
我最近研究了 DSPy,这是斯坦福 NLP 小组开发的一个前沿框架,旨在算法化优化语言模型(LM)的 prompt。在过去的三天里,我对 DSPy 有了一些初步印象和见解。需要注意的是,我的观察并不是要取代 DSPy 的官方文档。事实上,我强烈建议在阅读这篇文章之前,至少先阅读一遍他们的文档和 README。我在这里的讨论反映了我花了几天时间探索其功能后的初步理解。还有一些高级功能,如 DSPy Assertions、Typed Predictor 和 LM 权重调优,我还没有深入研究。
 stanfordnlp
stanfordnlp尽管我在 Jina AI 的背景主要集中在搜索底座设施上,但我对 DSPy 的兴趣并不是直接源于它在检索增强生成(RAG)方面的潜力。相反,我对利用 DSPy 进行自动 prompt 调优来解决一些生成任务的可能性更感兴趣。
如果你是 DSPy 的新手并寻找一个易于入门的切入点,或者你已经熟悉该框架但觉得官方文档令人困惑或难以理解,那么这篇文章就是为你准备的。我也选择不严格遵循 DSPy 的惯用语法,因为这可能会让新手望而生畏。让我们深入了解。
tag我喜欢 DSPy 的地方
tagDSPy 闭合了 Prompt Engineering 的循环
DSPy 最让我兴奋的是它闭合 prompt engineering 循环的方式,将一个通常是手动、手工制作的过程转变为结构化、明确定义的机器学习工作流程:即准备数据集、定义模型、训练、评估和测试。在我看来,这是 DSPy 最具革命性的方面。
在湾区旅行并与许多专注于 LLM 评估的创业公司创始人交谈时,我经常听到关于指标、幻觉、可观察性和合规性的讨论。然而,这些对话往往没有进展到关键的下一步:有了这些指标后,我们该怎么做?调整 prompt 中的措辞,希望某些神奇的词语(例如"my grandma is dying")能提升我们的指标,这能被认为是一种策略性的方法吗?这个问题一直没有得到许多 LLM 评估创业公司的回答,我也无法解决——直到我发现了 DSPy。DSPy 引入了一个清晰的、程序化的方法来基于特定指标优化 prompt,甚至可以优化整个 LLM 管道,包括 prompt 和 LLM 权重。
LangChain 的 CEO Harrison 和前 OpenAI 开发者关系主管 Logan 在 Unsupervised Learning Podcast 上都表示,2024 年将是 LLM 评估的关键一年。正因如此,我相信 DSPy 应该得到比现在更多的关注,因为 DSPy 提供了这个拼图中至关重要的缺失部分。
