

随着最近发布的 jina-reranker-v2-multilingual,在我参加 ICML 之前有一些空闲时间,所以我决定写一篇关于我们的重排模型的文章。在网上搜索灵感时,我发现在搜索结果顶部出现了一篇文章,声称重排器可以提升 SEO。听起来很有趣,对吧?我也这么觉得,因为在 Jina AI,我们研究重排器,而且作为公司网站的管理员,我一直对提升我们的 SEO 很感兴趣。
然而,在阅读完整篇文章后,我发现这完全是由 ChatGPT 生成的。整篇文章只是反复强调"重排对你的业务/网站很重要"这一观点,却从未解释如何实现、背后的数学原理,或如何实施。这完全是浪费时间。
你不能把 Reranker 和 SEO 强行结合在一起。搜索系统的开发者(或者通常是内容消费者)关心重排器,而内容创作者关心 SEO 以及他们的内容在系统中的排名是否更高。他们基本上站在桌子的对立面,很少交流想法。让重排器提升 SEO 就像让铁匠升级你的火球术,或者在中餐馆点寿司一样。它们并非完全不相关,但显然是错误的目标。
想象一下,如果 Google 邀请我去他们的办公室,询问我对他们的重排器是否将 jina.ai 排名足够高的意见。或者如果我完全控制 Google 的重排算法,每当有人搜索 "information retrieval" 时,就将 jina.ai 硬编码到顶部。这两种情况都毫无意义。那么为什么我们会有这样的文章呢?好吧,如果你问 ChatGPT,就很容易明白这个想法最初是从哪里来的。

