 97% 的对和三元组都在同一语言中,只有 3% 涉及跨语言对或三元组。但这 3% 就足以产生戏剧性的结果:Embeddings 几乎不显示语言聚类,而语义相似的文本无论使用什么语言都会产生接近的 embeddings,正如从 jina-embeddings-v3 的 UMAP 投影所示。
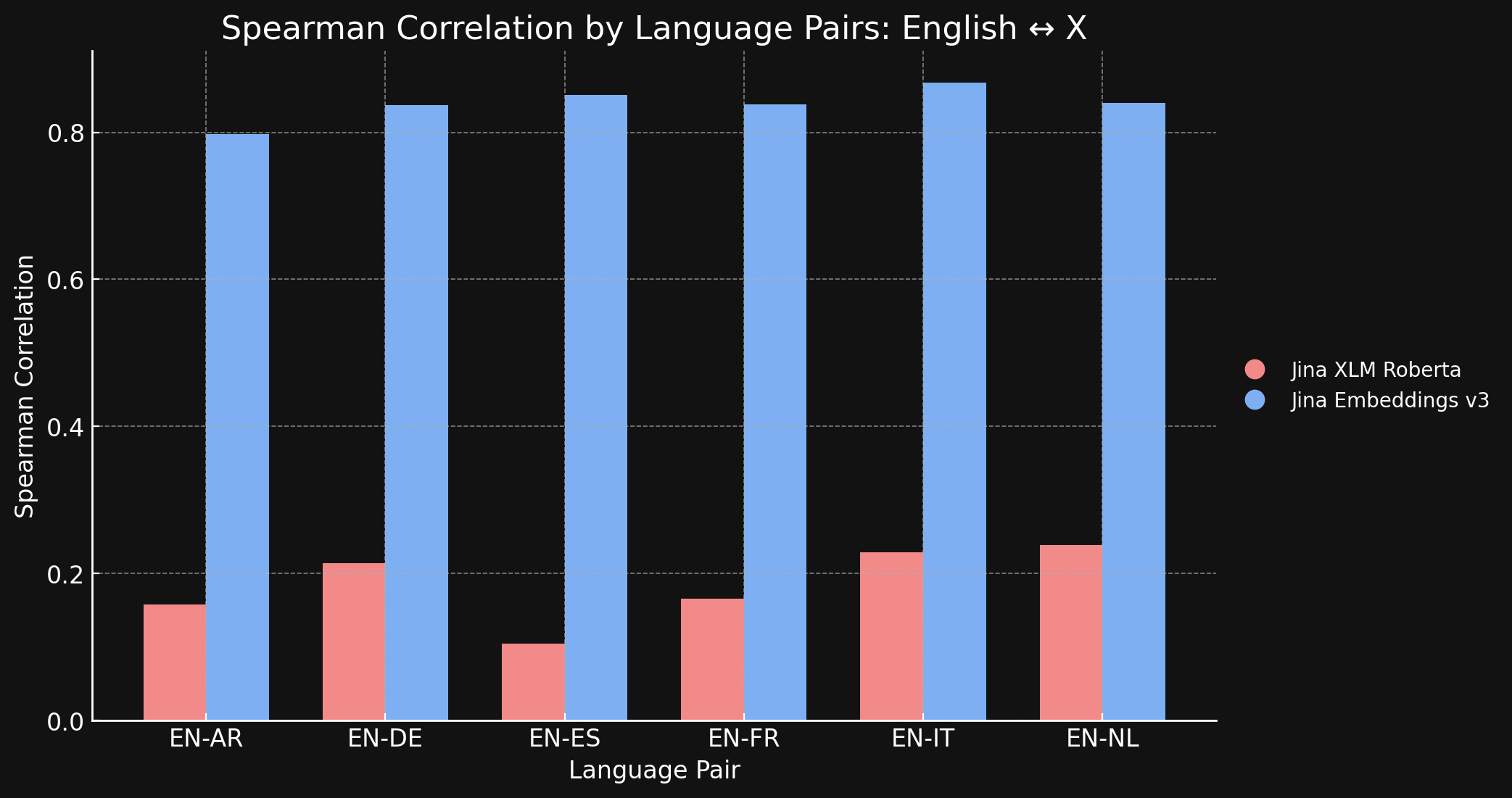
为了验证这一点,我们测量了 jina-xlm-roberta 和 jina-embeddings-v3 在 STS17 数据集上生成的表征的 Spearman 相关性。
下表显示了不同语言翻译文本的语义相似性排名之间的 Spearman 相关性。我们取一组英语句子,然后测量它们的嵌入与特定参考句子嵌入的相似度,并按照从最相似到最不相似的顺序排序。然后我们将所有这些句子翻译成另一种语言并重复排序过程。在理想的跨语言嵌入模型中,这两个有序列表应该是相同的,Spearman 相关性应该是 1.0。
下面的图表和表格显示了我们使用 jina-xlm-roberta 和 jina-embeddings-v3 比较 STS17 基准测试中的英语和其他六种语言的结果。
| Task | jina-xlm-roberta |
jina-embeddings-v3 |
|---|---|---|
| English ↔ Arabic | 0.1581 | 0.7977 |
| English ↔ German | 0.2136 | 0.8366 |
| English ↔ Spanish | 0.1049 | 0.8509 |
| English ↔ French | 0.1659 | 0.8378 |
| English ↔ Italian | 0.2293 | 0.8674 |
| English ↔ Dutch | 0.2387 | 0.8398 |