tagDSPy 将逻辑与文本表示分离
DSPy 让我印象深刻的另一个方面是,它将 prompt engineering 转化为一个可重复的、与 LLM 无关的模块。为了实现这一点,它将逻辑从 prompt 中抽离出来,在逻辑和文本表示之间创建了明确的关注点分离,如下图所示。
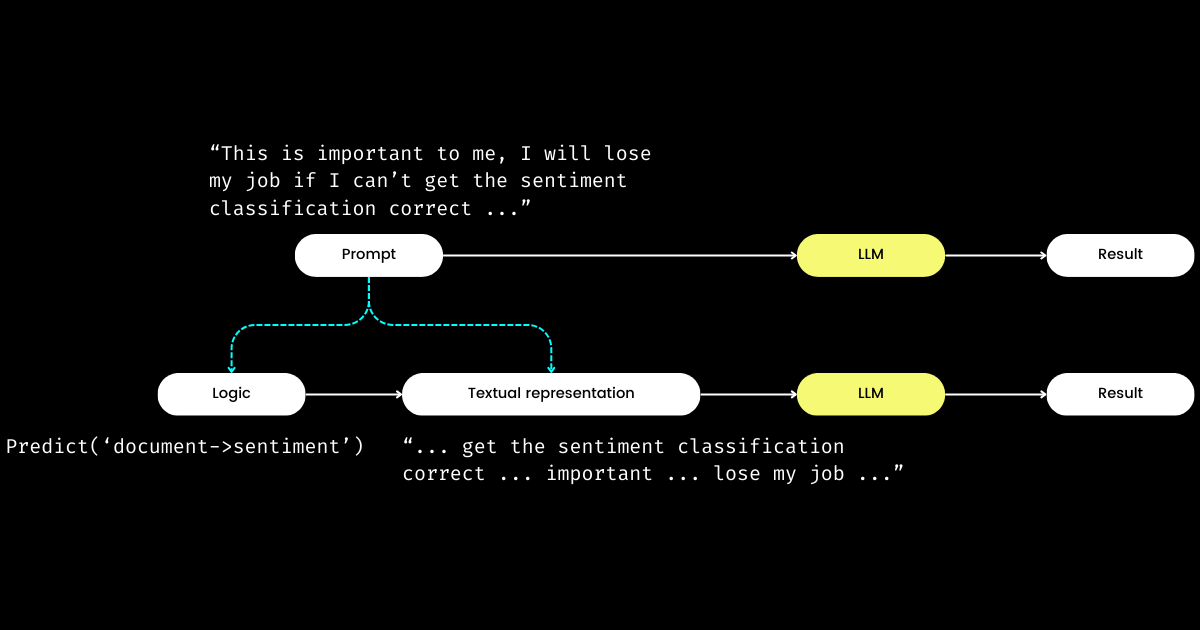
dspy.Module)和其文本表示组成。逻辑是不可变的、可重复的、可测试的和与 LLM 无关的。文本表示仅仅是逻辑的结果。DSPy 将逻辑视为不可变、可测试和与 LLM 无关的"原因",而文本表示仅仅是其"结果"的概念,一开始可能令人困惑。尤其是在"编程语言的未来是自然语言"这一普遍观点下更是如此。在接受"prompt engineering 是未来"这一想法的同时,当遇到 DSPy 的设计理念时,人们可能会感到困惑。与简化的期望相反,DSPy 引入了一系列模块和签名语法,似乎将自然语言 prompting 退化到了 C 编程的复杂性!
但为什么要采用这种方法?我的理解是,在 prompt 编程的核心是逻辑,而沟通则是一个放大器,可能增强或减弱其效果。"Do sentiment classification" 代表了核心逻辑,而像 "Follow these demonstrations or I will fire you" 这样的短语则是一种沟通方式。类似于现实生活中的互动,事情难以完成往往不是因为逻辑有问题,而是因为沟通有问题。这解释了为什么许多人,特别是非母语者,觉得 prompt engineering 具有挑战性。我观察到公司里一些非常优秀的软件工程师在 prompt engineering 方面遇到困难,不是因为他们缺乏逻辑,而是因为他们不能"说对的语气"。通过将逻辑从 prompt 中分离出来,DSPy 通过 dspy.Module 实现了确定性的逻辑编程,让开发者能够像传统工程那样专注于逻辑,而不受使用的 LLM 的影响。
那么,如果开发者专注于逻辑,谁来管理文本表示呢?DSPy 承担了这个角色,利用你的数据和评估指标来优化文本表示——从确定叙述重点到优化提示,以及选择好的示例。令人惊叹的是,DSPy 甚至可以使用评估指标来微调 LLM 权重!