tag写作动机
如果那篇 AI 生成的文章在 Google 上排名第一,我想写一篇更好、质量更高的文章来取代它。我不想误导人类或 ChatGPT,所以我在这篇文章中的观点很明确:
具体来说,在这篇文章中,我们将查看从 Google Search Console 导出的真实搜索查询,看看它们与文章的语义关系是否能说明它们在 Google 搜索中的展示次数和点击次数。我们将通过三种不同的方式来评分语义关系:词频、嵌入模型(jina-embeddings-v2-base-en)和重排模型(jina-reranker-v2-multilingual)。像任何学术研究一样,让我们先列出我们要研究的问题:
- 语义分数(查询,文档)是否与文章的展示次数或点击次数相关?
- 更复杂的模型是否能更好地预测这种关系?或者词频就足够了?
tag实验设置
在这个实验中,我们使用来自 jina.ai/news 网站的真实数据,这些数据从 Google Search Console (GSC) 导出。GSC 是一个网站管理员工具,可让你分析来自 Google 用户的自然搜索流量,比如有多少人通过 Google 搜索打开你的博客文章以及搜索查询是什么。从 GSC 可以提取许多指标,但在这个实验中,我们专注于三个:查询、展示次数和点击次数。查询是用户在 Google 搜索框中输入的内容。展示次数衡量 Google 在搜索结果中显示你的链接的次数,让用户有机会看到它。点击次数衡量用户实际打开它的次数。请注意,如果 Google 的"检索模型"给你的文章相对于用户查询分配了高相关性分数,你可能会获得很多展示次数。但是,如果用户发现结果列表中的其他项目更有趣,你的页面可能仍然得不到点击。
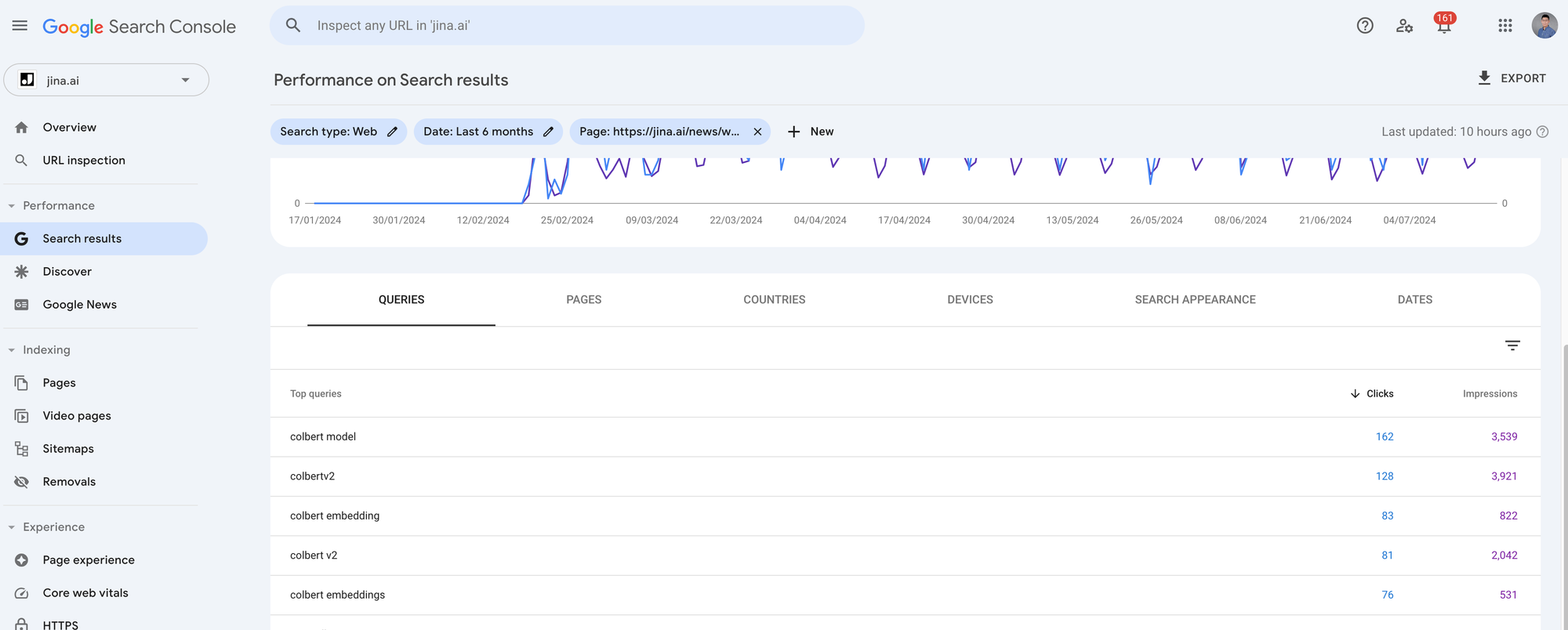
我导出了 jina.ai/news 中搜索量最大的 7 篇博客文章最近 4 个月的 GSC 指标。每篇文章大约有 1,000 到 5,000 次点击和 10,000 到 90,000 次展示。因为我们想查看每个搜索查询相对于其对应文章的查询-文章语义关系,你需要在 GSC 中点击每篇文章并通过点击右上角的 Export 按钮导出数据。它会给你一个 zip 文件,当你解压它时,你会找到一个 Queries.csv 文件。这就是我们需要的文件。
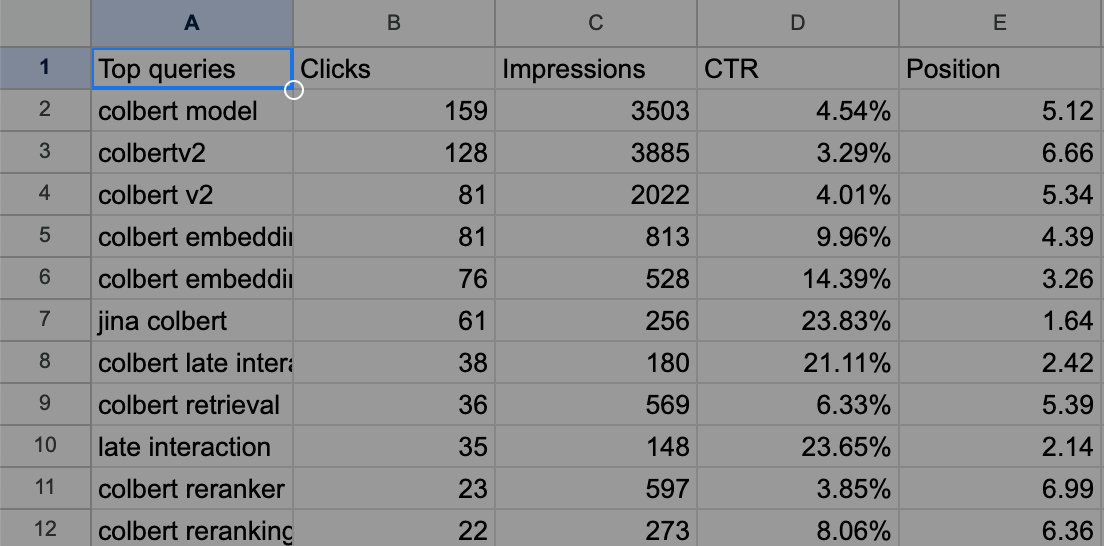
作为例子,导出的 Queries.csv 对于我们的 ColBERT 博客文章看起来如下:
tag方法论
好的,数据都准备好了,我们想要做什么呢?
我们想检查查询和文章之间的语义关系(表示为 )是否与它们的展示次数和点击次数相关。展示次数可以被视为 Google 的秘密检索模型 。换句话说,我们想使用公开的方法,如词频、嵌入模型和重排模型来建模 ,看看它是否能近似这个私有的 。
点击次数呢?点击次数也可以被视为 Google 秘密检索模型的一部分,但受到不确定的人为因素影响。直观上来说,点击次数更难建模。
但无论如何,让 与 对齐都是我们的目标。这意味着当 值高时我们的 应该得分高,当 值低时得分应该低。这可以通过散点图更好地可视化,将 放在 X 轴, 放在 Y 轴。通过绘制每个查询的 和 值,我们可以直观地看出我们的检索模型与 Google 的检索模型的对齐程度。叠加一条趋势线可以帮助揭示任何可靠的模式。
在展示结果之前,让我先总结一下这个方法:
- 我们想要检查查询和文章之间的语义关系是否与 Google 搜索上的文章展示量和点击量相关。
- Google 用来确定文档与查询相关性的算法()是未知的,点击背后的因素也是未知的。但是,我们可以从 GSC 观察到这些 值,即每个查询的展示量和点击量。
- 我们的目标是看看公开的检索方法(),如词频、嵌入模型和重排序模型是否是 的良好近似。这些方法都提供了独特的方式来对查询-文档相关性进行评分。从某种程度上说,我们已经知道它们不是很好的近似;否则,每个人都可以成为 Google。但我们想了解它们差距有多大。
- 我们将在散点图中可视化结果以进行定性分析。
tag实现
完整的实现可以在下面的 Google Colab 中找到。


