



Jina CLIP v1(jina-clip-v1)是一个新的多模态嵌入模型,它扩展了 OpenAI 的原始 CLIP 模型的功能。通过这个新模型,用户可以使用一个嵌入模型,在纯文本和文本-图像跨模态检索中都能获得最先进的性能。与 OpenAI CLIP 相比,Jina AI 在纯文本检索方面提升了 165%,在图像到图像检索方面提升了 12%,在文本到图像和图像到文本任务中保持相同或略有提升的性能。这种增强的性能使得 Jina CLIP v1 在处理多模态输入时成为不可或缺的工具。
在本文中,我们将首先讨论原始 CLIP 模型的缺点,以及我们如何使用独特的协同训练方法来解决这些问题。然后,我们将在各种检索基准测试上展示我们模型的有效性。最后,我们将提供详细说明,指导用户如何通过我们的 Embeddings API 和 Hugging Face 开始使用 Jina CLIP v1。
tag多模态 AI 的 CLIP 架构
2021 年 1 月,OpenAI 发布了 CLIP(对比语言-图像预训练)模型。CLIP 具有简单而巧妙的架构:它将两个嵌入模型——一个用于文本,一个用于图像——组合成一个具有单一输出嵌入空间的模型。它的文本和图像嵌入可以直接相互比较,使得文本嵌入和图像嵌入之间的距离与该文本对图像的描述程度成正比,反之亦然。
这在多模态信息检索和零样本图像分类中被证明非常有用。无需进一步的特殊训练,CLIP 就能很好地将图像分类到自然语言标签中。

原始 CLIP 中的文本嵌入模型是一个只有 6300 万参数的定制神经网络。在图像方面,OpenAI 发布的 CLIP 包含了一系列 ResNet 和 ViT 模型。每个模型都针对其各自的模态进行预训练,然后通过带标注的图像训练,为准备好的图像-文本对生成相似的嵌入。
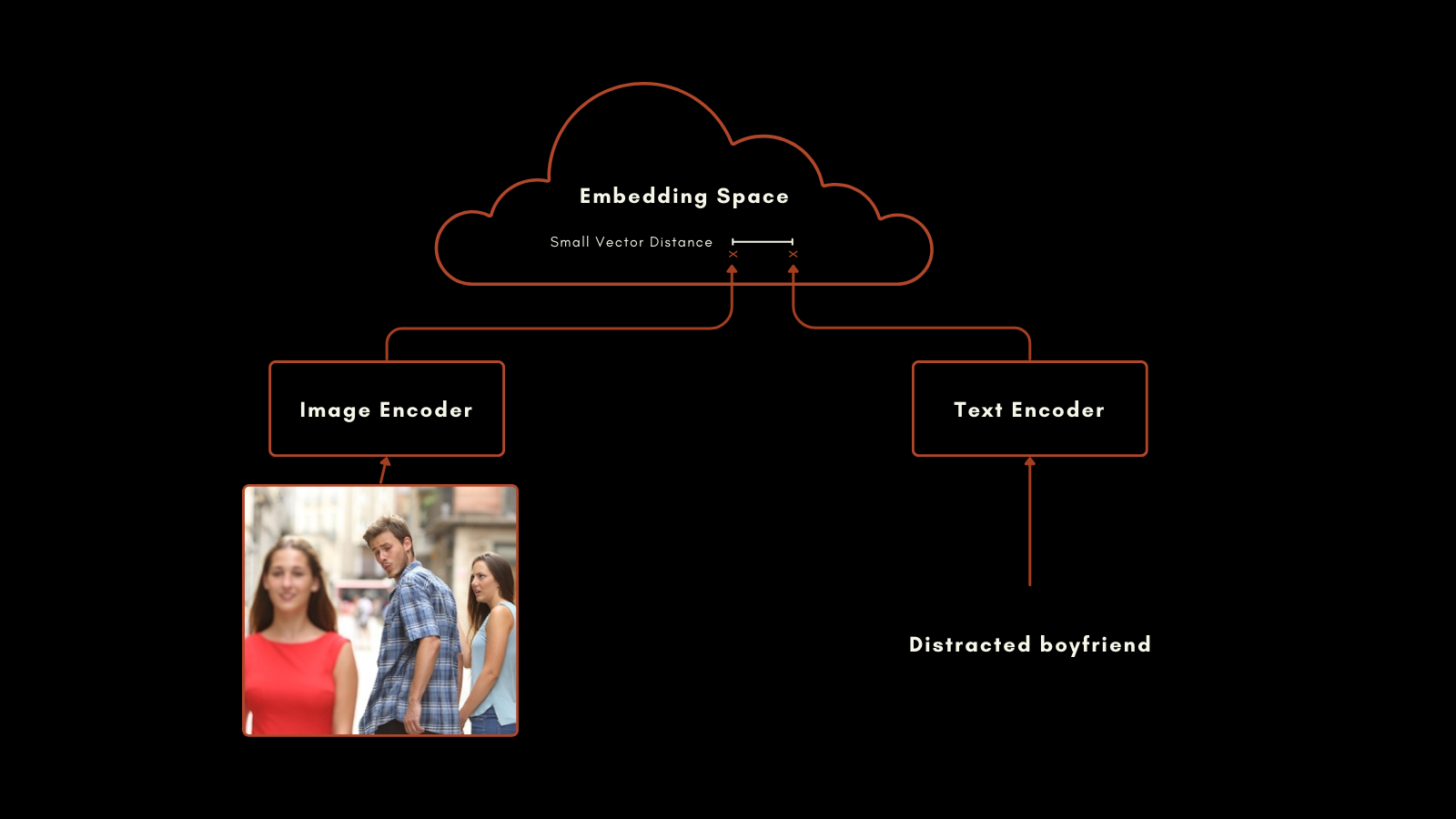
这种方法取得了令人印象深刻的结果。尤其值得注意的是它的零样本分类性能。例如,即使训练数据中没有包含宇航员的标记图像,CLIP 也能根据其对文本和图像中相关概念的理解,正确识别宇航员的图片。
然而,OpenAI 的 CLIP 有两个重要的缺点:
- 首先是文本输入容量非常有限。它最多可以接受 77 个标记的输入,但实验分析表明,在实践中它实际使用不超过 20 个标记来生成嵌入。这是因为 CLIP 是从带有标题的图像中训练的,而标题往往很短。这与当前支持数千个标记的文本嵌入模型形成对比。
- 其次,它的文本嵌入在纯文本检索场景中的性能非常差。图像标题是一种非常有限的文本类型,不能反映文本嵌入模型预期支持的广泛用例。
在大多数实际用例中,纯文本和图像-文本检索是结合使用的,或者至少两者都可用于任务。为纯文本任务维护第二个嵌入模型实际上使 AI 框架的规模和复杂性增加了一倍。