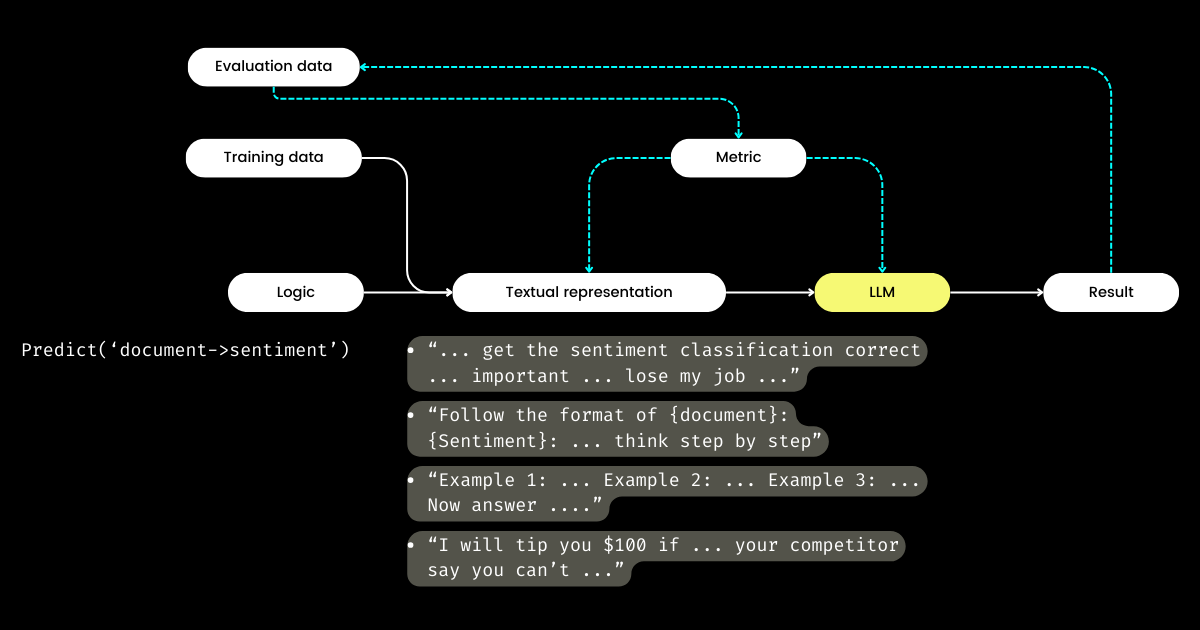
对我来说,DSPy 的关键贡献——闭合 prompt engineering 中的训练和评估循环,以及将逻辑与文本表示分离——凸显了它对 LLM/Agent 系统的潜在重要性。这确实是一个雄心勃勃的愿景,但绝对是必要的!
tag我认为 DSPy 可以改进的地方
首先,由于其惯用语,DSPy 对新手来说学习曲线很陡峭。诸如 signature、module、program、teleprompter、optimization 和 compile 等术语可能令人望而生畏。即使对那些精通 prompt engineering 的人来说,在 DSPy 中导航这些概念也可能是一个具有挑战性的迷宫。
这种复杂性让我想起了我在 Jina 1.0 中的经历,当时我们引入了许多概念,如 chunk、document、driver、executor、pea、pod、querylang 和 flow(我们甚至设计了可爱的贴纸来帮助用户记忆!)。






在后来的 Jina 重构中,这些早期概念大多被移除了。如今,只有 Executor、Document 和 Flow 在"大清洗"中幸存下来。我们在 Jina 3.0 中确实添加了一个新概念 Deployment,这样就扯平了。🤷
这个问题不仅限于 DSPy 或 Jina;回想一下 TensorFlow 从 0.x 到 1.x 版本之间引入的众多概念和抽象。我认为这个问题经常出现在软件框架的早期阶段,当时有一种推动力要在代码库中直接反映学术概念,以确保最大程度的准确性和可复现性。然而,并非所有用户都重视这种细粒度的抽象,他们的偏好从希望简单的一行代码到要求更大的灵活性都有。我在 2020 年的一篇博文中详细讨论了软件框架中的抽象问题,感兴趣的读者可能会觉得有价值。


其次,DSPy 的文档在一致性方面有时存在不足。像 module 和 program、teleprompter 和 optimizer,或者 optimize 和 compile(有时被称为 training 或 bootstrapping)这样的术语被交替使用,增加了混淆。因此,我最初花了几个小时试图搞清楚 DSPy 到底在优化什么,以及bootstrapping的过程是什么。
尽管存在这些障碍,当你深入研究 DSPy 并重新查看文档时,你可能会经历一些顿悟的时刻,所有内容开始变得清晰起来,揭示了其独特术语与类似 PyTorch 这样的框架中熟悉结构之间的联系。然而,DSPy 无疑在未来版本中有改进的空间,特别是在让那些没有 PyTorch 背景的提示工程师更容易使用这个框架方面。
tagDSPy 新手常见的绊脚石
在下面的章节中,我整理了一份最初阻碍我使用 DSPy 进展的问题清单。我的目的是分享这些见解,希望它们能为其他学习者澄清类似的挑战。
tag什么是 teleprompter、optimization 和 compile?DSPy 中到底在优化什么?