你可以在这里看到对比学习与原始预训练相比带来的巨大差异。尽管在训练数据中只有 3% 的跨语言数据,jina-embeddings-v3 模型已经学习到足够的跨语言语义,几乎消除了在预训练中产生的语言差距。
tag英语对抗世界:其他语言能在对齐中保持竞争力吗?
我们在 89 种语言上训练了 jina-embeddings-v3,特别关注 30 种使用广泛的书面语言。尽管我们努力构建大规模的多语言训练语料库,英语仍然占我们在对比训练中使用的数据的近一半。其他语言,包括那些有大量文本材料可用的广泛使用的全球语言,相比训练集中庞大的英语数据量,仍然相对代表性不足。
考虑到英语的这种主导地位,英语表征是否比其他语言的表征更加对齐?为了探索这一点,我们进行了一项后续实验。
我们构建了一个数据集 parallel-sentences,包含 1,000 对英语文本,一个"锚点"和一个"正例",其中正例文本在逻辑上被锚点文本蕴含。

例如,下表中的第一行。这些句子的含义并不完全相同,但它们具有兼容的含义。它们都在信息性地描述同一种情况。
然后,我们使用 GPT-4 将这些句对翻译成五种语言:德语、荷兰语、简体中文、繁体中文和日语。最后,我们手动检查以确保质量。
| Language | Anchor | Positive |
|---|---|---|
| English | Two young girls are playing outside in a non-urban environment. | Two girls are playing outside. |
| German | Zwei junge Mädchen spielen draußen in einer nicht urbanen Umgebung. | Zwei Mädchen spielen draußen. |
