


最新!第二部分:深入探讨边界提示和误解。
大约一年前,在 2023 年 10 月,我们发布了全球首个具有 8K 上下文长度的开源嵌入模型,jina-embeddings-v2-base-en。从那时起,关于嵌入模型中长上下文的实用性一直存在争议。对于许多应用来说,将数千词的文档编码为单个嵌入表示并不理想。许多用例需要检索文本的较小部分,而基于密集向量的检索系统通常在处理较小文本段时表现更好,因为语义在嵌入向量中不太可能被"过度压缩"。
检索增强生成(RAG)是最著名的应用之一,它需要将文档分割成较小的文本块(比如在 512 个 token 以内)。这些文本块通常存储在向量数据库中,其向量表示由文本嵌入模型生成。在运行时,同样的嵌入模型将查询编码为向量表示,然后用于识别相关的存储文本块。这些文本块随后传递给大型语言模型(LLM),后者基于检索到的文本合成对查询的响应。

简而言之,嵌入较小的文本块似乎更可取,部分原因是下游 LLM 的输入大小限制,还因为人们担心长上下文中的重要上下文信息在压缩成单个向量时可能会被稀释。
但如果行业只需要 512 上下文长度的嵌入模型,那训练 8192 上下文长度的模型又有什么意义呢?
在本文中,我们通过探索 RAG 中简单分块-嵌入流程的局限性,重新审视这个重要但令人不适的问题。我们引入了一种名为"Late Chunking"的新方法,它利用 8192 长度嵌入模型提供的丰富上下文信息来更有效地嵌入文本块。
tag丢失上下文问题
简单的分块-嵌入-检索-生成的 RAG 流程并非没有挑战。具体来说,这个过程可能会破坏远距离上下文依赖关系。换句话说,当相关信息分散在多个文本块中时,将文本段从上下文中分离出来可能会使它们失效,使这种方法特别成问题。
在下图中,一篇维基百科文章被分成句子块。你可以看到像"its"和"the city"这样的短语都指代"Berlin",而"Berlin"只在第一句中出现。这使得嵌入模型更难将这些引用与正确的实体联系起来,从而产生较低质量的向量表示。

