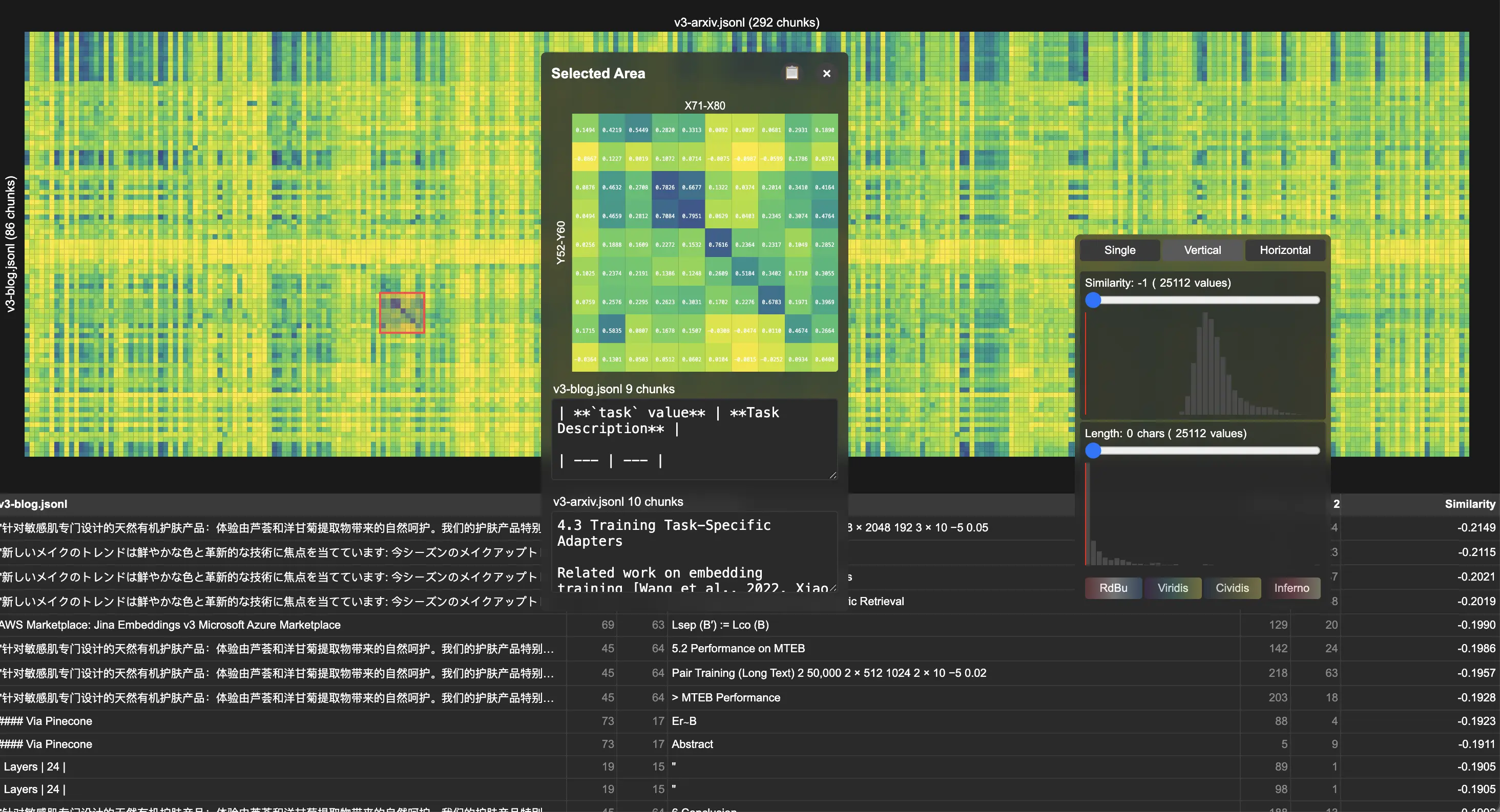


人们经常问我们一个有趣的问题:“你们如何检查你们的向量模型 (Embeddings) 的质量?” 当然,有 MTEB 可以在公共基准上进行严肃和定量的评估,但对于开放领域或新问题,你们会怎么做呢?今天,我们想分享一个我们用于调试和可视化的内部小工具。你可以称它为我们的质量测试工具包。我们称它为 Correlations,它在 GitHub 上是开源的。
tag设计
Correlations 生成交互式热图,其中每个单元格显示两个片段之间的余弦相似度,无论它们是来自相同还是不同的文档集合、模态、超参数或模型。它支持以下几种交互:
- 悬停检查:单个单元格对的原始文本/图像和相似度得分
- 区域选择:交互式区域选择,用于集中分析相似度模式
- 阈值过滤:相似度得分和文本长度过滤器,用于减少噪声
该工具通过两阶段管道运行:
npm run embed:使用 Jina Embeddings API 和可配置的分块策略(换行符、标点符号、基于字符或正则表达式模式)npm run corr:基于浏览器的 UI,提供具有实时交互的相关性热图
开始使用:
npm install
export JINA_API_KEY=your_jina_key_here
npm run embed -- https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model -o v3-blog.jsonl -t retrieval.query
npm run embed -- https://arxiv.org/pdf/2409.10173 -o v3-arxiv.jsonl -t retrieval.passage
npm run corr -- v3-blog.jsonl v3-arxiv.jsonlJINA_API_KEY 用于在必要时从 URL 嵌入和读取内容,当然也支持从本地文本文件读取。你也可以自带向量模型 (Embeddings) 并仅运行 npm run corr 进行可视化,在这种情况下,你不需要 JINA_API_KEY。该工具支持自相关分析(在单个集合内)和互相关分析(在两个集合之间)。
tag用例
tag内容去重和对齐分析
我们通过分析我们的 jina-embeddings-v3 出版物来展示该工具的实用性。通过比较学术论文和发布说明,可视化结果显示相关性热图中存在明显的对角线模式,表明文档之间存在强大的分块到分块的对齐。详细检查显示了系统的内容重用,尤其是在描述 LoRA 任务类型的技术部分中。
tag引文和参考文献验证
该工具对于验证检索增强生成系统中的引文准确性非常有用,在这些系统中,验证检索到的段落是否真正支持生成的声明至关重要。基于相似性的分析是一种强大而直观的工具,可以探索大型数据集,例如,通过按相似性对项目进行分组来揭示模式。
tag分块策略探索
通过检查不同的方法如何影响文本片段内部和之间的语义连贯性,可以评估延迟分块和其他分割策略。该可视化工具通过揭示与语义结构对齐的相似性模式,帮助识别延迟分块效应和最佳分块边界。
tag跨模态分析