| Dutch | Twee jonge meisjes spelen buiten in een niet-stedelijke omgeving. | Twee meisjes spelen buiten. |
| Chinese (Simplified) | 两个年轻女孩在非城市环境中玩耍。 | 两个女孩在外面玩。 |
| Chinese (Traditional) | 兩個年輕女孩在非城市環境中玩耍。 | 兩個女孩在外面玩。 |
| Japanese | 2人の若い女の子が都市環境ではない場所で遊んでいます。 | 二人の少女が外で遊んでいます。 |
然后,我们使用 jina-embeddings-v3 对每对文本进行编码,并计算它们之间的余弦相似度。下图和表格显示了每种语言的余弦相似度分数分布和平均相似度:
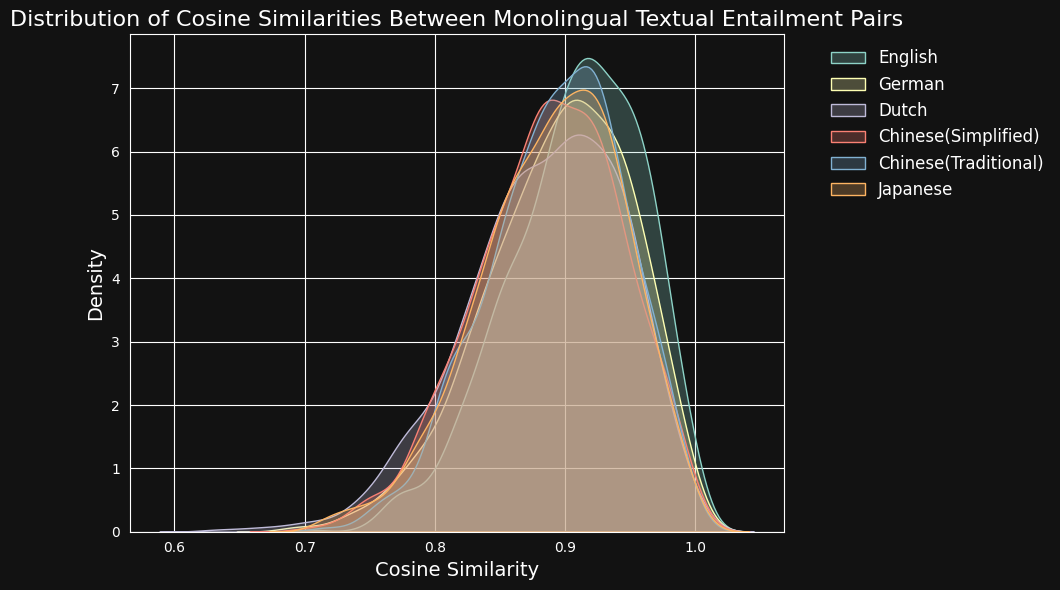
| Language | Average Cosine Similarity |
|---|---|
| English | 0.9078 |
| German | 0.8949 |
| Dutch | 0.8844 |
| Chinese (Simplified) | 0.8876 |
| Chinese (Traditional) | 0.8933 |
| Japanese | 0.8895 |
尽管英语在训练数据中占主导地位,jina-embeddings-v3 在识别德语、荷兰语、日语和两种形式的中文的语义相似性方面的表现与英语相差无几。
tag打破语言障碍:超越英语的跨语言对齐
跨语言表征对齐的研究通常研究包含英语的语言对。从理论上讲,这种关注可能会掩盖真实情况。模型可能只是优化了将所有内容尽可能地表示为接近其英语等效项,而没有检查其他语言对是否得到了适当的支持。
为了探索这一点,我们使用 parallel-sentences 数据集进行了一些实验,重点关注超出仅英语双语对的跨语言对齐。
