

代码和文档的精确搜索比以往任何时候都更加重要。我们非常激动地推出我们最新的代码嵌入模型:jina-embeddings-v2-base-code。这个新的开源编程语言嵌入模型旨在改进开发者与代码和文档的交互方式。它支持英语和 30 种主流编程语言,作为同类模型中唯一支持高达 8,192 输入 token 的开源模型而脱颖而出。jina-embeddings-v2-base-code 现已在 HuggingFace 上以 Apache 2.0 许可证发布,并可通过我们的 Embedding API 免费使用。
访问 Embedding API 并从下拉列表中选择 jina-embeddings-v2-base-code。免费体验 100 万个 token。
tag为什么要开发代码嵌入模型?
开发者经常需要浏览大量代码库,不是为了寻找错误,而是为了定位特定功能或理解某些流程是如何实现的。这项任务往往耗时费力,有时就像大海捞针。集成开发环境(IDE)通过提供自动化信息搜索的工具和功能,显著改善了这一过程。然而,仍有进一步提升的空间,这正是我们的嵌入模型发挥作用的地方。
tagjina-embeddings-v2-base-code 的使用场景
通过整合 AI 驱动的搜索功能,我们不仅增强了 IDE 中的现有功能,还改变了开发者与代码库交互的方式。这项技术超越了简单的文本搜索,提供了语义理解能力,可以解读查询背后的意图,从而显著减少代码审查、单元测试和整体质量管理所需的时间和精力。
增强的代码导航
- 查询格式:用自然语言描述你要搜索的功能或代码片段。
- 检索结果格式:相关的代码文件或代码片段,以及指向代码特定部分的注释或高亮。
简化的代码审查
- 查询格式:描述你想要在代码库中审查的编程概念或模式。
- 检索结果格式:匹配所描述概念、模式或最佳实践的代码片段或拉取请求列表,使审查者能够专注于需要改进的关键领域。
自动化文档辅助
- 查询格式:需要文档或解释的代码片段。
- 检索结果格式:建议的 docstring 或文档条目,解释代码的功能、参数和返回类型,使维护最新和全面的文档变得更加容易。
通过解决这些具体的使用场景,jina-embeddings-v2-base-code 不仅提升了开发体验,还促进了更具协作性和效率的编码环境。
tag性能基准测试
在精确度和准确度至关重要的领域,jina-embeddings-v2-base-code 在十五个关键 CodeNetSearch 基准测试中的九个中表现优异。不仅如此,我们的模型在其余基准测试中也保持着极具竞争力的分数。与包括微软和 Salesforce 在内的最接近的竞争对手相比,jina-embeddings-v2-base-code 不仅排名更高,还展示了其卓越的设计和能力。
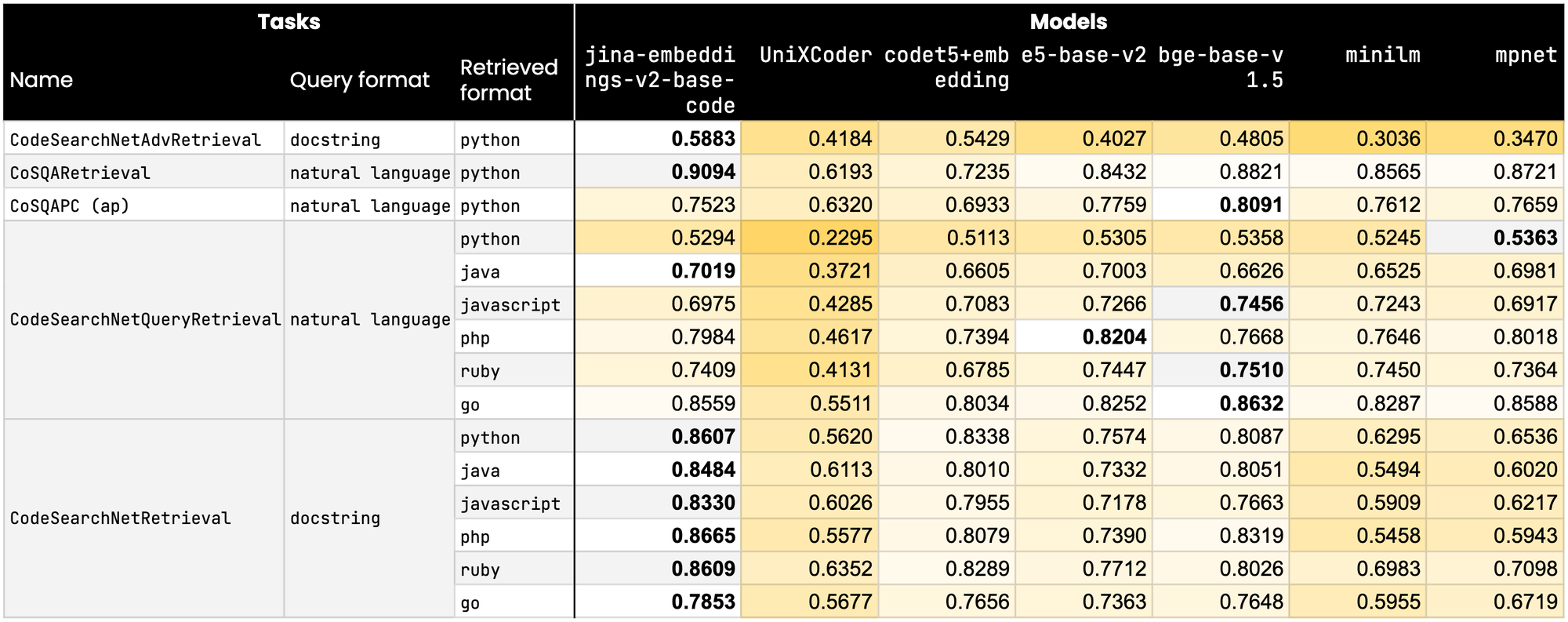
tag模型亮点
- 领先的性能:我们对卓越的追求体现在 Jina Embedding 模型的表现上,它们在基准测试中始终名列前茅,超越其他开源产品,甚至优于微软和 Salesforce 的模型。
- 小巧而强大:在 AI 领域,效率至关重要。jina-embeddings-v2-base-code 拥有 1.61 亿个参数(未量化前为 307MB),设计注重效率,在不损失性能的同时提供高速表现和成本节省。
- 扩展的上下文能力:能够处理高达 8192 个 token,可以处理大型函数和众多对象文件,提供的理解深度和上下文超越了仅支持几百个 token 的模型的局限性。
- 多语言支持:为了实现多功能性,我们的模型训练涵盖了 30 种编程语言和框架,重点强调六种最流行的语言:Python、JavaScript、Java、PHP、Go 和 Ruby。这种广泛的覆盖确保 jina-embeddings-v2-base-code 能够满足编程社区的多样化需求。
- RAG 集成实现无缝代码生成:该模型与 RAG 的兼容性以及与代码生成模型的集成不仅可以从通用知识生成代码,还能够读取相关 API 和文档,从而实现高效准确的自动代码集成。
tag无缝 API 集成
jina-embeddings-v2-base-code 设计为易于集成,支持主要的向量数据库,如 MongoDB、Qdrant 和 Weaviate,以及 Haystack 和 LlamaIndex 等框架。这确保开发者可以轻松地将我们的模型整合到他们现有的系统中,利用其功能来增强代码检索和文档处理。
我们重视您对 jina-embeddings-v2-base-code 的反馈。加入我们的社区频道,提供反馈并了解我们的最新进展。让我们一起打造一个更强大、更包容的 AI 未来。