Jina AI 的新模型直接解决了这些问题,jina-clip-v1 利用近几年的进展,在涉及文本和图像模态所有组合的任务中带来最先进的性能。
tag介绍 Jina CLIP v1
Jina CLIP v1 保留了 OpenAI 的原始 CLIP 架构:两个经过共同训练以在相同嵌入空间中产生输出的模型。
在文本编码方面,我们采用了 Jina BERT v2 架构,该架构用于 Jina Embeddings v2 模型。这种架构支持最先进的 8k 标记输入窗口,输出 768 维向量,可以从更长的文本中生成更准确的嵌入。这比原始 CLIP 模型支持的 77 个标记输入多了 100 多倍。
对于图像嵌入,我们使用的是北京人工智能研究院的最新模型:EVA-02 模型。我们已经通过实验比较了多个图像 AI 模型,在类似预训练的跨模态场景中测试它们,EVA-02 明显优于其他模型。它的模型大小也与 Jina BERT 架构相当,因此图像和文本处理任务的计算负载大致相同。
这些选择为用户带来了重要的好处:
- 在所有基准测试和所有模态组合上都有更好的性能,尤其是在纯文本嵌入性能方面有很大提升。
EVA-02在图像-文本和纯图像任务中都表现出经验上的优越性能,再加上 Jina AI 的额外训练,提高了纯图像性能。- 支持更长的文本输入。Jina Embeddings 的 8k 标记输入支持使其能够处理详细的文本信息并将其与图像关联。
- 由于这个多模态模型在非多模态场景中也具有高性能,因此在空间、计算、代码维护和复杂性方面都能节省大量成本。
tag训练
我们高性能多模态 AI 的部分秘诀在于我们的训练数据和流程。我们注意到,图像标题中使用的文本长度很短是 CLIP 式模型在纯文本性能不佳的主要原因,我们的训练明确地设计来解决这个问题。
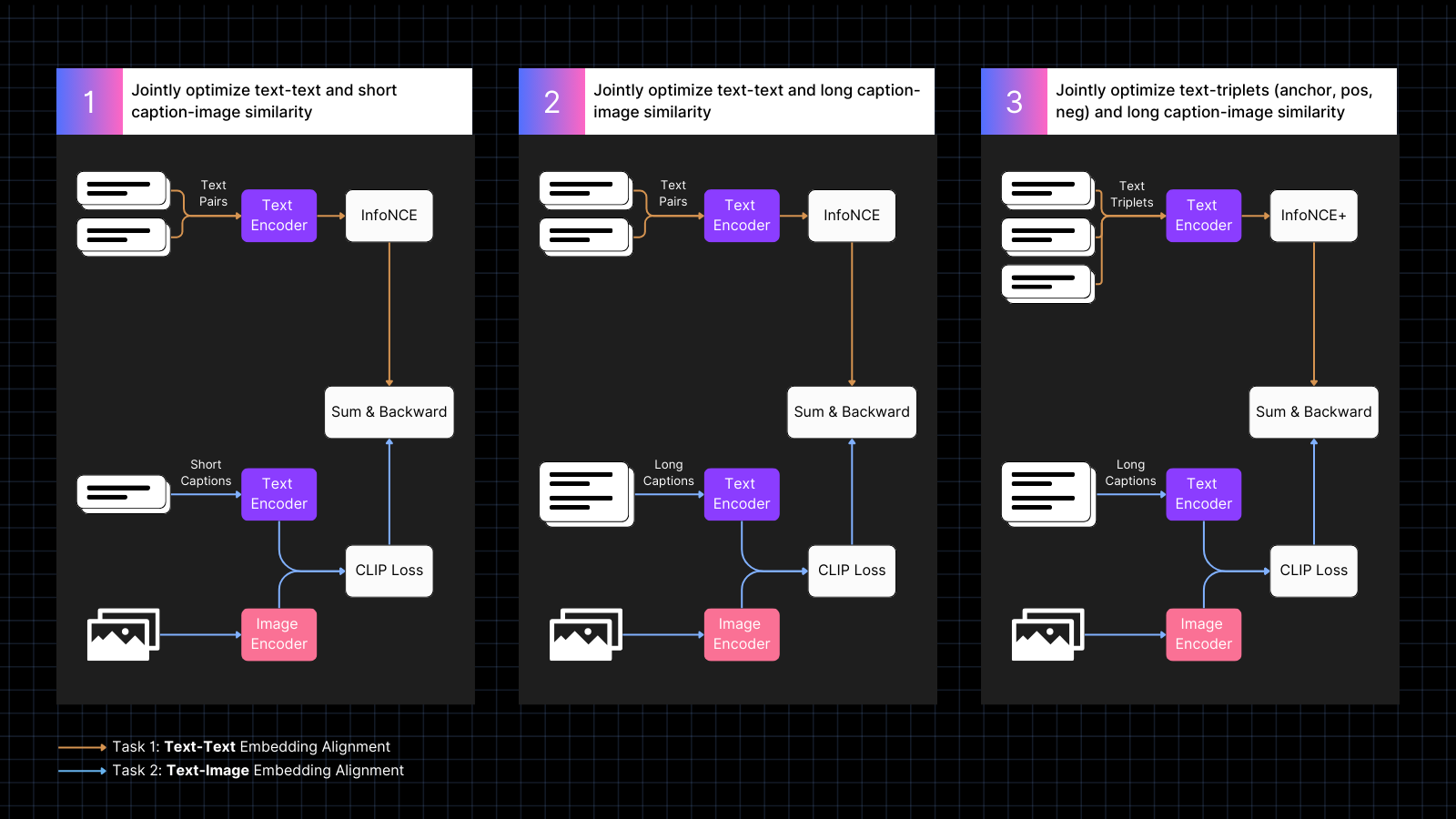
训练分为三个步骤:
- 使用带标题的图像数据来学习对齐图像和文本嵌入,同时穿插具有相似含义的文本对。这种协同训练共同优化这两种类型的任务。在这个阶段,模型的纯文本性能会下降,但不会像仅使用图像-文本对训练那样严重。
- 使用将图像与更大文本对齐的合成数据进行训练,这些文本由 AI 模型生成,用于描述图像。同时继续使用纯文本对进行训练。在这个阶段,模型学会结合图像关注更大的文本。
- 使用具有难负样本的文本三元组来进一步提高纯文本性能,通过学习做出更细致的语义区分。同时,继续使用图像和长文本的合成对进行训练。在这个阶段,纯文本性能显著提高,而模型不会失去任何图像-文本能力。
有关训练和模型架构的更多详细信息,请阅读我们最近的论文:
tag多模态嵌入的最新突破
我们在纯文本、纯图像和涉及两种输入模态的跨模态任务中评估了 Jina CLIP v1 的性能。我们使用 MTEB 检索基准来评估纯文本性能。对于纯图像任务,我们使用 CIFAR-100 基准。对于跨模态任务,我们在 Flickr8k、Flickr30K 和 MSCOCO Captions 上进行评估,这些都包含在 CLIP Benchmark 中。