下表显示了不同语言对之间等效文本的余弦相似度分布 — 这些文本是来自同一英语源文的翻译。理想情况下,所有对都应该有一个余弦值为 1 — 即完全相同的语义嵌入。在实践中,这不可能发生,但我们期望一个好的模型对于翻译对来说具有非常高的余弦值。
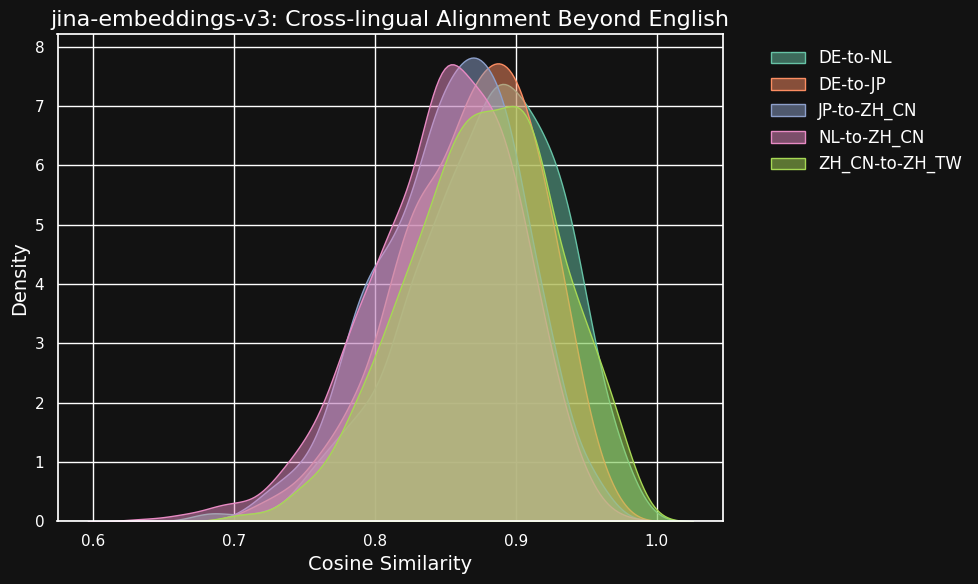
| Language Pair | Average Cosine Similarity |
|---|---|
| German ↔ Dutch | 0.8779 |
| German ↔ Japanese | 0.8664 |
| Chinese (Simplified) ↔ Japanese | 0.8534 |
| Dutch ↔ Chinese (Simplified) | 0.8479 |
| Chinese (Simplified) ↔ Chinese (Traditional) | 0.8758 |
虽然不同语言之间的相似度分数比同一语言中兼容文本的分数略低,但它们仍然非常高。荷兰语/德语翻译之间的余弦相似度几乎与德语中兼容文本之间的余弦相似度一样高。
这可能并不令人惊讶,因为德语和荷兰语是非常相似的语言。同样,这里测试的两种中文变体实际上不是两种不同的语言,只是同一种语言的风格略有不同的形式。但你可以看到,即使是像荷兰语和中文或德语和日语这样非常不相似的语言对之间,语义等效文本之间仍然显示出很强的相似性。
我们考虑到这些非常高的相似值可能是使用 ChatGPT 作为翻译器的副作用。为了测试这一点,我们下载了 TED Talks 的英语和德语人工翻译文本,并检查对齐的翻译句子是否具有相同的高相关性。
结果比我们的机器翻译数据更强,从下图可以看出。
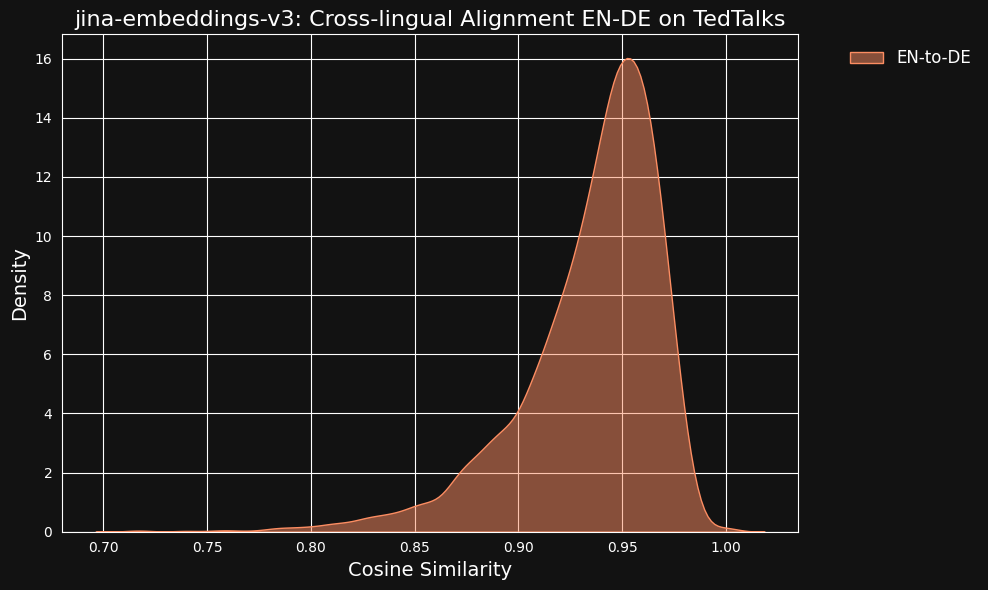
tag跨语言数据对跨语言对齐的贡献有多大?