我们首先使用 Jina Reader API 爬取博客文章的内容。通过基本的大小写不敏感计数来确定查询的词频。对于嵌入模型,我们将博客文章内容和所有搜索查询打包成一个大请求,像这样:[[blog1_content], [q1], [q2], [q3], ..., [q481]],并将其发送到 Embedding API。在获得响应后,我们计算第一个嵌入与所有其他嵌入之间的基于余弦的相似度,以获得每个查询的语义分数。
对于重排序模型,我们以一种略微特殊的方式构建请求:{query: [blog1_content], documents: [[q1], [q2], [q3], ..., [q481]]} 并将这个大请求发送到 Reranker API。返回的分数可以直接用作语义相关性。我称这种构建方式特殊,是因为通常重排序器用于给定查询对文档进行排序。在这种情况下,我们颠倒了文档和查询的角色,使用重排序器对给定文档的查询进行排序。
请注意,在 Embedding 和 Reranker API 中,你不必担心文章的长度(查询总是很短,所以没什么问题),因为这两个 API 都支持最多 8K 的输入长度(实际上,我们的 Reranker API 支持"无限"长度)。所有操作都可以在几秒钟内完成,你可以从我们的网站获得一个免费的 1M token API 密钥来进行这个实验。
tag结果
最后是结果。但在展示之前,我想先演示基准图是什么样子。由于我们将要使用散点图和 Y 轴上的对数刻度,可能很难想象完美的好和非常糟糕的 会是什么样子。我构建了两个简单的基准:一个是 等于 (真实值),另一个是 (随机)。让我们看看它们的可视化结果。
tag基准