结果总结在下表中:
| Model | Text-Text | Text-to-Image | Image-to-Text | Image-Image |
|---|---|---|---|---|
| jina-clip-v1 | 0.429 | 0.899 | 0.803 | 0.916 |
| openai-clip-vit-b16 | 0.162 | 0.881 | 0.756 | 0.816 |
| % increase vs OpenAI CLIP |
165% | 2% | 6% | 12% |
从这些结果可以看出,jina-clip-v1 在所有类别中都优于 OpenAI 的原始 CLIP,并在纯文本和纯图像检索方面表现显著更好。平均在所有类别中,性能提升了 46%。
你可以在我们最新的论文中找到更详细的评估。
tagEmbeddings API 入门
你可以使用 Jina Embeddings API 轻松地将 Jina CLIP v1 集成到你的应用程序中。
下面的代码展示了如何使用 Python 中的 requests 包调用 API 来获取文本和图像的嵌入。它将文本字符串和图像 URL 传递给 Jina AI 服务器,并返回两者的编码。
<YOUR_JINA_AI_API_KEY> 替换为已激活的 Jina API 密钥。你可以从 Jina Embeddings 网页获得一个包含一百万个免费令牌的试用密钥。import requests
import numpy as np
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
url = 'https://api.jina.ai/v1/embeddings'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR_JINA_AI_API_KEY>'
}
data = {
'input': [
{"text": "Bridge close-shot"},
{"url": "https://fastly.picsum.photos/id/84/1280/848.jpg?hmac=YFRYDI4UsfbeTzI8ZakNOR98wVU7a-9a2tGF542539s"}],
'model': 'jina-clip-v1',
'encoding_type': 'float'
}
response = requests.post(url, headers=headers, json=data)