这意味着,如果我们像上面的例子那样将长文章分成句子长度的块,RAG 系统可能难以回答"柏林的人口是多少?"这样的查询。因为城市名称和人口数字从未在同一个文本块中一起出现,而且在没有更大文档上下文的情况下,LLM 在面对这些块时无法解析像"it"或"the city"这样的照应指代。
有一些启发式方法可以缓解这个问题,比如使用滑动窗口重新采样、使用多个上下文窗口长度,以及执行多次文档扫描。然而,像所有启发式方法一样,这些方法也是可能有效可能无效的;它们在某些情况下可能有用,但没有理论保证其有效性。
tag解决方案:Late Chunking
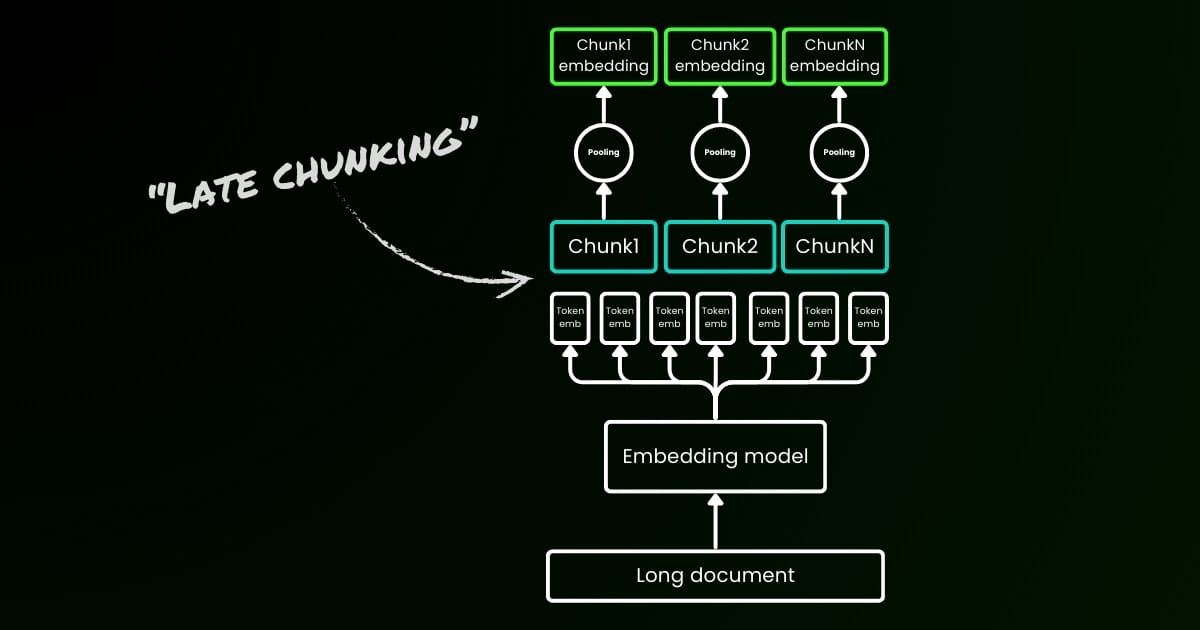
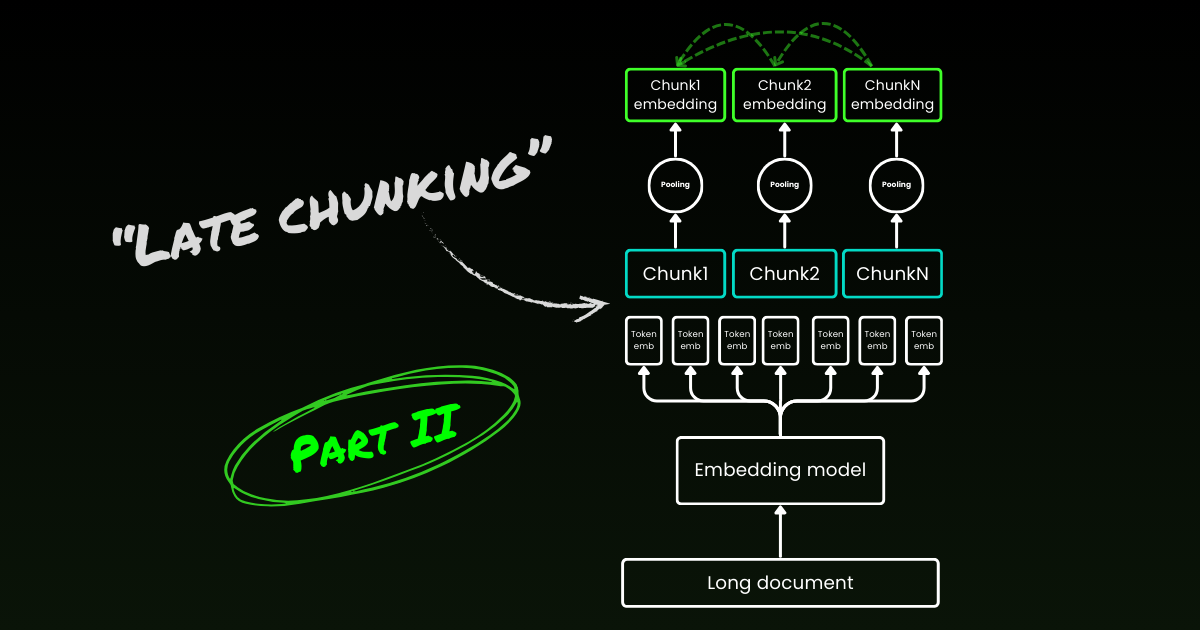
朴素编码方法(如下图左侧所示)涉及使用句子、段落或最大长度限制来预先分割文本。之后,嵌入模型重复应用于这些生成的文本块。为了为每个块生成单个嵌入,许多嵌入模型使用平均池化处理这些 token 级别的嵌入,以输出单个嵌入向量。

相比之下,我们在本文中提出的"Late Chunking"方法首先将嵌入模型的 transformer 层应用于整个文本或尽可能多的文本。这会为每个 token 生成一个包含整个文本信息的向量表示序列。随后,对这个 token 向量序列的每个块应用平均池化,生成考虑了整个文本上下文的每个块的嵌入。与生成独立同分布(i.i.d.)块嵌入的朴素编码方法不同,Late Chunking 创建了一组块嵌入,其中每个嵌入都"以"前面的嵌入为条件,从而为每个块编码更多的上下文信息。
显然,要有效地应用 Late Chunking,我们需要像 jina-embeddings-v2-base-en 这样支持最多 8192 个 token(大约十个标准页面的文本)的长上下文嵌入模型。这种长度的文本段不太可能有需要更长上下文才能解决的上下文依赖关系。
需要强调的是,Late Chunking 仍然需要边界提示,但这些提示仅在获得 token 级别的嵌入之后使用——这就是其名称中"Late"的由来。
| 朴素分块 | Late Chunking | |
|---|---|---|
| 边界提示的需求 | 是 | 是 |
| 边界提示的使用 | 直接在预处理中 | 在从 transformer 层获得 token 级别的嵌入之后 |
| 生成的块嵌入 | i.i.d. | 条件性 |
| 邻近块的上下文信息 | 丢失。一些启发式方法(如重叠采样)可以缓解这一问题 | 通过长上下文嵌入模型得到很好的保留 |
tag实现和定性评估