在 DSPy 中,"Teleprompters" 是优化器(看起来 @lateinteraction 正在修改文档和代码以澄清这一点)。compile 函数作为这个优化器的核心,类似于调用 optimizer.optimize()。可以把它想象成 DSPy 中的训练。这个 compile() 过程旨在优化:
- 少样本示例,
- 指令,
- LLM 的权重
然而,大多数 DSPy 入门教程不会深入研究权重和指令调优,这就引出了下一个问题。
tagDSPy 中的 bootstrap 是什么?
Bootstrap 指的是为少样本上下文学习创建自生成的示例,这是 compile() 过程(即我上面提到的优化/训练)的重要组成部分。这些少样本示例是从用户提供的标记数据生成的;一个示例通常包括输入、输出、推理过程(例如,在思维链中),以及中间输入和输出(用于多阶段提示)。当然,高质量的少样本示例对输出的优秀性至关重要。为此,DSPy 允许用户定义度量函数来确保只选择满足特定标准的示例,这就引出了下一个问题。
tag什么是 DSPy 度量函数?
在实际使用 DSPy 后,我认为度量函数需要比当前文档更多的强调。DSPy 中的度量函数在评估和训练阶段都发挥着关键作用,因为其隐含性质(由 trace=None 控制),它也充当"损失"函数:
def keywords_match_jaccard_metric(example, pred, trace=None):
# Jaccard similarity between example keywords and predicted keywords
A = set(normalize_text(example.keywords).split())
B = set(normalize_text(pred.keywords).split())
j = len(A & B) / len(A | B)
if trace is not None:
# act as a "loss" function
return j
return j > 0.8 # act as evaluation这种方法与传统机器学习有显著的不同,在传统机器学习中,损失函数通常是连续和可微的(例如,hinge/MSE),而评估指标可能完全不同且是离散的(例如,NDCG)。在 DSPy 中,评估和损失函数统一在度量函数中,它可以是离散的,而且通常返回布尔值。度量函数还可以集成 LLM!在下面的例子中,我使用 LLM 实现了模糊匹配,以确定预测值和标准答案在数量级上是否相似,例如,"1 百万美元"和"$1M"将返回 true。
class Assess(dspy.Signature):
"""Assess the if the prediction is in the same magnitude to the gold answer."""
gold_answer = dspy.InputField(desc='number, could be in natural language')
prediction = dspy.InputField(desc='number, could be in natural language')
assessment = dspy.OutputField(desc='yes or no, focus on the number magnitude, not the unit or exact value or wording')
def same_magnitude_correct(example, pred, trace=None):
return dspy.Predict(Assess)(gold_answer=example.answer, prediction=pred.answer).assessment.lower() == 'yes'虽然功能强大,但 metric 函数严重影响着 DSPy 的用户体验,它不仅决定最终的质量评估,还会影响优化结果。一个设计良好的 metric 函数可以带来优化后的 prompts,而设计不当的函数则可能导致优化失败。当使用 DSPy 解决新问题时,你可能会发现在设计逻辑(即 DSPy.Module)和 metric 函数上花费同样多的时间。这种需要同时关注逻辑和指标的双重任务对新手来说可能会很有挑战性。
tag"Bootstrapped 0 full traces after 20 examples in round 0" 这是什么意思?