消失的语言差距和高水平的跨语言性能似乎与明确的跨语言训练数据的很小部分不成比例。只有 3% 的对比训练数据专门教导模型如何在语言之间进行对齐。
因此,我们进行了一个测试,看看跨语言是否真的有任何贡献。
完全不使用任何跨语言数据重新训练 jina-embeddings-v3 对于一个小实验来说代价太大了,所以我们从 Hugging Face 下载了 xlm-roberta-base 模型,并使用我们训练 jina-embeddings-v3 时使用的部分数据进行对比学习进一步训练。我们专门调整了跨语言数据的数量来测试两种情况:一种是没有跨语言数据,另一种是 20% 的对是跨语言的。你可以在下表中看到训练的元参数:
| Backbone | % Cross-Language | Learning Rate | Loss Function | Temperature |
xlm-roberta-base without X-language data | 0% | 5e-4 | InfoNCE | 0.05 |
xlm-roberta-base with X-language data | 20% | 5e-4 | InfoNCE | 0.05 |
然后,我们使用来自 MTEB 的 STS17 和 STS22 基准测试和 Spearman 相关性评估了两个模型的跨语言性能。我们在下面展示结果:
tagSTS17
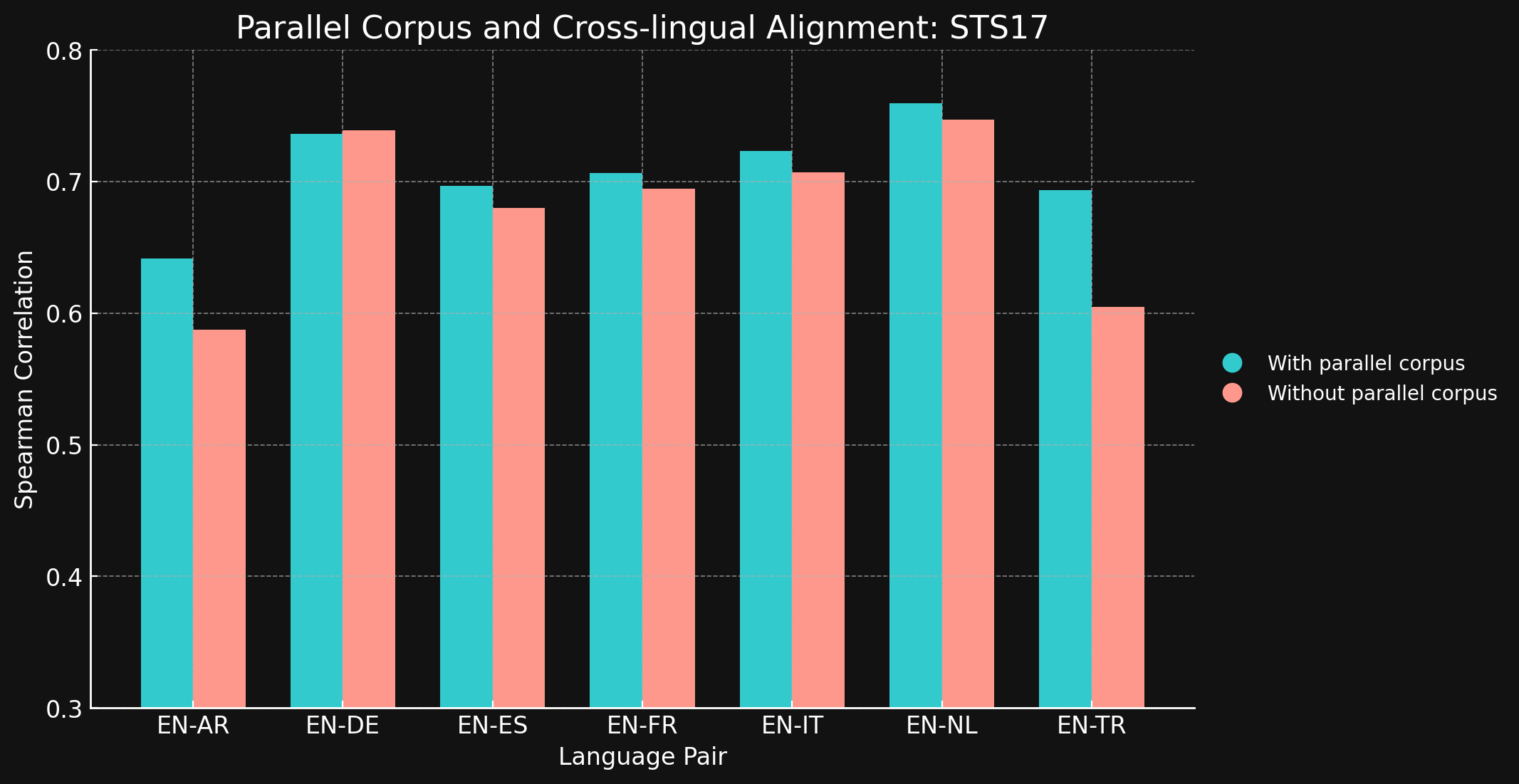
| Language Pair | With parallel corpora | Without parallel corpora |
