


late_chunking 参数控制模型是否在将文档分块之前处理整个文档,从而在长文本中保留更多上下文。从用户的角度来看,输入和输出格式保持不变,但嵌入值将反映完整文档的上下文,而不是为每个块独立计算。- 当使用
late_chunking=True时,每个请求中的令牌总数(input中所有块的总和)限制为 8192,这是 v3 允许的最大上下文长度。 - 当使用
late_chunking=False时,此令牌限制不适用,总令牌数仅受 Embedding API 的速率限制约束。
要启用迟分技术,在 API 调用中传递 late_chunking=True。
你可以通过搜索聊天历史来看到迟分技术的优势:
history = [
"Sita, have you decided where you'd like to go for dinner this Saturday for your birthday?",
"I'm not sure. I'm not too familiar with the restaurants in this area.",
"We could always check out some recommendations online.",
"That sounds great. Let's do that!",
"What type of food are you in the mood for on your special day?",
"I really love Mexican or Italian cuisine.",
"How about this place, Bella Italia? It looks nice.",
"Oh, I've heard of that! Everyone says it's fantastic!",
"Shall we go ahead and book a table there then?",
"Yes, I think that would be a perfect choice! Let's call and reserve a spot."
]
如果我们用 Embeddings v2 询问 What's a good restaurant?,结果并不是很相关:
| Document | Cosine Similarity |
|---|---|
| I'm not sure. I'm not too familiar with the restaurants in this area. | 0.7675 |
| I really love Mexican or Italian cuisine. | 0.7561 |
| How about this place, Bella Italia? It looks nice. | 0.7268 |
| What type of food are you in the mood for on your special day? | 0.7217 |
| Sita, have you decided where you'd like to go for dinner this Saturday for your birthday? | 0.7186 |
使用 v3 且不使用迟分技术时,我们得到类似的结果:
| Document | Cosine Similarity |
|---|---|
| I'm not sure. I'm not too familiar with the restaurants in this area. | 0.4005 |
| I really love Mexican or Italian cuisine. | 0.3752 |
| Sita, have you decided where you'd like to go for dinner this Saturday for your birthday? | 0.3330 |
| How about this place, Bella Italia? It looks nice. | 0.3143 |
| Yes, I think that would be a perfect choice! Let's call and reserve a spot. | 0.2615 |
然而,当使用 v3 并启用迟分技术时,我们看到性能明显提升,最相关的结果(一个好餐厅)位于顶部:
| Document | Cosine Similarity |
|---|---|
| How about this place, Bella Italia? It looks nice. | 0.5061 |
| Oh, I've heard of that! Everyone says it's fantastic! | 0.4498 |
| I really love Mexican or Italian cuisine. | 0.4373 |
| What type of food are you in the mood for on your special day? | 0.4355 |
| Yes, I think that would be a perfect choice! Let's call and reserve a spot. | 0.4328 |
如你所见,即使最佳匹配完全没有提到"餐厅"这个词,迟分技术也保留了其原始上下文并将其作为正确的最佳答案。它将"餐厅"的含义编码到餐厅名称"Bella Italia"中,因为它在更大的文本中看到了其含义。
tag使用套嵌式嵌入平衡效率和性能
Embeddings v3 中的 dimensions 参数使你能够以最小的代价平衡存储效率和性能。v3 的套嵌式嵌入让你可以根据需要截断模型产生的向量,减少维度的同时保留有用信息。较小的嵌入非常适合在向量数据库中节省空间并提高检索速度。你可以根据维度减少的程度估计性能影响:
data = {
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 768, # 1024 by default
"input": [
"The Force will be with you. Always.",
"力量与你同在。永远。",
"La Forza sarà con te. Sempre.",
"フォースと共にあらんことを。いつも。"
]
}
response = requests.post(url, headers=headers, json=data)
tag常见问题
tag我已经在生成嵌入之前对文档进行分块。迟分技术相比我自己的系统有什么优势吗?
迟分技术比预先分块更有优势,因为它先处理整个文档,在将文本分割成块之前保留重要的上下文关系。这会产生更丰富的上下文嵌入,可以提高检索准确性,特别是在复杂或较长的文档中。此外,由于模型在分段之前对文档有整体理解,迟分技术可以在搜索或检索期间帮助提供更相关的响应。这与预先分块相比能带来更好的整体性能,因为在预先分块中,每个块都是独立处理的,没有完整的上下文。
tag为什么 v2 在对对分类方面比 v3 更好,我应该担心吗?