sim = cos_sim(np.array(response.json()['data'][0]['embedding']), np.array(response.json()['data'][1]['embedding']))
print(f"Cosine text<->image: {sim}")
tag与主要 LLM 框架的集成
Jina CLIP v1 已经可以在 LlamaIndex 和 LangChain 中使用:
- LlamaIndex:使用
JinaEmbedding与MultimodalEmbedding基类,并调用get_image_embeddings或get_text_embeddings。 - LangChain:使用
JinaEmbeddings,并调用embed_images或embed_documents。
tag定价
文本和图像输入都按令牌消耗计费。
对于英文文本,我们经验性地计算出平均每个单词需要 1.1 个令牌。
对于图像,我们计算覆盖你的图像所需的 224x224 像素块的数量。这些图块可能部分为空白但计数相同。每个图块处理需要 1,000 个令牌。
示例
对于一个尺寸为 750x500 像素的图像:
- 图像被分割成 224x224 像素的图块。
- 要计算图块数量,将宽度像素除以 224,然后向上取整。
750/224 ≈ 3.35 → 4 - 对高度像素重复相同操作:
500/224 ≈ 2.23 → 3
- 要计算图块数量,将宽度像素除以 224,然后向上取整。
- 此示例中所需的总图块数量为:
4(水平)x 3(垂直)= 12 个图块 - 成本将是 12 x 1,000 = 12,000 个令牌
tag企业支持
我们为购买110 亿令牌生产部署计划的用户推出新的福利。这包括:
- 与我们的产品和工程团队进行三小时的咨询,讨论你的具体用例和需求。
- 为你的 RAG(检索增强生成)或向量搜索用例定制的 Python notebook,演示如何将 Jina AI 的模型集成到你的应用程序中。
- 分配专门的客户经理和优先电子邮件支持,确保你的需求得到及时有效的满足。
tagHugging Face 上的开源 Jina CLIP v1
Jina AI 致力于开源搜索底座,为此,我们在 Hugging Face 上以 Apache 2.0 许可证免费提供这个模型。
你可以在 Hugging Face 上 jina-clip-v1 的模型页面找到下载和在自己系统或云安装上运行此模型的示例代码。

tag总结
Jina AI 的最新模型 —— jina-clip-v1 —— 代表了多模态嵌入模型的重大进步,相比 OpenAI 的 CLIP 提供了显著的性能提升。在纯文本和纯图像检索任务中有显著改进,在文本到图像和图像到文本任务中也具有竞争力,它为复杂的嵌入用例提供了一个很有前景的解决方案。
由于资源限制,此模型目前仅支持英语文本。我们正在努力扩展其功能以支持更多语言。
