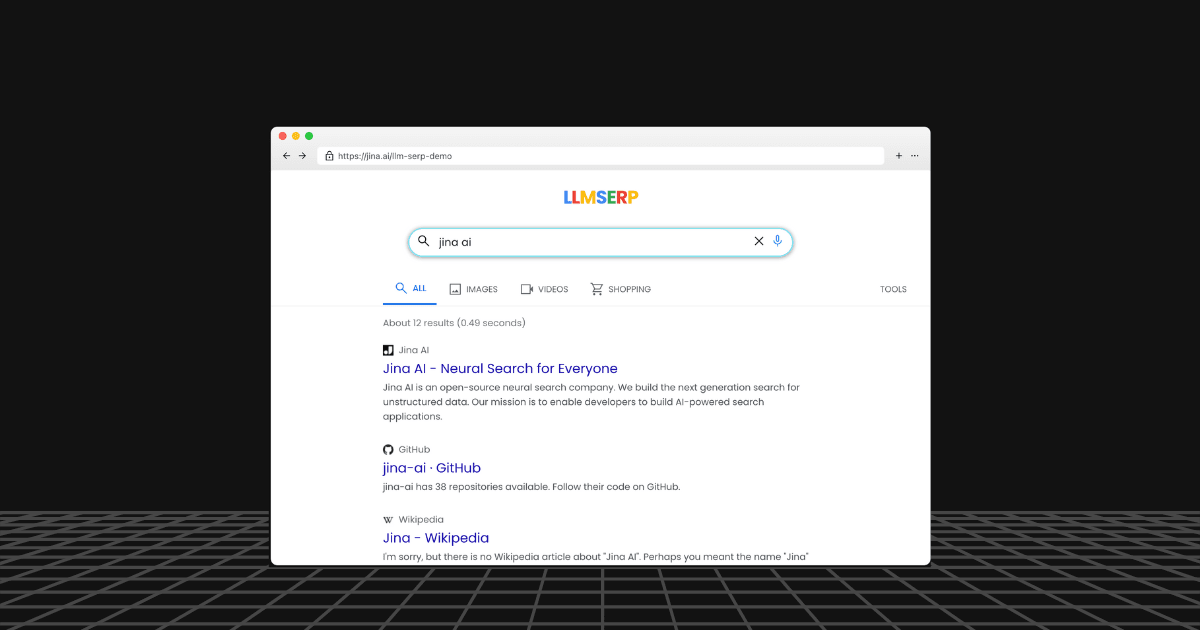


尝试这个交互式演示,看看你的网站在 LLM SERP 中是如何呈现的。
自从 RAG 出现以来,使用 LLM 改进搜索已成为一种趋势。从 Perplexity 到 DeepSearch 和 DeepResearch,将搜索引擎结果注入生成过程的理念已成为事实标准。许多用户也表示他们不再像以前那样经常使用 Google,认为其经典的分页设计乏味、令人不知所措或繁琐。相反,他们已经习惯于聊天式搜索界面中问答式结果的高精确度和召回率,这表明这种设计理念可能是未来的发展方向。
但如果 LLM 本身就是搜索引擎呢?
如果你可以像使用 Google 一样探索 LLM 中嵌入的知识呢?分页、链接和一切 - 就像你熟悉的过去那样。如果你不确定我的意思,先看看下面的演示。
这些链接、标题和摘要完全由 LLM 生成。你可以访问 https://jina.ai/llm-serp-demo 自己尝试一些查询!
在提出关于幻觉的担忧之前,让我们先解释为什么这个想法有一些价值:LLM 是在海量的网络知识库上训练的。像 DeepSeek-R1、GPT-4、Claude-3.7 和 Gemini-2.0 这样的模型已经在来自公共互联网的数万亿个 token 上进行了训练。粗略估计,领先模型使用了不到 1% 到约 5% 的高质量、可公开访问的网络文本进行训练。
如果你认为这个数字似乎太小,考虑这个比较:如果我们用 Google 的索引作为基准(代表世界上 100% 的用户可访问数据),那么 Bing 的索引大约是 Google 的 30-50%。百度覆盖约 5-10%,Yandex 覆盖 3-5%。Brave Search 索引不到 1%。因此,如果一个 LLM 在 1-5% 的高质量公共数据上训练,它可能等同于一个不错的小型搜索引擎可以提供的相同数据量。
由于这些模型已经有效地"记住"了这些网络数据,我们只需要以一种能"激活"它们记忆的方式进行提示,让它们能够像搜索引擎一样运作,并生成类似搜索引擎结果页面(SERP)的结果。
所以是的,幻觉是一个挑战,但随着每一次迭代模型能力的提升,我们可以合理地期待这个问题会得到缓解。在 X 上,每当新模型发布时,人们都热衷于从头开始生成 SVG,希望每个版本都能比上一个版本产生更好的插图。这个搜索引擎的想法也遵循类似的期望,即 LLM 对数字世界理解的逐步改进。

qwen-2.5-max 一次性绘制猪的 SVG 的能力。知识截止日期是另一个限制。搜索引擎应该返回接近实时的信息,但由于 LLM 权重在训练后被冻结,它们无法提供超出截止日期的准确信息。通常,查询离这个截止日期越近,出现幻觉的可能性就越大。因为较旧的信息可能被更频繁地引用和改述,可能增加了它们在训练数据中的权重。(这假设信息是均匀加权的;突发新闻可能会获得不成比例的关注,而不考虑时效性。)然而,这个限制恰恰定义了这种方法最有用的地方——对于在模型知识时间范围内的信息。
tagLLM-as-SERP 在哪些方面有用?
在 DeepSearch/RAG 或任何搜索基础系统中,一个核心挑战是确定问题是需要外部信息还是可以从模型的知识中回答。当前系统通常使用基于提示的路由,指令如:
- For greetings, casual conversation, or general knowledge questions, answer directly without references.
- For all other questions, provide a verified answer with external knowledge. Each reference must include exactQuote and url.这种方法在两个方向都会失败 - 有时会触发不必要的搜索,有时又会错过关键的信息需求。特别是对于较新的推理模型,在生成过程中期之前,通常不明显是否需要外部数据。
如果我们直接进行搜索呢?我们可以同时调用一个真实的搜索 API 和一个 LLM-as-search 系统。这样就不需要提前做路由决策,而是将其移到下游,在那里我们有实际的结果可以比较 - 来自真实搜索的最新数据、模型训练截止日期内的知识,以及可能的一些错误信息。

最后的推理步骤可以识别不一致性,并根据时效性、可靠性和结果间的共识来权衡各个来源——这些我们不需要显式编码,因为这本就是 LLM 擅长的领域。我们还可以访问搜索结果中的每个 URL(例如使用 Jina Reader)来进一步验证来源。在实际应用中,这个验证步骤总是必要的;无论是真实还是伪造的搜索引擎,你都不应该仅仅依赖搜索引擎的摘录。
tag结论
通过使用 LLM-as-SERP,我们将"这是否在模型的知识范围内?"这一二元问题转变为一个更稳健的证据权衡过程。
我们提供了一个演示平台以及由我们托管的 API 端点供你试验。您也可以将其集成到自己的 DeepSearch/DeepResearch 实现中,亲身体验其改进效果。

该 API 模拟了一个完整的 SERP 端点,您可以在其中定义结果数量、分页、国家、语言等。您可以在 GitHub 上找到它的实现。我们期待听到您对这种有趣方法的反馈。