该工具的功能不仅仅限于文本,还支持通过 jina-clip-v2 进行图像向量模型 (image embeddings),从而能够分析多模态应用中的文本-图像相关模式。
tag向量模型可视化相关工作
当使用高维向量模型 (high-dimensional embeddings) 时,可解释性挑战尤为突出。向量模型 (embedding) 可视化技术的格局已经发生了显著的变化,不同的方法可以归类为:
- 基于降维的方法:使用 PCA、t-SNE、UMAP 等传统方法将高维空间投影到 2D/3D
- 基于交互式探索的方法:像 Parallax 和 TextEssence 这样的工具,可以直接操作和探索
- 特定领域的解决方案:像 Clustergrammer 这样的生物数据专用工具
- 直接相似性可视化:我们的方法和类似的基于热图的方法,可以保留完整的关系信息
| 方法 | 途径 | 用例 |
|---|---|---|
| Correlations | 直接成对相似性热图 | 文本相似性调试、对齐分析 |
| Embedding Projector | PCA、t-SNE 和自定义线性投影 | 交互式可视化和解释 |
| Parallax | 用于语义探索的代数公式 | 理解语义关系 |
| TextEssence | 比较语料库分析 | 历时分析、语料库比较 |
| Nomic Atlas | 基于云的可扩展可视化 | 大规模数据集、协作 |
| Clustergrammer | 带有聚类的交互式热图 | 高维生物数据 |
| t-SNE | 非线性聚类可视化 | 模型调试、混淆识别 |
| UMAP | 局部和全局结构保留 | 中大型数据集、通用分析 |
| PCA | 线性降维 | 初始探索、基线比较 |
tag逐点方法的局限性
现有的可视化工具主要侧重于 2D 空间中的逐点表示,这可能会丢失关于成对关系的关键信息。此外,大多数工具都是为单向量模型 (single embedding) 空间分析而设计的,而不是为不同来源、模态或向量模型 (embedding) 策略(例如,开启与关闭延迟分块)之间的比较评估而设计的。
例如,我们最近在 Jina 遇到了两个用例。第一个涉及 DeepSearch 中的交叉检查引用,我们需要将生成的报告与参考资料中的原始摘录进行匹配。第二个是多模态检索,我们需要验证新未标记数据上的图像-文本和图像-图像对齐。在这两种情况下,我们都需要探索两个向量模型 (embeddings) 集合之间的关系。因此,我们使用 Correlations 来了解匹配的对齐程度,并验证最高的相关性是否始终对应于正确的匹配。
tag结论
除了检查氛围之外,correlations 还可以提供对语义关系的更深入见解。作为起点,可以从相关矩阵中提取几个关键统计数据:
- 矩阵密度:高于指定阈值的相关性比例,表示整体语义内聚力
- 特征值分布:主成分分析揭示了相似性结构中的主导模式
- 矩阵秩:表示相似性关系的有效维度
- 条件数:衡量数值稳定性及潜在的多重共线性问题
高级分析还可能涉及提取代表连贯语义区域的有意义的子矩阵。从 n 阶实矩阵中提取 k 阶最大和主子矩阵是一个典型的组合优化问题,可以识别相关性最高的片段。