| English ↔ Arabic | 0.6418 | 0.5875 |
| English ↔ German | 0.7364 | 0.7390 |
| English ↔ Spanish | 0.6968 | 0.6799 |
| English ↔ French | 0.7066 | 0.6944 |
| English ↔ Italian | 0.7232 | 0.7070 |
| English ↔ Dutch | 0.7597 | 0.7468 |
| English ↔ Turkish | 0.6933 | 0.6050 |
tagSTS22
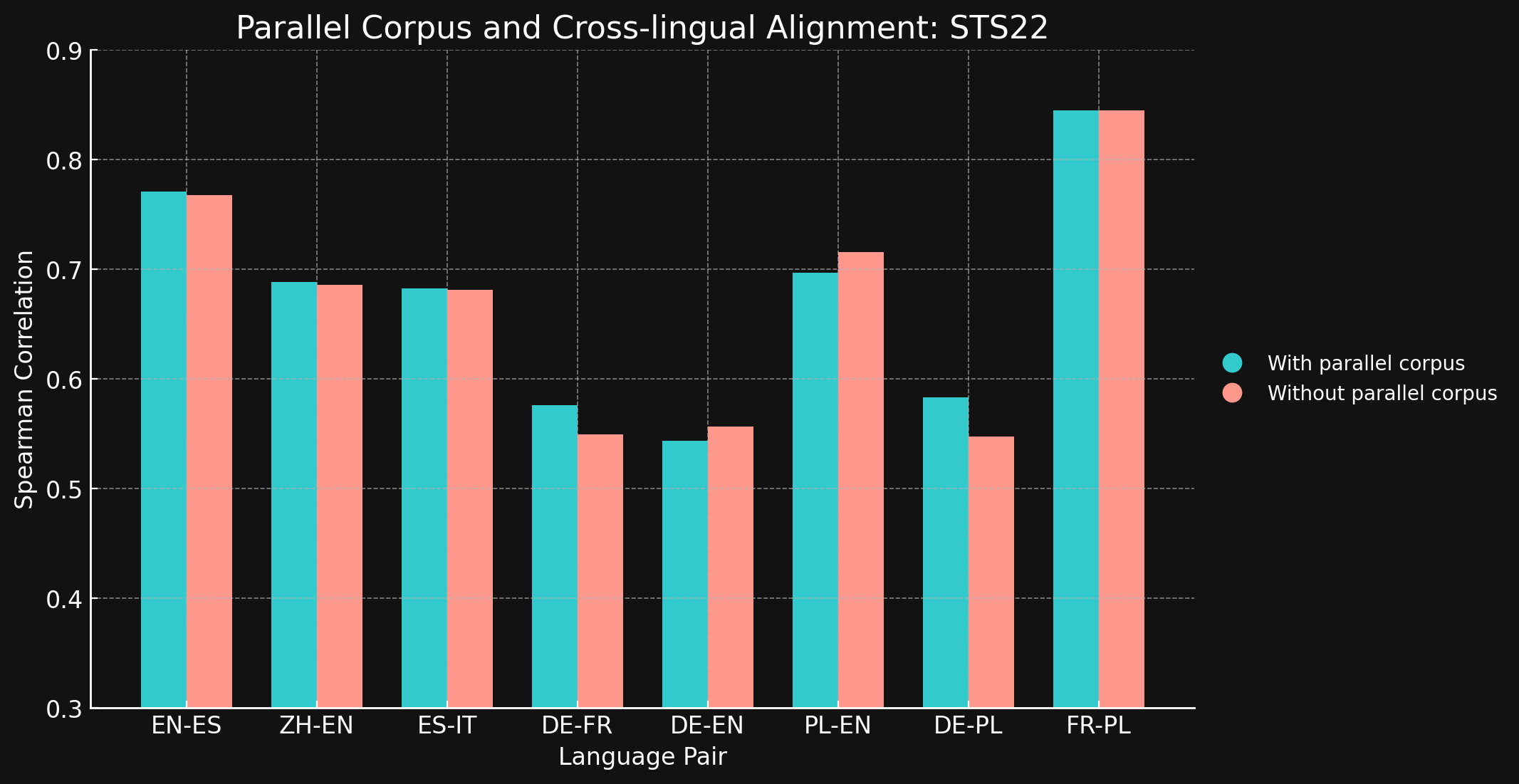
| 语言对 | 使用平行语料库 | 不使用平行语料库 |
| 英语 ↔ 西班牙语 | 0.7710 | 0.7675 |
| 简体中文 ↔ 英语 | 0.6885 | 0.6860 |
| 西班牙语 ↔ 意大利语 | 0.6829 | 0.6814 |
| 德语 ↔ 法语 | 0.5763 | 0.5496 |
| 德语 ↔ 英语 | 0.5439 | 0.5566 |
| 波兰语 ↔ 英语 | 0.6966 | 0.7156 |
| 德语 ↔ 英语 | 0.5832 | 0.5478 |
| 法语 ↔ 波兰语 | 0.8451 | 0.8451 |
令我们惊讶的是,对于我们测试的大多数语言对,跨语言训练数据几乎没有带来任何改进。虽然很难确定这个结论对于使用更大数据集的完整训练模型是否仍然成立,但这确实证明了显式的跨语言训练并没有带来太多益处。