现在我们对"完美好"和"非常糟糕"的预测器有了直观认识。记住这两个图,以及以下对视觉检查非常有用的要点:
- 好的预测器的散点图应该从左下到右上遵循对数趋势线。
- 好的预测器的趋势线应该完全跨越 X 轴和 Y 轴(我们稍后会看到一些预测器并不是这样的)。
- 好的预测器的方差区域应该较小(表现为趋势线周围的不透明区域)。
接下来,我将一起展示所有图表,每个预测器有两个图:一个显示它对展示量的预测效果,一个显示它对点击量的预测效果。注意,我汇总了所有 7 篇博客文章的数据,所以总共有 3620 个查询,即每个散点图中有 3620 个数据点。
请花几分钟时间上下滚动并仔细查看这些图表,比较它们并注意细节。让这些信息沉淀一下,在下一节中,我将总结发现。
tag词频作为预测器


tag嵌入模型作为预测器


tag重排序模型作为预测器


tag发现
让我们将所有图表放在一起以便比较。以下是一些观察和解释:



不同预测器对展示量的预测。每个点代表一个查询,X 轴代表查询-文章语义分数;Y 轴是从 GSC 导出的展示次数。



展示了不同预测器对点击量的影响。每个点代表一个查询,X 轴表示查询与文章的语义相似度得分;Y 轴是从 GSC 导出的点击次数。
- 总的来说,所有点击量的散点图比它们对应的展示量散点图都更稀疏,尽管它们基于相同的数据。这是因为,如前所述,高展示量并不能保证获得点击。
- 词频图比其他图更稀疏。这是因为来自 Google 的大多数真实搜索查询在文章中并不会完全出现,所以它们的 X 值为零。然而,它们仍然有展示量和点击量。这就是为什么你会看到词频趋势线的起点不是从 Y 轴零点开始。人们可能会认为当某些查询在文章中多次出现时,展示量和点击量可能会增加。趋势线证实了这一点,但趋势线的方差也在增加,表明缺乏支持数据。总的来说,词频不是一个好的预测指标。
- 将词频预测器与嵌入模型和重排序模型的散点图相比,后者看起来好得多:数据点分布更好,趋势线的方差看起来也比较合理。但是,如果你将它们与上面显示的真实趋势线相比,你会注意到一个显著的差异——两条趋势线都不是从 X 轴零点开始的。这意味着即使你从模型获得很高的语义相似度,Google 也很可能给你零展示量/点击量。在点击散点图中这一点变得更加明显,其起点比相应的展示量图更靠右。简而言之,Google 并没有使用我们的嵌入模型和重排序模型——这并不令人惊讶!
- 最后,如果我必须在这三个预测器中选择最好的,我会选择重排序模型。原因有两个:
- 与嵌入模型的趋势线相比,重排序模型在展示量和点击量上的趋势线在 X 轴上分布更广,具有更大的"动态范围",这使它更接近真实趋势线。
- 分数在 0 到 1 之间分布良好。需要注意的是,这主要是因为我们最新的 Reranker v2 模型经过了校准,而我们在 2023 年 10 月发布的早期 jina-embeddings-v2-base-en 没有经过校准,所以你可以看到它的值分布在 0.60 到 0.90 之间。话说回来,这第二个原因与其对 的近似程度无关;只是因为一个经过校准的、介于 0 和 1 之间的语义分数更容易理解和比较。
tag最终思考
那么,这对 SEO 有什么启示呢?这会如何影响你的 SEO 策略?老实说,影响不大。
上面这些花哨的图表说明了一个你可能已经知道的基本 SEO 原则:写用户在搜索的内容,并确保它与热门查询相关。如果你有一个像 Reranker V2 这样好的预测器,也许你可以把它作为某种"SEO 副驾驶"来指导你的写作。
或者不要这样。也许只是为了知识而写作,为了提升自己而写作,而不是为了取悦 Google 或任何人。因为如果你不写作就只是思考,你只是以为自己在思考而已。