Late Chunking 的实现可以在上面链接的 Google Colab 中找到。在这里,我们利用了最近在 Tokenizer API 中发布的功能,该功能利用所有可能的边界提示将长文档分割成有意义的块。关于这个功能背后的算法的更多讨论可以在 X 上找到。

当对上述维基百科示例应用延迟分块时,你可以立即看到语义相似度的提升。例如,在维基百科文章中"这座城市"和"柏林"的情况下,表示"这座城市"的向量现在包含了将其链接到之前提到的"柏林"的信息,这使得它在涉及该城市名称的查询中能获得更好的匹配效果。
| Query | Chunk | Sim. on naive chunking | Sim. on late chunking |
|---|---|---|---|
| Berlin | Berlin is the capital and largest city of Germany, both by area and by population. | 0.849 | 0.850 |
| Berlin | Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. | 0.708 | 0.825 |
| Berlin | The city is also one of the states of Germany, and is the third smallest state in the country in terms of area. | 0.753 | 0.850 |
你可以在上面的数值结果中观察到这一点,这些结果比较了"Berlin"这个词与使用余弦相似度计算的柏林文章中各个句子的嵌入。"Sim. on IID chunk embeddings"列显示了"Berlin"查询嵌入与使用先验分块的嵌入之间的相似度值,而"Sim. under contextual chunk embedding"代表了使用延迟分块方法的结果。
tag在 BEIR 上的定量评估
为了验证延迟分块在玩具示例之外的有效性,我们使用了来自 BeIR 的一些检索基准进行测试。这些检索任务包括一个查询集、一个文本文档语料库和一个 QRels 文件,该文件存储了与每个查询相关的文档 ID 信息。
为了识别与查询相关的文档,将文档分块、编码成嵌入索引,并使用 k-近邻(kNN)为每个查询嵌入确定最相似的块。由于每个块对应一个文档,块的 kNN 排名可以转换为文档的 kNN 排名(在排名中仅保留多次出现的文档的第一次出现)。然后将这个结果排名与地面真实 QRels 文件提供的排名进行比较,并计算 nDCG@10 等检索指标。下面描述了这个过程,评估脚本可在此仓库中找到以供复现。
 jina-ai
jina-ai我们在各种 BeIR 数据集上进行了这项评估,比较了朴素分块与我们的延迟分块方法。为了获取边界提示,我们使用了一个正则表达式,将文本分割成大约 256 个令牌长度的字符串。朴素分块和延迟分块评估都使用 jina-embeddings-v2-small-en 作为嵌入模型;这是 v2-base-en 模型的较小版本,仍然支持最多 8192 个令牌长度。结果可以在下表中找到。
| Dataset | Avg. Document Length (characters) | Naive Chunking (nDCG@10) | Late Chunking (nDCG@10) | No Chunking (nDCG@10) |
|---|---|---|---|---|
| SciFact | 1498.4 | 64.20% | 66.10% | 63.89% |
| TRECCOVID | 1116.7 | 63.36% | 64.70% | 65.18% |
| FiQA2018 | 767.2 | 33.25% | 33.84% | 33.43% |
| NFCorpus | 1589.8 | 23.46% | 29.98% | 30.40% |
| Quora | 62.2 | 87.19% | 87.19% | 87.19% |
在所有情况下,延迟分块相比朴素方法都提高了分数。在某些情况下,它甚至优于将整个文档编码为单个嵌入的方法,而在其他数据集中,完全不进行分块反而产生了最佳结果(当然,不分块只在不需要对块进行排序时才有意义,这种情况在实践中很少见)。如果我们将朴素方法和延迟分块之间的性能差距与文档长度进行对比绘图,就会发现文档的平均长度与通过延迟分块获得的 nDCG 分数的改善程度呈相关性。换句话说,文档越长,延迟分块策略的效果就越好。

tag结论
在本文中,我们介绍了一种名为"延迟分块"的简单方法,通过利用长上下文嵌入模型的能力来嵌入短块。我们展示了传统的独立同分布块嵌入如何无法保留上下文信息,从而导致次优检索;以及延迟分块如何提供一个简单但高效的解决方案来维护和调节每个块内的上下文信息。延迟分块的效果在较长文档上变得越发显著——这种能力只能通过像 jina-embeddings-v2-base-en 这样的高级长上下文嵌入模型才能实现。我们希望这项工作不仅验证了长上下文嵌入模型的重要性,还能激发这个主题的进一步研究。
继续阅读第二部分:深入探讨边界提示和误解。