然而,需要注意的是,STS17 包含了英语/阿拉伯语和英语/土耳其语这两个语言对。这两种语言在我们的训练数据中的代表性都相对较低。我们使用的 XML-RoBERTa 模型在预训练数据中,阿拉伯语占 2.25%,土耳其语占 2.32%,远低于我们测试的其他语言。在这个实验中使用的小型对比学习数据集中,阿拉伯语仅占 1.7%,土耳其语仅占 1.8%。
这两个语言对是测试中唯一显示出跨语言数据训练能带来明显差异的语言对。我们认为,对于在训练数据中代表性较低的语言来说,显式的跨语言数据可能更有效,但在得出结论之前还需要进行更多探索。跨语言数据在对比训练中的作用和效果是 Jina AI 正在积极研究的领域。
tag结论
传统的语言预训练方法,如掩码语言建模,会留下一个"语言差距",导致不同语言中语义相似的文本无法像预期那样紧密对齐。我们已经证明,Jina Embeddings 的对比学习方法在减少甚至消除这个差距方面非常有效。
这种方法有效的原因尚不完全清楚。我们在对比训练中确实使用了显式的跨语言文本对,但数量很小,而且它们在确保高质量跨语言结果方面实际发挥了多大作用还不清楚。我们尝试在更受控的条件下展示明确的效果,但并未得到明确的结果。
然而,很明显 jina-embeddings-v3 已经克服了预训练中的语言差距,成为了多语言应用的强大工具。它已经可以用于任何需要在多种语言中实现相同强大性能的任务。
您可以通过我们的 Embeddings API(提供一百万个免费令牌)或通过 AWS 或 Azure 使用 jina-embeddings-v3。如果您想在这些平台之外或在公司内部使用它,请记住它是在 CC BY-NC 4.0 许可下发布的。如果您对商业使用感兴趣,请联系我们。