之所以 v2-base-(zh/es/de) 模型在对对分类(PC)方面表现更好,主要是因为平均分数的计算方式。在 v2 中,只考虑中文的 PC 性能,其中 embeddings-v2-base-zh 模型表现出色,导致平均分数更高。v3 的基准测试包括中文、法语、波兰语和俄语四种语言。因此,与 v2 仅中文的分数相比,其整体分数看起来较低。然而,v3 在所有语言的 PC 任务中仍然能够匹配或超越 multilingual-e5 等模型。这种更广泛的范围解释了感知到的差异,特别是对于多语言应用来说,这种性能下降不应成为担忧,因为 v3 仍然具有很强的竞争力。
tagv3 真的在特定语言上超越了 v2 双语模型吗?
当比较 v3 和 v2 双语模型时,性能差异取决于具体的语言和任务。
v2 双语模型针对各自的语言进行了高度优化。因此,在特定语言的基准测试中,如中文的对对分类(PC),v2 可能显示出更优的结果。这是因为 embeddings-v2-base-zh 的设计专门针对该语言,使其能在这个狭窄范围内表现出色。
然而,v3 的设计支持更广泛的多语言,可处理 89 种语言,并通过特定任务的 LoRA 适配器进行优化。这意味着虽然 v3 可能不会在特定语言的每个单一任务中都超越 v2(如中文的 PC),但在跨多种语言评估或更复杂的特定任务场景(如检索和分类)中,它往往表现更好。
对于多语言任务或跨语言工作时,v3 提供了更平衡和全面的解决方案,在语言间实现更好的泛化。然而,对于双语模型经过精细调整的特定语言任务,v2 可能仍保持优势。
实践中,选择合适的模型取决于你的具体任务需求。如果你只使用特定语言且 v2 针对该语言进行了优化,你可能仍能看到 v2 的竞争性结果。但对于更通用或多语言应用,由于 v3 的多样性和更广泛的优化,它可能是更好的选择。
tag为什么 v2 在摘要方面比 v3 更好,我需要担心吗?
v2-base-en 在摘要(SM)方面表现更好,是因为其架构针对语义相似度等任务进行了优化,这与摘要密切相关。相比之下,v3 的设计是为了支持更广泛的任务,特别是在检索和分类任务方面,更适合复杂和多语言场景。
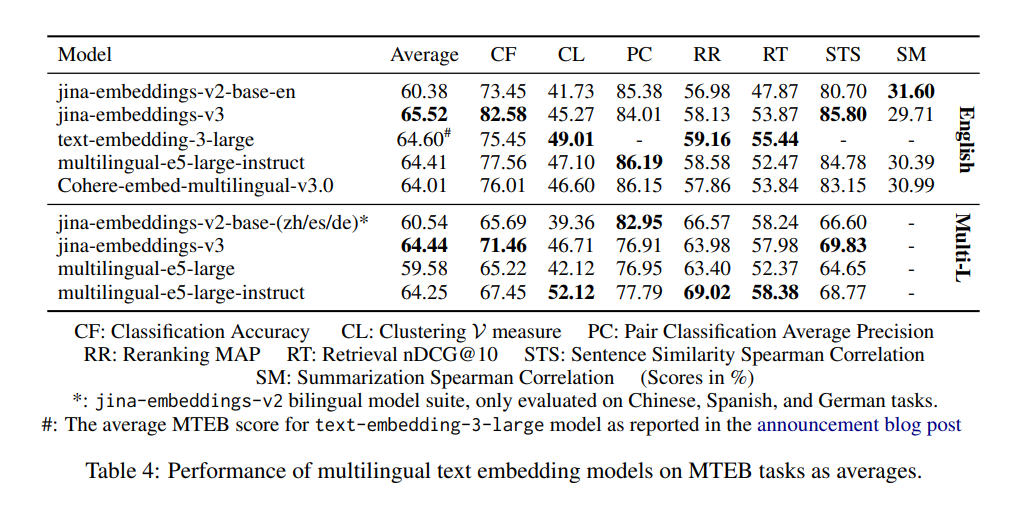
然而,SM 方面的这种性能差异对大多数用户来说不应该是一个问题。SM 评估仅基于一个摘要任务 SummEval,该任务主要衡量语义相似度。仅这一个任务并不能很好地说明或代表模型的更广泛能力。由于 v3 在其他关键领域(如检索)表现出色,摘要方面的差异不太可能对你的实际使用场景产生显著影响。