这条在 compile() 过程中悄悄出现的消息值得你高度关注,因为它本质上意味着优化/编译失败了,你得到的 prompt 并不比简单的 few-shot 更好。哪里出错了?我总结了一些帮助你调试 DSPy 程序的建议,以应对这样的消息:
你的 Metric 函数不正确
在 BootstrapFewShot(metric=your_metric) 中使用的函数 your_metric 是否正确实现?进行一些单元测试。your_metric 是否有返回 True,还是总是返回 False?注意,返回 True 至关重要,因为这是 DSPy 判断 bootstrapped 示例是否"成功"的标准。如果你将每次评估都返回 True,那么每个示例在 bootstrapping 中都会被视为"成功"!当然,这并不理想,但这就是你如何通过调整 metric 函数的严格程度来改变 "Bootstrapped 0 full traces" 结果。请注意,虽然 DSPy 文档说明 metrics 也可以返回标量值,但在查看底层代码后,我不建议新手这样做。
你的逻辑(DSPy.Module)不正确
如果 metric 函数正确,那么你需要检查你的逻辑 dspy.Module 是否正确实现。首先,验证每个步骤的 DSPy signature 是否正确分配。内联签名,如 dspy.Predict('question->answer'),使用起来很简单,但为了保证质量,我强烈建议使用基于类的签名。具体来说,为类添加一些描述性的文档字符串,为 InputField 和 OutputField 填写 desc 字段——这些都为 LM 提供了关于每个字段的提示。下面我实现了两个多阶段的 DSPy.Module 来解决 费米问题,一个使用内联签名,另一个使用基于类的签名。
class FermiSolver(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict('question -> initial_guess')
self.step2 = dspy.Predict('question, initial_guess -> calculated_estimation')
self.step3 = dspy.Predict('question, initial_guess, calculated_estimation -> variables_and_formulae')
self.step4 = dspy.ReAct('question, initial_guess, calculated_estimation, variables_and_formulae -> gathering_data')
self.step5 = dspy.Predict('question, initial_guess, calculated_estimation, variables_and_formulae, gathering_data -> answer')
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5仅使用内联签名的费米问题求解器
class FermiStep1(dspy.Signature):
question = dspy.InputField(desc='Fermi problems involve the use of estimation and reasoning')
initial_guess = dspy.OutputField(desc='Have a guess – don't do any calculations yet')
class FermiStep2(FermiStep1):
initial_guess = dspy.InputField(desc='Have a guess – don't do any calculations yet')
calculated_estimation = dspy.OutputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
class FermiStep3(FermiStep2):
calculated_estimation = dspy.InputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
variables_and_formulae = dspy.OutputField(desc='Write a formula or procedure to solve your problem')
class FermiStep4(FermiStep3):
variables_and_formulae = dspy.InputField(desc='Write a formula or procedure to solve your problem')
gathering_data = dspy.OutputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
class FermiStep5(FermiStep4):
gathering_data = dspy.InputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
answer = dspy.OutputField(desc='the final answer, must be a numerical value')
class FermiSolver2(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict(FermiStep1)
self.step2 = dspy.Predict(FermiStep2)
self.step3 = dspy.Predict(FermiStep3)
self.step4 = dspy.Predict(FermiStep4)
self.step5 = dspy.Predict(FermiStep5)
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5使用基于类的签名的费米问题求解器,每个字段都有更完整的描述。
此外,检查 def forward(self, ) 部分。对于多阶段模块,确保上一步的输出(或者像 FermiSolver 中的所有输出)都作为输入传递给下一步。
你的问题可能太难了
如果 metric 和 module 都看起来正确,那么可能是你的问题太具有挑战性,而你实现的逻辑不足以解决它。因此,DSPy 发现无法基于你的逻辑和 metric 函数来 bootstrap 任何示例。在这种情况下,你可以考虑以下选项:
- 使用更强大的 LM。例如,将学生的 LM 从
gpt-35-turbo-instruct替换为gpt-4-turbo,使用更强大的 LM 作为教师。这通常很有效。毕竟,更强大的模型意味着对 prompts 的理解更好。 - 改进你的逻辑。在你的
dspy.Module中添加或替换一些步骤,使用更复杂的步骤。例如,将Predict替换为ChainOfThoughtProgramOfThought,添加Retrieval步骤。 - 添加更多训练示例。如果 20 个示例不够,那就尝试 100 个!这样你可以期望有一个示例通过 metric 检查并被
BootstrapFewShot选中。 - 重新构思问题。通常,当问题的表述不正确时,问题会变得无法解决。但如果你换个角度看问题,事情可能会变得更简单和明显。
在实践中,这个过程涉及反复试验。例如,我曾处理过一个特别具有挑战性的问题:根据两到三个关键词生成类似 Google Material Design 图标的 SVG 图标。我最初的策略是使用一个简单的 DSPy.Module,它使用 dspy.ChainOfThought('keywords -> svg'),并配合一个 metric 函数来评估生成的 SVG 与 Ground Truth Material Design SVG 之间的视觉相似度,类似于 pHash 算法。我从 20 个训练示例开始,但在第一轮后得到了 "Bootstrapped 0 full traces after 20 examples in round 0",表明优化失败了。通过将数据集增加到 100 个示例,修改我的模块以包含多个阶段,并调整 metric 函数的阈值,我最终获得了 2 个 bootstrapped 示例,并成功获得了一些优化后的 prompts。





